ZeRO-DP是分布式训练工具DeepSpeed的核心功能之一,许多其他的分布式训练工具也会集成该方法。本文从AllReduce开始,随后介绍大模型训练时的主要瓶颈----显存的占用情况。在介绍完成标准数据并行(DP)后,结合前三部分的内容引出ZeRO-DP。
相关博客
【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
【深度学习】混合精度训练与显存分析
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
一、AllReduce
1. AllReduce的作用
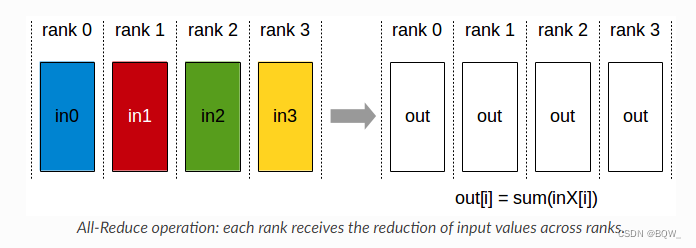
AllReduce从各个显卡(rank)上收集数据并进行聚合,再将聚合的结果分发至各个显卡(rank)。
2. Pytorch AllReduce示例
下面是一个pytorch调用AllReduce的示例,方便从代码的角度来理解AllReduce。
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def allreduce_func(rank, size):
group = dist.new_group(list(range(size)))
tensor = torch.ones(1).to(torch.device("cuda", rank))
# tensor即用来发送,也用来接收
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor)
