本文分享了如何基于 OceanBase 4.3.3 bp1 社区版的向量检索能力,通过几条简单的命令,快速搭建一个定制化的专属游戏助手的过程。
背景
在 OceanBase 最新推出 V 4.3.3 免费试用的同时,也同时发布了几个基于OB Cloud 的向量能力,搭建 AI 应用的Demo教程。其中, 基于文档知识库搭建 AI 助手的Demo,受到了很多用户的关注,我们也在线下的 AI动手实验营里和大家一起进行了搭建。
这里,我们基于这个AI助手 Demo的基本步骤,用 OceanBase 社区版 4.3.3 bp1 ,改造搭建一个《黑神话:悟空》的 RAG 智能问答助手,也给大家分享一下搭建过程中如何避坑。
关于 OceanBase 的向量检索能力
OceanBase 在 4.3.3 bp1 版本中,支持了向量数据类型(Vector),提供的向量能力包括:新的向量数据类型、向量索引以及向量搜索 SQL 操作符等几项功能,它使得 OceanBase 数据库能够将文档、图像及其他非结构化数据的语义内容存储为 embedding 向量,并使用这些 embedding 向量快速进行相似性查询。
向量检索技术已经广泛应用于多个业务场景,现在也有越来越多的 OceanBase 用户,开始提出了向量检索的需求。以下是几个使用向量检索的具体例子:
- 检索增强生成(RAG)
- 利用向量检索能能力可以快速检索大型知识库中的相关文档向量,为生成式任务提供信息支撑,从而改善答案的质量和相关性;
- 2023 年,RAG 是基于 LLM 系统最受欢迎的架构,有非常多的产品都是基于 RAG 构建。例如支付宝的智能体开发平台 “百宝箱”,以及蚂蚁集团开源的 DB-GPT 项目,就都是在此基础上进行的微调。
- 生物识别
- 典型的场景是人脸识别:利用一些特征提取的算法将人脸转换为数值特征向量,并在高维空间中快速匹配和检索相似特征,从而实现高效准确的身份辨识。
- 多模数据搜索推荐:
- 在实现多模态搜索时,向量检索是一种常用的技术。为了在不同数据模态之间进行检索,一般会先将所有模态的数据转换成统一的向量表示形式,即将图像、文本、音视频等数据编码为向量。一旦所有数据都被转换成向量形式,就可以在共同的向量空间中计算不同模态数据之间的相似度。
- 文搜图,图搜文用的都是这个思路。
这里不多啰嗦,给各位推荐一个叫《向量数据库是什么?为啥 AI 大模型离不开它?》的视频,时长只有三分钟,可以帮助大家快速理解视频标题中的问题。
向量数据库是什么?为啥AI大模型离不开它?
