Stable Diffusion模型
什么是Stable Diffusion模型
一般而言,扩散是在图像中反复添加小且随机的噪声。与之相反,Stable Diffusion模型是一种将噪声生成为图像的机器学习模型。经过训练,它可逐步对随机高斯噪声进行去噪以获得感兴趣的样本,如无条件图片生成(unconditional image synthesis)、图片修复(inpainting)、图片超分(super-resolution)、类别条件图片生成(class-condition)、文图生成(text-to-image)、布局条件图片生成(layout-to-image)等。训练的神经网络通常为U-Net。
扩散模型的主要缺陷在于其去噪过程的耗时与内存消耗十分昂贵。进程变慢以及大量内存的消耗是此类模型的特点。造成这一缺陷的主要原因是它们在像素空间进行了大量的运算。
Latent Diffusion的引入
通过在较低维度的潜空间上应用扩散过程而非使用实际的像素空间,Latent Diffusion降低了模型对计算资源的消耗。
Latent Diffusion模型的组成
Latent Diffusion模型有三个主要组成部分:
Variational autoencoders (VAE)
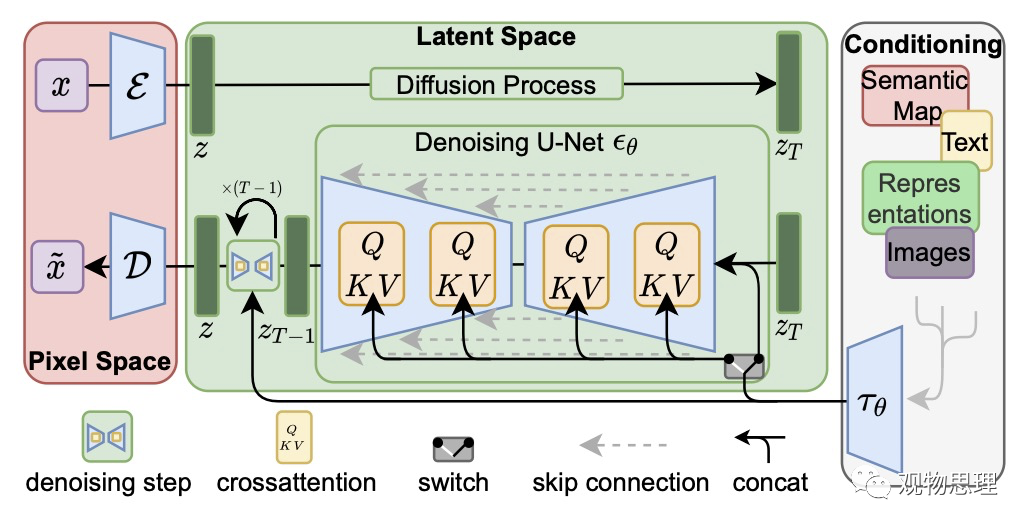
Variational autoencoders由编码器(encoder)和解码器(decoder)组成。前者忽略图片中的高频信息,只保留重要的深层特征,将图像转换为低维潜空间中的表示,该表示可作为下一组件U-Net的输入。后者则将潜空间中的表示转化为图像。
在训练过程中,利用编码器获得正向扩散过程中输入图像的潜表示(latent)。而在推理过程中,解码器可以用来把潜表示转化为图像。
U-Net
该模块由以残差模块组成的编码器和解码器组成。编码器压缩图像,解码器则将低分辨率图像解码为高分辨率图像。
为防止U-Net在下采样时丢失重要信息,在编码器的下采样与解码器的上采样之间添加了连接。
在Stable Diffusion模型中使用的U-Net模型中的解码器与编码器之间增加了用于对文本嵌入的输出进行调节的交叉注意层。
Text-Encoder
文本编码器是一个基于transformer的编码器,它将标记序列映射至潜在文本嵌入序列,使得输入的文字被转换为U-Net可以理解的嵌入空间以指导模型对潜表示的去噪。
Latent Diffusion有效的原因
