介绍
在本系列的上一部分中,我们使用了CIFAR-10数据集,并介绍了PyTorch的基础知识:
张量及其相关操作
数据集和数据加载器
构建基本的神经网络
基本模型的训练和评估
我们为CIFAR-10数据集中的图像分类开发的模型只能在验证集上达到53%的准确率,并且在一些类别(如鸟类和猫类)的图像分类上表现非常困难(约33-35%的准确率)。这是预期的,因为我们通常会使用卷积神经网络进行图像分类。在本教程系列的这一部分,我们将专注于卷积神经网络(CNN)并改善在CIFAR-10上的图像分类性能。
CNN基础知识
在我们深入代码之前,让我们讨论卷积神经网络的基础知识,以便更好地理解我们的代码在做什么。如果你已经对CNN的工作原理感到熟悉,可以跳过本节。
与前一部分中开发的前馈网络相比,卷积神经网络具有不同的架构,并由不同类型的层组成。在下图中,我们可以看到典型CNN的一般架构,包括它可能包含的不同类型的层。
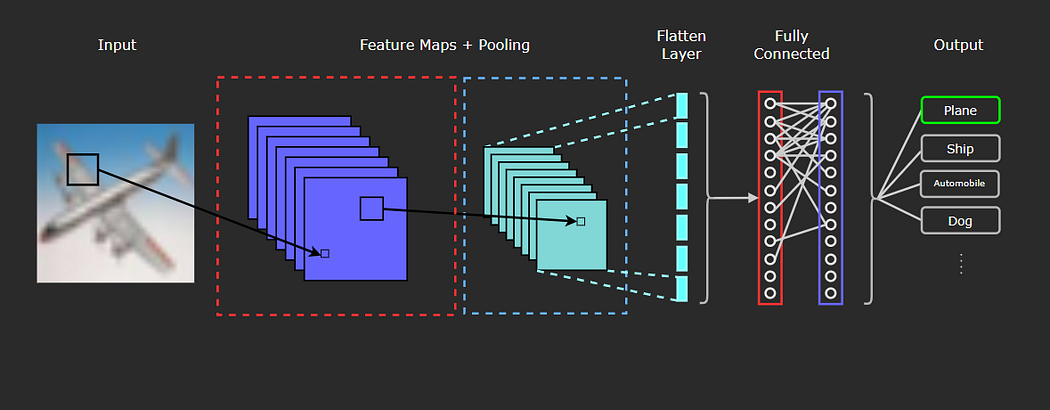
卷积网络中通常包含的三种类型的层是:
卷积层(红色虚线框)
池化层(蓝色虚线框)
全连接层(红色和紫色实线框)
卷积层
CNN的定义组件和第一层是卷积层,它由以下部分组成:
输入数据(在本例中为图像)
滤波器
特征图
将卷积层与全连接层区分开来的关键是卷积运算。我们不会详细讨论卷积的定义,但如果你真的感兴趣并想深入了解其数学定义以及一些具体的示例,我强烈推荐阅读这篇文章,它在解释数学定义方面做得非常好
https://betterexplained.com/articles/intuitive-convolution/#Part_3_Mathematical_Properties_of_Convolution
卷积相对于密集连接层(全连接层)在图像数据中的优势何在?简而言之,密集连接层会学习输入中的全局模式,而卷积层具有学习局部和空间模式的优势。这可能听起来有些模糊或抽象,所以让我们看一个例子来说明这是什么意思。

在图片的左侧,我们可以看到一个基本的2D黑白图像的4是如何在卷积层中表示的。
红色方框是滤波器/特征检测器/卷积核,在图像上进行卷积操作。在右侧是相同图像在一个密集连接层中的表示。你可以看到相同的9个图像像素被红色的卷积核框起来。请注意,在左侧,像素在空间上是分组的,与相邻的像素相邻。然而,在右侧,这相同的9个像素不再是相邻的。
通过这个例子,我们可以看到当图像被压平并表示为完全连接/线性层时,空间/位置信息是如何丢失的。这就是为什么卷积神经网络在处理图像数据时更强大的原因。输入数据的空间结构得到保留,图像中的模式(边缘、纹理、形状等)可以被学习。
这基本上是为什么在图像上使用卷积神经网络的原因,但现在让我们讨论一下如何实现。让我们来看看我们的输入数据的结构,我们一直在谈论的那些叫做“滤波器”的东西,以及当我们将它们放在一起时卷积是什么样子。
输入数据
CIFAR-10数据集包含60,000个32x32的彩色图像,每个图像都表示为一个3D张量。每个图像将是一个(32,32,3)的张量,其中的维度是32(高度)x 32(宽度)x 3(R-G-B颜色通道)。下图展示了从数据集中分离出来的飞机全彩色图像的3个不同的颜色通道(RGB)。
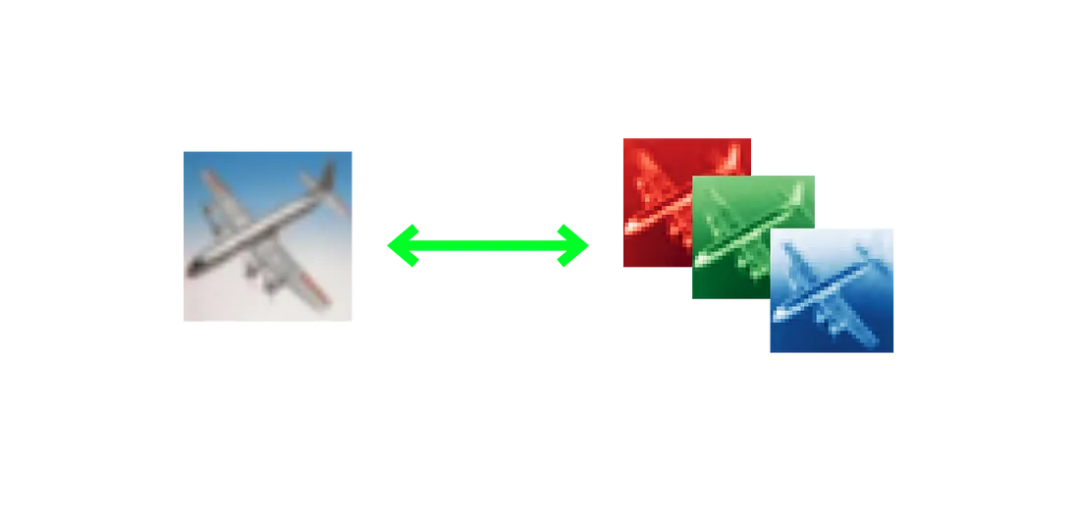
通常将图像视为二维的,所以很容易忘记它们实际上是以三维表示的,因为它们有3个颜色通道!
