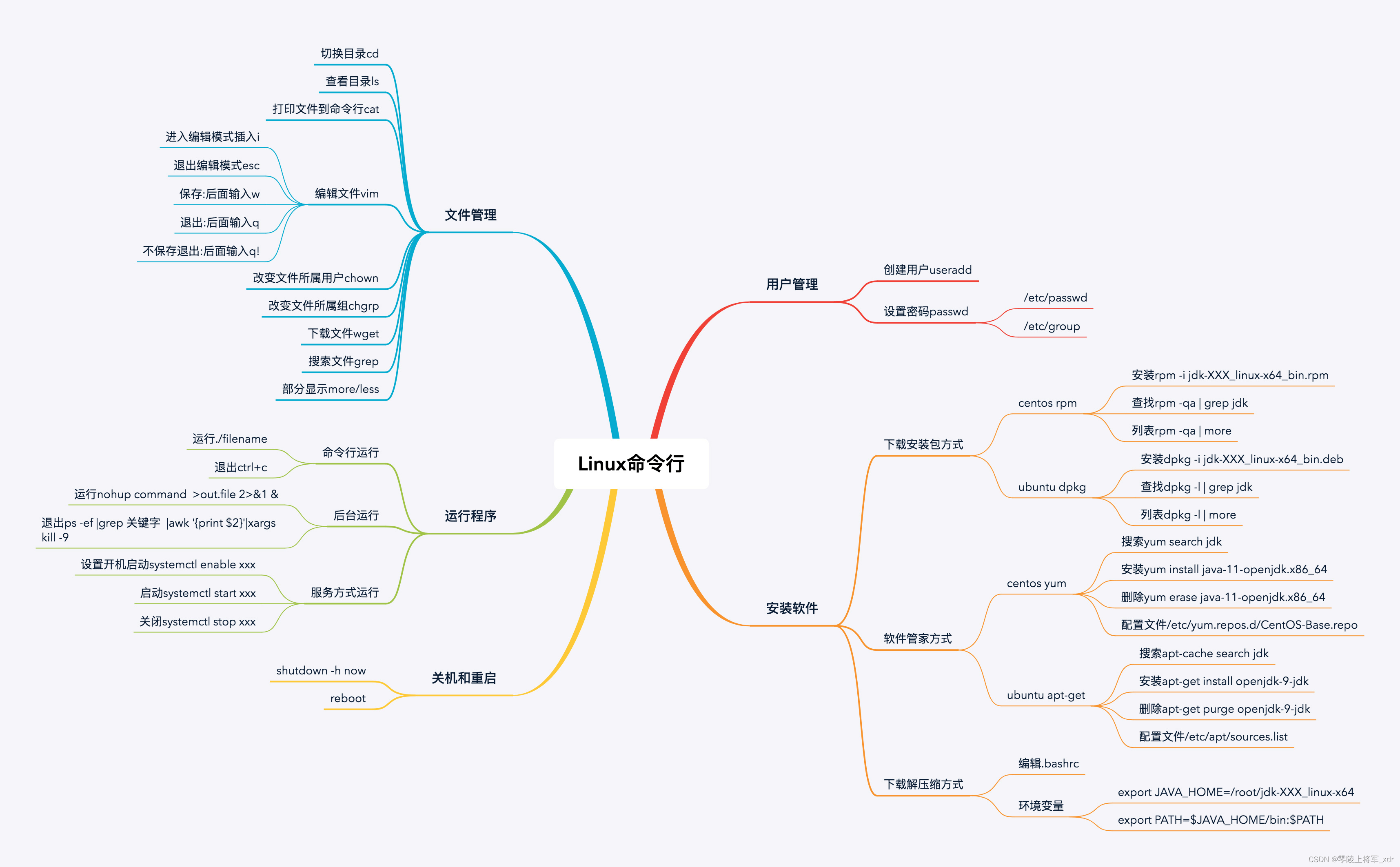
IO操作
概述
根据用户态和内核态的划分,用户态的进程是不能直接访问各种硬件资源的,只能向内核发起系统调用,由内核完成一系列操作再切回用户进程。
用户进程每次想要访问硬件资源(包括读和写)就叫做一次IO。
IO共有5大类,分别是阻塞IO,非阻塞IO,IO多路复用,信号驱动IO以及异步IO,其中前四种都属于同步IO,在进行实际的IO操作时进程都会陷入阻塞状态。
文件描述符FD
在正式介绍IO之前,我们需要先清楚文件描述符这一定义。简单来说,文件描述符就是一个数字,这个数字是内存中文件表的索引,用户进程可以根据这一数字在内核中定位到具体想要访问的文件。
Linux系统中一共有三个与fd相关的表,分别是file descriptor table,system file table以及inode table。
每个用户进程都会维护着一个属于自己的file descriptor table,代表当前进程所关注的fd,他的key是文件描述符fd,value是该文件描述符在system file table中的索引。该表的前3位0,1,2分别代表标准输入,标准输出和错误输出,这是每个用户进程都会维护的。
system file table位于内核,系统会在其中为每次IO操作创建一个属于它自己的entry,即使是同一进程连续打开一个文件多次的情况,也会生成多个对应的system file table entry。该entry中保存着对应的实际文件在inode table中的地址,同时还保存着一个offset。
之所以要每次IO一个entry,是因为每次IO都有自己独立的offset。
inode table位于内核,其中保存着文件在磁盘中的具体位置,由于Linux系统万物皆文件的特性,每个硬件(包括键盘、鼠标、网卡等)都抽象为了一个对应的文件,因此该文件系统可以涵盖所有IO操作。
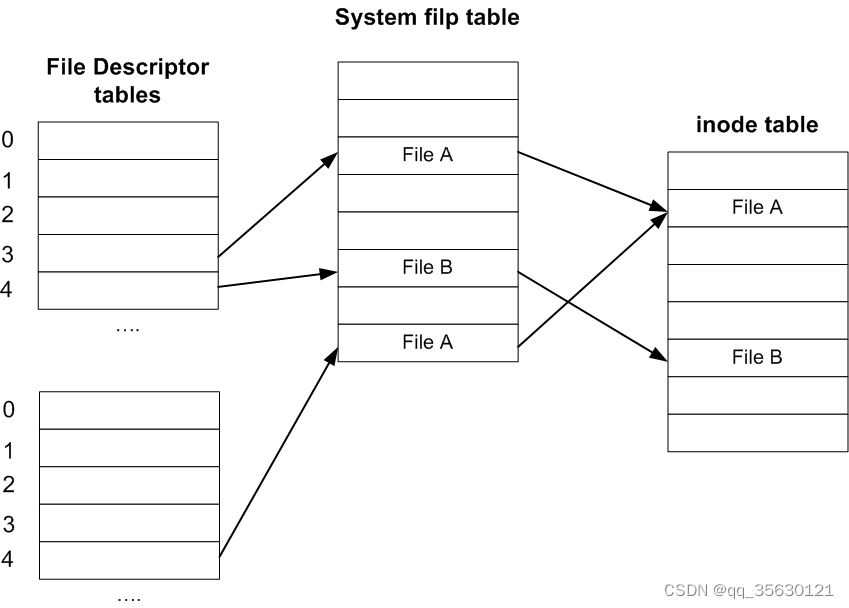
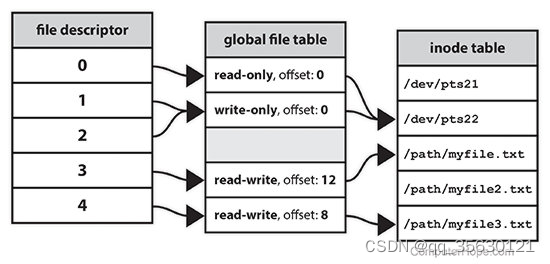
之所以要有文件描述符,是因为只有内核有直接操作文件系统的权限。在用户想要访问一个文件时,需要向内核发起一次系统调用,内核首先会在system file table中创建一个对应文件的entry,接着会将对应的索引,即文件描述符返回给用户。用户如果想对指定的文件进行后续操作,需要将对应的文件描述符再传给内核,内核就知道用户想要操作哪个文件了。
