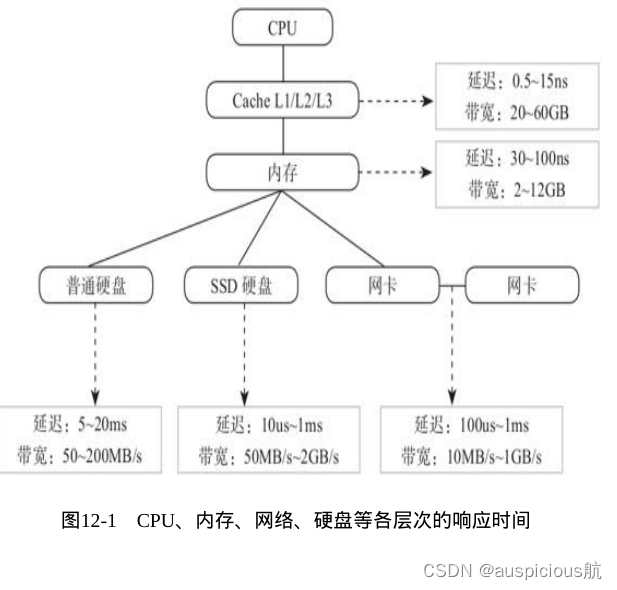
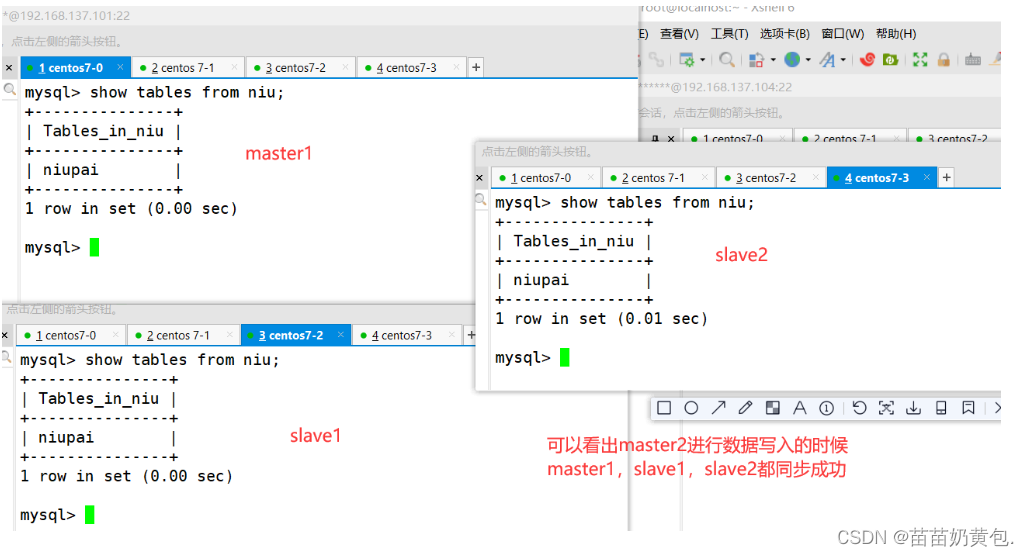
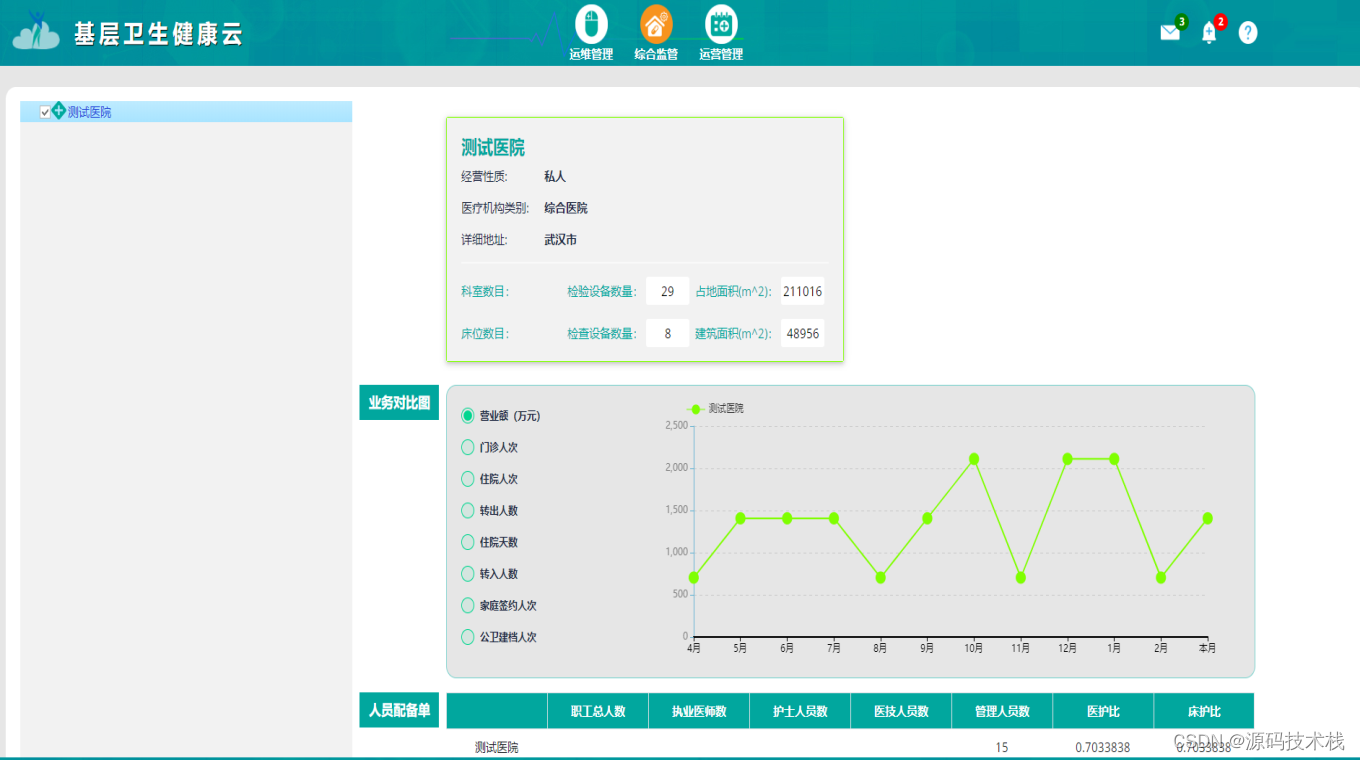
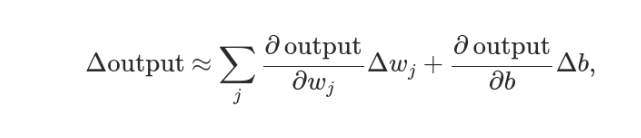import os, time
import pandas as pd
def xlsx2csv_mh ( ) :
for f in os. listdir( "./数据源/" ) :
t1 = time. time( )
data = pd. read_excel( "./数据源/" + f, index_col= 0 )
data. to_csv( "./数据源(csv)/" + f + '.csv' , encoding= 'utf-8' )
print ( f" { f} 转换完成......" )
t2 = time. time( )
print ( t2 - t1)
xlsx2csv_mh( )
