文章目录
- 集群原理
- 缓存分片算法
- Hash算法
- 一致性Hash算法
- 二者区别
- 集群方案
- 通信协议
- 缓存路由
- 缓存扩展
- 保障可用性
- 搭建
- redis安装步骤
- 集群安装
- 基本配置
- 启动节点
- 创建集群
- 访问集群
- 添加主节点
- 加入集群
- 分配槽
- 添加从节点
- 切换从节点
- 删除节点
- 手动切换故障
- 升级节点
- 问题记录
- 安装gcc
- jemalloc/jemalloc.h:没有那个文件或目录
- 安装net-tools
- 关闭防火墙
十年前做项目的时候基本都是单体应用开发,那个时候缓存基本都是使用JVM的内存,后来随着应用的拆分,我们使用独立的缓存服务器,一开始主要是存储会话数据,后来将一些不常改变但是经常使用的字典数据也使用缓存存储。如果只是使用一个存储节点,对于中小项目来说是够用的,即使抛开缓存大小的问题但也面临着高可用的问题,所以本文就Redis缓存的扩展性和可用性深入研究一下。
集群原理
我打个比方,缓存节点我们当作装鸡蛋的篮子,鸡蛋就是数据,一篮子只能装20个鸡蛋,显然我们有100个鸡蛋,那么一个篮子是装不下的,那么我们就得多用几个篮子,那么我们依据实际的业务规模怎么动态添加或者减少篮子以及每个篮子装哪些鸡蛋,这就涉及到两个算法,Hash算法和一致性Hash算法,这也是2022年11月5号软考系统架构设计师在案例题中考到的知识点。
缓存分片算法
缓存分片算法就是解决怎么把数据放到不同存储节点上。
Hash算法
Hash表是一种常见的数据结构,其实现方式是对数据记录的关键值进行Hash计算,然后再对需要分片的缓存节点个数进行取模,根据取模结果分配数据。
比如,我有key字段,值为(1,2,3,4,5,6,7,8,9),存在三个缓存节点(0,1,2),那么我们将key对3取模(当作hash算法),那么分配流程如下:
由此可知:
key(1,4,7)%3=1,分配到缓存节点1
key(2,5,8)%3=2,分配到缓存节点2
key(3,6,9)%3=0,分配到缓存节点0
采用Hash算法的分片,简单、均分,如果扩展节点数据会重新分配,波动比较大。
一致性Hash算法
一致性Hash算法是将数据按照特征值映射到一个首尾相接的Hash环上,同时缓存节点也映射到这个环上。我们按照上一小节的例子来说,新添加一个缓存节点,那么key%4取模,那么大部分数据将会重新进行分配到不同的存储节点上,所以这会引起大量的数据进行迁移,迁移过程中部分数据无法命中会直接访问数据库,这样数据库压力就会增大,为了解决这个问题,一致性Hash算法出现了。

接上一个例子,Hash算法是对key按照缓存节点个数进行取模运算,而一致性Hash算法是对232取模,基本思路如下:
- 首先Hash环被分为2 32份,从0到232-1;
- 缓存节点的IP对232取模,将缓存节点映射到hash环上,如上图的蓝色小球所示;
- 最后将数据按照key对232取模,加入存在J K L M四个数值,取模后映射到图中所示位置,J在缓存节点1上,K在缓存节点2上,L
M在缓存节点0上,按照顺时针找最大的节点。
假如我们新添加一个缓存节点n,不管缓存节点n在这三个区间(0->1,1->2,2->0)的哪个区间,只需要迁移一部分数据,而不像Hash算法那样,所有数据都要重新取模计算。
二者区别
缓存节点发生变更时,一致性Hash算法减少缓存数据的迁移,避免出现大规模缓存数据命中失效的情况,避免了缓存数据命中失效后访问数据库的问题,保证了系统的稳定性。
集群方案
Redis是一个高性能的键值对(key-value)缓存数据库,Redis集群采用Hash算法对数据空间进行分片,以槽(Slot)为基本数据单位,共分成214个槽(16384),槽从0开始编号截止到16383。
数据存放在哪个槽里面使用CRC16(key)%16384取模,即对数据的key值先进行CRC16校验,然后再对16384进行模取,得到的结果就是该数据对应的槽。
 由上图看以看出,存储节点和槽之间有对应关系,数据key经过CRC16(key)%16384之后可以计算出属于哪个槽,所以存储节点、槽、数据之间的关系就一目了然了。
由上图看以看出,存储节点和槽之间有对应关系,数据key经过CRC16(key)%16384之后可以计算出属于哪个槽,所以存储节点、槽、数据之间的关系就一目了然了。
通信协议
根据Hash算法可以完成数据拆分和存放,那么存储节点之间怎么协同?这就需要知道一个协议Gossip,该协议主要包含消息类型,节点的槽信息等。
一个新节点假如集群的时候,是按照下图通信的:

1.新加入的节点发送Meet消息,告诉已经存在的节点“我来了”
2.已存在的节点返回一个Pong消息,告诉新加入的节点“我所拥有的数据状态信息”
3.新加入的节点定期发送Ping消息给已存在的节点
4.已存在的节点返回Pong消息给新加入的节点,3、4步会在生命周期内一直循环
Meet消息:用于通知旧节点有新的节点加入
Ping消息:用于跟其他节点通信,该消息封装了节点自身和其他节点的状态数据
Pong消息:用于响应Meet和Ping消息,封装自己的数据状态给对方
Fail消息:当一个节点发现另外的一个节点下线或者挂掉后,会向集群中其他节点广播该消息
缓存路由
缓存节点之间通过Gossip协议通信,那么客户端怎么获取缓存节点上的数据呢?因为节点是多个,且划分不同的槽,所以缓存路由就出现了,来解决客户端获取缓存数据的问题。
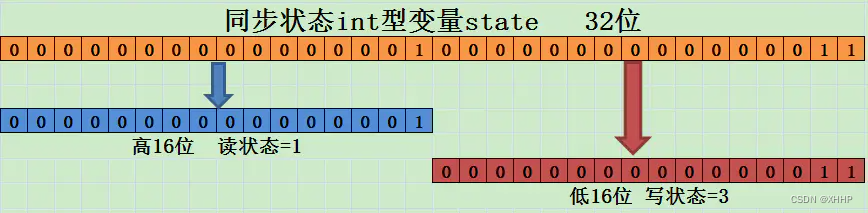
在Gossip协议的数据结构中,有个数据项是描述节点槽信息的,该数据项是一个二进制位数组,如果数组某一个元素存储的二进制位是1表示该节点存放数组下标对应的槽数据,如果二进制位是0,表示该节点不存放数组下标对应的槽数据。
 每个存储节点都有一个结构体(clusterState,源码来自redis-3.0),用来存储节点自身和缓存节点槽信息(clusterNode ),槽信息中记录着所属节点的ip和端口号。
每个存储节点都有一个结构体(clusterState,源码来自redis-3.0),用来存储节点自身和缓存节点槽信息(clusterNode ),槽信息中记录着所属节点的ip和端口号。
typedef struct clusterState {
clusterNode *myself; /* This node */
uint64_t currentEpoch;
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
int size; /* Num of master nodes with at least one slot */
dict *nodes; /* Hash table of name -> clusterNode structures */
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS];
clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS];
clusterNode *slots[REDIS_CLUSTER_SLOTS];
zskiplist *slots_to_keys;
/* The following fields are used to take the slave state on elections. */
mstime_t failover_auth_time; /* Time of previous or next election. */
int failover_auth_count; /* Number of votes received so far. */
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
int cant_failover_reason; /* Why a slave is currently not able to
failover. See the CANT_FAILOVER_* macros. */
/* Manual failover state in common. */
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
PORT_LONGLONG mf_master_offset; /* Master offset the slave needs to start MF
or zero if stil not received. */
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The followign fields are used by masters to take state on elections. */
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
PORT_LONGLONG stats_bus_messages_sent; /* Num of msg sent via cluster bus. */
PORT_LONGLONG stats_bus_messages_received; /* Num of msg rcvd via cluster bus.*/
} clusterState;
typedef struct clusterNode {
mstime_t ctime; /* Node object creation time. */
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
int flags; /* REDIS_NODE_... */
uint64_t configEpoch; /* Last configEpoch observed for this node */
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
int numslaves; /* Number of slave nodes, if this is a master */
struct clusterNode **slaves; /* pointers to slave nodes */
struct clusterNode *slaveof; /* pointer to the master node */
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
PORT_LONGLONG repl_offset; /* Last known repl offset for this node. */
char ip[REDIS_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known port of this node */
clusterLink *link; /* TCP/IP link with this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
MOVED重定向请求

