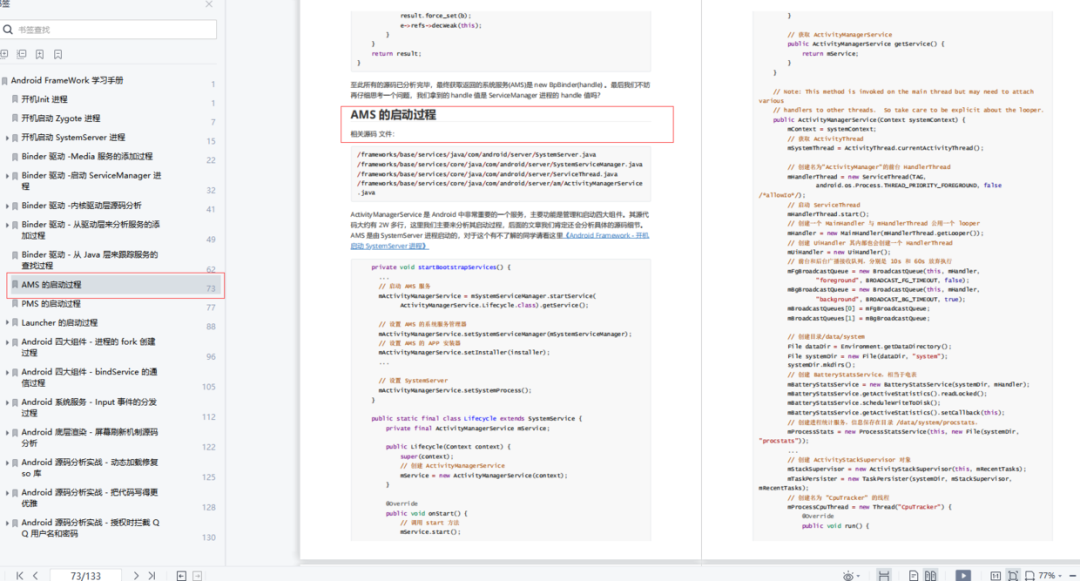
近期评论区有小伙伴私信需要灰狼优化算法GWO法化VMD的,所以打算再写一篇。
与之前的文章不同,这篇文章作者考虑到,大家有可能会以最小样本熵或最小包络熵为适应度函数的,在这个程序中将会直接把样本熵和包络熵集成,在代码中选择“1”代表包络熵,选择“2”代表样本熵,方便大家自由切换。
接下来一段摘自一篇文献中,解释为什么样本熵也可以作为适应度函数:
样本熵(sample entropy)的物理含义与近似熵相似,它是用来测量信号中出现新模式的概率,并测量其复杂性。随着新模型生成的可能性增加,这个时间序 列就变得更加复杂。样本熵的优点是计算结果与数据的长度无关,其计算式的参数中m和r对样本熵影响 程度是一致的,因此样本熵拥有更好地一致性。 对于信号数据而言,样本熵值越低,则其样本序列自我相似度愈高;反之,其样本序列便越复杂。
同样以西储大学数据集为例,选用105.mat中的X105_BA_time.mat数据。没有数据的看我这篇文章。西储大学轴承数据处理--附MATLAB代码_西储大学轴承数据matlab分析_今天吃饺子的博客
首先进行VMD分解,采用灰狼优化算法(GWO)对VMD的两个关键参数(惩罚因子α和模态分解数K)进行优化,以最小包络熵或最小样本熵为适应度值。
灰狼优化算法与上一期的黏菌优化算法,速度不相上下,这是因为灰狼优化算法在程序的每次循环中只调用了一次目标函数。
老规矩,先上结果图:
首先是以最小样本熵为适应度函数的结果图:



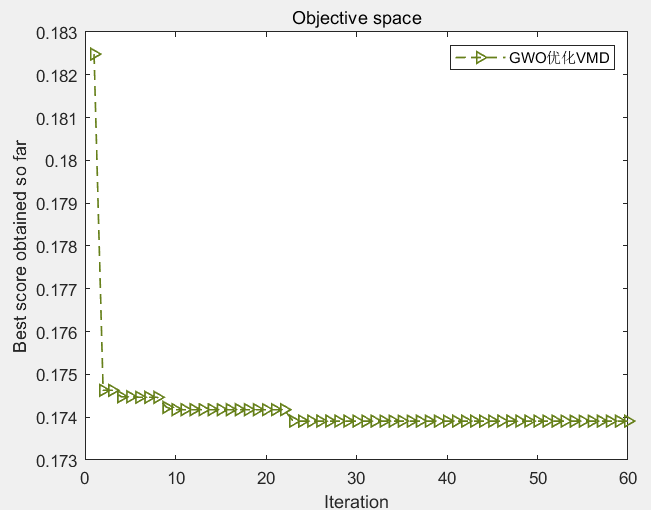
然后是以最小包络熵为适应度函数的结果图:


![]()
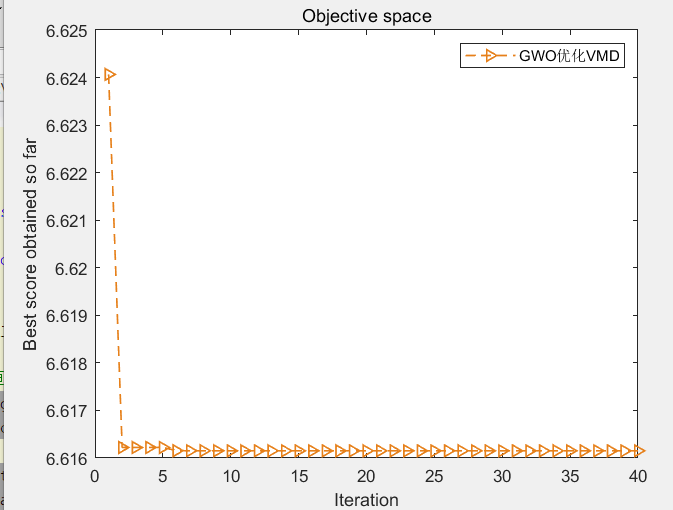
部分代码:
%%
%% 以最小包络熵或最小样本熵为目标函数,采用SMA算法优化VMD,求取VMD最佳的两个参数
clear all
clc
addpath(genpath(pwd))
load 105.mat
D=2; % 优化变量数目
lb = [100 3];
ub = [2500 10];
dim = 2;
Max_iter=40; % 最大迭代数目
SearchAgents_no=15; % 种群规模
xz = 2; %xz=1 or 2, 选择1,以最小包络熵为适应度函数,选择2,以最小样本熵为适应度函数。
if xz == 1
fobj=@EnvelopeCost;
else
fobj=@SampleCost;
end
da = X105_DE_time(6001:7000); %这里选取105的DEtime数据
[Alpha_score,Alpha_pos,Convergence_curve]=GWO(SearchAgents_no,Max_iter,lb,ub,dim,fobj,da);
%画适应度函数图
figure
plot(Convergence_curve,'Color',[0.7 0.1 0.1],'Marker','>','LineStyle','--','linewidth',1);
title('Objective space')
xlabel('Iteration');
ylabel('Best score obtained so far');
legend('GWO优化VMD')
display(['The best solution obtained by GWO is : ', num2str(round(Alpha_pos))]); %输出最佳位置
display(['The best optimal value of the objective funciton found by GWO is : ', num2str(Alpha_score)]); %输出最佳适应度值大家注意看到xz这个变量,当选择是 xz=1,就是以最小包络熵为适应度函数,选择 xz=2,就是以最小样本熵为适应度函数。这样大家切换起来就很方便了!
完整代码获取:下方卡片回复关键词:GWOVMD
觉着不错的给博主留个小赞吧!您的一个小赞就是博主更新的动力!谢谢!
参考文献:
[1]李颖,王鹏,吴仕虎,巴鹏.基于AO-VMD的往复压缩机故障特征提取方法[J].机电工程,2023,40(05):673-681.



![[内核笔记1]内核文件结构与缓存——inode和对应描述](https://img-blog.csdnimg.cn/img_convert/4bc49353a2c0128939f28fd04235cd4a.png)