def init_process(rank, size, fn, backend='nccl'):
"""
为每个进程初始化分布式环境,保证相互之间可以通信,并调用函数fn。
"""
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def run(world_size, func):
"""
启动world_size个进程,并执行函数func。
"""
processes = []
mp.set_start_method("spawn")
for rank in range(world_size):
p = mp.Process(target=init_process, args=(rank, world_size, func))
p.start()
processes.append(p)
for p in processes:
p.join()
if __name__ == "__main__":
run(2, allreduce_func)
3. Ring-AllReduce实现
AllReduce可以有多种实现方法,目前主流的实现方法是基于Ring的方式。理解AllReduce的实现方法才能够更好的理解为什么ZeRO-DP有效。总的来说,Ring-AllReduce可以分为reduce-scatter和all-gather两部分。
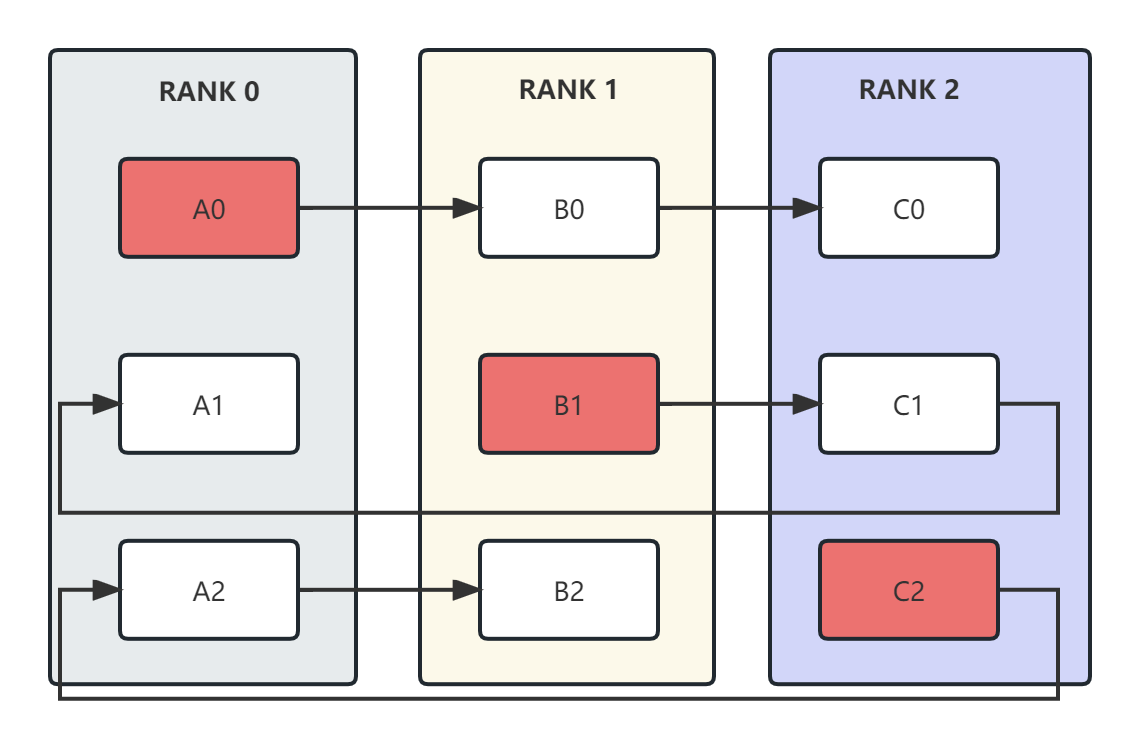