ASK重定向请求

缓存扩展
不管是缓存扩展还是收缩,其实都是数据迁移的过程,数据迁移过程如下:

保障可用性
存储节点出现故障时,我们需要及时发现故障,确定存储节点故障下线有两种方式,主观下线和客观下线。
主观下线:

客观下线:

搭建
单服务器(三主三从)环境
一台centos7.9虚拟机,IP地址192.168.31.70,6个存储节点端口分别是:7000、7001、7002、7003、7004、7005。
redis版本:redis-5.0.14
redis安装步骤
tar -xzvf redis-5.0.14.tar.gz -C /usr/local
cd /usr/local/redis-5.0.14
make distclean
make install
集群安装
基本配置
cd /usr/local/redis-5.0.14
mkdir cluster-test
cd cluster-test
mkdir 7000 7001 7002 7003 7004 7005
cd 7000
vi redis.conf
redis.conf文件内容如下:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
redis.conf文件中端口号跟目录对应即可,这样一共配置6个存储节点。
启动节点
配置好后启动这六个节点服务:
cd 7000
redis-server ./redis.conf
其它5个节点服务也都启动起来,启动后我们可以看到节点id:

创建集群
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \
> 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
> --cluster-replicas 1
这6个节点组成三主三从服务,上述命令执行过程中需要输入’yes’,日志情况如下:

 创建好的集群如下:
创建好的集群如下:

访问集群
[root@local70 ~]# redis-cli -c -p 7000
127.0.0.1:7000> set foo bar
-> Redirected to slot [12182] located at 127.0.0.1:7002
OK
127.0.0.1:7002> set hello world
-> Redirected to slot [866] located at 127.0.0.1:7000
OK
127.0.0.1:7000> set name laoli
-> Redirected to slot [5798] located at 127.0.0.1:7001
OK
127.0.0.1:7001> get name
"laoli"
127.0.0.1:7001> get hello
-> Redirected to slot [866] located at 127.0.0.1:7000
"world"
127.0.0.1:7000> get foo
-> Redirected to slot [12182] located at 127.0.0.1:7002
"bar"
127.0.0.1:7002>
添加主节点
准备一个空的存储节点7006,在cluster-test下新建一个目录7006,然后在7006目录下新建一个redis.conf文件,文件内容如下:
port 7006
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
然后启动该节点服务。
[root@local70 7006]# redis-server redis.conf
启动后存储节点7006的信息如下:
I'm 643c74ed91af854c6c04398f24c7366e26e05130
加入集群
打开一个新的终端,输入命令:
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
7006终端日志:
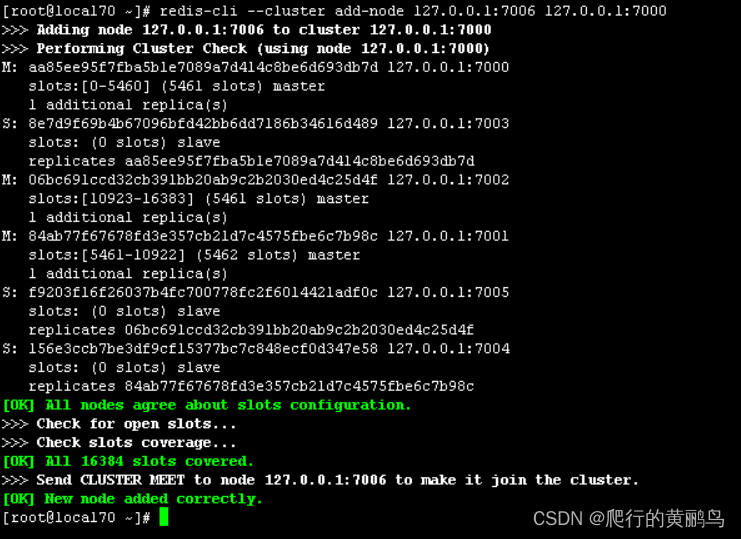 7000终端日志:
7000终端日志:
 我们连上7006节点,看是否加入集群:
我们连上7006节点,看是否加入集群:
 可以看到7006已经加入集群,但是没有数据且没被分配槽。要想分配槽给该节点需要使用重新分配功能。
可以看到7006已经加入集群,但是没有数据且没被分配槽。要想分配槽给该节点需要使用重新分配功能。
数据项表示:
- Node ID
- ip:port
- flags: master, replica, myself, fail, …
- if it is a replica, the Node ID of the master
- Time of the last pending PING still waiting for a reply.
- Time of the last PONG received.
- Configuration epoch for this node (see the Cluster specification).
- Status of the link to this node.
- Slots served…
分配槽
使用reshard命令重新分配槽。
redis-cli --cluster reshard 127.0.0.1:7000
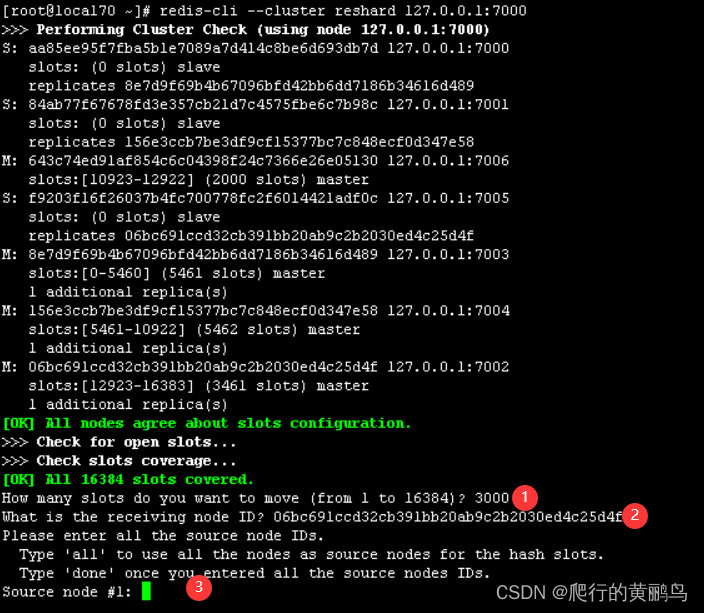 redis-cli reshard只需要指定集群中的一个节点,就可以自动发现其它节点信息,如上图信息。
redis-cli reshard只需要指定集群中的一个节点,就可以自动发现其它节点信息,如上图信息。
1、指定需要移动的槽数
2、指定目标节点的ID
3、指定源节点的ID,all表示所有节点,done表示已输入的节点,可以输入一个或多个然后输入done结束
4、执行途中还有一个确认的地方,输入yes或no
重新分配完后,可以使用如下命令查看槽分配情况。
redis-cli -p 7000 cluster nodes
添加从节点
添加从节点有两种方式。
第一种方式:随机分配副本。该命令中没有指定向哪个主节点添加副本,所以首先会向副本较少的主节点中随机分配副本。
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave
第二种方式:指定主节点。该命令中我们将新副本分配给特定的主副本。
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave --cluster-master-id 指定的主节点ID
切换从节点
在上一小节添加的从节点,如果我们想把7006节点变更成其它主节点的副本,那么我们使用如下命令即可:
[root@centos7-84 ~]# redis-cli -p 7006
127.0.0.1:7006> cluster replicate 指定的主节点ID
变更后查看变更结果:
$ redis-cli -p 7000 cluster nodes | grep slave | grep 指定的主节点ID
删除节点
删除命令中第一个参数是集群中的任意一个节点,第二个参数是待删除的节点ID
redis-cli --cluster del-node 127.0.0.1:7000 待删除的节点ID
也可以使用此命令删除主节点,但是主节点必须先变成空节点才可以。删除主节点还有一种方式,是在其一个副本上执行手动故障切换,待其变为新主节点的副本时进行删除。
手动切换故障
只能在副本执行的命令:
CLUSTER FAILOVER [FORCE | TAKEOVER]