总之文件描述符相当于内核给用户提供的一种类似于通信信号一样的东西。
IO流程
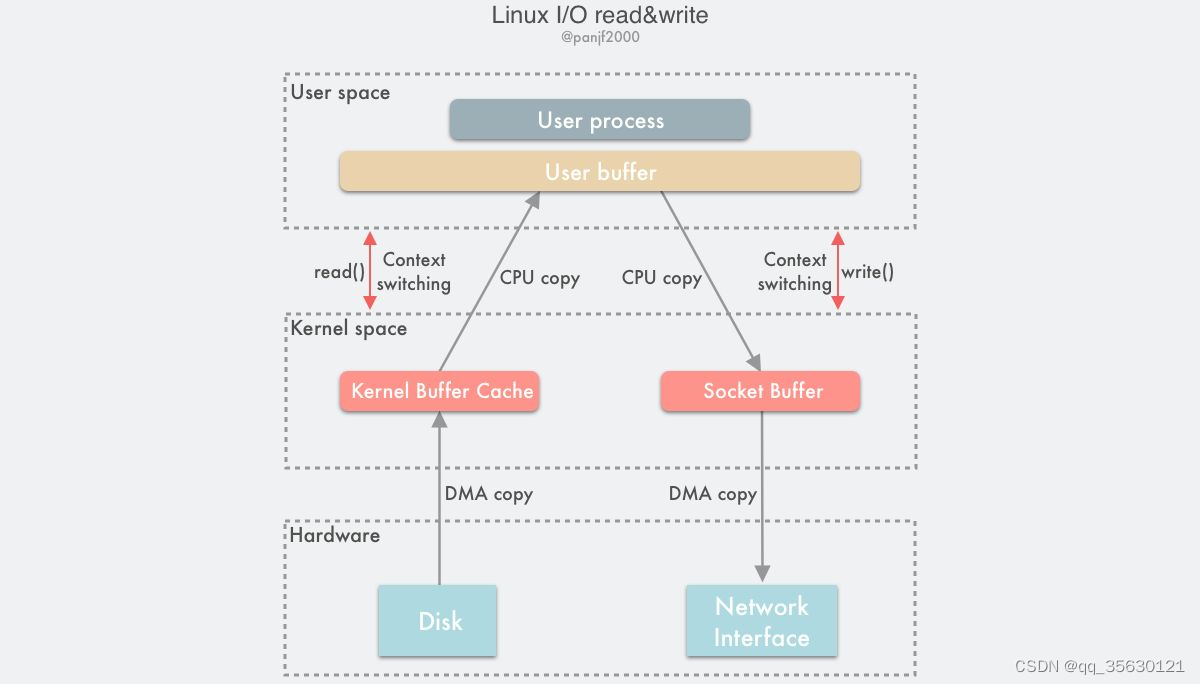
在Linux架构中,无论哪种IO方式,其工作流程都是差不多的,下面以读文件举例。
- 首先由用户发起系统调用,并传入需要监控的文件描述符(对于大多数阻塞IO),系统切换至内核态。
- 内核根据文件描述符查找到对应的硬件,这里是磁盘,并由相应的DMA负责将数据拷贝至内核缓存
- 当数据拷贝完成,内核会将数据从内核缓冲区拷贝至用户缓冲区,并切换回用户态。
- 用户态进程读取数据。
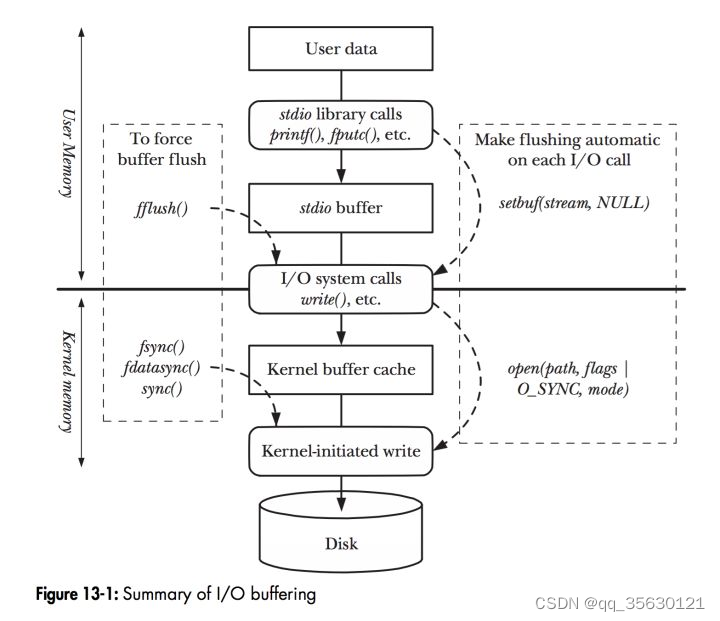
一次简单的IO操作,至少需要两次上下文切换,以及一次DMA负责的数据拷贝和一个CPU负责的拷贝。
阻塞IO
最简单也是最常见的IO操作,通常读取磁盘文件使用的都是阻塞IO,例如open,read,writer,close函数。调用这些函数的进程在函数返回之前会一直阻塞在调用处。
对于本地IO来说,阻塞IO通产是很快的,但对于网络IO来说,由于网络的不可控性,阻塞IO通常就不能直接使用了。
阻塞IO的优缺点都很明显,优点就是简单,方便,缺点也是过于简单,没有进行任何优化。
在这里插入图片描述

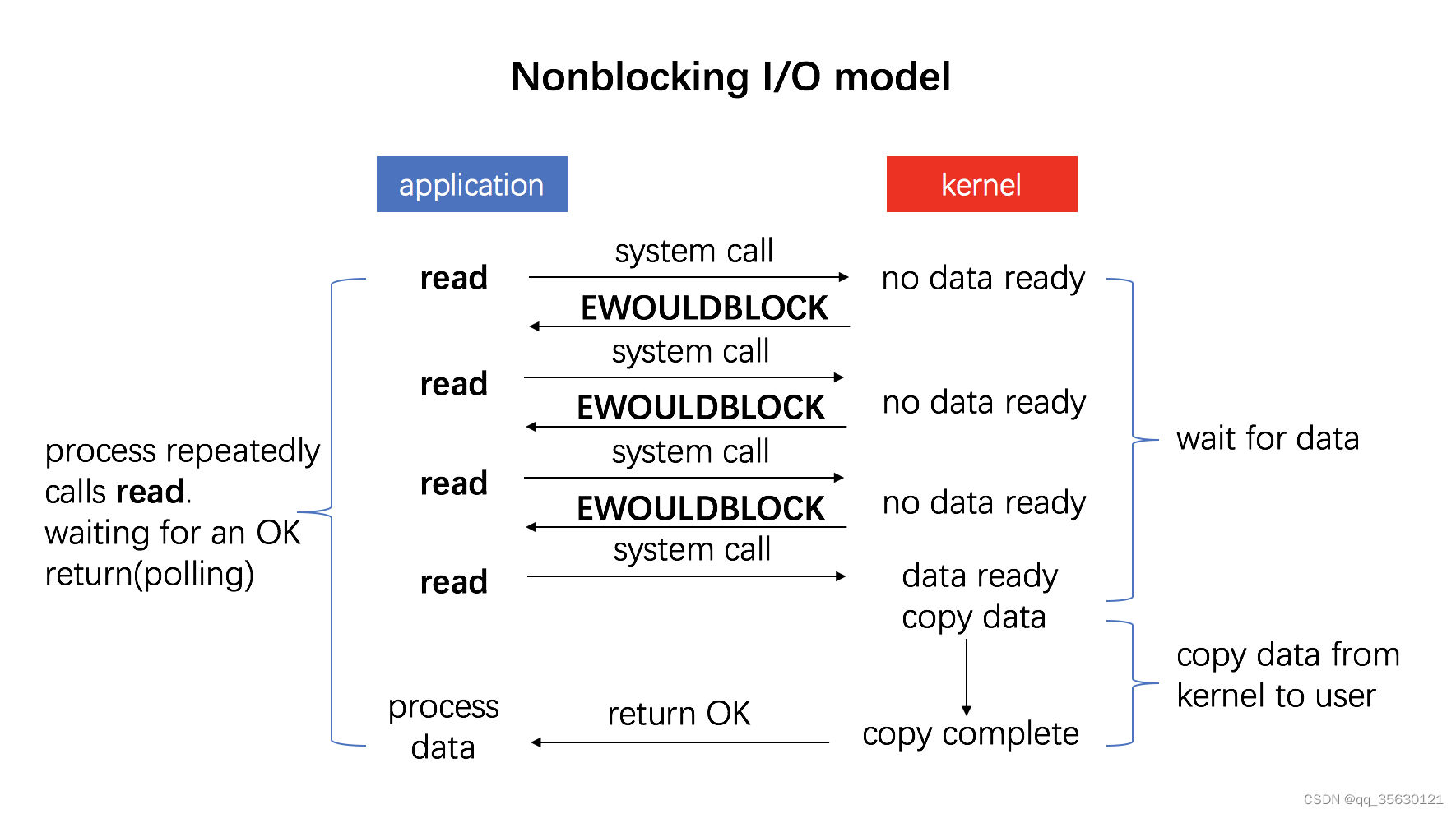
非阻塞IO
与阻塞IO相对应的就是非阻塞IO,非阻塞IO在进入内核态之后首先会判断对应资源是否准备完成,如果准备则进行对应操作并返回结果,如果没准备完成会立即返回一个EWOULDBLOCK错误。
用户进程可以在稍后再次发起IO请求,直到IO操作成功。
非阻塞IO的优点是可以让用户在数据准备完成之前先进行其他操作,但缺点也很明显,需要多次发起系统调用,而系统调用恰恰又是特别消耗CPU资源的行为。
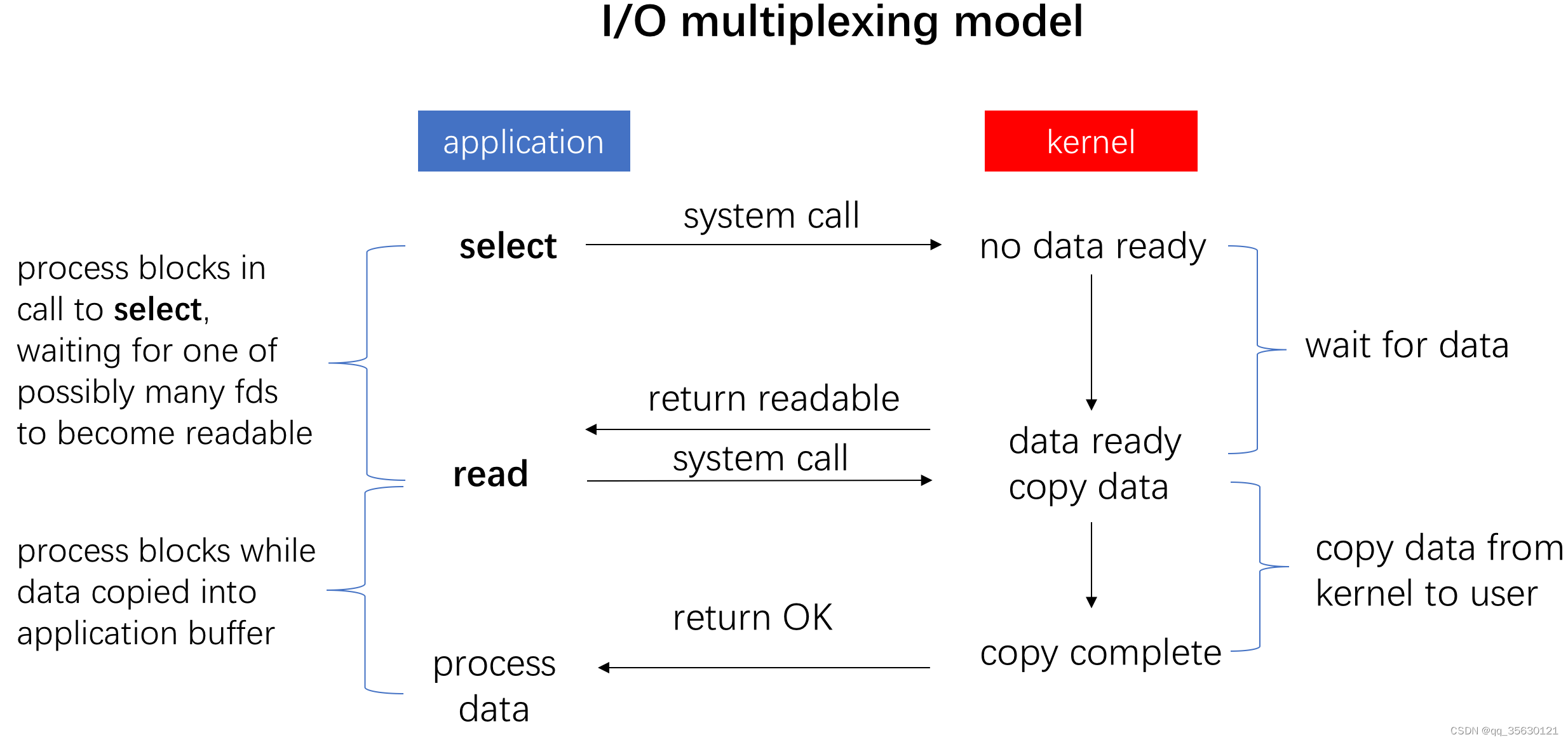
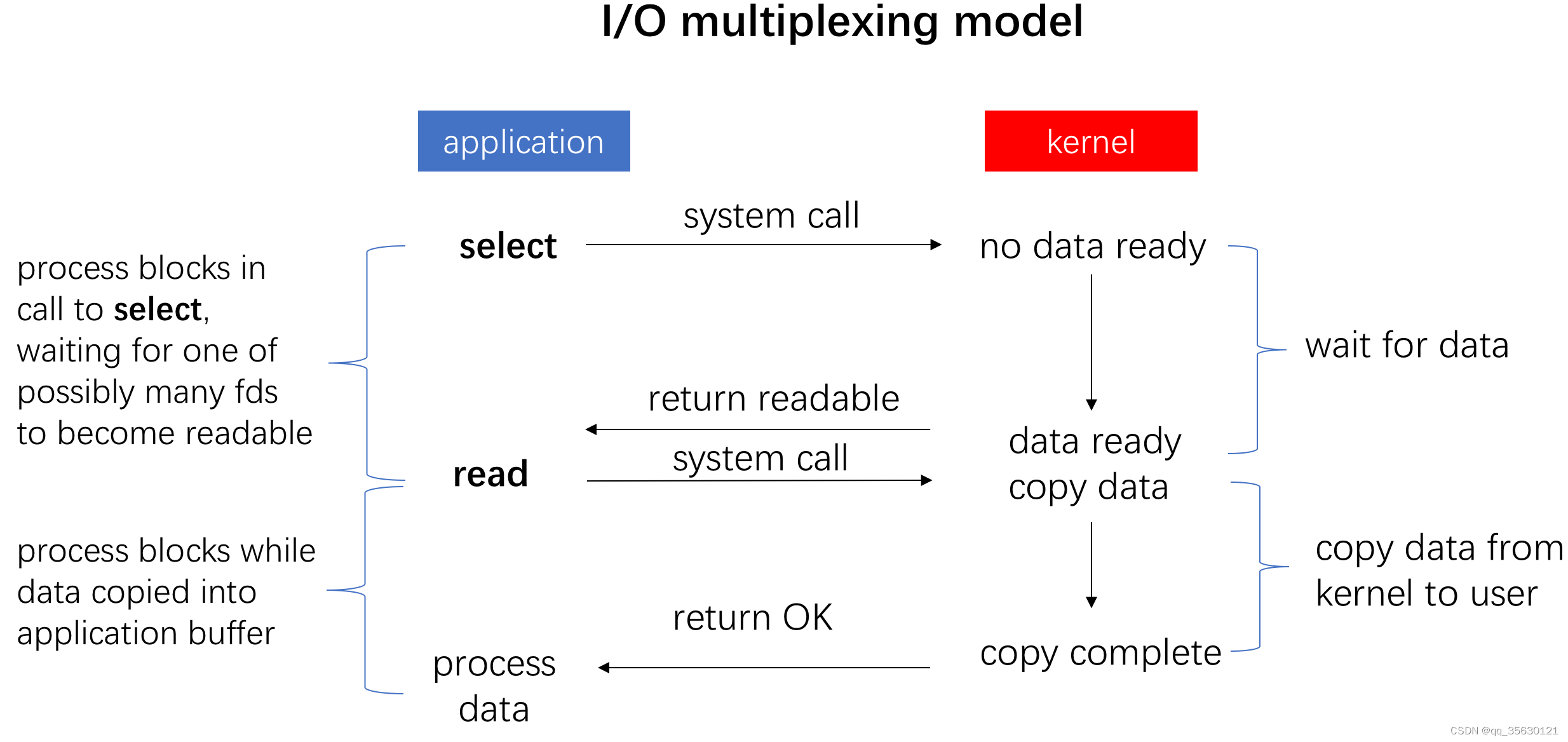
IO多路复用
所谓的IO多路复用本质上还是阻塞IO,只不多可以在一次阻塞中同时监控多个文件描述符,并在任意文件描述符可以操作时进行返回。
Linux为我们提供了三种IO多路复用的方式,分别是select,poll,epoll,其在使用时对应的时间复杂度分别是O(n), O(n)和O(1),其中n是需要监控的文件描述符的数量。