构建你自己的专属答疑助手
组件介绍
AI 助手 Demo 中的介绍虽然是 “构建一个 RAG 聊天机器人,用来回答与 OceanBase 文档相关的问题”,不过大家可以偷梁换柱,把 OceanBase 官网文档改成任何你更感兴趣的数据源。
下面的内容,会记录通过试用 OceanBase 向量检索的能力的过程,为大家使用 OceanBase 构建专属的聊天机器人 “趟一遍坑”。
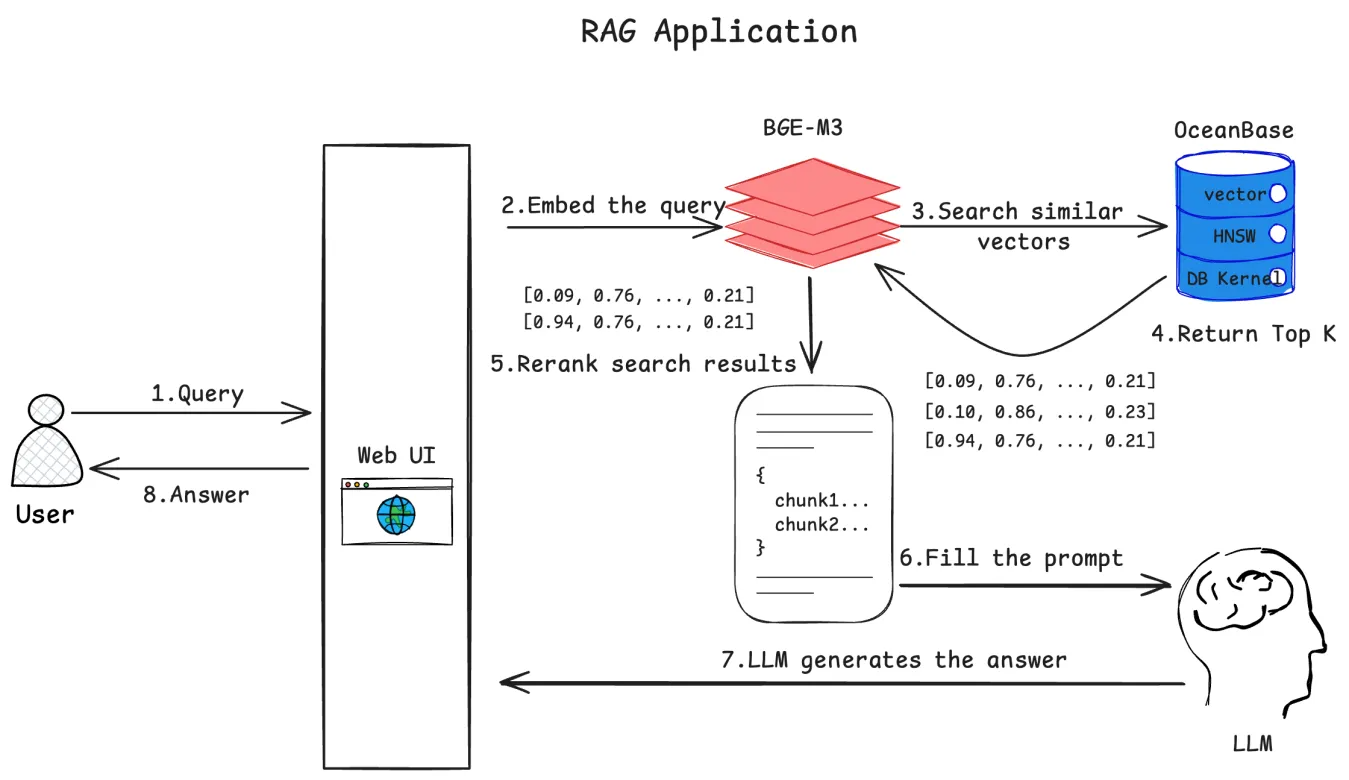
这张图画的是Demo教程中关于 AI 助手的简单架构,再补充说明几点:
- OceanBase 在这个机器人中的作用,是存储和查询数据源对应的向量数据的数据库。
- 先要通过 BGE-M3 模型,把数据源转换为向量。
- 然后通过智谱 AI 的 LLM 能力分析用户问题,基于从 OceanBase 向量数据库中检索到的相关内容,给出答案。
趟坑记录
部署过程可以根据 AI 动手实验营里的步骤 https://github.com/oceanbase-devhub/ai-workshop-2024 来就行,我在一个从来没装过任何开发环境的 Mac 上试了下,只需要复制黏贴几条命令,整体还是比较顺畅的。这里简单记录几个部署过程中可能会踩到的小坑。
首先需要 clone 这个项目下来,文档里虽然没写,但是大家肯定也都知道。
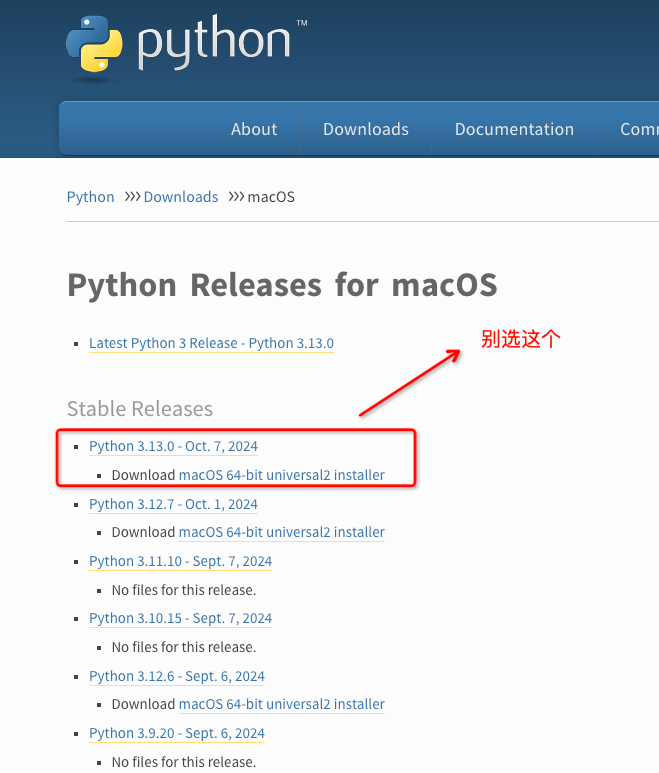
git clone https://github.com/oceanbase-devhub/ai-workshop-2024.git然后文档里写了需要安装 Python 3.9+,详见:Python Releases for macOS | Python.org。这里注意版本千万不能选最新发布的 3.13,否则可能绘因为各种依赖的组件还没适配这个最新版本,导致一些意外。因为这个问题,遇到好几个报错,一个个都解完了(为解决这几个报错,还安装了 Fortran 编译器和 Rust),最后才看到是 Python 版本过高导致的(前面的那些报错的根因其实也都是 Python 版本的问题,血的教训):
error: the configured Python interpreter version (3.13) is newer than PyO3's maximum supported version (3.12)推荐直接去官网下载 pkg 安装包。我降级到 Python 3.12 的时候是编译安装的,超级慢,强烈不推荐。