这里假设有3张显卡,逻辑拓扑结构为一个环。此外,每块显卡中的数据都被切分为3块。每个显卡都会从红色的数据块开始,然后沿着箭头的方向进行传递和累积。这个逻辑在后续的reduce-scatter和all-gather中完全相同。
总的来说,在n个显卡上将数据分成n块,第i个显卡以第i块为起始,经过n-1步完成reduce-scatter或者all-gather。
- reduce-scatter
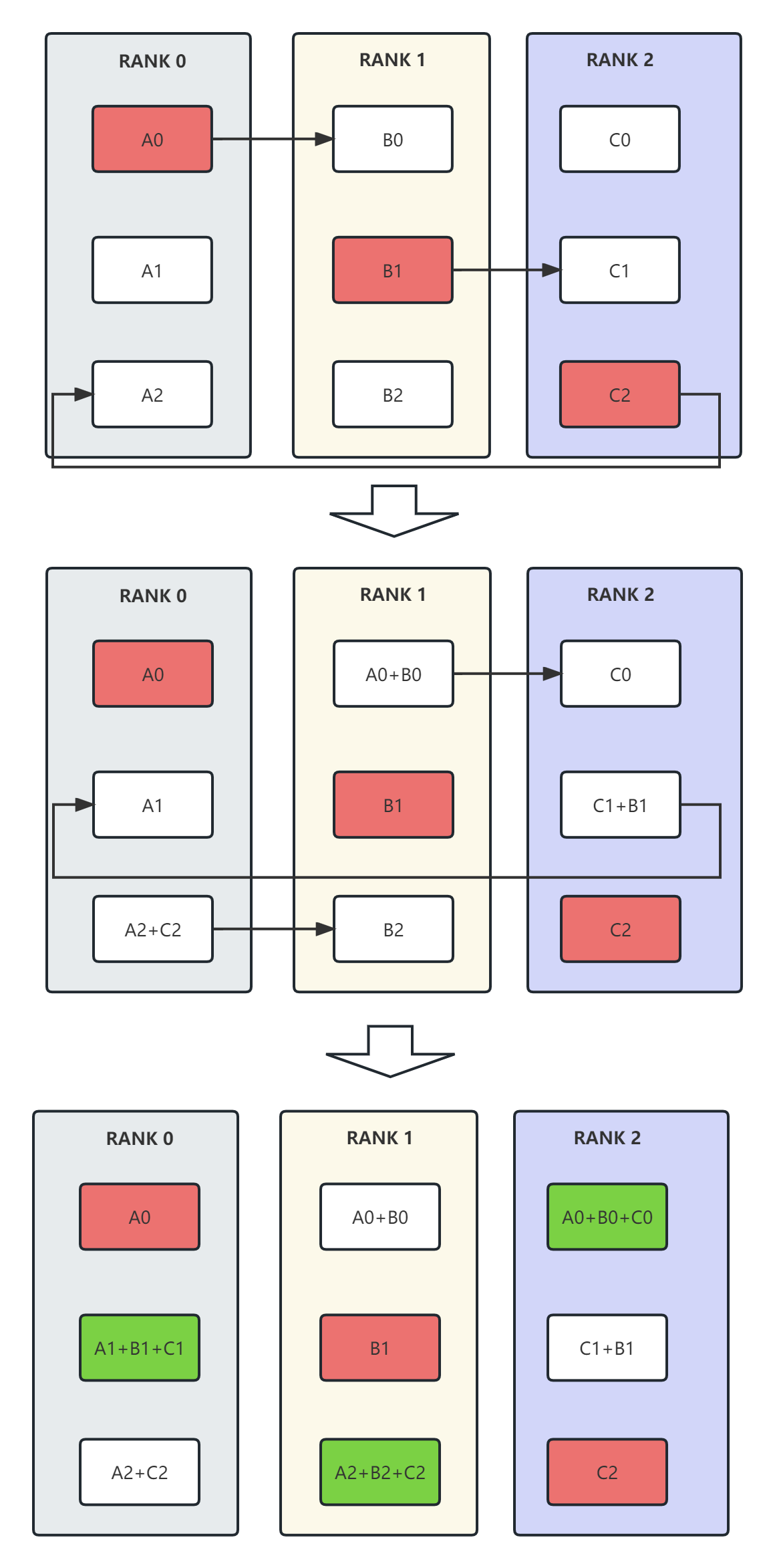
上图是一个reduce-scatter的例子。各个显卡从红色的数据开始传输,经过2步后,reduce的结果存储在了绿色的位置。
- all-gather
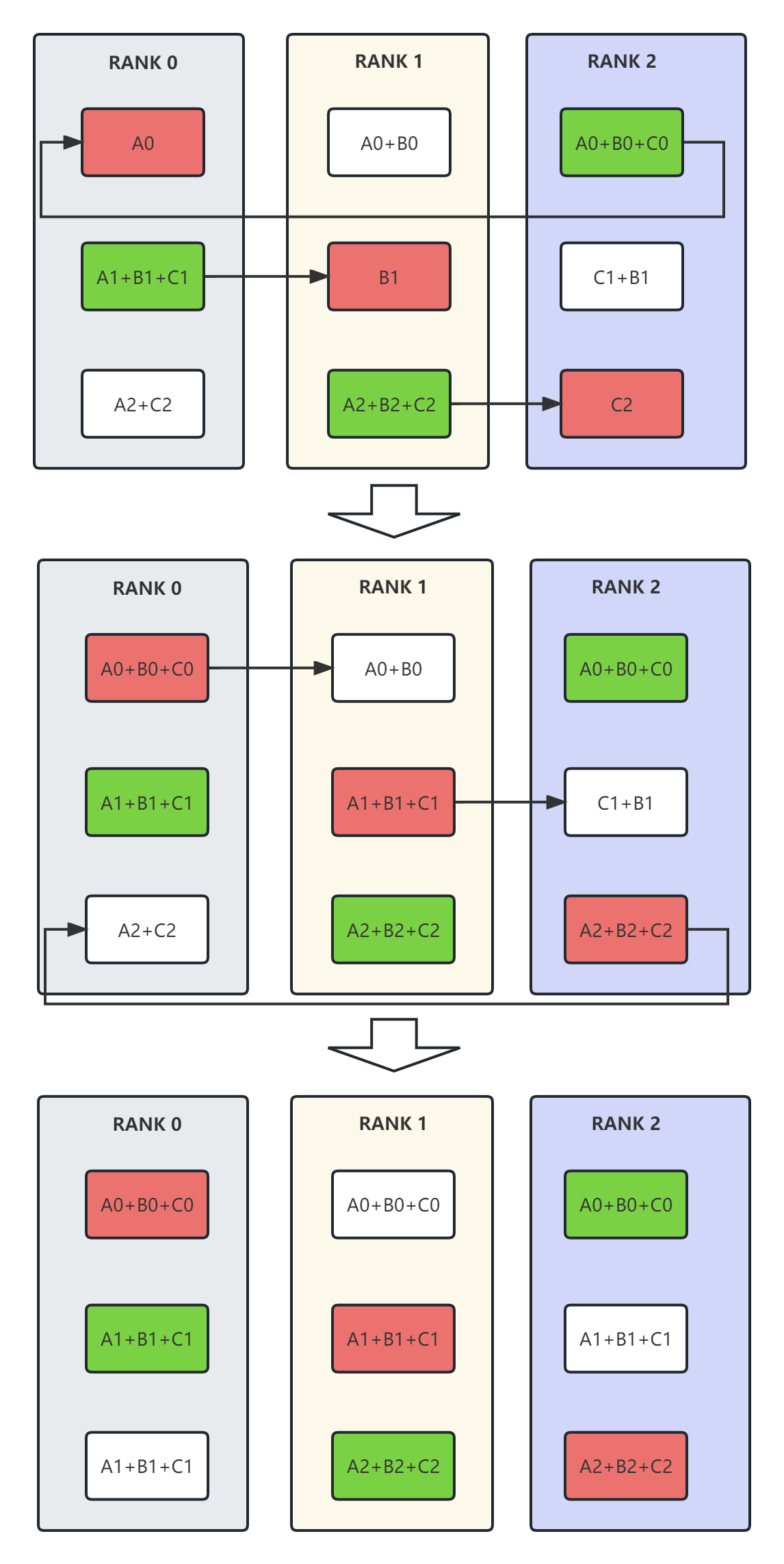
上图是all-gather的例子。在经过reduce-scatter后,reduce的数据分布在绿色的数据块上。all-gather从绿色的数据块开始,经过2步骤后,所有的显卡都有了完整的reduce结果。
二、显存占用分析
关于混合精度训练以及显存占用的详细介绍见文章《【深度学习】混合精度训练与显存分析 》。这里仅进行简单的介绍,方便于后续ZeRO-DP中显存的分析。总的来说,模型训练时显存主要分为两部分。第一部分是模型权重、梯度和优化器状态;第二部分是激活和临时缓存区。ZeRO-DP主要是优化第一部分的显存占用,所以这里主要介绍第一部分的显存。