滤波器
在卷积层中,滤波器(也称为卷积核或特征检测器)是一组权重数组,它以滑动窗口的方式在图像上进行扫描,计算每一步的点积,并将该点积输出到一个称为特征图的新数组中。这种滑动窗口的扫描称为卷积。让我们看一下这个过程的示例,以帮助理解正在发生的事情。
一个3x3的滤波器(蓝色)对输入(红色)进行卷积,生成一个特征图(紫色):
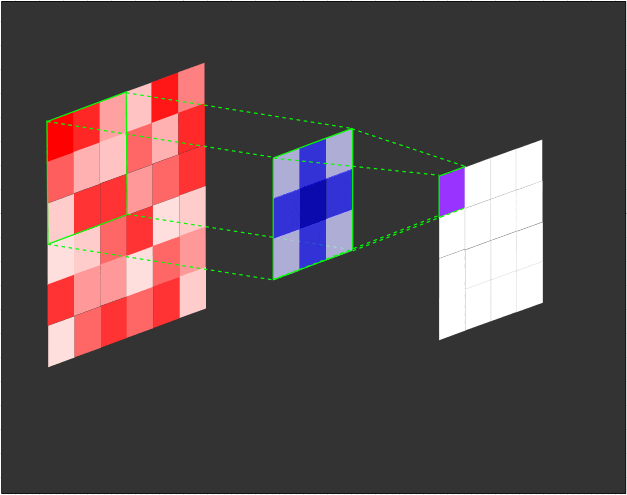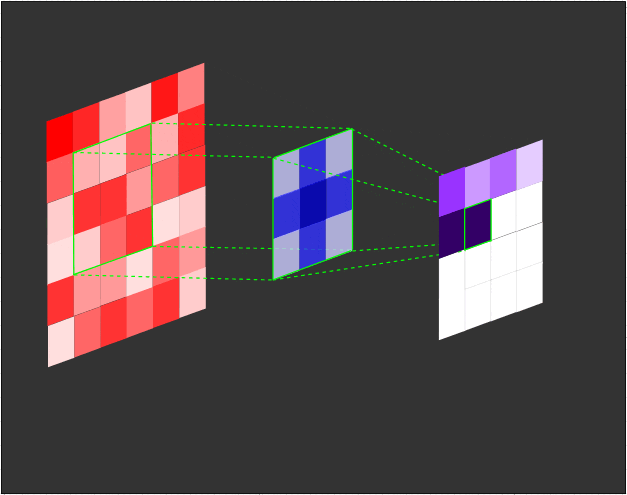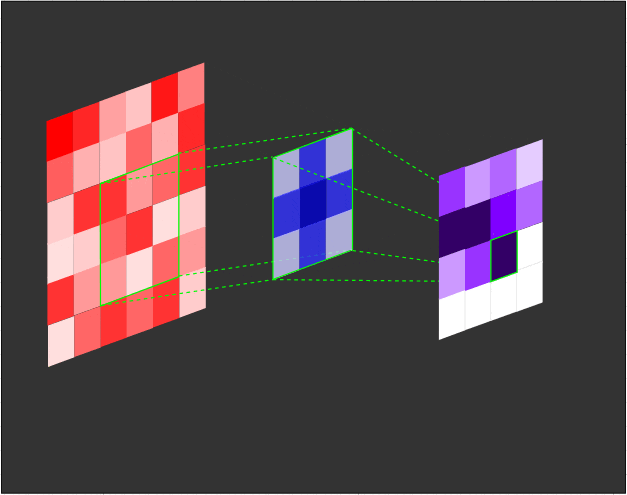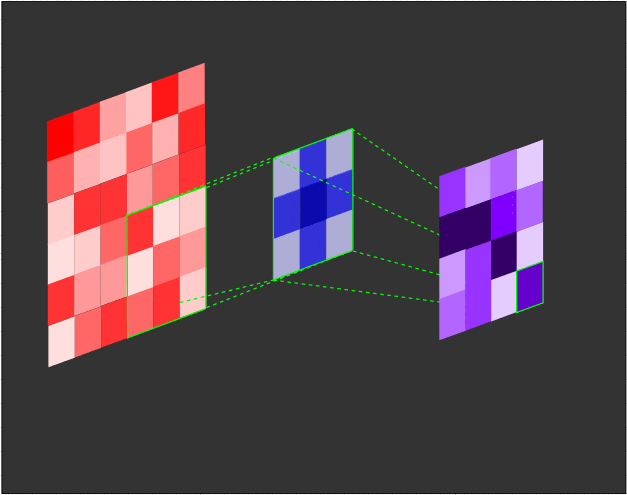
在每个卷积步骤中计算点积的示意图:
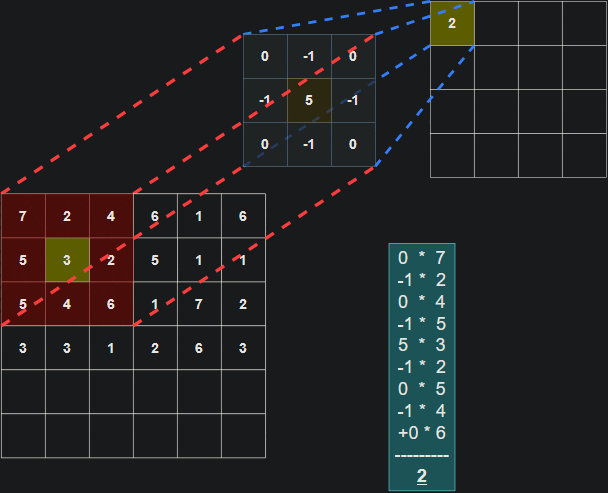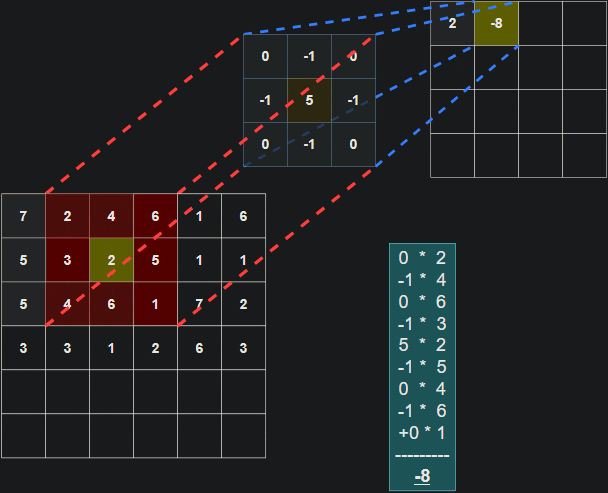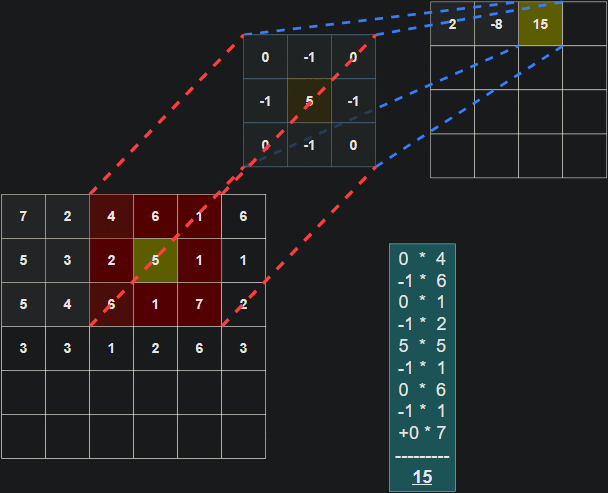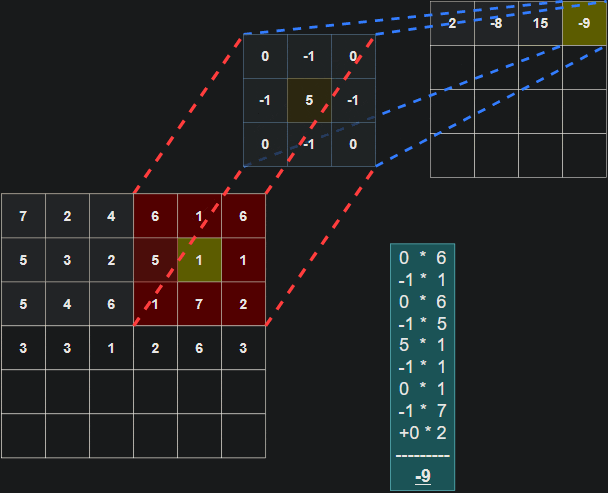
需要注意的是,滤波器的权重在每个步骤中保持不变。就像在全连接层中的权重一样,这些值在训练过程中进行学习,并通过反向传播在每个训练迭代后进行调整。
这些示意图并不能完全展示所有情况。当训练一个卷积神经网络时,模型不仅在卷积层中使用一个滤波器是很常见的。通常在一个卷积层中会有32或64个滤波器,实际上,在本教程中,我们将在一个层中使用多达96个滤波器来构建我们的模型。
最后,虽然滤波器的权重是需要训练的主要参数,但卷积神经网络也有一些可以调整的超参数:
层中的滤波器数量
滤波器的维度
步幅(每一步滤波器移动的像素数)
填充(滤波器如何处理图像边界)
我们不会详细讨论这些超参数,因为本文不旨在全面介绍卷积神经网络,但这些是需要注意的重要因素。
池化层
池化层与卷积层类似,都是通过滤波器对输入数据(通常是从卷积层输出的特征图)进行卷积运算。
然而,池化层的功能不是特征检测,而是降低维度或降采样。最常用的两种池化方法是最大池化和平均池化。在最大池化中,滤波器在输入上滑动,并在每一步选择具有最大值的像素作为输出。在平均池化中,滤波器输出滤波器所经过像素的平均值。
全连接层
最后,在卷积和池化层之后,卷积神经网络通常会有全连接层,这些层将在图像分类任务中执行分类,就像本教程中的任务一样。
现在,我们已经了解了卷积神经网络的结构和操作方式,让我们开始进行有趣的部分,在PyTorch中训练我们自己的CNN模型!
设置
与本教程的第一部分一样,我建议使用Google Colab进行跟随,因为你的Python环境已经安装了PyTorch和其他库,并且有一个GPU可以用于训练模型。
因此,如果你使用的是Colab,请确保使用GPU,方法是转到“运行时”(Runtime)并点击“更改运行时类型”。
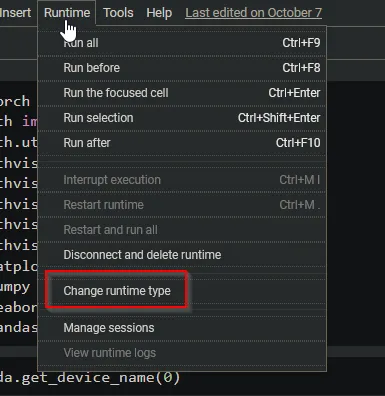
在对话框中选择GPU并保存。
现在你可以在Colab中使用GPU了,并且我们可以使用PyTorch验证你的设备。
