在实际的工作中,我们使用Kubernetes 通常不会直接创建 Pod,而是通过 各种 Controller 来管理 Pod 的。Controller 中定义了 Pod 的部署特性,比如有几个副本,在什么样的 Node 上运行等。为了满足不同的业务场景,Kubernetes 提供了多种 Controller,包括 Deployment、Replication Controller、ReplicaSet、DaemonSet、StatefuleSet、Job、cronjobs ,后面我们会逐一介绍。
一、Replication controllers
Replication Controller(升级版本为ReplicaSet,本节后面说明),本节对RC的概念进行深入描述。
RC是Kubernetes系统中的核心概念之一,简单来说,它其实是定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下几个部分。
- Pod期待的副本数(replicas)。
- 用于筛选目标Pod的Label Selector。
- 当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模版(template)。
下面是一个完整的RC定义的例子,即确保拥有tier=frontend标签的这个Pod(运行nginx容器)在整个Kubernetes集群中始终只有一个副本:
[root@k8s-m1 tmp]# cat rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
spec:
replicas: 1
selector:
tier: frontend
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: nginx-demo
image: nginx
ports:
imagePullPolicy: Always
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80
当我们定义了一个RC并提交到Kubernetes集群中以后,Master节点上的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,否则系统就会再自动创建一些Pod。可以说,通过RC,Kubernetes实现了用户应用集群的高可用性,并且大大减少了系统管理员在传统IT环境中需要完成的许多手工运维工作(如主机监控脚本、应用监控脚本、故障恢复脚本等)。
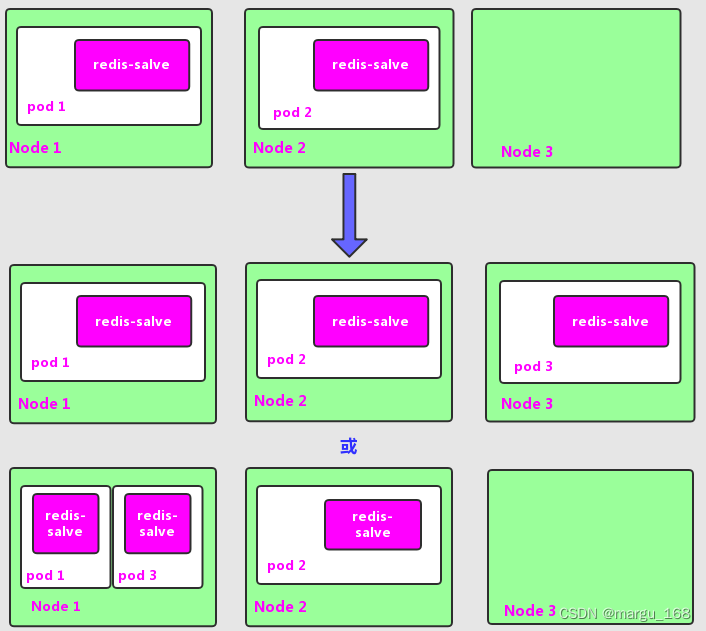
下面我们以3个Node节点的集群为例,说明Kubernetes如何通过RC来实现Pod副本数量自动控制的机制。假如我们的RC里定义redis-slave这个Pod需要保持2个副本,系统将可能在其中的两个Node上创建Pod。如下图描述了在两个Node上创建redis-slave Pod的情形。
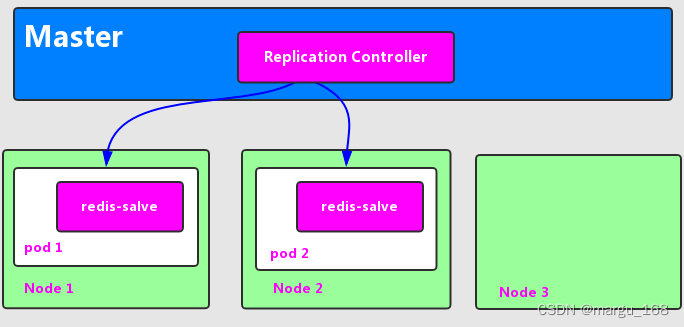
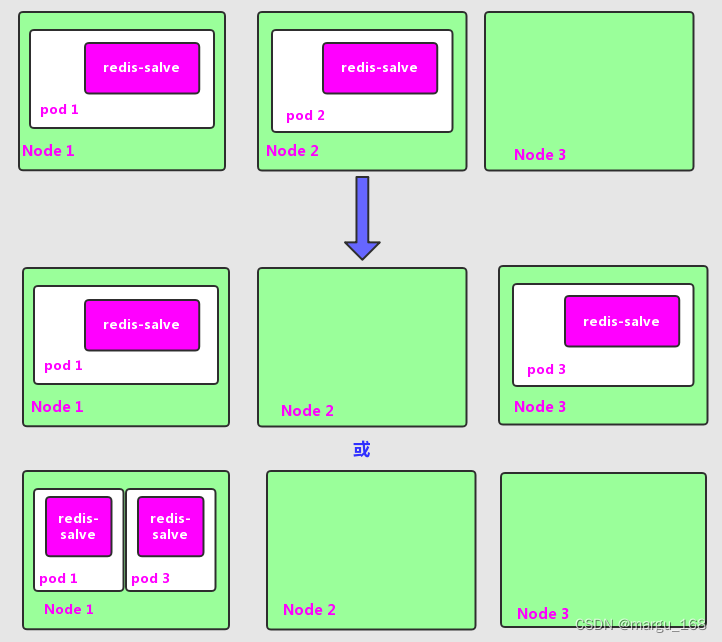
假设Node2上的Pod2意外终止,根据RC定义的replicas数量2,Kubernetes将会自动创建并启动一个新的Pod,以保住整个集群中始终有两个redis-slave Pod在运行。
如下图所示,系统可能选择Node3或者Node1来创建一个新的Pod。
此外,在运行时,我们可以通过修改RC的副本数量,来实现Pod的动态缩放(Scaling)功能,还可以通过执行kubectl scale命令来一键完成:
[root@k8s-m1 ~]#kubectl scale rc redis-slave --replicas=3
scaled
Scaling的执行结果如下图所示
需要注意的是,删除RC并不会影响通过该RC已创建好的Pod。为了删除所有Pod,可以设置replicas的值为0,然后更新该RC。另外,kubectl提供了stop和delete命令来一次性删除RC和RC控制的全部Pod。
