写在前面:
虽说自己肯定对外宣称自己是搞CV的,但是其实在自己接近两年半(🐔)的研究生生涯中,也没有熟练掌握过很多个CV领域的模型,或者说是CV领域的概念。我认为这个东西是必须得补的,不然作为CV算法工程师是肯定要被淘汰的。目前激发自己研究和学习热情的最好方式还是经营自己小小的博客,因此想开一个系列介绍自己在学习CV模型中收获与感悟,更重要的是罗列学习资源,以便日后读者或者我自己能够快速把这个学习过的模型重拾起来。
参考资料:
[论文链接]
[论文源代码]
[AdaIN补充材料]
1. 研究动机 (Motivation)
在Diffusion Model出现以前,GAN应当是深度生成模型中占据统治地位的,与其对标的是变分自编码器VAE。虽然普遍认为GAN的生成质量会比VAE好一些,但是二者其实是不分伯仲的。StyleGAN这篇文章是发表在CVPR2019上,它致力于分析和理解GAN是如何完成图片合成过程的。此前的GAN,其generator完全是一个黑匣子,为什么GAN生成的图片会有随机生成的特征(我的理解,例如:其他地方见到的人出现在另一张图片的背景里),GAN的latent space究竟控制了哪些东西,有哪些性质,这些我们都没有办法解释。本论文就是想探究这个GAN的可解释性的。
2. 挑战(Challenge)
考虑的是一个比较novel的方面,所以challenge这点没有写很多。
3. 点子(Idea)
上面说到StyleGAN对于GAN的主要创新在于Generator,而本论文对于Generator的创新又主要集中在latent space。一般的Generator的输入不是别的,就是在一个latent space中采样的一个z。然而,由于对z的可解释性很差,特征会在隐空间中互相缠绕,牵一发而动全身,我们想做的就是让图片的不同属性在特征空间中解耦。看一下作者的表述:
The input latent space must follow the probability density of the training data, and we argue that this leads to some degree of unavoidable entanglement. Our intermediate latent space is free from that restriction and is therefore allowed to be disentangled.
作者的解决方法就是不直接把latent code输入到generator中,而是首先把latent code嵌入到一个中间的latent space。。。更多的理论分析... 倒是没有,但是他说只要这么做了就能解决隐空间中特征纠缠的问题。
4. 方法(Method)
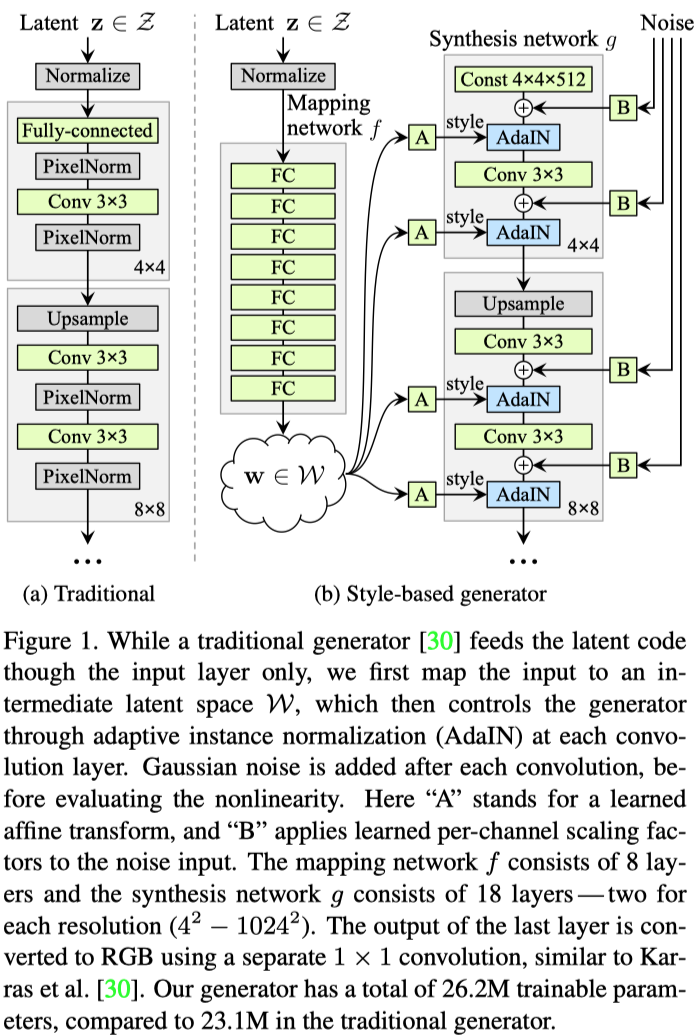
主要的方法框图就是这样,z不直接作为generator的输入,而是先转换成w,z到w的过程是一系列MLP,记为函数f。而从w输入到主要generator的过程是首先经过了一个仿射变换生成$(\mathbf{y}_s,\mathbf{y}_b)$,然后经过了一个adaptive instance normalization(AdaIN)的操作。这里我有如下三点疑问:
- 文章在多处提到:"Our generator starts from a learned constant input",这个constant是什么?是z吗?到底是啥?