因此,首先,让我们处理导入部分:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.utils import make_grid
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torchvision import utils
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd如果你想检查你可以访问的GPU是什么,请键入并执行torch.cuda.get_device_name(0),你应该会看到设备输出。Colab有几种不同的GPU选项可供选择,因此你的输出将根据你所能访问的内容而有所不同,但只要你在运行此代码时没有看到“RuntimeError: No CUDA GPUs are available”错误,那么你正在使用GPU!
我们可以将GPU设备设置为device,以便在开发模型时将其分配给GPU,如果没有CUDA GPU设备可用,我们也可以使用CPU。
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
# cuda接下来,让我们设置一个随机种子,以便我们的结果是可重现的,并下载我们的训练数据并设置一个转换,将图像转换为张量并对数据进行归一化。
torch.manual_seed(42)transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)training_data = CIFAR10(root="cifar",
train = True,
download = True,
transform=transform)
test_data = CIFAR10(root = "cifar",
train = False,
download = True,
transform = transform)一旦下载完成,让我们查看数据集中的类别:
classes = training_data.classes
classes
#['airplane',
# 'automobile',
# 'bird',
# 'cat',
# 'deer',
# 'dog',
# 'frog',
# 'horse',
# 'ship',
# 'truck']最后,让我们设置训练和测试数据加载器:
batch_size = 24
train_dataloader = DataLoader(training_data, batch_size=batch_size, shuffle=True, num_workers=0)
test_dataloader = DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=0)
for X, y in train_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
#Shape of X [N, C, H, W]: torch.Size([24, 3, 32, 32])
#Shape of y: torch.Size([24]) torch.int64现在我们准备构建我们的模型!