最后如果你已经有了 OceanBase 4.3.3 bp1 及以上版本的测试环境,直接用就行,好像只会创建一张由向量数据类型组成的表而已,没必要重新通过 docker 部署一个新的 OceanBase 集群。表结构如下:
MySQL [test]> desc corpus;
+----------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+---------------+------+-----+---------+-------+
| id | varchar(4096) | NO | PRI | NULL | |
| embedding | VECTOR(1024) | YES | | NULL | |
| document | longtext | YES | | NULL | |
| metadata | json | YES | | NULL | |
| component_code | int(11) | NO | PRI | NULL | |
+----------------+---------------+------+-----+---------+-------+
5 rows in set (0.00 sec)其中的 embedding 列就是一个超多维的向量类型,用于快速进行相似性查询。
准备数据
嘿嘿,大家可以在这一步做些手脚,对应原文档里的 5.2 小节。文档中的描述是 “克隆 OceanBase 开源文档仓库并处理它们,生成文档的向量数据和其他结构化数据后将数据插入到我们部署好的 OceanBase 数据库中”。
但是 OceanBase 官网文档实在太多,导入和解析会非常耗时(取决于网络和其他硬件资源)。恰巧前一段儿时间 “试用” 了下《黑神话:悟空》,觉得其中的《影神图》(游戏角色人物小传)写得十分精彩。为了能够早点儿回家打虎先锋,这里偷懒,对原文档的命令进行了一点儿调整。

我把原始步骤里的一大批 OceanBase 文档替换成了游戏里的《影神图》(这里需要注意的是,数据源的原始资料暂时还只支持 markdown 格式的文件),执行的内容被 “篡改” 成了如下命令序列:
cd doc_repos
git clone --single-branch --branch master https://github.com/liboyang0730/black-myth-wukong-portraits.git
cd ..
