标准化数据【离差标准化数据、标准差标准化数据、小数定标标准化数据】
离差标准化数据:

数据的整体分布情况并不会随离差标准化而发生改变,原先取值较大的数据,在做完离差标准化后的值依旧较大;
对原始数据的一种线性变换,结果是将原始数据的数值映射到[0,1]区间之间。
实操:
import pandas as pddata =pd.read_csv('./609/detail.csv',encoding='gbk')data.head()


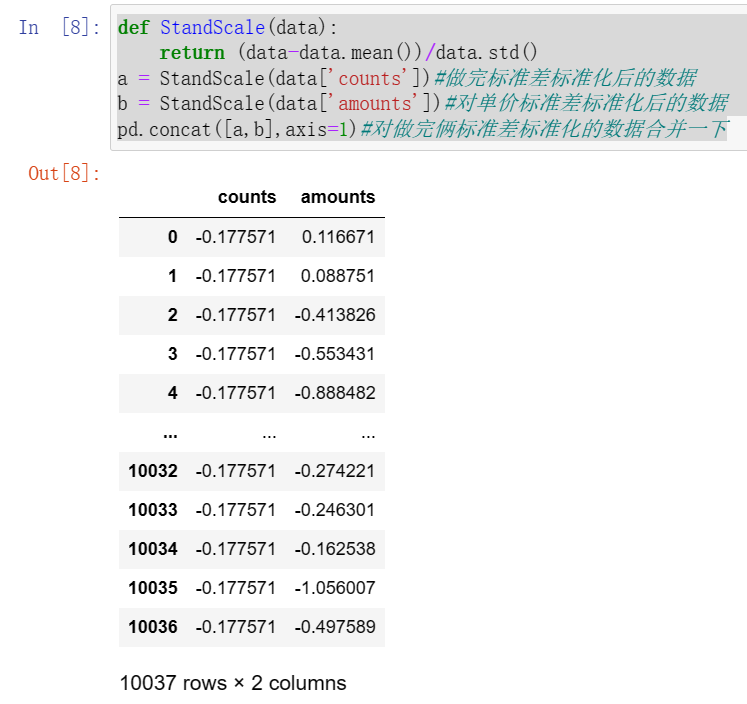
def MinMaxScale(data):return (data-data.min())/(data.max()-data.min())MinMaxScale(data['counts'])#做完离差标准化后的数据
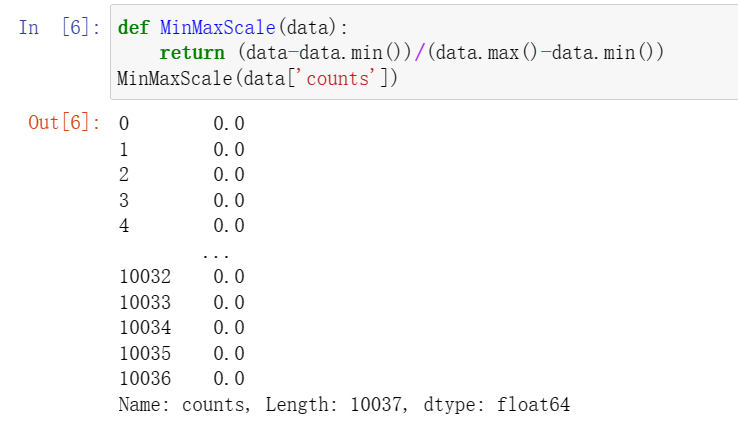
a = MinMaxScale(data['counts'])#做完离差标准化后的数据b = MinMaxScale(data['amounts'])#对单价离差标准化后的数据pd.concat([a,b],axis=1)#对做完俩离差标准化的数据合并一下
标准差标准化数据:

也叫零均值标准化或分数标准化,是当前使用最广泛的数据标准化方法。经过该方法处理的数据均值为0,标准差为1。
实操:
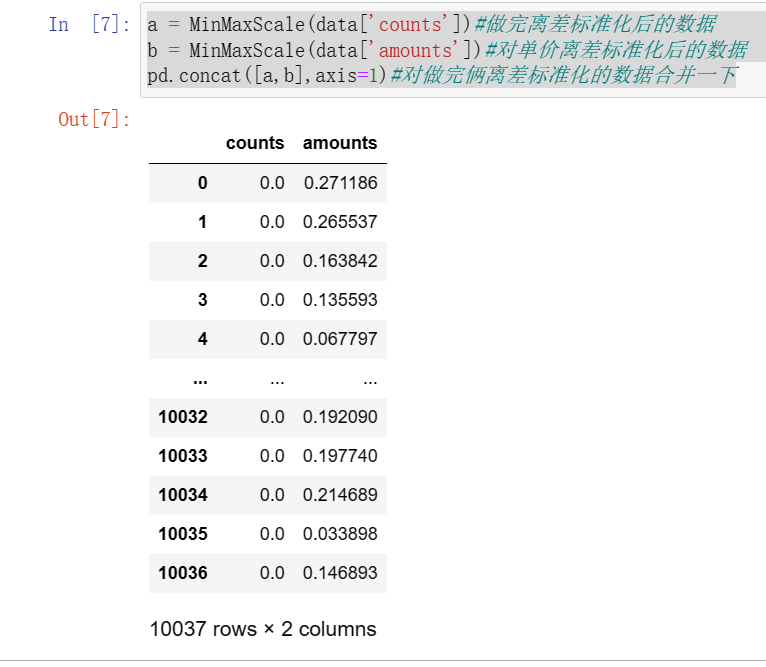
def StandScale(data):return (data-data.mean())/data.std()a = StandScale(data['counts'])#做完标准差标准化后的数据b = StandScale(data['amounts'])#对单价标准差标准化后的数据pd.concat([a,b],axis=1)#对做完俩标准差标准化的数据合并一下
小数定标标准化数据:

通过移动数据的小数位数,将数据映射到区间[-1,1]之间。
实操:
import numpy as npdef DecimalScale(data):return data/10**(np.ceil(np.log10(data.abs().max())))#ceil取整a = DecimalScale(data['counts'])#做完标准差标准化后的数据b = DecimalScale(data['amounts'])#对单价标准差标准化后的数据pd.concat([a,b],axis=1)#对做完俩标准差标准化的数据合并一下

使用sklearn构建模型【scikit-learn】:
加载datasets模块中数据集
sklearn库的datasets模块集成了部分数据分析的经典数据集,可以使用这些数据集进行数据预处理,建模等操作,熟悉sklearn的数据处理流程和建模流程;
datasets模块常用数据集的加载函数与解释。
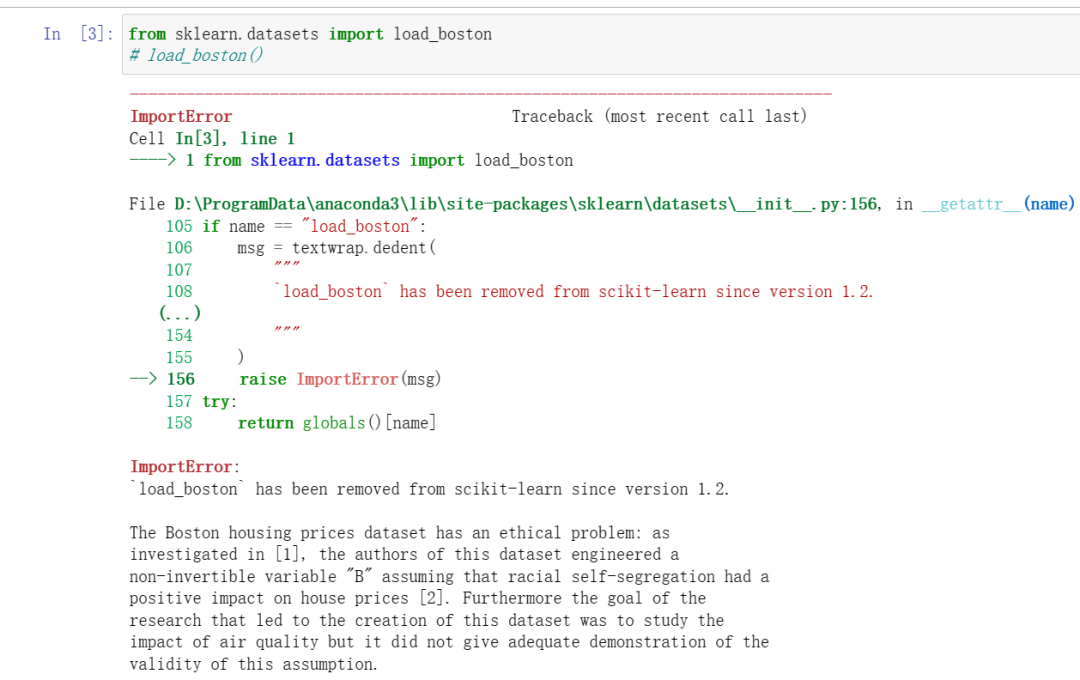
嘿嘿,一来就报错,解决一下子:

好的,我们就采取第二种好了方法好了:【文末附🔗】
将数据集划分为训练集和测试集
k折交叉验证法:将样本打乱,均匀分成k份;轮流选择其中k-1份做训练,剩余的一份做验证;计算预测误差平方和。
train_test_split()函数:能够对数据集进行拆分。
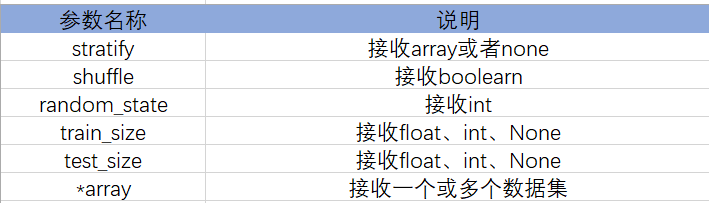
X ,y = data[data.columns.delete(-1)], data['MEDV']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=888)
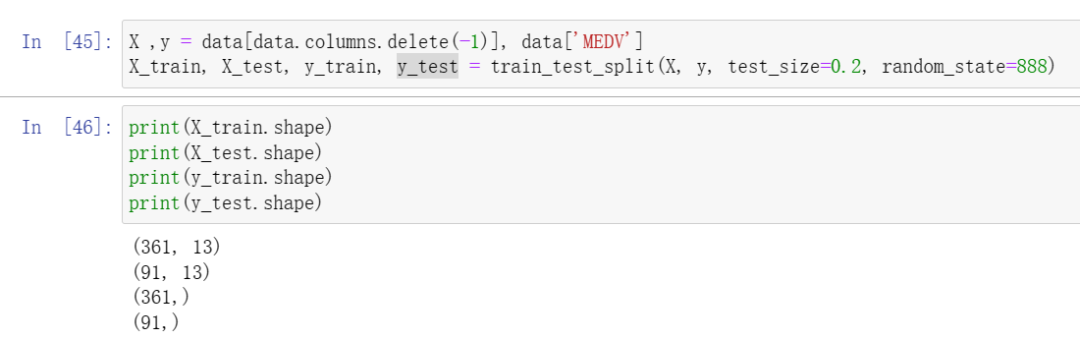
sklearn把相关的功能封装为转换器(transformer)
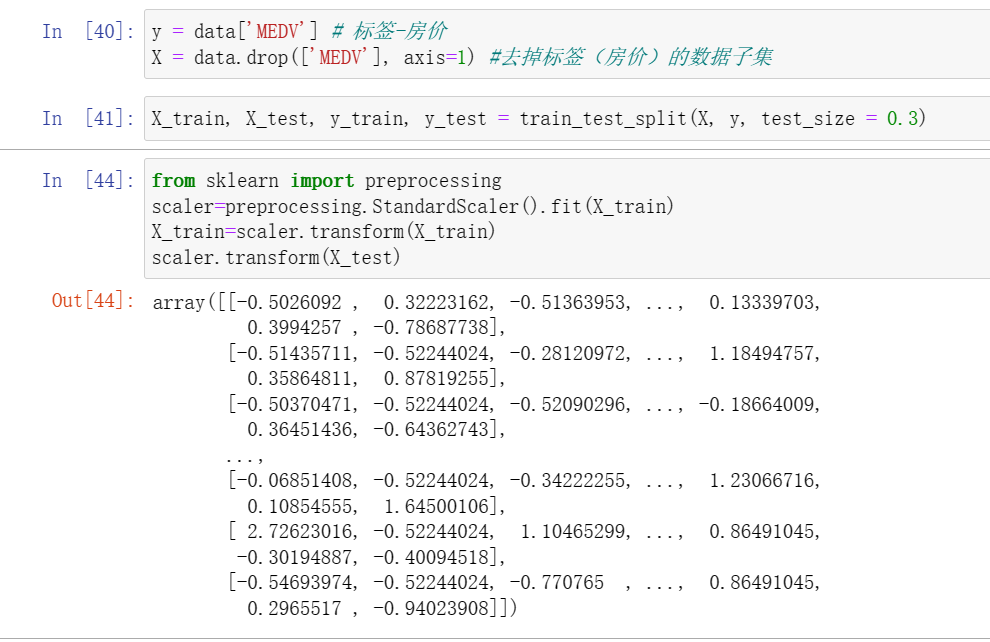
在数据分析过程中,各类特征处理相关的操作都需要对训练集和测试集分开操作。
y = data['MEDV'] # 标签-房价X = data.drop(['MEDV'], axis=1) #去掉标签(房价)的数据子集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)from sklearn import preprocessingscaler=preprocessing.StandardScaler().fit(X_train)X_train=scaler.transform(X_train)scaler.transform(X_test)
资料分享栏目
数据集之波斯顿房价:
链接:https://pan.baidu.com/s/1za40m3Cq9R0w0pKpe8qhXA
提取码:jq3v