在需要监控少量文件描述符时,select和poll的效率会更高,因为二者时间复杂度中的常数项更低,但当需要监控大量文件描述符时,epoll的效率会更高。
下面将对这三种方式做简单介绍:
Select
select内部会一直循环遍历所有文件描述符的状态,有一个fd满足监听条件或者超时为止。内部循环的时间复杂度就是O(n)。
此外在用户态获取返回值之后,如果有fd可操作,还需要再遍历一遍所有的fd从中找出可操作的fd,这也需要O(n)的操作时间。
为了提高效率,当一次遍历没有成功之后,当前线程会进入一段时间的休眠,直到被定时器或者状态变化的fd唤醒。
Poll
Poll的算法与Select类似,但在实现上有所不同,最大的区别在于Select使用的是定长数组,而Poll使用的是链表,可以同时监听更多的fd。
Epoll
Epoll与Select和poll的算法完全不同,其原理简单来说就是为每个要监听的fd指定一个回调函数,在fd状态发生变更时将其主动推送给用户。
epoll_create函数可以创建一个负责注册监听事件的entry,再通过epoll_ctl逐个注册想要监听的fd,最后调用epoll_wait进行等待,直到有可以操作的fd退给用户。
epoll提供两类监控事件,分别是EPOLLLT(水平触发)和EPOLLET(边沿触发),水平触发指的是如果当前fd内还有数据可读,那么就会一直将其返回给用户,而边沿触发则是只在有新数据可读时才会将其返回给用户。
边沿触发让用户可以暂时先不处理一些数据量较大且不是很重要的fd,而专注于更敏感的fd,但需要注意的是在读取fd时需要将所有buffer读空。
epoll的优点:每个fd只会被注册一次,降低了用户态和内核态之前的拷贝数据。epoll_wait只会返回可以操作的文件描述符,在用户态减少一次全部遍历。在监听时只是将有事件发生的fd加入其可以返回的链表,减少遍历次数。
信号驱动IO
使用场景和相关资料都很少,暂时不研究
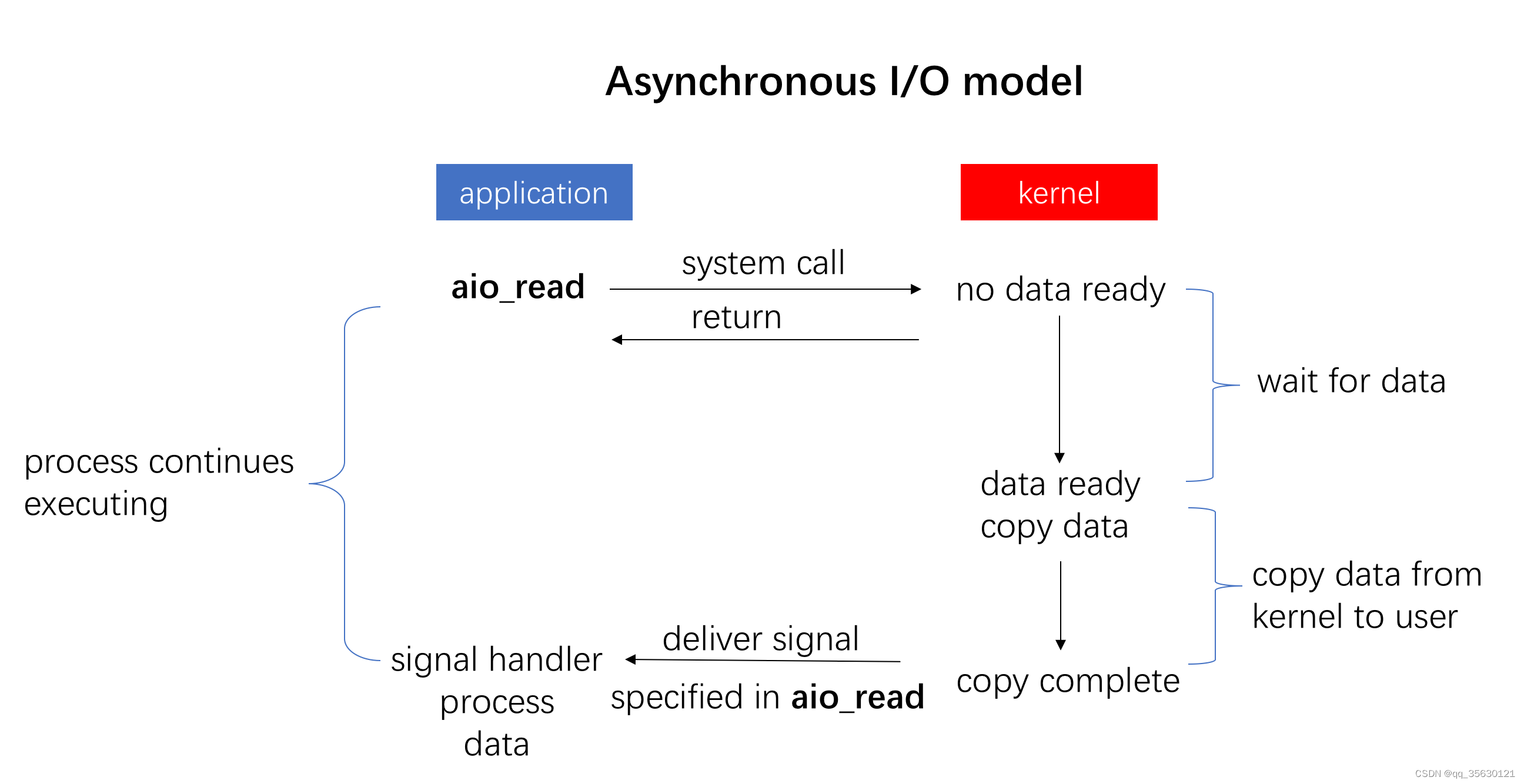
异步IO
异步IO的关键点在于内核的数据准备和数据拷贝工作都是在后台进行的,用户进程在向内核发起IO相关的系统调用信号后便会直接返回。
内核在收到信号后会驱动DMA将数据拷贝至内核态缓存,再将数据拷贝至用户态缓存,在一切准备就绪之后才会通知用户进程,用户进程在收到信号通知后可以直接访问已经准备好的数据。
