目录
案例:假定我们给出字符串 ”ababcabcdabcde”作为主串, 然后给出子串: ”abcd”,现在我们需要查找子串是否在主串中 出现,出现返回主串中的第一个匹配的下标,失败返回-1 ;
1.BF算法(暴力算法)
2.KMP算法
1.next数组
2.代码中如何实现next数组;
3.代码实现
4.next数组优化
案例:假定我们给出字符串 ”ababcabcdabcde”作为主串, 然后给出子串: ”abcd”,现在我们需要查找子串是否在主串中 出现,出现返回主串中的第一个匹配的下标,失败返回-1 ;
1.BF算法(暴力算法)
思路:遍历主串,子串和当前位置的比较;匹配成功返回主串当前位置,主串遍历完成都没有匹配成功,返回-1;
代码:
#include<iostream>
#include<string>
using namespace std;
int BF(string str,string sub)
{
int strlen=str.size();
int sublen=sub.size();
//遍历主串,和子串比较
for(int i=0;i<strlen-sublen+1;i++)
{
int t=i,j=0;
for(;j<sublen;j++)
{
if(str[t++]!=sub[j])
break;
}
if(j==sublen)
return i;
}
return -1;
}
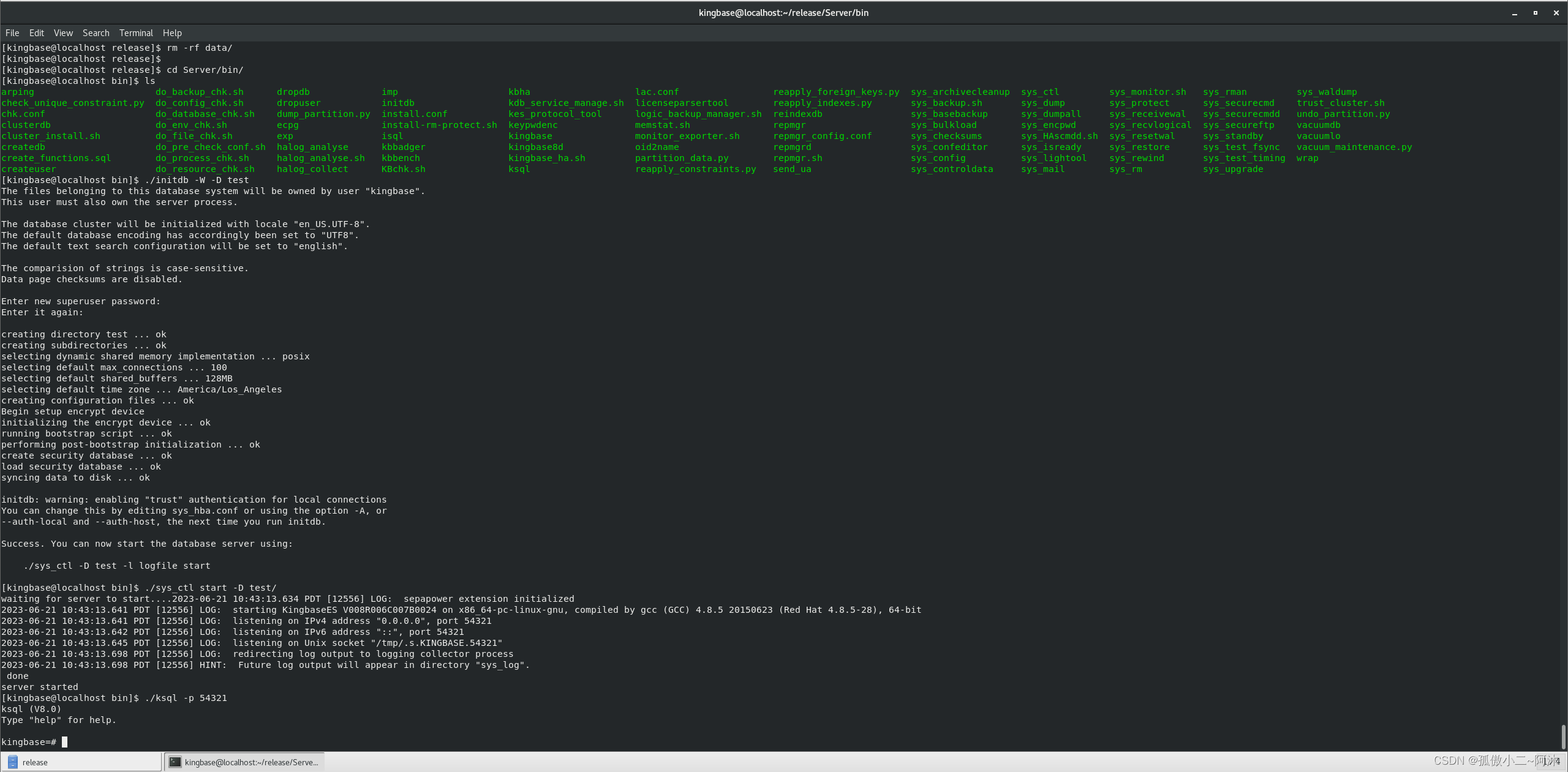
int main()
{
cout<<BF("ababcabcdabcde","abcd")<<endl;
return 0;
}结果:
时间复杂度:O(N^2) (或者O(strlen*sublen)) 空间复杂度:O(1)
2.KMP算法
概念:KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数(数组)实现,函数本身包含了模式串的局部匹配信息。KMP算法的时间复杂度O(m+n) [1] (看不懂看下面的例子)
思想:在子串和主串不匹配,两者前面的元素一定相同