假设模型的参数量是 Ψ \Psi Ψ,使用Adam作为优化器进行混合精度训练。由于模型的参数和梯度使用float16,所以显存消耗分别为 2 Ψ 2\Psi 2Ψ和 2 Ψ 2\Psi 2Ψ。Adam会维护一个float32的模型副本,消耗 4 Ψ 4\Psi 4Ψ显存。Adam优化器本身会为模型的每个参数维护两个float32的辅助变量,所以显存消耗占用为 4 Ψ + 4 Ψ 4\Psi+4\Psi 4Ψ+4Ψ。总的来说,模型会消耗 2 Ψ + 2 Ψ = 4 Ψ 2\Psi+2\Psi=4\Psi 2Ψ+2Ψ=4Ψ,Adam优化器这消耗 4 Ψ + 4 Ψ + 4 Ψ = 12 Ψ 4\Psi+4\Psi+4\Psi=12\Psi 4Ψ+4Ψ+4Ψ=12Ψ。最终的总消耗为 4 Ψ + 12 Ψ = 16 Ψ 4\Psi+12\Psi=16\Psi 4Ψ+12Ψ=16Ψ。
这里为了方便讨论,将优化器显存占用表示为 K Ψ K\Psi KΨ(不同的优化器不同),则混合精度训练的显存占用为 4 Ψ + K Ψ 4\Psi+K\Psi 4Ψ+KΨ。
三、数据并行(Data Parallelism, DP)
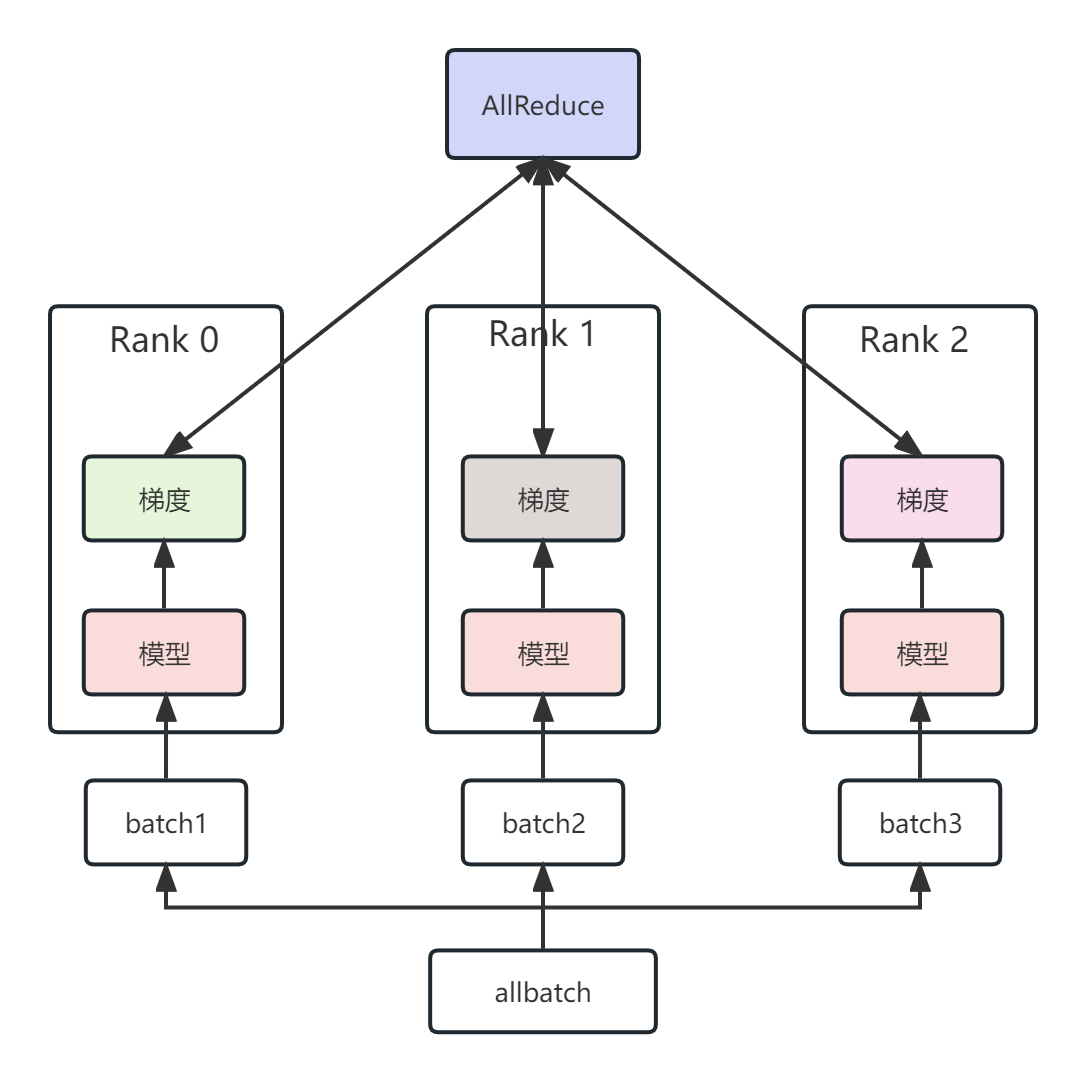
- 标准的数据并行会将模型参数拷贝至各个显卡上,也就是上图中各个Rank都拥有相同的模型参数。
- 随后,将采样的batch均等划分至各个显卡上;
- 各个显卡独立完成前向传播和反向传播,得到对应的梯度(此时,各个显卡上的梯度并不相同);
- 通过AllReduce操作,将各个显卡上的梯度进行平均,并将平均后的梯度返还给各个显卡(此时,各个显卡上的梯度完全相同);
- 各个显卡独自更新模型参数;
四、ZeRO-DP