内存管理
存储架构
当前Linux系统内部共有四种存储空间,分别是寄存器(Register),高速缓存(Cache),主存/内存(Memory),磁盘(Disk)。
从左到右速度和价格都依次降低,越快的肯定越贵嘛。
其中寄存器为每个CPU核独享,速度非常快,但容量也很小,64位CPU通常只有64x64bit大小。一般软件开发也不会优化到这种程度,了解即可。
Cache又分为L1,L2和L3三种,也是速度和价格依次下降。其中L1每核独享,L3每个CPU的核内共享,L2取决于具体实现,一般Intel为共享,ARM为独享。
内存我们就很熟悉了,当前用RAM实现,大型服务器通常都有几百G了。内存分为内核态和用户态,其中用户态又使用虚拟内存的方式进行寻址。
磁盘存储空间就很大了,但访问速度与内存相比低了3个数量级,一般程序都不会跑到磁盘上。但磁盘上有个特殊的分区,swap分区。由于
Cache
Cache是我们在做系统优化时一般所能考虑到的最高级存储了。由于Cache本身就有三层,每层又有着不同的同步策略,Cache和Cache之间,Cache和内存之间都有着复杂的同步关系,深究起来非常非常复杂。
这里我只介绍自己了解过的一些针对Cache的开发点,其他就一点一点积累吧。
Cache Miss
这应该是我们听过的跟Cache相关的最多的词了,简单来说就是CPU在想要访问一个数据时,会先在自己的三层Cache中查找其是否存在,如果存在就拿来用,此时称为Cache Hit,如果不存在就会根据地址访问内存,将其从内存加载到Cache中,再进行访问,此时称为Cache Miss。
从内存加载到Cache的过程中,CPU是无法继续执行当前指令的,如果有其他可以执行的指令CPU会切换到其他指令,否则就会陷入阻塞状态。降低Cache Miss率可以有效提升CPU效率。
由于Cache的容量是有限的,因此需要一种算法来更新Cache中的数据,一般使用的都是LRU(最近最少使用)算法,即将使用频率最低的部分从Cache中剔除。LRU算法在内存中可以通过链表加哈希表的形式实现,Cache中的实现方法未知。
降低Cache Miss率的方法
- 提高CPU亲和性:在当前操作系统架构中,CPU需要经常在内核态和用户态之间切换,同时还需要经常在不同用户态线程之间切换。由于每个进程做使用的数据大概率都是不一样的,因此线程切换时,大概率会发生Cache Miss。由于通常情况下CPU核的数量一定是比需要运行的线程数少的,因此这一问题无法避免。但在某些特殊情况下,例如使用Linux服务器做转发器,此时系统运行的线程数是有限的,因此可以将一个线程绑定到CPU上,可以大大降低Cache Miss率。