构建CNN
在PyTorch中,nn.Conv2d是用于图像输入数据的卷积层。Conv2d的第一个参数是输入中的通道数,在我们的第一层卷积层中,我们将使用3,因为彩色图像将有3个颜色通道。
在第一个卷积层之后,该参数将取决于前一层输出的通道数。第二个参数是在该层中卷积操作输出的通道数。这些通道是卷积层介绍中讨论的特征图。最后,第三个参数将是卷积核或滤波器的大小。这可以是一个整数值,如3表示3x3的卷积核,或者是一个元组,如(3,3)。因此,我们的卷积层将采用nn.Conv2d(in_channels, out_channels, kernel_size)的形式。还可以添加其他可选参数,包括(但不限于)步幅(stride)、填充(padding)和膨胀(dilation)。在我们的卷积层conv4中,我们将使用stride=2。
在一系列卷积层之后,我们将使用一个扁平化层将特征图扁平化,以便能够输入到线性层中。为此,我们将使用nn.Flatten()。我们可以使用nn.BatchNorm1d()应用批量归一化,并需要将特征数作为参数传递。
最后,我们使用nn.Linear()构建线性的全连接层,第一个参数是特征数,第二个参数是指定输出特征数。
因此,要开始定义我们模型的基本架构,我们将定义一个ConvNet类,该类继承自PyTorch的nn.Module类。然后,我们可以将每个层定义为类的属性,并根据需要构建它们。
一旦我们指定了层的架构,我们可以通过创建一个forward()方法来定义模型的流程。我们可以使用激活函数包装每个层,在我们的情况下,我们将使用relu。我们可以通过传递前一层和p(元素被丢弃的概率,缺省值为0.5)在层之间应用dropout。
最后,我们创建模型对象并将其附加到设备上,以便可以在GPU上训练。
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
self.d1 = 0.1
self.conv1 = nn.Conv2d(3, 48, 3)
self.conv2 = nn.Conv2d(48, 48, 3)
self.conv3 = nn.Conv2d(48, 96, 3)
self.conv4 = nn.Conv2d(96, 96, 3, stride=2)
self.flat = nn.Flatten()
self.batch_norm = nn.BatchNorm1d(96 * 12 * 12)
self.fc1 = nn.Linear(96 * 12 * 12, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.relu(self.conv2(x))
x = nn.functional.dropout(x, self.d1)
x = nn.functional.relu(self.conv3(x))
x = nn.functional.relu(self.conv4(x))
x = nn.functional.dropout(x, 0.5)
x = self.flat(x)
x = nn.functional.relu(self.batch_norm(x))
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
model = ConvNet().to(device)训练和测试函数
如果你完成了本教程的第一部分,我们的训练和测试函数将与之前创建的函数相同,只是在训练方法中返回损失,而在测试方法中返回损失和正确数量,以便在调整超参数时使用。
# Train Method
def train(dataloader, model, loss_fn, optimizer, verbose=True):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if verbose == True:
if batch % 50 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
return loss# Test Method
def test(dataloader, model, loss_fn, verbose=True):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
if verbose == True:
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
return test_loss, correct # For reporting tuning results/ early stopping最后,在基本模型训练之前,我们定义损失函数和优化器。
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)让我们训练模型。
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")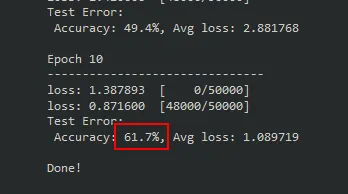
仅经过10个epochs,61.7%的性能比我们训练的全连接模型要好得多!很明显,CNN更适合用于图像分类,但我们可以通过延长训练时间和调整超参数来进一步提高性能。
在进行这些之前,让我们快速看看模型内部是什么样子。请记住,滤波器的像素是我们模型中可训练的参数。这不是训练图像分类模型的必要步骤,也不会得到太多有用的信息,但是了解模型内部的情况还是挺有意思的。
可视化滤波器
我们可以编写一个函数来绘制模型中指定层的滤波器。我们只需要指定要查看的层,并将其传递给我们的函数。
def visualizeTensor(tensor, ch=0, all_kernels=False, nrow=8, padding=1):
n,c,w,h = tensor.shape
if all_kernels:
tensor = tensor.view(n*c, -1, w, h)
elif c != 3:
tensor = tensor[:,ch,:,:].unsqueeze(dim=1)
rows = np.min((tensor.shape[0] // nrow + 1, 64))
grid = utils.make_grid(tensor,
nrow=nrow,
normalize=True,
padding=padding)
grid = grid.cpu() # back to cpu for numpy and plotting
plt.figure( figsize=(nrow,rows) )
plt.imshow(grid.numpy().transpose((1, 2, 0)))让我们来看看第一个卷积层(conv1)中的滤波器是什么样子,因为这些滤波器直接应用于图像。
filter = model.conv1.weight.data.clone()
visualizeTensor(filter)
plt.axis('off')
plt.ioff()
plt.show下面是输出,包含了我们的conv1卷积层中48个滤波器的可视化。我们可以看到每个滤波器都是一个不同值或颜色的3x3张量。
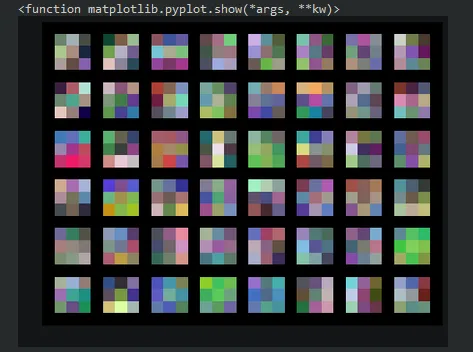
如果我们的滤波器是5x5的,我们会在绘图中看到以下差异。请记住,使用nn.Conv2d我们可以使用第三个参数更改滤波器的大小,因此如果我们想要一个5x5的滤波器,conv1将如下所示:
self.conv1 = nn.Conv2d(3, 48, 5) # New Kernel Size如果我们用新的5x5滤波器重新训练模型,输出将如下所示:
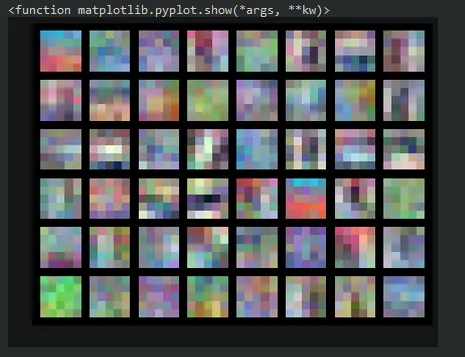
如我之前提到的,这里并没有太多有用的信息,但还是很有趣可以看到这些。
超参数优化
在本教程中,我们将调整的超参数是卷积层中的滤波器数量以及线性层中的神经元数量。当前这些值在我们的模型中是硬编码的,所以为了使它们可调整,我们需要使我们的模型可配置。
我们可以在模型的__init__方法中使用参数(c1、c2和l1),并使用这些值创建模型的层,在调整过程中将动态传递这些值。
class ConfigNet(nn.Module):
def __init__(self, l1=256, c1=48, c2=96, d1=0.1):
super().__init__()
self.d1 = d1
self.conv1 = nn.Conv2d(3, c1, 3)
self.conv2 = nn.Conv2d(c1, c1, 3)
self.conv3 = nn.Conv2d(c1, c2, 3)
self.conv4 = nn.Conv2d(c2, c2, 3, stride=2)
self.flat = nn.Flatten()
self.batch_norm = nn.BatchNorm1d(c2 * 144)
self.fc1 = nn.Linear(c2 * 144, l1)
self.fc2 = nn.Linear(l1, 10)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.relu(self.conv2(x))
x = nn.functional.dropout(x, self.d1)
x = nn.functional.relu(self.conv3(x))
x = nn.functional.relu(self.conv4(x))
x = nn.functional.dropout(x, 0.5)
x = self.flat(x)