poetry run python convert_headings.py \
doc_repos/black-myth-wukong-portraits/docs
poetry run python embed_docs.py --doc_base doc_repos/black-myth-wukong-portraits/docs效果展示
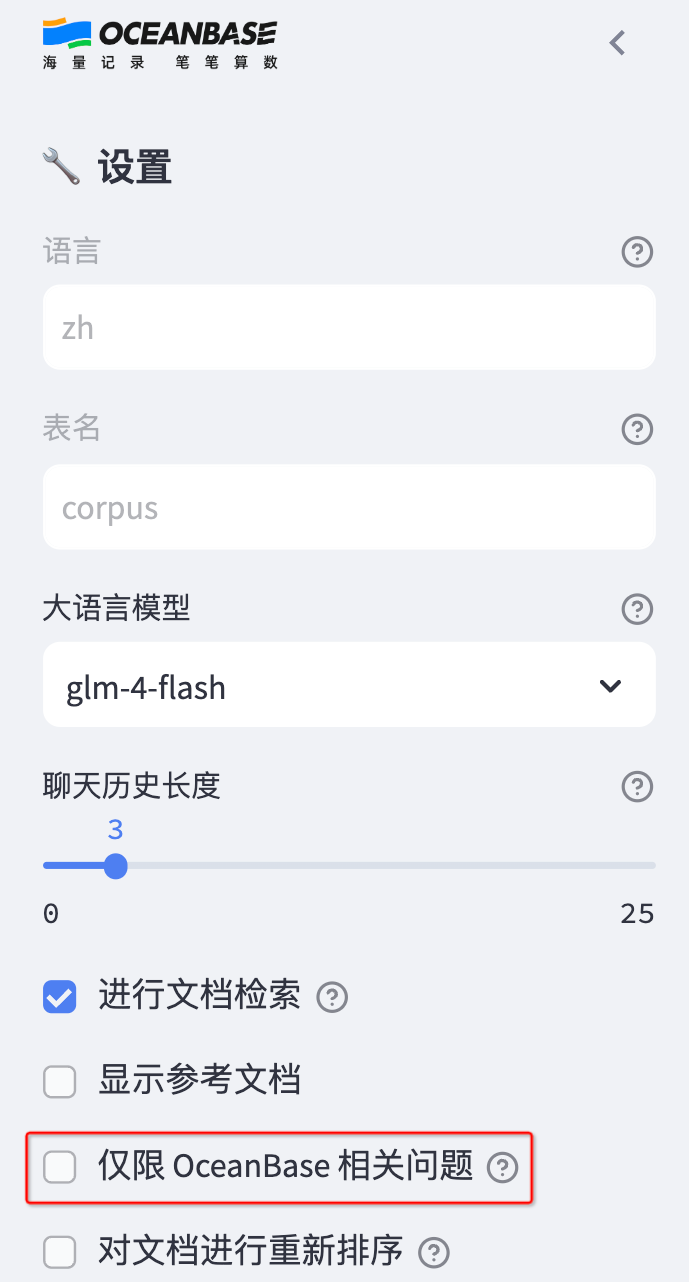
展示之前,需要先关掉 “仅限 OceanBase 相关问题” 的选项:
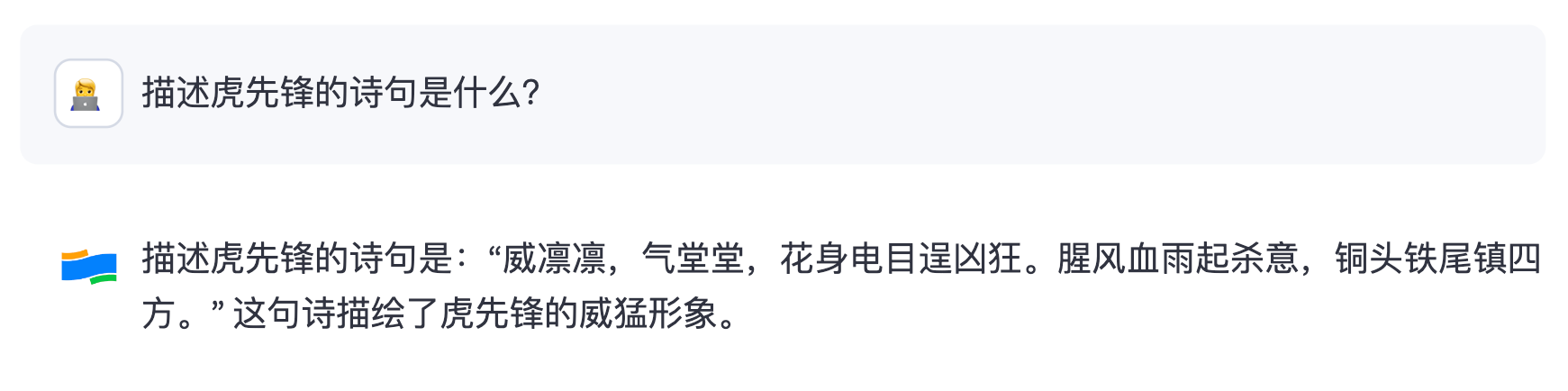
展示一下试用效果,先问它三个《影神图》中存在的信息:
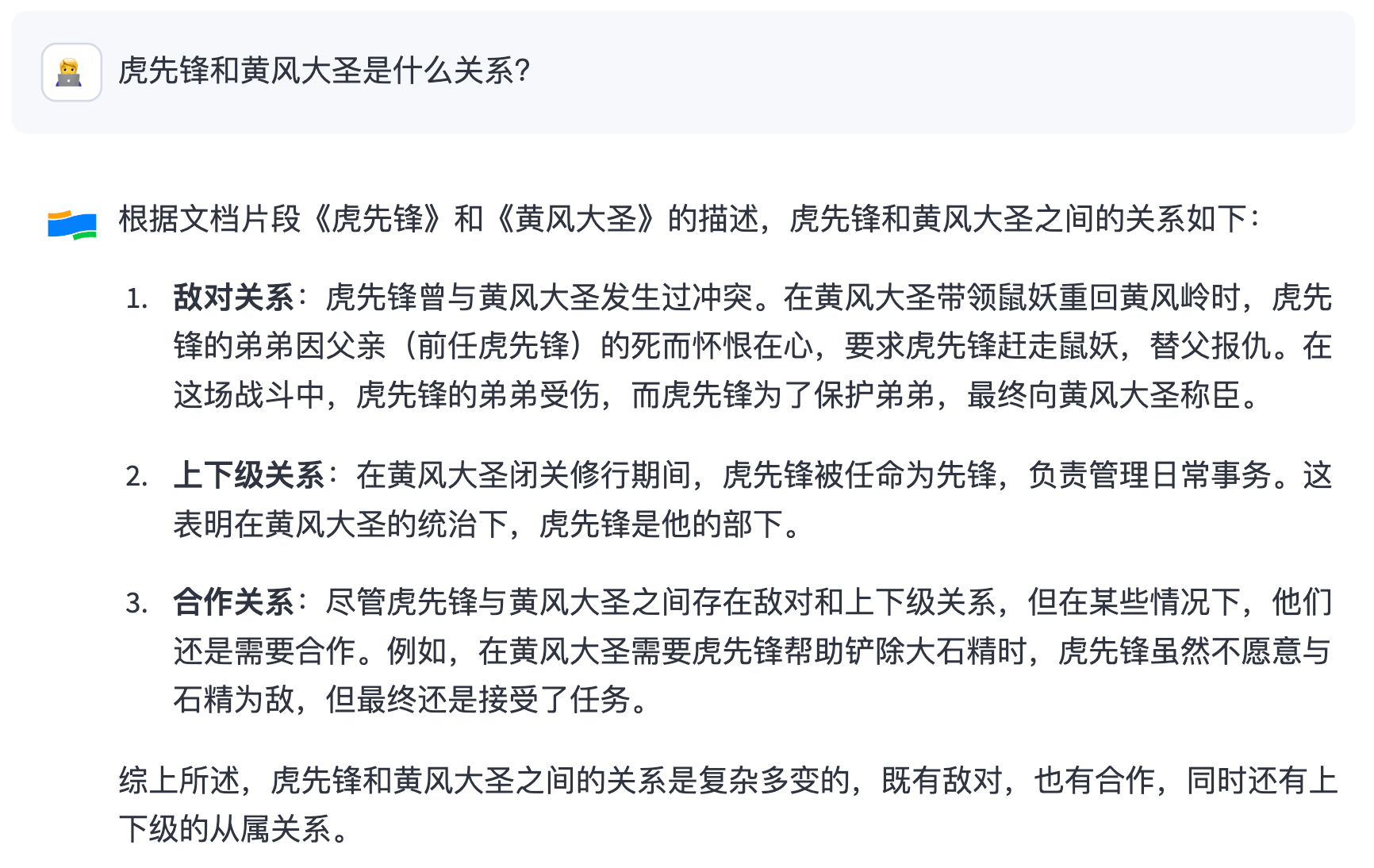
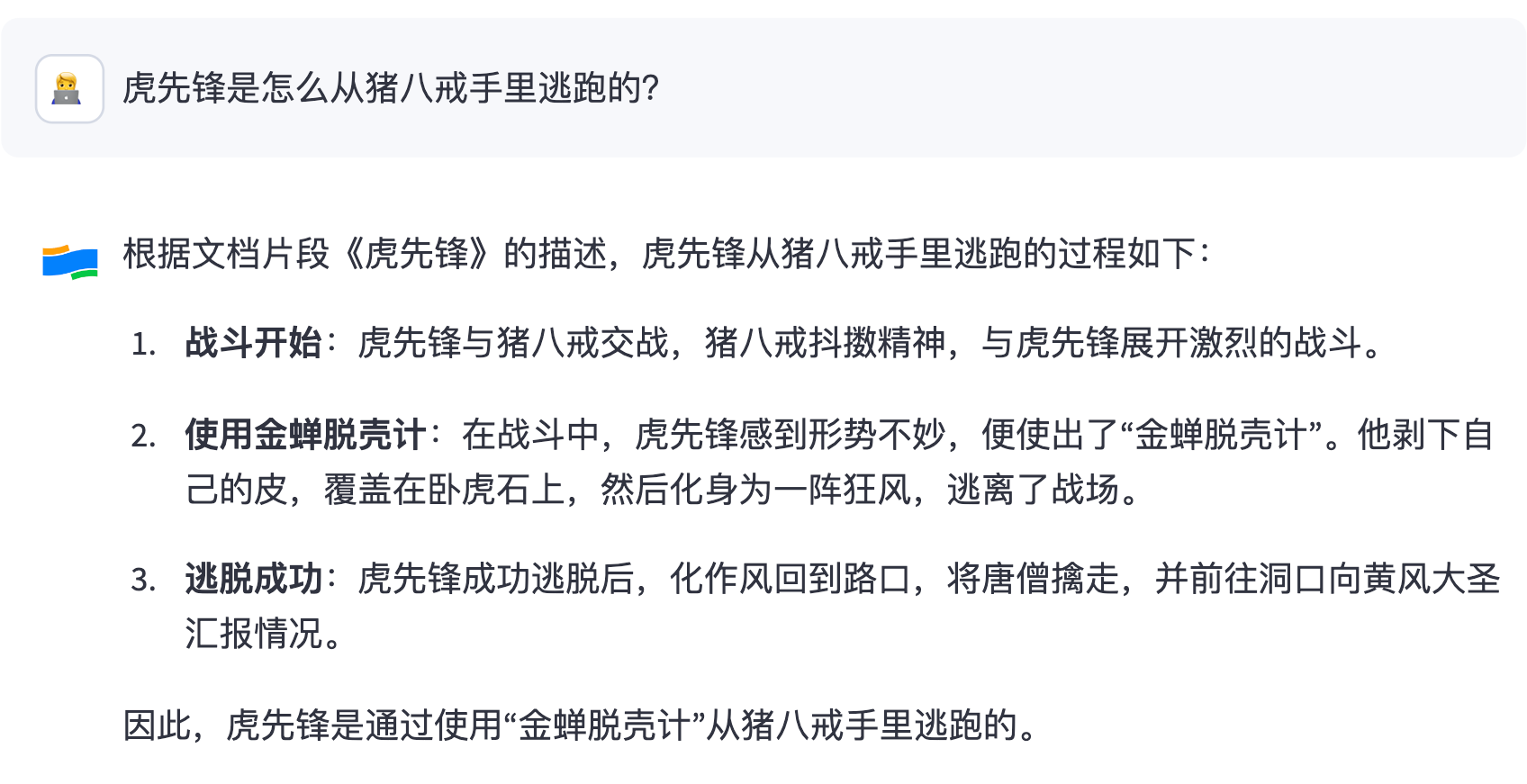
如果你要问它数据源里不存在的内容,它可能就要一本正经地胡说八道,或者让你 “听君一席话,如听一席话” 了。例如:


所以如果希望进一步提升这个游戏助手的智能程度,那就还需要更多的数据源作为输入,只靠《影神图》还是不够的。个人理解,如果要想让游戏助手回答上面的一个问题,指导玩家如何打赢敌人,至少还需要再导入 “战斗系统” 和 “游戏玩法” 的资料。
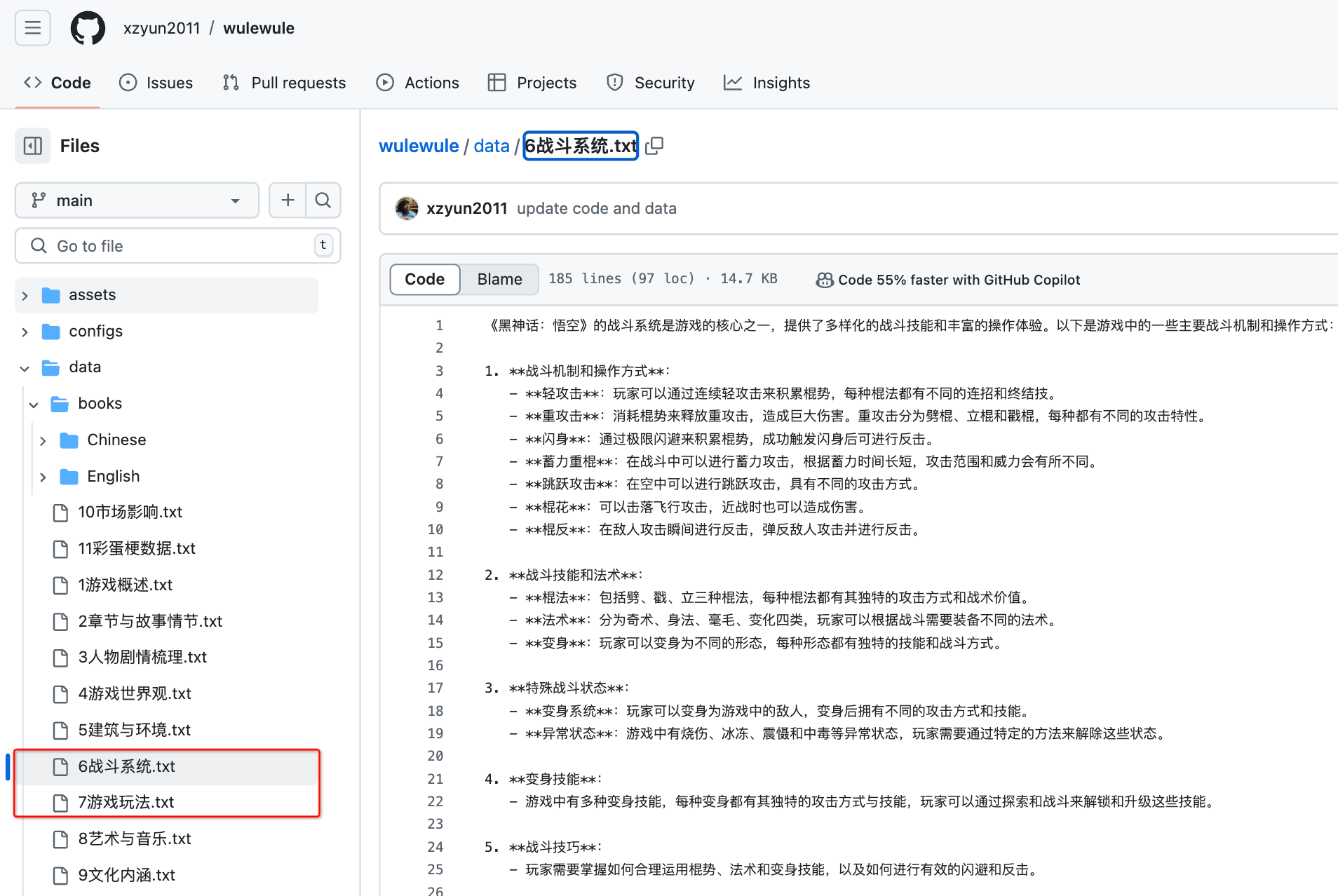
虽然网络上有很多游戏资料和攻略,但是本文终究只是个示例,就不再赘述后续如何逐步完善这个助手的过程了。
By the way:回答问题时,如果有显示相关参考文档的需求,在 rag/doc_rag.py 里仿照 oceanbase-doc 加一行 black-myth-wukong-portraits 的内容,然后在页面设置里勾上 “显示参考文档” 就好了。
liboyang@B-N7YMPHGD-0333 ai-workshop-2024 % git diff rag/doc_rag.py
diff --git a/rag/doc_rag.py b/rag/doc_rag.py