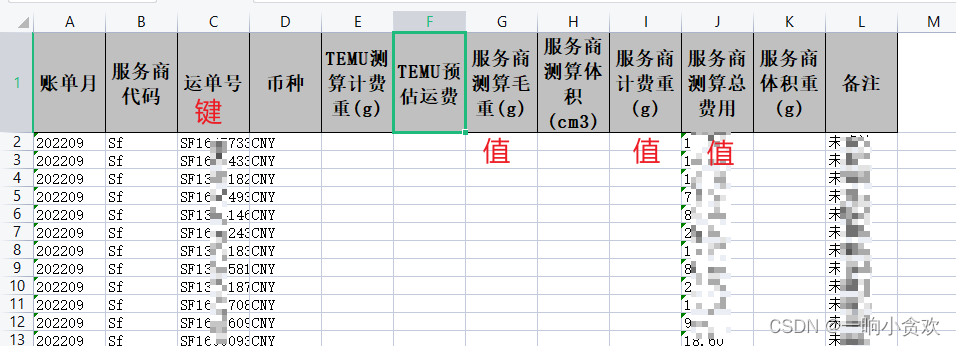
list_a.append((row[2],row[6]+"="+row[8]+"="+row[9])),这行就是我做的列表,row[2]就是键,row[6]+“=”+row[8]+“=”+row[9],这个就是值,中间我用=等于号隔开了
import json
import os
from collections import defaultdict
import csv
for f in os. listdir( './数据源(csv)/' ) [ : 1 ] :
list_a = [ ]
d = defaultdict( list )
with open ( './数据源(csv)/' + f, newline= '' , encoding= 'utf-8' ) as csvfile:
reader = csv. reader( csvfile, delimiter= ',' , quotechar= '"' )
for row in reader:
list_a. append( ( row[ 2 ] , row[ 6 ] + "=" + row[ 8 ] + "=" + row[ 9 ] ) )
for key, value in list_a:
d[ key] . append( value)
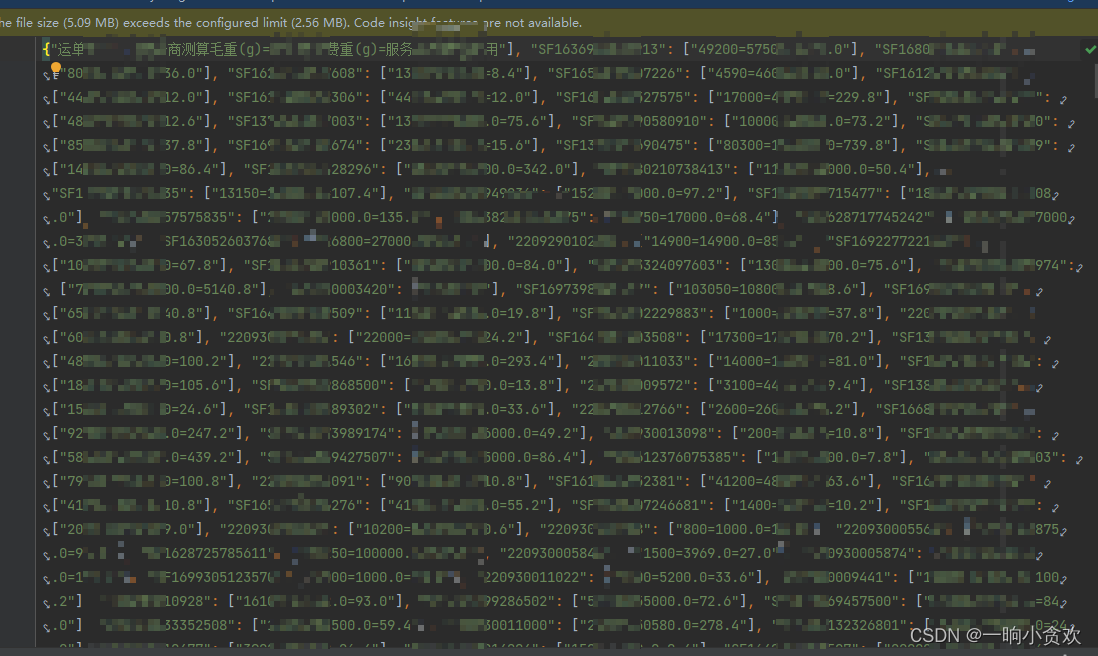
with open ( f"./json文件/ { f} .json" , "w" , encoding= "utf-8" ) as f_w:
f_w. write( json. dumps( d, ensure_ascii= False ) )
print ( f" { f} ,转换json成功" )
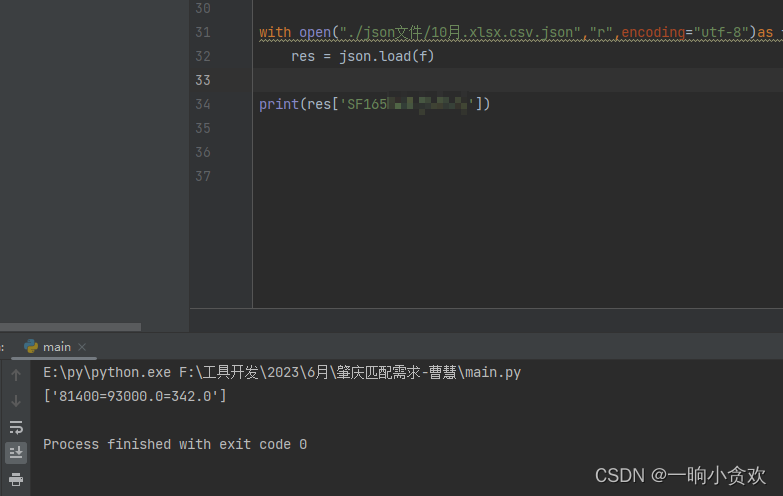
with open ( "./json文件/10月.xlsx.csv.json" , "r" , encoding= "utf-8" ) as f:
res = json. load( f)
print ( res[ 'SF16xxxxxxx' ] )