ZeRO-DP(Zero Redundancy Optimizer-Data Parallelism)是来自于论文《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》中的一种显存优化方法ZeRO的核心部分。通过该方法可以大幅度的优化显存占用,从而在有限的资源下训练更大的模型。
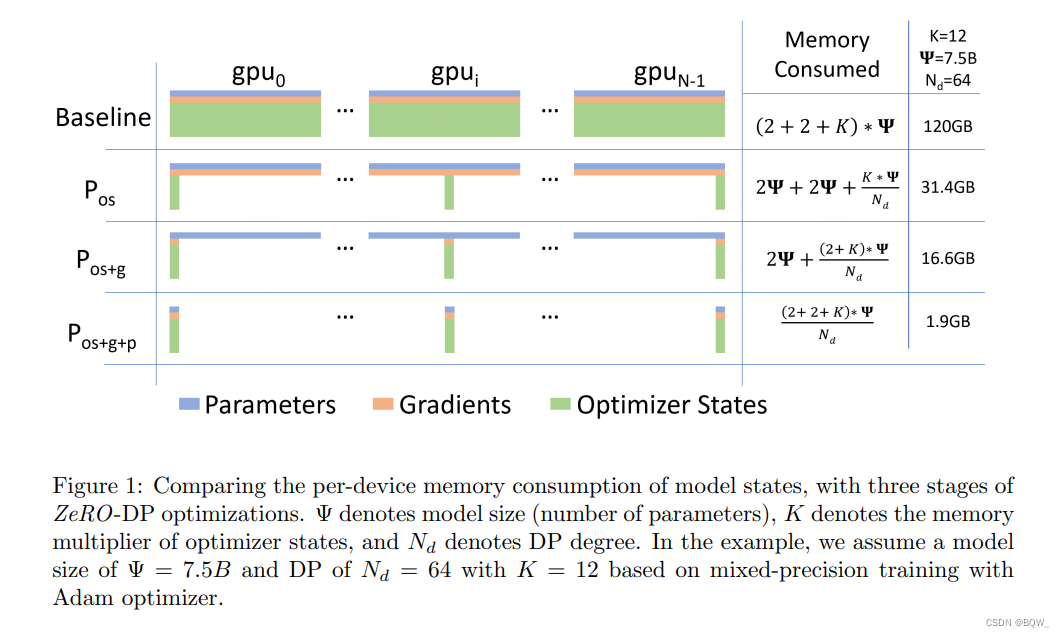
在标准的数据并行中,每个显卡(rank)都会保存独立的权重、梯度和优化器状态,如上图中的baseline所示。那么每个显卡是否有必要存储全部的这些信息呢?ZeRO-DP的答案是不需要。ZeRO-DP能够对模型状态(权重、梯度和优化器状态)进行划分(不像标准DP那样进行复制),然后通过动态通信调度来最小化通信开销。ZeRO-DP能够在保持整体通信开销接近标准DP的同时,线性地降低模型的单显卡显存占用。
1. ZeRO-DP的细节
总的来说,ZeRO-DP可以分为三个阶段: P o s P_{os} Pos、 P g P_{g} Pg和 P p P_p Pp。三个阶段对应优化器状态划分、梯度划分和模型参数划分,并且三个阶段可以叠加使用(上图展示了三个阶段的叠加)。关于三个阶段是否会增加通信量,会在后面分析,目前先接受这三个阶段并不会显著增加通信开销。
-
P o s P_{os} Pos:优化器状态划分
在 P o s P_{os} Pos阶段,根据DP度 N d N_d Nd将优化器的状态划分为 N d N_d Nd等份,即第i个显卡仅更新优化器状态的第i个部分。所以,每个显卡仅需要存储和更新总优化器状态的 1 N d \frac{1}{N_d} Nd1,并更新 1 N d \frac{1}{N_d} Nd1的参数。然后,在每个训练step末尾,使用all-gather获得整个参数的更新。