- 如果主串当前位置前n个和子串的前n个相同,让子串以O(1)时间复杂度返回到相同部分的下一个位置

结合子串和主串前面元素相同,实际找子串的前n项和后n项也是一样效果
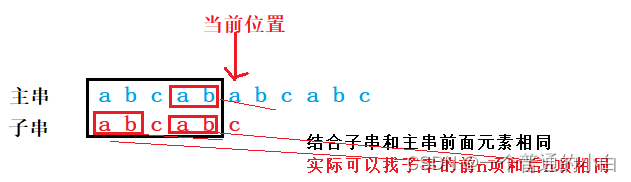
1.next数组
next数组:next【0】设置为-1,是否能在当前位置前面找到两个以第一个元素开始,(当前位置-1)元素结束的字符串,如果找得到当前位置的next【i】为第一个字符串最后一个元素(子串下标是-1的,next[i]==2, 子串实际是第3个元素);找不到next【i】=0(子串下标-1,实际是第一个元素);
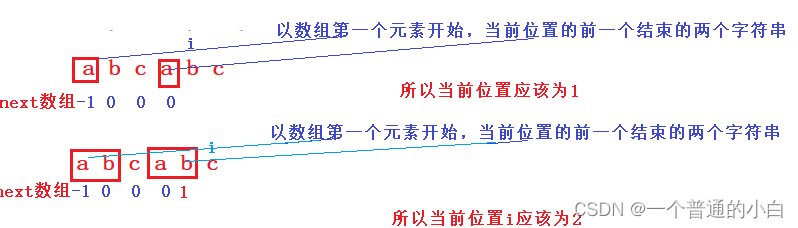
2.代码中如何实现next数组;
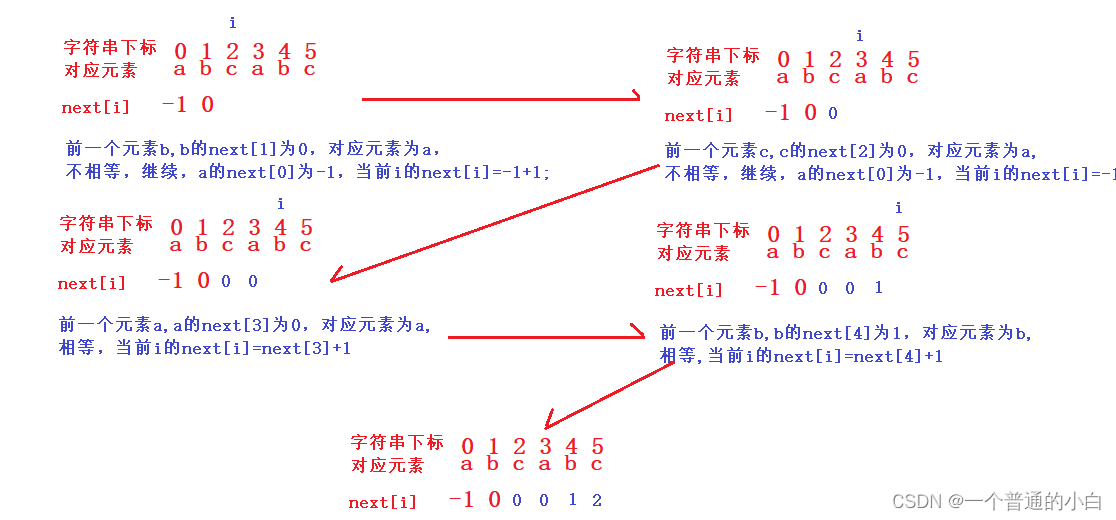
- next【0】=-1,next【1】=0(前面只有一个元素);
- 当前位置i,如果前一个位置,子串【i-1】等于子串【next【i-1】】,当前位置next【i】=next[i-1]+1;
- 子串【i-1】不等于子串【next【i-1】】,重复这个过程,一直没有等于最后会到第一个元素,next【第一个元素】值为-1,当前位置next【i】=-1+1;
3.代码实现
- KMP算法在字符串匹配中的时间复杂度:O(N) 空间复杂度:O(N)
#include<iostream>
#include<string>
#include<vector>
using namespace std;
void BuildNextFunc(vector<int> &next,string &sub,int len)
{
next[0]=-1;
if(len>1)
{
next[1]=0;
for(int i=2;i<len;i++)
{
//前一个等于特点位置
if(sub[i-1]==sub[next[i-1]])
{
next[i]=next[i-1]+1;
}
else
{
int t=next[i-1];
while(next[t]!=-1&&sub[i-1]!=sub[t])