- 使用prefetch:prefetch理论上很简单,就是在CPU使用之前提前把内存中的数据主动推送到Cache中。例如我们想要遍历一个链表,就可以在遍历当前节点时提前将下一节点通过prefetch推送到Cache中,从而大大降低Cache Miss率。但是prefetch指令会带来额外的负载,同时CPU也有自己的一套prefetch逻辑,具体使用prefetch是否有优化作用还要视具体情况而论。但Linux系统从3.0版本开始已经不再提供prefetch接口了。
Cache Line对齐
如果说Cache Miss是频率最高的词,那么Cache Line应该就是第二了。所谓的Cache Line其实就是Cache中的一行,也是Cache操作的最小单元,在64位操作系统重Cache Line一般长度为64bit。在程序开发时,为了尽可能的提高效率,通常需要Cache Line对齐。
所谓的Cache Line对齐就是让一个结构体中的成员占用的内存尽量是32bit的整数倍,当一个结构体的长度接近64或者32时,可以通过在结构体中添加padding的方法将其长度填充至32或64bit,这样可以使CPU在访问下一个相同数据时不需要跨Cache Line访问。
内存屏障
由于L1 Cache和L2 Cache通常都是每核独享的,那么不可避免的会出现同步上的问题。同时,由于CPU会对执行的指令顺序做优化,导致指令实际的执行顺序与程序中预期的顺序不一致,这也称为CPU乱序。
内存屏障就是为了解决上述问题产生的。内存屏障可以分为读屏障和写屏障,根据实现方式又可以分为CPU屏障和编译器屏障。
- 编译器屏障:编译器屏障的作用是可以防止编译器优化导致的指令乱序问题,常用的volatile关键字本质上就是一个编译器屏障,但编译器屏障并不能避免CPU乱序造成的问题。
- CPU屏障:Intel为我们提供了三种CPU屏障以供调用,分别是读屏障(lfence),写屏障(sfence)以及读写屏障(mfence)
- sfence:调用sfence时,当前CPU会将Store Buffer中的数据立即输入Cache中,让其他核可以访问到,同时保证sfence之前的写指令都执行完毕才会继续向下执行,也就是防止乱序。