x = nn.functional.relu(self.batch_norm(x))
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
model = ConfigNet().to(device)当然,我们不仅限于调整这些超参数。事实上,学习率和批量大小通常也包括在要调整的超参数列表中,但由于我们将使用网格搜索,为了保持训练时间合理,我们必须大大减少可调整的变量数量。
接下来,让我们为搜索空间定义一个字典,并保存给我们最佳结果的参数。由于我们使用网格搜索进行优化,将使用每个超参数组合的所有组合。
你可以轻松地向每个超参数的列表中添加更多值,但每个额外的值都会大大增加运行时间,因此建议从以下值开始以节省时间。
search_space = {
'c1': [48, 96],
'c2': [96, 192],
'l1': [256, 512],
}
best_results = {
'c1': None,
'c2': None,
'l1': None,
'loss': None,
'acc': 0
}提前停止
优化过程中一个重要的组成部分是使用提前停止。由于我们将进行多次训练运行,每次训练运行时间都很长,如果训练性能没有改善,我们将希望提前结束训练。继续训练一个没有改善的模型是没有意义的。
实质上,我们将在每个时期之后跟踪模型产生的最低损失。然后,我们定义一个容差,指定模型必须在多少个时期内达到更好的损失。如果在指定的容差内没有实现更低的损失,将终止该运行的训练,并继续下一个超参数组合。
如果你像我一样,喜欢检查训练过程,可以设置self.verbose = True来记录控制台上的更新,并查看提前停止计数器增加的情况。你可以在此处硬编码到EarlyStopping类中,也可以在优化过程中实例化EarlyStopping对象时更改verbose值。
class EarlyStopping():
def __init__(self, tolerance=5, verbose=False, path="cifar-tune.pth"):
self.tolerance = tolerance
self.counter = 0
self.early_stop = False
self.lowest_loss = None
self.verbose = verbose
self.path = path
def step(self, val_loss):
if (self.lowest_loss == None):
self.lowest_loss = val_loss
torch.save(model.state_dict(), self.path)
elif (val_loss < self.lowest_loss):
self.lowest_loss = val_loss
self.counter = 0
torch.save(model.state_dict(), self.path)
else:
if self.verbose:
print("Early stop counter: {}".format(self.counter+1))
self.counter +=1
if self.counter >= self.tolerance:
self.early_stop = True
if self.verbose:
print('Early stopping executed.')图像增强
在设置超参数优化方法之前,我们还有最后一件事要做,以提取出一些额外的性能并避免在训练数据上过度拟合。图像增强是一种将随机变换应用于图像的技术,从本质上讲,它会创建“新的”人工数据。这些变换可以是以下几种:
旋转图像几度
水平/垂直翻转图像
裁剪
轻微的亮度/色调变化
随机缩放
包含这些随机变换将提高模型的泛化能力,因为增强后的图像将与原始图像类似,但不同。内容和模式将保持不变,但数组表示将有所不同。
PyTorch通过torchvision.transforms模块使图像增强变得很容易。如果我们想要应用多个变换,可以使用Compose将它们链接在一起。
需要记住的一点是,图像增强对每个变换需要一点计算量,并且这些计算量应用于数据集中的每个图像。将许多不同的随机变换应用于我们的数据集将增加训练时间。
因此,现在让我们限制变换的数量,以便训练时间不会太长。如果你想添加更多变换,请查看PyTorch关于转换和增强图像的文档,然后将它们添加到Compose列表中。
选择了增强变换之后,我们可以像应用规范化和将图像转换为张量一样将它们应用于数据集。
# Augment Images for the train set
augmented = transforms.Compose([
transforms.RandomRotation(20),
transforms.ColorJitter(brightness=0.2, hue=0.1),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Standard transformation for validation set
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
training_data = CIFAR10(root="cifar",
train = True,
download = True,
transform=augmented)
test_data = CIFAR10(root = "cifar",
train = False,
download = True,
transform = transform)现在我们已经在训练数据上设置了图像增强,我们准备设置我们的超参数优化方法。
定义优化方法
我们可以创建一个类(HyperSearch),其中包含超参数值配置、详细报告设置、报告列表(以便在优化完成后查看每个配置的表现)的属性,以及一个变量来存储具有最佳性能的配置。
class HyperSearch():
def __init__(self, config, verbose=True):
self.config = config
self.verbose = verbose
self.report_list = []
self.best_results = { 'c1': None,
'c2': None,
'l1': None,
'loss': None,
'acc': 0
}接下来,我们可以创建一个方法(仍在HyperSearch类中),以执行网格搜索,并对每个超参数组合进行训练运行。首先,我们将使用tolerance=3配置EarlyStopping,并设置它保存每个超参数组合的权重。如果我们将self.verbose设置为True,我们可以在控制台中看到当前正在训练的超参数组合。
之后,我们使用我们设计的CoinfigNet模型定义我们的模型,并传递l1、c1和c2的值,同时选择损失函数和优化器,并设置我们的训练和验证DataLoader。由于我们没有时间也没有意愿完全训练每个组合,所以我们将保持较低的时期数。目标是了解哪种组合在对数据集进行分类时效果最好,然后我们可以将该模型完全训练,以查看它在完整的训练周期中的性能。
# Optimization Method
def optimize(self):
for l1 in self.config['l1']:
for c1 in self.config['c1']:
for c2 in self.config['c2']:
early_stopping = EarlyStopping(tolerance=3, verbose=False, path="{}-{}-{}.pth".format(c1, c2, l1))
if self.verbose == True:
print('Conv1: {} | Conv2: {} | Lin1: {}'.format(str(c1), str(c2), str(l1)))
model = ConfigNet(l1=l1, c1=c1, c2=c2).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lrate)
train_dataloader = DataLoader(training_data, batch_size=batch_sz, shuffle=True, num_workers=0)
test_dataloader = DataLoader(test_data, batch_size=batch_sz, shuffle=True, num_workers=0)现在,我们定义训练循环,大部分与之前相同,只是现在我们将保存train和test方法的损失,以便early_stopping可以跟踪训练进展(或缺乏进展)。最后,在每个时期之后,将结果保存到报告中,并更新最佳损失的值。
epochs = 10
for t in range(epochs):
if self.verbose == True:
print(f"Epoch {t+1}\n-------------------------------")
train_loss = train(train_dataloader, model, loss_fn, optimizer, verbose=self.verbose)
test_loss, test_acc = test(test_dataloader, model, loss_fn, verbose=self.verbose)
# Early Stopping
early_stopping.step(test_loss)
if early_stopping.early_stop:
break
print("Done!")