当我们的应用升级时,通常会通过Build一个新的Docker镜像,并用新的镜像版本来替代旧的版本的方式达到目的,在系统升级的过程中,我们希望是平滑的方式,比如当前系统中10个对应的旧版本的Pod,最佳的方式是旧版本的Pod每次停止一个,同时创建一个新版本的Pod,在整个升级过程中,此消彼长,而运行中的Pod数量始终是10个,几分钟以后,当所有的Pod都已经是最新版本时,升级过程完成。通过RC的机制,Kubernetes很容易就实现了这种高级实用的特性,被称为“滚动升级”(Rolling Update)。
二、Replica Set
由于Replication Controller与Kubernetes代码中的模块Replication Controller同名,同时这个词也无法准确表达它的本意,所以在Kubernetes v1.2时,它就升级成了另外一个新的概念 – Replica Set,官方解释为“下一代的RC”,它与RC当前存在的唯一区别是:Replica Sets支持基于集合的Label selector(Set-based selector),而RC只支持基于等式的Label Selector(equality-based selector),这使得Replica Set的功能更强,下面是等价于之前RC例子的Replica Set的定义(省去了Pod模版部分的内容):
ReplicaSet的创建
Kubernetes官方强烈建议避免直接使用ReplicaSet,而应该通过Deployment来创建RS和Pod。
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
spec:
selector:
matchLabels:
tier: frontend
matchExpression:
- {key: tier, operator: In, values: [frontend]}
template:
…
kubectl命令工具适用于RC的绝大部分命令都同样适用于Replica Set。此外,当前我们很少单独使用Replica Set,它主要被Deployment这个更高层的资源对象所使用,从而形成一整套Pod创建、删除、更新的编排机制。当我们使用Deployment时,无须关心它是如何创建和维护Replica Set的,这一切都是自动发生的。
Replica Set与Deployment这两个重要资源对象逐步替换了之前的RC的作用,是Kubernetes v1.3里Pod自动扩容(伸缩)这个告警功能实现的基础,也将继续在Kubernetes未来的版本中发挥重要的作用。
最后我们总结一下关于RC(Replica Set)的一些特性与作用。
- 在大多数情况下,我们通过定义一个RC实现Pod的创建过程及副本数量的自动控制。
- RC里包括完整的Pod定义模版。
- RC通过Label Selector机制实现对Pod副本的自动控制。
- 通过改变RC里的Pod副本数量,可以实现Pod的扩容或缩容功能。
- 通过改变RC里的Pod模版中的镜像版本,可以实现Pod的滚动升级功能。
三、Deployment
Deployment是Kubernetes v1.2引入的概念,引入的目的是为了更好地解决Pod的编排问题。为此,Deployment在内部使用了Replica Set来实现目的,无论从Deployment的作用与目的,它的YAML定义,还是从它的具体命令行操作来看,我们都可以把它看作RC的一次升级,两者相似度超过90%。
Deployment相对于RC的一个最大升级是我们随时知道当前Pod“部署”的进度。实际上由于一个Pod的创建、调度、绑定节点及在目标Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
Deployment的典型使用场景有以下几个。
创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程。
检查Deployment的状态来看部署动作是否完成(Pod副本的数量是否达到预期的值)。
更新Deployment以创建新的Pod(比如镜像升级)。
如果当前Deployment不稳定,则回滚到一个早先的Deployment版本。
暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后再恢复Deployment,进行新的发布。
扩展Deployment以应对高负载。
查看Deployment的状态,以此作为发布是否成功的指标。
清理不再需要的旧版本ReplicaSets。
Deployment的定义与Replica Set的定义很类似,除了API声明与Kind类型等有所区别:
| Deployment | Replicaset |
|---|---|
| apiVersion: extensions/v1beta1 | apiVersion: v1 |
| kind: Deployment | kind: ReplicaSet |
| metadata: | metadata: |
| name: nginx-deployment | name: nginx-repset |
| 下面我们通过运行一些例子来一起直观地感受这个新概念。首先创建一个名为nginx-deployment.yaml的Deployment描述文件,内容如下: |
[root@k8s-m1 tmp]# cat nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 1
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: nginx-demo
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
#运行下述命令创建Deployment:
[root@k8s-m1 tmp]#kubectl create -f de.yaml
deployment.apps/frontend created
#运行下述命令查看Deployment的信息:
[root@k8s-m1 tmp]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
frontend 1 1 1 1 3m
对上述输出中涉及的数量解释如下:
DESIRED:Pod副本数量的期望值,即Deployment里定义的Replicas。
CURRENT:当前Replicas的值,实际上是Deployment所创建的Replica Set里的Replica值,这个值不断增加,直到达到DESIRED为止,表明整个部署过程完成。
UP-TO-DATE:最新版本的Pod副本数量,用于指示在滚动升级的过程中,有多少个Pod副本已经成功升级。
AVAILABLE:当前集群中可用的Pod副本数量,即集群中当前可用的Pod数量。
运行下述命令查看对应的Replica Set,我们看到它的命名与Deployment的名字有关系:
[root@k8s-m1 tmp]# kubectl get replicasets.apps
NAME DESIRED CURRENT READY AGE
frontend-7d7c57fc94 1 1 1 54s
运行下述命令查看创建的Pod,我们发现Pod的命名以Deployment对应的Replica Set的名字为前缀,这种命名很清晰地表明了一个Replica Set创建了哪些Pod,对于滚动升级这种复杂的过程来说,很容易排查错误:
[root@k8s-m1 tmp]# kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-7d7c57fc94-gpfts 1/1 Running 0 96s
运行kubectl describe deployments,可以清楚地看到Deployment控制的Pod的水平扩展过程。
Pod的管理对象,除了RC(RS)和Deployment,还包括DaemonSet、StatefulSet、Job等,分别用于不同的应用场景中,在其他专栏会进行详细介绍。
更多关于kubernetes的知识分享,请前往博客主页。




![五、浅析[ElasticSearch]底层原理与分组聚合查询](https://img-blog.csdnimg.cn/531f2cd371284c1299a7d3c1e726dc78.png)