- lfence:调用lfence时,当前CPU会立即读取invalid queue中的数据,将Cache中的数据全部刷新成最新版,同时也保证lfence之前的读指令都执行完毕。
可以看到内存屏障一共有两方面的作用,一是及时同步,二是防止乱序。在某些关键字段的读写时(例如数组index)需要结合具体情况添加对应的屏障,dpdk提供的rte_rmb核rte_wmb就是基于lfence和sfence实现的。
在现在的x86系统中,及时没有读写屏障也不会有同步之间的严重问题了,具体实现我也不是很清楚,但如果在某些特殊场景下,为了避免CPU乱序,还是要加写屏障的(防止Store Load乱序)。
内存
内存按照使用功能可以分为内核态和用户态,而用户态又需要区分虚拟内存和物理内存,这里重点介绍虚拟内存以及与其相关的TLB Miss。
虚拟内存
由于用户态的所有进程共用一块物理内存,因此如何对物理内存就行分配就是首先需要考虑的问题。经过多次架构演变,Linux系统最终使用虚拟内存的方式来为各个进程分配物理内存。
虚拟内存相当于是进程和物理内存之间的一个中间层,每个进程都会维护着一个属于自己的页表,一个页表就相当于一个目录,其key为虚拟内存地址,value为物理内存地址,提供了一个从虚拟内存到物理内存的映射。
对于当前常见的64位操作系统,其所使用的寻址空间为48位,已经能够提供256T的寻址能力。Linux系统默认的一页大小为4K,所对应的页偏移(即虚拟内存和物理内存相同的地址空间)为12位,因此还需要36位的大小的页表提供查询。
为了尽可能降低页表的大小,Linux使用多级页表,一般为4级,每级提供9位的寻址能力。在使用时,会从高到低地逐次查询页表,最终定位到需要的物理内存地址。
这样做的问题也显而易见,页表默认都保存在内存中,如果四级页表都没有在Cache中,那么CPU仅仅是想简单的查询一个数据就需要访问5次内存(四次定位物理地址,一次读取数据),这样会大大降低效率。
为了解决这一问题,TLB(Translation Lookaside Buffer)应运而生。TLB相当于是一个专门为虚拟地址向物理地址映射提供服务的寄存器,其效率相当快,且每核独享。但与寄存器一样,其造价很贵,因此空间很小,如何高效利用这些空间也是系统优化中需要经常考虑的问题。
TLB Miss
与Cache Miss类似,CPU在想要获取一个虚拟地址对应的物理地址时,会先查询其TLB中的数据,如果其中没有对应的虚拟地址,也就称为TLB Miss。此时从Cache和内存中的页表查询对应地址,并将其添加到TLB中。