self.append_to_report(test_acc, test_loss, c1, c2, l1)
if self.best_results['loss'] == None or test_loss < self.best_results['loss']:
if self.verbose == True:
print("UPDATE: Best loss changed from {} to {}".format(self.best_results['loss'], test_loss))
self.best_results.update({
'c1': c1,
'c2': c2,
'loss': test_loss,
'l1': l1,
'acc': test_acc
})
self.report()我们可以将整个超参数优化周期的结果输出到一个漂亮的表格中,在表格中,我们可以看到每次运行的超参数配置,以及相应的损失和准确率。
def report(self):
print("""
|-----------------------------------------------------------------------------------------------------|
| |
| Report for hyperparameter optimization |
| |
|-----------------------------------------------------------------------------------------------------|
| RUN | PERFORMANCE | CONFIGURATION |
|------------|--------------------------------------|-------------------------------------------------|""")
for idx, item in enumerate(self.report_list):
print("| Run {:02d} | Accuracy: {:.2f}% | Loss: {:.2f} | Conv-1: {} | Conv-2: {:3} | Linear-1: {:>4} |".format(idx,
item[0]*100,
item[1],
item[2],
item[3],
item[4]))
print("|------------|---------------------|----------------|--------------|---------------|------------------|")
print("\nBest Results | Accuracy: {:.2f}% | Loss: {:.2f} | Conv-1: {} | Conv-2: {} | Linear-1: {:>4} |".format(self.best_results['acc']*100,
self.best_results['loss'],
self.best_results['c1'],
self.best_results['c2'],
self.best_results['l1']))
def append_to_report(self, acc, loss, c1, c2, l1):
list_set = (acc, loss, c1, c2, l1)
self.report_list.append(list_set)因此,将所有这些代码放在一起,我们的HyperSearch类应该如下所示:
class HyperSearch():
def __init__(self, config, verbose=True):
self.config = config
self.verbose = verbose
self.report_list = []
self.best_results = { 'c1': None,
'c2': None,
'l1': None,
'loss': None,
'acc': 0
# 'd1': None,
# 'lr': None,
# 'bsz': None,
}
# Optimization Method
def optimize(self):
for l1 in self.config['l1']:
for c1 in self.config['c1']:
for c2 in self.config['c2']:
early_stopping = EarlyStopping(tolerance=3, verbose=False, path="{}-{}-{}.pth".format(c1, c2, l1))
if self.verbose == True:
print('Conv1: {} | Conv2: {} | Lin1: {}'.format(str(c1), str(c2), str(l1)))
model = ConfigNet(l1=l1, c1=c1, c2=c2).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lrate)
train_dataloader = DataLoader(training_data, batch_size=batch_sz, shuffle=True, num_workers=0)
test_dataloader = DataLoader(test_data, batch_size=batch_sz, shuffle=True, num_workers=0)
epochs = 10
for t in range(epochs):
if self.verbose == True:
print(f"Epoch {t+1}\n-------------------------------")
train_loss = train(train_dataloader, model, loss_fn, optimizer, verbose=self.verbose)
test_loss, test_acc = test(test_dataloader, model, loss_fn, verbose=self.verbose)
# Early Stopping
early_stopping.step(test_loss)
if early_stopping.early_stop:
break
print("Done!")