显存分析。如上图所示,显存占用从 4 Ψ + K Ψ 4\Psi+K\Psi 4Ψ+KΨ降低至 4 Ψ + K Ψ N d 4\Psi+\frac{K\Psi}{N_d} 4Ψ+NdKΨ。若 N d N_d Nd很大时,则显存占用接近 4 Ψ + 12 Ψ N d ≈ 4 Ψ 4\Psi+\frac{12\Psi}{N_d}\approx 4\Psi 4Ψ+Nd12Ψ≈4Ψ,能够带来4倍的节约。
-
P g P_{g} Pg:梯度划分
由于在 P o s P_{os} Pos阶段已经对优化器状态进行了划分,那么每个显卡也没必要保存所有的梯度。因此,当每层梯度需要更新参数时,仅对需要的梯度进行reduce。在参数更新后,梯度这部分的显存就会被释放。因此,梯度的显存占用从 2 Ψ 2\Psi 2Ψ降低至 2 Ψ N d \frac{2\Psi}{N_d} Nd2Ψ。
这个操作本质上是 Reduce-Scatter \text{Reduce-Scatter} Reduce-Scatter,不同参数对应的梯度被reduce至相应的显卡上。为了在实现中更加的高效,这里会使用分桶(bucketization)策略。该策略将所有梯度分桶至对应的划分,并在整个桶上进行reduce。
