HashMap 和 Hashtable 的区别?
- 线程是否安全:
HashMap是非线程安全的,Hashtable是线程安全的,因为Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!); - 效率: 因为线程安全的问题,
HashMap要比Hashtable效率高一点。另外,Hashtable基本被淘汰,不要在代码中使用它; - 对 Null key 和 Null value 的支持:
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出NullPointerException。 - 初始容量大小和每次扩充容量大小的不同 : ① 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而HashMap会将其扩充为 2 的幂次方大小。也就是说HashMap总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。 - 底层数据结构: JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
HashMap 和 HashSet 区别?
HashSet 底层就是基于 HashMap 实现的。
HashMap | HashSet |
|---|---|
实现了 Map 接口 | 实现 Set 接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向 map 中添加元素 | 调用 add()方法向 Set 中添加元素 |
HashMap 使用键(Key)计算 hashcode | HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性 |
HashMap 和 TreeMap 区别?
TreeMap 和HashMap 都继承自AbstractMap ,但是需要注意的是TreeMap它还实现了NavigableMap接口和SortedMap 接口。
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
实现SortedMap接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。
说说HashMap 的底层实现?
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK1.8 之后相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。

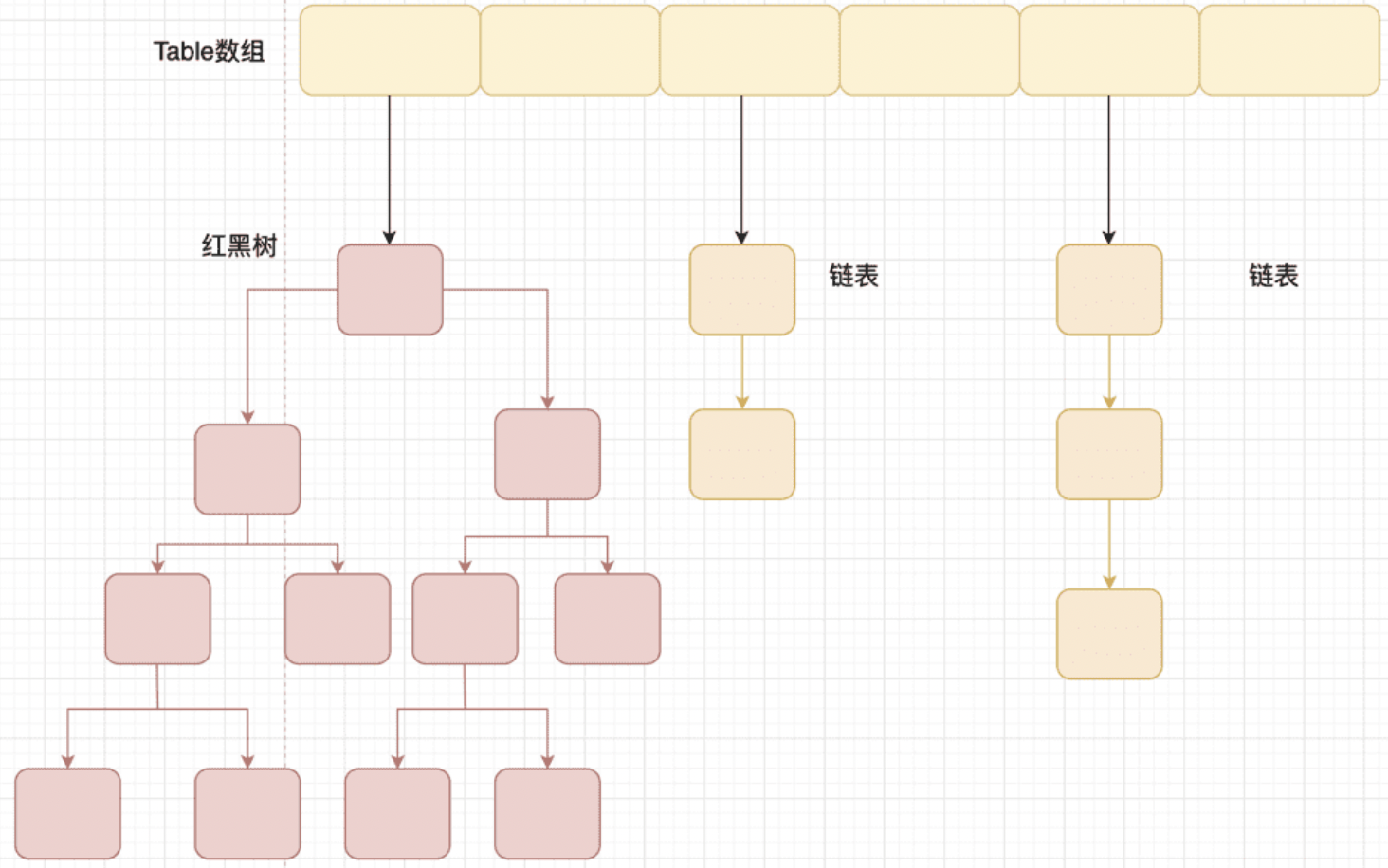
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
-
loadFactor 加载因子
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
-
put方法
HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
对 putVal 方法添加元素的分析如下:
-
如果定位到的数组位置没有元素 就直接插入。
-
如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
我们再来对比一下 JDK1.7 put 方法的代码
对于 put 方法的分析如下:
- ① 如果定位到的数组位置没有元素 就直接插入。
- ② 如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的 key 比较,如果 key 相同就直接覆盖,不同就采用头插法插入元素


![[windows] opencv + ffmpeg + h264 + h265 源码编译教程](https://img-blog.csdnimg.cn/622f9556e27349139fdf00c729bd86bb.png)








![[附源码]Python计算机毕业设计Django校园租赁系统](https://img-blog.csdnimg.cn/07a6b652eccf4a8fa39ac553ff68f5cd.png)