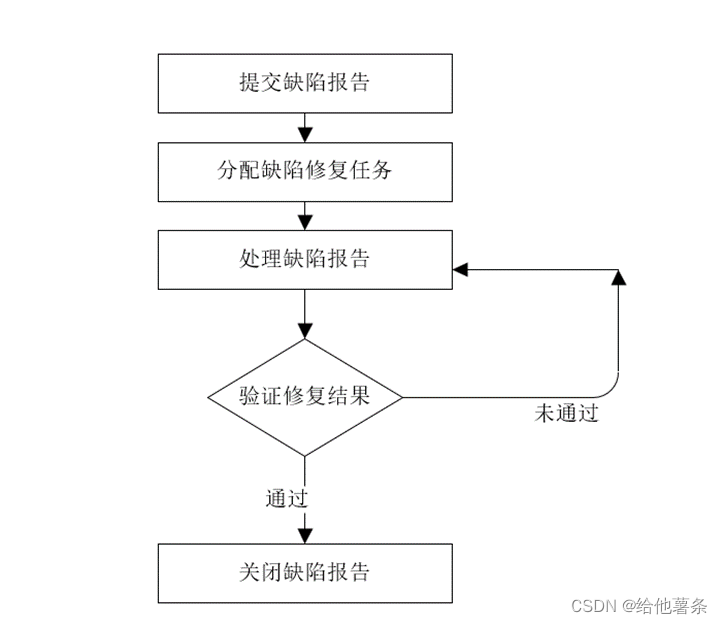
一、整型
1. 整型分类
整型分为以下两个大类:
(1)按长度分为:int8、int16、int32、int64
(2)对应的无符号整型:uint8、uint16、uint32、uint64
其中,uint8就是我们熟知的byte型,int16对应C语言中的short型,int64对应C语言中的long型。
| 类型 | 描述 |
|---|---|
| uint8 | 无符号8位整型(0 ~ 255) |
| uint16 | 无符号16位整型(0 ~ 65535) |
| uint32 | 无符号32位整型(0 ~ 4294967295) |
| uint64 | 无符号64位整型(0 ~ 18446744073709551615) |
| int8 | 有符号8位整型(-128 ~ 127) |
| int16 | 有符号16位整型(-32768 ~ 32767) |
| int32 | 有符号32位整型(-2147483648 ~ 2147483647 ) |
| int64 | 有符号64位整型(-9223372036854775808 ~ 9223372036854775807) |
2. 特殊整型
| 类型 | 描述 |
|---|---|
| uint | 在32位操作系统上是uint32,在64位操作系统上是uint64 |
| int | 在32位操作系统上是int32,在64位操作系统上是int64 |
| uintptr | 无符号整型,用于存放指针 |
注意:
(1)在使用int和uint类型时,不能假定它是32位或64位的整型,而是考虑int和uint可能在不同平台上的差异。
(2)获取对象的长度的内建len()函数返回的长度可以根据不同平台的字节长度进行变化,实际使用中,切片或 map 的元素数量等都可以用int来表示。
(3)在涉及到二进制传输、读写文件的结构描述时,为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用int和uint。
3. 数字字面量语法
Go1.13版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮点数的格式定义数字,例如:a:=0b1011,表示二进制的1011;a:=0o666,表示八进制的666(也可以以0开头,或略o表示八进制);a:=666,表示十进制的666;a:=0x10fba,表示十六进制的10fba。除此之外,还允许我们用 _ 来分隔数字,比如说:a:=123_456表示 v 的值等于 123456。
var a = 10
fmt.Printf("%d\n", a) //十进制输出 10
b := 0775
fmt.Printf("%o\n", b) //八进制 755
c := 0o775
fmt.Printf("%o\n", c) //八进制 755
d := 0b1011
fmt.Printf("%b\n", d) //二进制 1011
e := 0x10fba
fmt.Printf("%x\n", e) //十六进制 10fba
f := 123_45
fmt.Println(f) //十进制 12345二、浮点型
(1)Go语言支持两种浮点型float32和float64。
(2)这两种浮点型数据格式遵循IEEE 754标准: float32的浮点数的最大范围约为3.4e38,可以使用常量定义:math.MaxFloat32。float64的浮点数的最大范围约为1.8e308,可以使用常量定义:math.MaxFloat64。
打印浮点数时,可以使用fmt包配合动词%f,示例:
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f\n", math.Pi) //3.141593
fmt.Printf("%.2f\n", math.Pi) //3.14
fmt.Println(math.MaxFloat32) //3.4028234663852886e+38
fmt.Println(math.MaxFloat64) //1.7976931348623157e+308
}三、复数
复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位。
var a complex64 = 3 + 4i
var b complex128 = -3 - 5i四、布尔值
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和flase(假)两个值。
注意:
1.布尔类型变量的默认值是false。
2.Go语言中不允许将整型强转转换为布尔型。
3.布尔类型无法参与数值运算,页无法与其他类型进行转换。
五、字符串
1. 字符串简介
Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。 Go 语言里的字符串的内部实现使用UTF-8编码。 字符串的值为双引号中的内容,可以在Go语言的源码中直接添加非ASCII码字符,例如:
s1 := "hello"
s2 := "你好"2. 字符串转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示:
| 转义符 | 含义 |
|---|---|
| \r | 回车符(返回行首) |
| \n | 换行符 |
| \t | 制表符 |
| \' | 单引号 |
| \" | 双引号 |
| \\ | 反斜杠 |
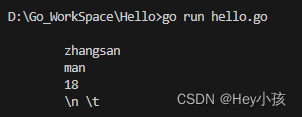
3. 多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
s1 := `
zhangsan
man
18
\n \t
`
fmt.Println(s1)注意:
反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
4. 字符串常用操作
| 方法 | 描述 |
|---|---|
| len(str) | 求字符串长度 |
| + 或 fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.Contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置/最后出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
(1)求长度
//1.求长度
s1 := "hello"
fmt.Println(len(s1)) //5(2)字符串拼接
s2 := " world"
//2.字符串拼接
fmt.Println(s1 + s2) //hello world
s3 := fmt.Sprintf("%s + %s", s1, s2)
fmt.Println(s3) //hello + world(3)字符串分割
//3.字符串分割
s4 := "How do you do"
fmt.Println(strings.Split(s4, " ")) //按空格分割![]()
(4)判断是否包含
//4.判断是否包含
fmt.Println(strings.Contains(s4, "do")) //包含返回true,否则返回false(5)前缀/后缀判断
fmt.Println(strings.HasPrefix(s4, "How")) //判断前缀
fmt.Println(strings.HasSuffix(s4, "doo")) //判断后缀(6)子串出现位置
fmt.Println(strings.Index(s4, "do")) //第一次出现的位置
fmt.Println(strings.LastIndex(s4, "do")) //最后一次出现的位置
fmt.Println(strings.Index(s4, "doo")) //没有出现返回-1(7)字符串插入
s5 := []string{"how", "do", "you", "do"}
fmt.Println(strings.Join(s5, "+")) //how+do+you+do六、字符
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。Go 语言的字符有以下两种:
(1)bite(uint8):代表一个ASCII码字符;
(2)rune(int32):代表一个UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
注意:
(1)因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串。
(2)若要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
七、类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
强制类型转换的基本语法如下:
T(表达式)
//其中,T表示要转换的类型
//表达式包括变量、算式、函数返回值等.