{
t=next[t];
}
next[i]=next[t]+1;
}
}
}
}
int KMP(string str,string sub)
{
if(str.empty()||sub.empty())
return -1;
int strlen=str.size();
int sublen=sub.size();
int subi=0,stri=0;
vector<int> next(sublen);
BuildNextFunc(next,sub,sublen);
while(subi<sublen&&stri<strlen)
{
//相同继续比较下一个,回退到-1说明子串当前第一个元素就和主串不同,所以++
if(subi==-1||str[stri]==sub[subi]){
subi++;
stri++;
}
//不相同,回退到特点位置,可能回退到-1
else{
subi=next[subi];
}
}
if(subi==sublen)
return stri-subi;
return -1;
}
int main()
{
cout<<KMP("ababcabcdabcde","abcd")<<endl;
cout<<KMP("ababcabcdabcde","")<<endl;
cout<<KMP("ababcabe","abcd")<<endl;
return 0;
}4.next数组优化
next 数组的优化,即如何得到 nextval 数组:有如下串: aaaaaaaab,他的 next 数组是-1,0,1,2,3,4,5,6,7. 而修正后的数组 nextval 是-1, -1, -1, -1, -1, -1, -1, -1, 7;
伪代码:sub[i]==sub[ next[i] ],nextval[i]=nextval[ next[i] ]
为什么可行:KMP算法就是如果不相同子串到next【i】去,然后继续比较,当前位置是i,变到next【i】,i位置就是因为值和主串的值不同才到next【i】位置的,现在i和next【i】的值相同,还得比较后继续next【i】到next【next【i】】