我要把上图的7001和7006进行故障切换,操作如下:
[root@centos7-84 ~]# redis-cli -p 7006
127.0.0.1:7006> CLUSTER FAILOVER
OK
127.0.0.1:7006> cluster nodes
17881b3c82499bfb1485dc6c0737d261fef71216 127.0.0.1:7005@17005 slave ee65d2f969160a957f2a6504d669a89987e4a2ff 0 1670316745000 7 connected
ee65d2f969160a957f2a6504d669a89987e4a2ff 127.0.0.1:7006@17006 myself,master - 0 1670316744000 7 connected 5461-10922
600dfee9d94379f099fb2263b9d7a6bc169b9f5b 127.0.0.1:7000@17000 master - 0 1670316745000 1 connected 0-5460
d097e18da56b8a7e35dad9f227e2337d19a60f56 127.0.0.1:7001@17001 slave ee65d2f969160a957f2a6504d669a89987e4a2ff 0 1670316746492 7 connected
3e171e4c2eec692d68755e0584cb74845b3e1a28 127.0.0.1:7002@17002 master - 0 1670316745487 3 connected 10923-16383
2236349a6f2bae8b2f8e20215a1bd7c3ef33878d 127.0.0.1:7003@17003 slave 3e171e4c2eec692d68755e0584cb74845b3e1a28 0 1670316746592 3 connected
cac0ed10ae257419a4e9b2b75d6c903065bbd94a 127.0.0.1:7004@17004 slave 600dfee9d94379f099fb2263b9d7a6bc169b9f5b 0 1670316746000 1 connected
127.0.0.1:7006>
从操作日志里可以看到7006称为主节点,7001和7005都成为了从节点,下图也可以看出:

升级节点
升级副本节点简单易行,停止服务更新后重启即可。
升级主节点需要使用CLUSTER FAILOVER命令,将其变为副本,再按照从节点升级一样操作即可。
问题记录
安装gcc
我新装的虚拟机没有gcc包,执行make会报错,所以需要执行gcc安装
yum install gcc-c++ -y
jemalloc/jemalloc.h:没有那个文件或目录
安装gcc包后,再执行make命令的时候,报如下错误:
[root@laoli81 redis-5.0.14]# make
cd src && make all
make[1]: 进入目录“/usr/local/redis-5.0.14/src”
CC Makefile.dep
make[1]: 离开目录“/usr/local/redis-5.0.14/src”
make[1]: 进入目录“/usr/local/redis-5.0.14/src”
CC adlist.o
In file included from adlist.c:34:0:
zmalloc.h:50:31: 致命错误:jemalloc/jemalloc.h:没有那个文件或目录
#include <jemalloc/jemalloc.h>
^
编译中断。
make[1]: *** [adlist.o] 错误 1
make[1]: 离开目录“/usr/local/redis-5.0.14/src”
make: *** [all] 错误 2
解决方式有如下两种方式,我执行的第一个:
[root@laoli81 redis-5.0.14]# make MALLOC=libc
[root@laoli81 redis-5.0.14]# make distclean
安装net-tools
安装net-tools包,可以查看端口
yum install net-tools -y
关闭防火墙
自己实验用,所以关掉防火墙
[root@laoli81 redis-5.0.14]# systemctl stop firewalld






![[windows] opencv + ffmpeg + h264 + h265 源码编译教程](https://img-blog.csdnimg.cn/622f9556e27349139fdf00c729bd86bb.png)