- Noise输入一定要加吗?为什么一定要加一个高斯噪声呢?
- 这个仿射变换A是什么?既然w的维度是512,经过一个仿射变化,它是如何在AdaIN中参与运算的?AdaIN公式如下:其中x为卷积那块儿的主要特征。
$$AdaIN(\mathbf{x}_i,\mathbf{y})=\mathbf{y}_{s,i}\frac{\mathbf{x}_i-\mu(\mathbf{x}_i)}{\sigma(\mathbf{x}_i)}+\mathbf{y}_{b,i}$$
下面一个一个进行解答:
1. 指的不是z,一般的GAN都有一个input layer把z转换成一个feature map,然后进行一系列upsample之类的出图,但是本论文发现其实把input layer删了直接替换成一个可学习的constant feature map,仅仅靠style就能生成很好的结果。下面是原文:
We then improve this new baseline further by adding the mapping network and AdaIN operations (C), and make a surprising observation that the network no longer benefits from feeding the latent code into the first convolution layer. We therefore simplify the architecture by removing the traditional input layer and starting the image synthesis from a learned 4 × 4 × 512 constant tensor (D). We find it quite remarkable that the synthesis network is able to produce meaningful results even though it receives input only through the styles that control the AdaIN operations.
2. 作者通过实验发现显式地加入噪声输入可以帮助生成随机的照片细节,并用实验证明了这一点,具体为什么这样设计则在Section3.2和3.3讨论了很多,感兴趣的读者可以自己去阅读一下。主要的思想是这样的(我的理解):在自然图片中存在很多随机的地方,一千个人有一千张脸,但是头发呢?Generator可以在人头上绘制无数种有差分的头发,但丝毫不影响图片的质量,这是我我们想要的性质。传统的generator由于唯一的随机输入就是latent vector z,因此模型(“神经网络”)在对照片随机差分的处理是,努力地搞出一种伪随机数发生器,这一过程经常失败,因此我们加入noise的做法会有效,也正是在这一点上帮助了模型。下面是一个对比图,其中(b)是完全不加随机噪声的结果,可以看到其他的几个加了noise的结果在绘制头发上都比它要好,尤其是细节差分上:

3. 看了一些参考资料后把AdaIN弄懂了,adaptive instance normalization(AdaIN) 是一种normalization的方法,我准备写在另一个博客里分析一下常见的normalization方法。写完之后链接会挂出来。
5. 结果(Result)
1)生成质量提高了
这个就是作者发现使用了他们的generator设计后,图片的质量非但没有下降反而提高了。图表就不放了。
2)风格迁移(Style Mixing)

风格迁移涉及到两个latent vector z1, z2,mix的方法很简单,就是在进行AdaIN操作的时候时而用z1生成的w1,时而用z2生成的w2。可以看到效果还是比较明显的,比如最后一行,虽然coarse style是来自A的,控制了人脸的样子。但是fine style是来自B的,控制了发色。