self.append_to_report(test_acc, test_loss, c1, c2, l1)
if self.best_results['loss'] == None or test_loss < self.best_results['loss']:
if self.verbose == True:
print("UPDATE: Best loss changed from {} to {}".format(self.best_results['loss'], test_loss))
self.best_results.update({
'c1': c1,
'c2': c2,
'loss': test_loss,
'l1': l1,
'acc': test_acc
})
self.report()
def report(self):
print("""
|-----------------------------------------------------------------------------------------------------|
| |
| Report for hyperparameter optimization |
| |
|-----------------------------------------------------------------------------------------------------|
| RUN | PERFORMANCE | CONFIGURATION |
|------------|--------------------------------------|-------------------------------------------------|""")
for idx, item in enumerate(self.report_list):
print("| Run {:02d} | Accuracy: {:.2f}% | Loss: {:.2f} | Conv-1: {} | Conv-2: {:3} | Linear-1: {:>4} |".format(idx,
item[0]*100,
item[1],
item[2],
item[3],
item[4]))
print("|------------|---------------------|----------------|--------------|---------------|------------------|")
print("\nBest Results | Accuracy: {:.2f}% | Loss: {:.2f} | Conv-1: {} | Conv-2: {} | Linear-1: {:>4} |".format(self.best_results['acc']*100,
self.best_results['loss'],
self.best_results['c1'],
self.best_results['c2'],
self.best_results['l1']))
def append_to_report(self, acc, loss, c1, c2, l1):
list_set = (acc, loss, c1, c2, l1)
self.report_list.append(list_set)调整
现在我们可以调整超参数了!通过使用%%time,在整个调整过程执行完成后,我们可以看到整个过程花费的时间。让我们保持学习率lrate=0.001和批量大小batch_sz=512,用我们之前定义的search_space实例化HyperSearch类,将verbose设置为True或False(根据你的喜好),然后调用optimize()方法开始调优。
注意:在我的机器上(NVIDIA RTX 3070),完成这个过程大约需要50分钟,所以如果你使用的是Colab上提供的GPU,可能需要大致相同的时间。
%%time
lrate=0.001
batch_sz=512
hyper_search = HyperSearch(search_space, verbose=True)
hyper_search.optimize()完成整个优化周期后,你应该得到一个如下所示的表格:
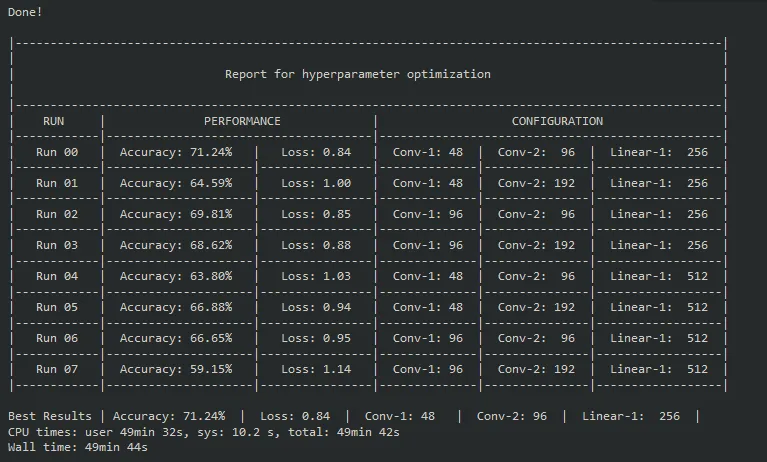
结果
从表格中可以看出,最佳结果来自于Run 00,它具有c1=48、c2=96和l1=256。损失为0.84,准确率为71.24%,这是一个不错的改进,尤其是考虑到只有10个时期!
因此,现在我们已经找到了在10个时期内性能最佳的超参数,让我们对这个模型进行微调!我们可以在更多的时期内训练它,并稍微降低学习率,以尝试获得更好的性能。
所以首先,让我们定义我们想要使用的模型,并设置批量大小和学习率:
class ConfigNet(nn.Module):
def __init__(self, l1=256, c1=48, c2=96, d1=0.1):
super().__init__()
self.d1 = d1
self.conv1 = nn.Conv2d(3, c1, 3)
self.conv2 = nn.Conv2d(c1, c1, 3)
self.conv3 = nn.Conv2d(c1, c2, 3)
self.conv4 = nn.Conv2d(c2, c2, 3, stride=2)
self.flat = nn.Flatten()
self.batch_norm = nn.BatchNorm1d(c2 * 144)
self.fc1 = nn.Linear(c2 * 144, l1)
self.fc2 = nn.Linear(l1, 10)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.relu(self.conv2(x))
x = nn.functional.dropout(x, self.d1)
x = nn.functional.relu(self.conv3(x))
x = nn.functional.relu(self.conv4(x))
x = nn.functional.dropout(x, 0.5)
x = self.flat(x)
x = nn.functional.relu(self.batch_norm(x))
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
model = ConfigNet().to(device)
model = ConfigNet(l1=256, c1=48, c2=96, d1=0.1).to(device)
batch_sz = 512
lrate = 0.0008最后,我们可以将时期数设置为50,并更改保存权重的路径。让训练周期运行起来,如果进展停滞,early stopping将终止训练。
%%time
early_stopping = EarlyStopping(tolerance=6, verbose=True, path="cifar-optimized-test.pth")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lrate)
train_dataloader = DataLoader(training_data, batch_size=batch_sz, shuffle=True, num_workers=0)
test_dataloader = DataLoader(test_data, batch_size=batch_sz, shuffle=True, num_workers=0)
epochs = 50
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loss = train(train_dataloader, model, loss_fn, optimizer)
test_loss, test_acc = test(test_dataloader, model, loss_fn)
# Early Stopping
early_stopping.step(test_loss)
if early_stopping.early_stop:
break