由于TLB大小有限,因此也要制定对应的更新算法,一般也是LRU。
TLB Miss优化
- 提高CPU亲和性:和Cache Miss一样,如果CPU经常切换线程,其使用的内存地址也会经常变换,TLB Miss率自然就高。
- 使用大页内存(Hugepage):最根本的方法还是降低页的数量,常见的大页内存有4M,1G,2G等,分别可以使页的数量降低512倍和50万倍,理论上其对应的TLB Miss率也会等比例的下降。大页内存在原理上也就是提高了页偏移,即提高了虚拟内存和物理内存的共用地址位。
Swap区间
关于虚拟内存还有一个问题,那就是每个进程都有自己的一份虚拟内存,总的虚拟内存大小是远大于实际的物理内存大小的,那么当各个进程同时使用的虚拟内存大于实际物理内存时该怎么办呢,Swap区间就是为了解决这一问题。
Swap是磁盘上的一个特殊区间,在安装系统时就已经指定了。当物理内存不足时,系统会根据更新算法将最少用到的物理内存地址暂时放到磁盘的Swap区间上,并将空闲下来的物理内存给新的程序使用。
除此之外,在系统休眠时,会将全部的内存数据存入Swap区间中,等到下次系统被唤醒时会重新从Swap区间加载全量内存数据。
用户态和内核态
概念
用户态(User Space)和内核态(Kernel Space)可以说是所有Linux开发人员都绕不开的话题,那么他们究竟是什么?有什么区别?有什么关系?又为什么这么设计?
首先需要理解什么是内核,所谓内核可以简单理解为一个特殊的软件,它支撑起了整个操作系统,有着最高的管理权限,并且可以直接与各种设备通信,可以执行ring 0级别的CPU指令集。
而内核态,就是系统为内核专门划分的一块物理内存,除内核外的软件对该内存都没有直接访问的权限,一般是物理内存的高位。
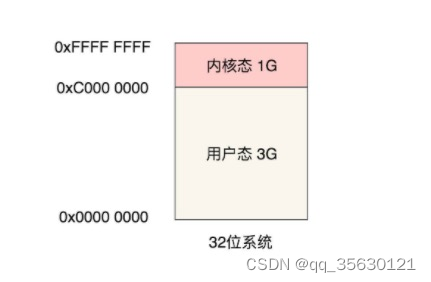
与之对应的用户态就是其他所有软件共享的一块物理内存,共享通过虚拟内存实现。
联系
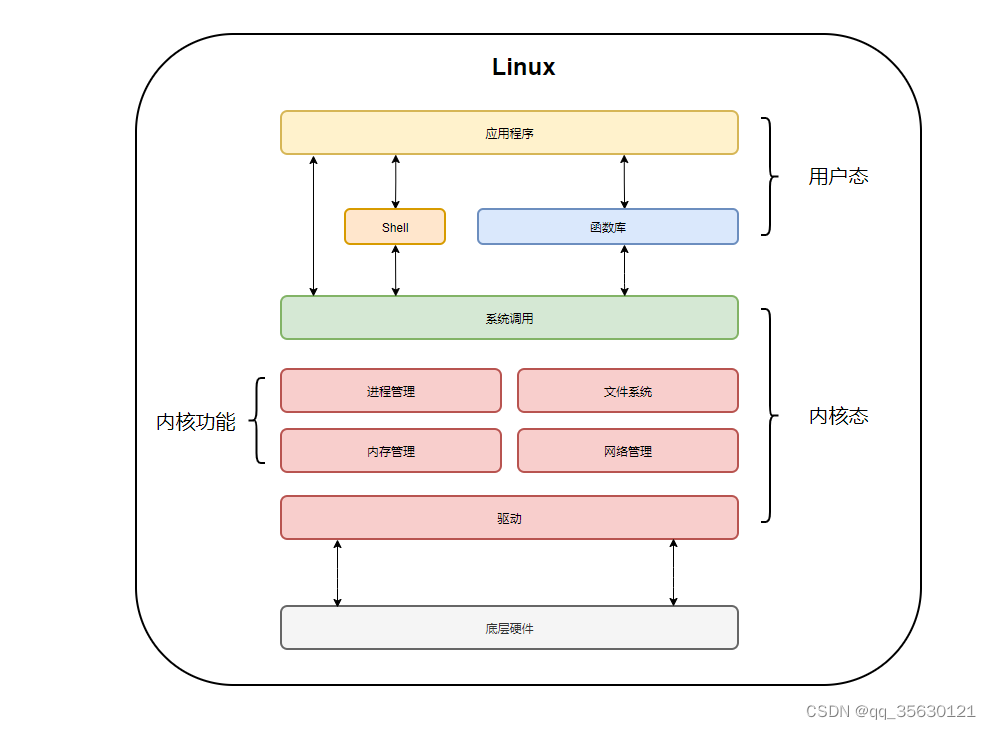
用户态可以通过三种方式与内核进行通信:
- 库函数或者Shell脚本,由内核态的程序主动发起,通过预定义的接口完成通信
- 异常:当用户态程序发生不可预期的异常时,会被动切换到内核态
- 中断:当CPU收到中断信号时,也会从用户态切换到内核态
原因
那操作系统为什么要这么设计呢?