index c385256..4a9f88a 100644
--- a/rag/doc_rag.py
+++ b/rag/doc_rag.py
@@ -74,6 +74,7 @@ def doc_search_by_vector(
supported_components = cm.keys()
replacers = [
+ (r"^.*black-myth-wukong-portraits", "https://github.com/liboyang0730/black-myth-wukong-portraits/blob/master"),
(r"^.*oceanbase-doc", "https://github.com/oceanbase/oceanbase-doc/blob/V4.3.3"),
(r"^.*ocp-doc", "https://github.com/oceanbase/ocp-doc/blob/V4.3.0"),
(r"^.*odc-doc", "https://github.com/oceanbase/odc-doc/blob/V4.3.1"),最后欢迎大家试用 OceanBase 4.3.3及以上版本的向量能力,通过几条简单的命令,快速搭建一个定制的 “智能答疑机器人”~

What's more?
- 11 月 28日晚 7点,OceanBase 视频号将为你带来 《AI 动手实战营 :基于 OceanBase + LLM 打造属于你的智能助手》,欢迎大家扫码预约

- 上海的朋友,也欢迎参加 12月7日的 OceanBase 城市交流会 ,现场也有 AI动手实验营。点击报名 >>

- oceanbase-devhub 除了本文介绍的答疑机器人,还介绍了如何利用 OceanBase 的向量能力,通过几条命令构建一个以图搜图的应用,详见:https://github.com/oceanbase-devhub/image-search
参考资料
- OceanBase 项目仓库:https://github.com/oceanbase/oceanbase
- OceanBase 数据库 V4.3.3 版本发布记录:https://www.oceanbase.com/product/oceanbase-database-community-rn/releaseNote#V4.3.3
- OceanBase AI workshop:https://github.com/oceanbase-devhub/ai-workshop-2024
- OceanBase Image Search:https://github.com/oceanbase-devhub/image-search
- B 站视频《向量数据库是什么?为啥 AI 大模型离不开它?》:https://www.bilibili.com/video/BV1ph411A7Ke
- 《黑神话:悟空》中的《影神图》:https://github.com/liboyang0730/black-myth-wukong-portraits



















