Spark SQL是基于ANTLR实现的,前文中有关于ANTLR的介绍文章《ANTLR实战》和《设计模式之访问者模式》,这篇文章主要介绍的内容是AstBuilder类。
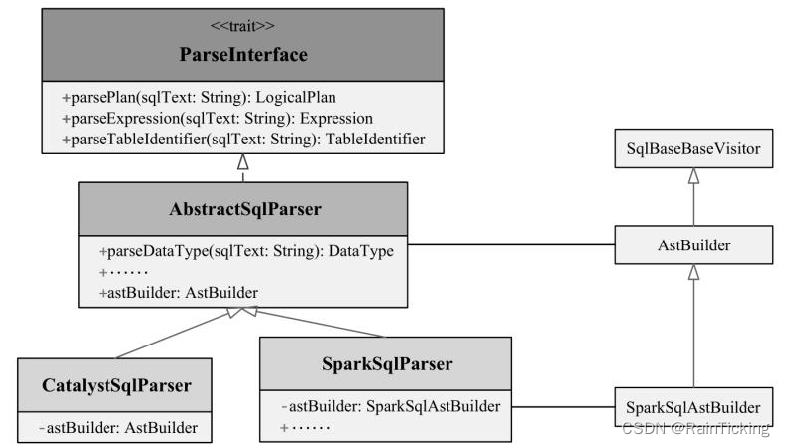
Catalyst中提供了直接面向用户的ParseInterface接口,该接口中包含了对SQL语句、Expression表达式和TableIdentifier数据表标识符的解析方法。AbstractSqlParser是实现了ParseInterface的虚类,其中定义了返回AstBuilder的函数。
整个SQL解析相关的实现如下图所示,其中CatalystSqlParser仅用于Catalyst内部,而SparkSqlParser用于外部调用。其中,比较核心的是AstBuilder,它继承了ANTLR4生成的默认SqlBaseBaseVisitor,用于生成SQL对应的抽象语法树AST(UnresolvedLogicalPlan);SparkSqlAst-Builder继承AstBuilder,并在其基础上定义了一些DDL语句的访问操作,主要在SparkSqlParser中调用。
当面临开发新的语法支持时,首先需要改动的是ANTLR4文件(在SqlBase.g4中添加文法),重新生成词法分析器(SqlBaseLexer)、语法分析器(SqlBaseParser)和访问者类(SqlBaseVisitor接口与SqlBaseBaseVisitor类),然后在AstBuilder等类中添加相应的访问逻辑,最后添加执行逻辑。
为加深理解Spark SQL生成的语法树结构,可以将Spark SQL编译器部分剥离出来,构造一个类似AstBuilder的访问者类MyVisitor,在实现的访问方法中输出visitor访问操作。类似于下面的代码逻辑,实现SqlBaseBaseVisitor中的所有方法。
public class MyVisitor extends SqlBaseBaseVisitor<String>{
public String visitSingleStatement(SqlBaseParser.SingleStatementContext ctx) {
System.out.println("visitSingleStatement");
return visitChildren(ctx);
}
.........................
}
MyVisitor中访问方法的类型为String(AstBuilder中的SqlBaseBaseVisitor为AnyRef类型,返回LogicalPlan类型),但不会返回字符串,仅用于输出访问的路径和对AST的理解。构造上述访问者类之后,接下来还需要构造一个Driver程序来驱动上述访问过程,测试下面的SQL语句。
SELECT name FROM student WHERE age > 18
为了便于理解Spark SQL的解析过程,可看GitHub上的项目 ANTLR4-SqlBase。
在Catalyst中,SQL语句经过解析,生成的抽象语法树节点都以Context结尾来命名。如下图所示为案例SQL语句生成的抽象语法树。
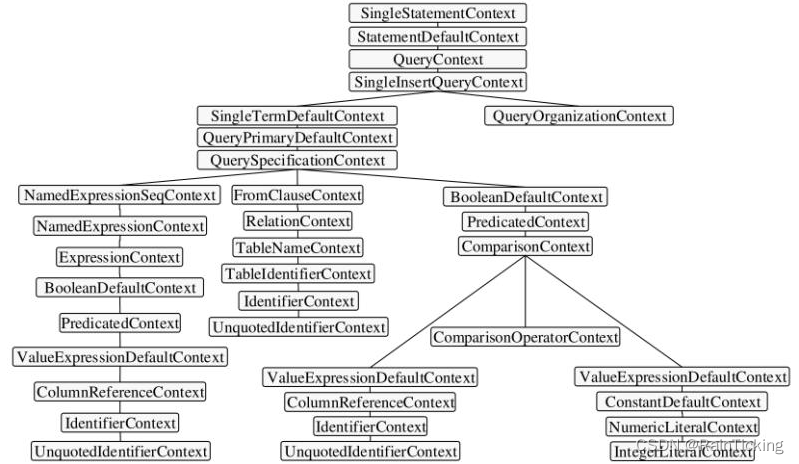
从语法树可以看到,SingleStatementContext是根节点,但是在访问该节点时一般什么都不做,只递归访问子节点。整个遍历访问操作中比较重要的是包含多个子节点的节点。例如QuerySpecificationContext节点,一般将数据表和具体的查询表达式整合在一起。左边的一系列节点对应select表达式中选择的列,中间的From ClauseContext为根节点的系列节点对应数据表,右边的一系列节点则对应where条件中的表达式。
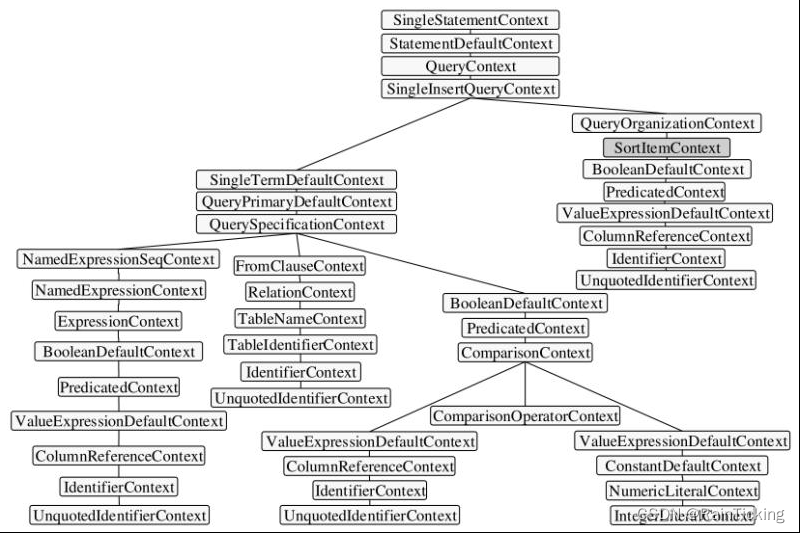
上述语法树的结构比较通用,其他类型的SQL语句生成的语法树大同小异,这里假设在上述语句中加入排序的操作。
SELECT name FROM student WHERE age > 18 order by id desc
加入排序操作后生成的语法树如图4.5所示,可以看到新的语法树在QueryOrganization-Context节点下面加入了SortItem Context节点,代表数据查询之后所进行的排序操作。一般来讲,QueryOrganizationContext为根节点所代表的子树中包含了各种对数据组织的操作,例如Sort、Lim it和W indow算子等。
从上面案例可以看出,即使非常简单的SQL语句,其语法树的节点也非常多。特别是当查询涉及聚合操作、Join操作和嵌套的子查询时,整棵语法树会变得非常庞大,难以一次完成展示。