print("Done!")Early stopping应该在达到50个时期之前终止训练,并且应该达到约77%的准确率。
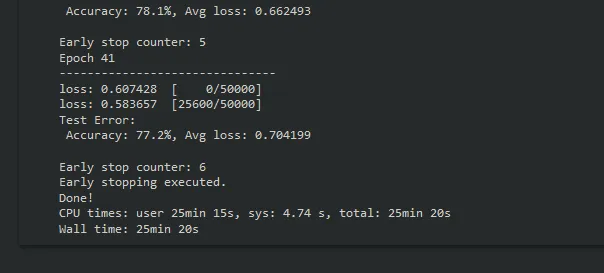
现在,我们已经调整了超参数,找到了最佳配置,并对该模型进行了微调,现在是对模型的性能进行更深入评估的时候了。
模型评估
在这种情况下,我们的测试数据集实际上是我们的验证数据。我们将重复使用我们的验证数据来评估模型,但通常在超参数调整之后,你将希望使用真实的测试数据进行模型评估。
让我们加载优化后的模型,准备没有应用任何图像增强的test_dataloader,并运行test()来进行评估。
model = ConfigNet(l1=256, c1=48, c2=96, d1=0.1).to(device)
model.load_state_dict(torch.load("cifar-optimized-test.pth"))
loss_fn = nn.CrossEntropyLoss()
batch_sz = 512
test_dataloader = DataLoader(test_data, batch_size=batch_sz, shuffle=False, num_workers=0)
classes = test_data.classestest_loss, test_acc = test(test_dataloader, model, loss_fn)这应该会输出准确率和损失:

总体性能不错,但每个类别的性能对我们更有用。以下代码将输出数据集中每个类别的模型准确率:
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
with torch.no_grad():
for data in test_dataloader:
images, labels = data
outputs = model(images.to(device))
_, predictions = torch.max(outputs, 1)
for label,prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class {classname:5s}: {accuracy:.1f}%')执行此代码块将给出以下输出:
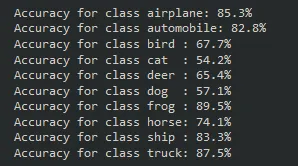
我们的模型在飞机、汽车、青蛙、船和卡车类别上表现非常好。有趣的是,它在狗和猫这两个类别上遇到了最大的困难,这也是前面这个系列中完全连接模型面临的最棘手的类别。
混淆矩阵
我们可以通过混淆矩阵进一步了解模型的性能。让我们设置一个混淆矩阵,并进行可视化。
num_classes = 10
confusion_matrix = torch.zeros(num_classes, num_classes)
with torch.no_grad():
for i, (inputs, classes) in enumerate(test_dataloader):
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for t, p in zip(classes.view(-1), preds.view(-1)):
confusion_matrix[t.long(), p.long()] += 1通过定义混淆矩阵,我们可以使用Seaborn库来帮助我们可视化它。
plt.figure(figsize=(15,10))
cf_dataframe = pd.DataFrame(np.array(confusion_matrix, dtype='int'), index=test_data.classes, columns=test_data.classes)
heatmap = sns.heatmap(cf_dataframe, annot=True, fmt='g')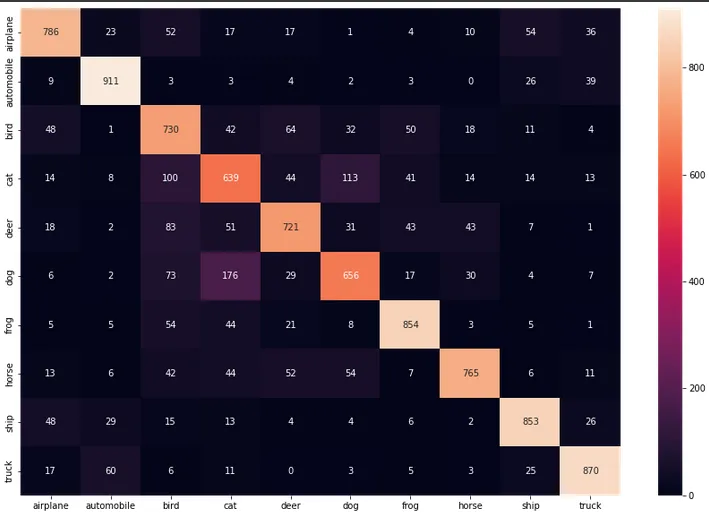
这个表格的两个维度是“实际”和“预测”值。我们希望大部分数据都在中心对角线上对齐,即实际和预测属于同一类别。从错误的预测中,我们可以看到模型经常混淆猫和狗,这两个类别的准确率最低。
总数看起来不错,但每个类别的精确度和召回率将为我们提供更有意义的数据。让我们首先看一下每个类别的召回率。
每个类别的召回率
cf = np.array(confusion_matrix)
norm_cf = cf / cf.astype(float).sum(axis=1)
plt.figure(figsize=(15,10))
cf_dataframe = pd.DataFrame(np.array(norm_cf, dtype='float64'), index=test_data.classes, columns=test_data.classes).astype(float)
heatmap = sns.heatmap(cf_dataframe, annot=True)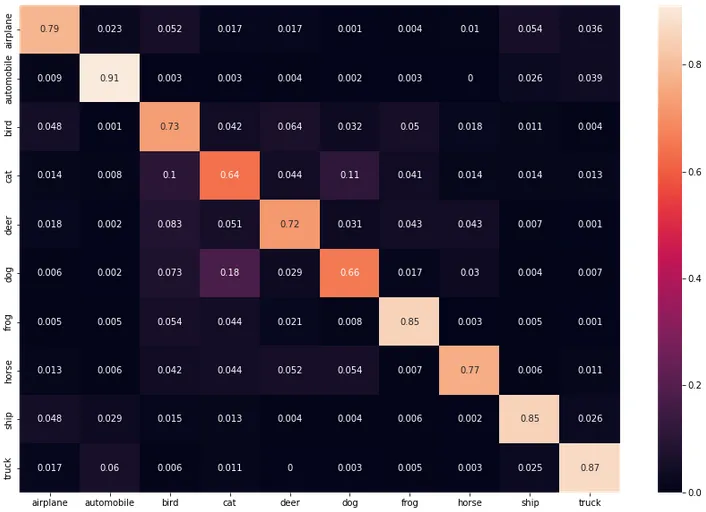
每个类别的精确度
cf = np.array(confusion_matrix)
norm_cf = cf / cf.astype(float).sum(axis=0)
plt.figure(figsize=(15,10))
cf_dataframe = pd.DataFrame(np.array(norm_cf, dtype='float64'), index=test_data.classes, columns=test_data.classes).astype(float)
heatmap = sns.heatmap(cf_dataframe, annot=True)
样本模型预测
最后,让我们给模型提供几张图像,并检查它的预测结果。让我们创建一个函数来准备我们的图像数据以供查看:
def imshow(img):
img = img / 2 + .05 # revert normalization for viewing
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1,2,0)))
plt.show()现在,我们可以准备我们的测试数据,并创建另一个函数来获取n个样本预测。
test_data = CIFAR10(root = "cifar",
train = False,
transform = transforms.ToTensor())
classes = test_data.classesdef sample_predictions(n = 4):
test_dataloader = DataLoader(test_data, batch_size=n, shuffle=True, num_workers=0)
dataiter = iter(test_dataloader)
images, labels = dataiter.next()
outputs = model(images.to(device))
_, predicted = torch.max(outputs, 1)
imshow(make_grid(images))
print('[Ground Truth | Predicted]:\n', ' '.join(f'[{classes[labels[j]]:5s} | {classes[predicted[j]]:5s}]\n' for j in range(n)))调用该函数,传递你想要采样的图像数量。输出将给出每个图像的实际类别和预测类别,从左到右。
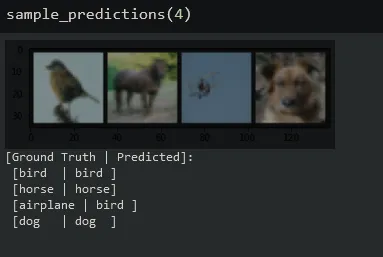
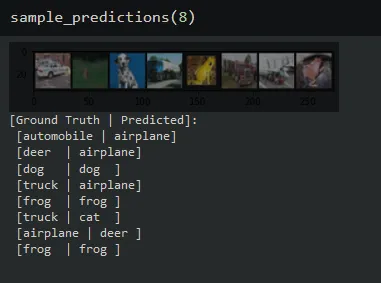
利用经过超参数调优和图像增强的卷积网络,我们成功提高了在CIFAR-10数据集上的性能!感谢你的阅读,希望你对PyTorch和用于图像分类的卷积神经网络有所了解。这里提供了包含所有代码的完整笔记本在GitHub上可用。
https://github.com/florestony54/intro-to-pytorch-2/blob/main/pytorch2_2.ipynb
感谢阅读!
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