主要有两点,首先为了给内核划分一片专用内存,保证在任何情况下操作系统都能跑,其次是因为有许多高度敏感的CPU指令集如果不当使用的后果是灾难性的,所以只能由提前设计好的内核调用,对外只提供对应的库函数。
这一过程被称为系统调用。每次系统调用需要两次上下文切换,分别是调用的用户态进程切换至内核态,等内核处理完成再从内核态切换至用户态。
问题
根据用户态和内核态对内存进行分区带来了许多优点,但传统架构中用户态的进程如果想要访问文件资源(磁盘和网口)需要多次的上下文切换和CPU参与的拷贝工作,这大大限制了CPU效率,为此催生了一系列的零拷贝技术。
进程和线程
进程和线程算是计算机系统里老生常谈的问题了,特别是在面试中,面试官很有可能问出的一个问题就是,说一下进程和线程的区别?
这篇文章就从概念上简单阐述一个现阶段我对这一问题的理解。
想要完整的回答这个问题,可以从是什么,为什么,怎么做的角度入手,对应的具体问题就是,进程和线程分别是什么?为什么要这么设计?以及Linux系统是怎么实现的?
概念
进程和线程本质上都是一种对程序的抽象,每个人都可能有自己的一套理解,并且各个操作系统的具体实现也会有所区别,最常见的一个定义就是,进程是资源分配的最小单位,线程是系统调用的最小单位。
对于计算机来说,资源无非就是内存和CPU,上面的定义如果说的更通俗一点就是操作系统以进程为单位为程序分配内存,以线程为单位为程序分配CPU时间。
进程的资源
在Linux系统中,内存被分为用户态和内核态,为了充分利用用户态的空间,Linux系统会为每个程序分配独立的虚拟内存,同时有一个对应的页表保存虚拟地址和物理地址之间的映射关系,在程序运行时不断的通过缺页中断来为其分配实际的物理地址。
这一虚拟地址空间,按照功能的不同又会被划分成如下几个区域:
- 用户自行分配和释放的堆区
- 系统负责分配和释放的栈区
- 存储全局变量和静态变量的静态区
- 存储常量的常量区
- 存储二进制代码的代码区
其中与我们关系比较密切的是堆和栈,这也是面试一大考点
栈是由操作系统维护的,栈中会保存函数的入参以及局部变量,线程的栈大小是有限的,可以通过配置进行修改,当前最常用的设置是2M,当创建的局部变量占用内存超过这一值时就会发生栈溢出错误。
堆是由用户自身进行维护的,与栈相比,堆通常可以视为无限大的,用户可以在其中申请到大量内存,这些内存使用完毕之后不会被系统释放,需要由用户手动释放,否则就会引发内存泄露。
栈内存的优点是使用方便,快捷,缺点就是空间有限,无法存储较大的数据。堆的优点是空间大,缺点是维护较为复杂,速度较慢,且容易产生内存碎片,降低内存的使用效率。
线程的资源
操作系统通常会按照线程为单位为程序分配时间片,时间片的大小取决于线程的优先级,优先级越高的线程分配的时间片大小就越大。Linux系统中通常会为IO操作密集的线程分配更高的优先级,这是因为用户对有IO操作的线程通常更为敏感。
对于用户线程来说,其分配的时间片大小可从5ms~800ms,具体取决于调度算法。
Linux系统的实现
在Linux系统中,进程和线程会统一使用task_struct进行表示,并不会做明显的区分。我们可以将一个task_struct视为一个线程,共用同一个虚拟空间的多个线程视为一个进程。
如果一个虚拟空间只有一个对应的线程,那么此线程就是一个进程,如果一个虚拟空间对应着多个task_struct,那么就可以将这一线程组视为一个进程。
进程和线程的切换
我们都知道进程和线程切换时需要进行上下文的切换,这也是频繁切换进程或线程时的主要性能损耗原因,那么进程和线程的上下文都有什么呢?
对于进程来说,其上下文的切换包含两方面,一是空间地址的切换,需要切换到新的虚拟地址空间,也就是切换到新的页表。二是处理器状态的切换,又叫硬件上下文切换,也就是保存当前的寄存器状态,并切换到下一个将要执行的进程的寄存器状态。
对于线程来说,如果切换前和切换后的线程属于同一个进程,那就说明他们有着相同的虚拟空间,也就只需要进行处理器状态的切换了。这也是多线程程序比多进程程序快的原因。
在Linux系统中,切换虚拟地址空间就是改变task_struct结构中一级页表的物理地址对应的字段,这一切换是很快的,但是在虚拟地址空间切换之后,TLB中的所有字段都需要失效,不然会让CPU访问到错误的物理地址。而这会已发大量的TLB Miss,这才是进程切换的最大开销。为了应对这一情况,处理器引入了ASID机制,大概就是为TLB中的表项打上一个进程的标记,这样就可以保留一部分进程对应的表项,利用这一机制可以降低TLB Miss发生的概率。











![[附源码]Python计算机毕业设计Django校园生活服务平台](https://img-blog.csdnimg.cn/587e1d627b304762a9fd34450271f0ef.png)