U-Net在低维空间上操作,与像素空间中的扩散相比,降低了计算复杂度与内存消耗。
训练细节
该模型的训练数据为LAION-5B及其子集。
训练Latent Diffusion模型时:
-
图像首先由编码器进行编码转换为低维潜空间中的表示(自编码器将输入图像进行下采样使其缩放8倍,并将原始大小为的图像映射为尺度是的潜表示)。
-
输入的文字则被ViT-L/14文本编码器转换。
-
转换所得的文本嵌入序列通过交叉注意层插入U-Net中。
-
计算U-Net预测结果与潜表示中掺入噪声的结果之间的重构误差。
模型训练采用了多块A100显卡,使用AdamW优化器,batchsize设为2048。训练时,首先预热10000步,使得学习率从增至,其后保持恒定直至训练结束。
Stable Diffusion模型的推理过程
img2img
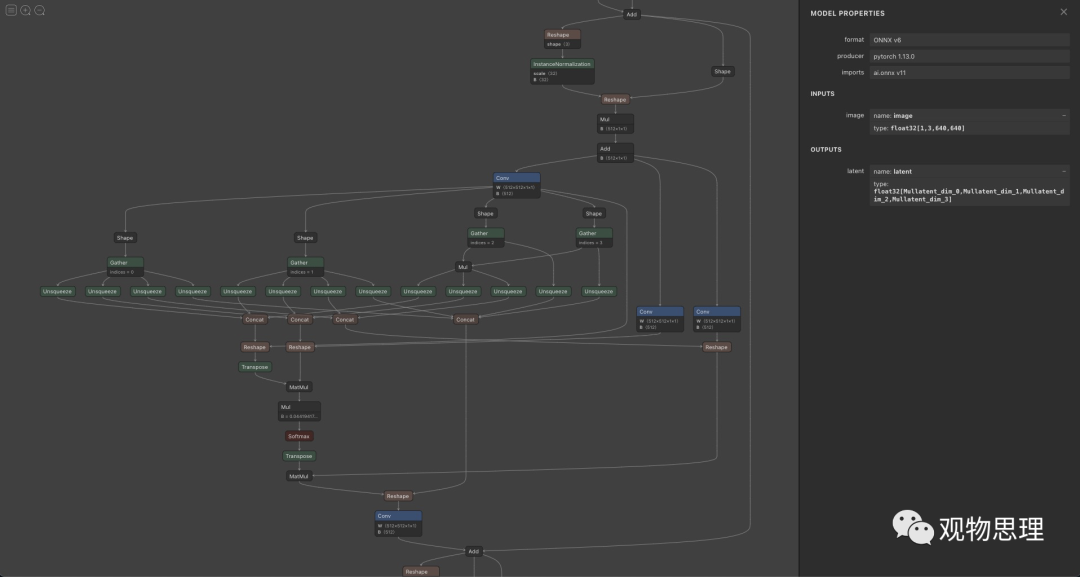
1. 输入图片,利用编码器获取其对应的初始潜表示。如下图所示,若输入的RGB图像为的分辨率,那么输出的潜表示向量维度为。
模型的编码器部分结构
2. 调用文本解码器将prompt解析为模型可理解的文本嵌入序列。
3. 将输入图片的潜表示和噪声混合后,与文本嵌入序列一起送入采样模型,然后将所得结果输入模型的解码器获得当前结果。
4. 循环2、3两步,将所得输出存入图片序列。
Latent Diffusion模型推理机制
模型超分辨效果优秀的原因
Stable Diffusion模型所采用的超分辨方法效果十分显著,它能够有效消除低分辨率图像中的振铃和overshoot伪影。取得如此效果的原因在于:
-
引入高阶退化过程模拟更为真实的退化,包含多个重复的经典退化过程,每个过程具有不同的退化超参数:
采用二阶退化,模拟模糊、噪声、缩放、JPEG压缩等实际退化。
-
采用U-Net结构,并引入skip-connection方案,保证模型在获取图像深层信息的同时保留一部分高频信息。
![[附源码]Python计算机毕业设计Django学生综合数据分析系统](https://img-blog.csdnimg.cn/a2ad5a21d26b4813989bc961f42e780a.png)








![[windows] opencv + ffmpeg + h264 + h265 源码编译教程](https://img-blog.csdnimg.cn/622f9556e27349139fdf00c729bd86bb.png)