显存分析。通过移除梯度和优化器状态的冗余,将显存占用进一步降低至 2 Ψ + K Ψ N d 2\Psi+\frac{K\Psi}{N_d} 2Ψ+NdKΨ。当 N d N_d Nd比较大时,显存占用接近 2 Ψ + K Ψ N d ≈ 2 Ψ 2\Psi+\frac{K\Psi}{N_d}\approx 2\Psi 2Ψ+NdKΨ≈2Ψ,带来8倍的节约。
-
P p P_p Pp:参数划分
类似于前两个阶段, P p P_p Pp则是对模型参数进行划分。在前向传播和反向传播过程中,若需要其他的参数则通过broadcast从其他显卡中获取。乍一看,这会显著增加通信开销。但实际上,这种方法仅比标准的DP增加1.5倍的通信量,但使得显存占用减少程度与 N d N_d Nd成正比。
显存分析。在前两个阶段的基础上,使用 P p P_{p} Pp可以将一个参数量为 Ψ \Psi Ψ的模型的显存占用从 16 Ψ 16\Psi 16Ψ至 16 Ψ N d \frac{16\Psi}{N_d} Nd16Ψ。只要有足够数量的显卡,ZeRO能够适应任意大的模型。
-
对模型尺寸的影响
如上图所示,对于参数量为7.5B的模型,使用标准DP单显卡需要120G的显存。在 N d = 64 N_d=64 Nd=64的情况下,使用 P o s P_{os} Pos,单显卡需要显存为31.4GB;使用 P p s + g P_{ps+g} Pps+g,单显卡需要显存为16.6GB;使用 P o s + g + p P_{os+g+p} Pos+g+p,单显卡需要显存为1.9GB。
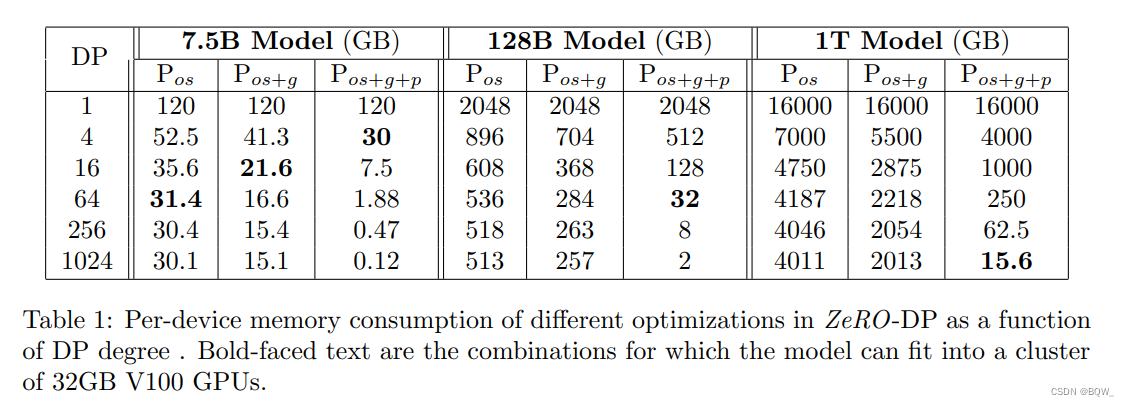
理论上来说,三个阶段 P o s P_{os} Pos、 P o s + g P_{os+g} Pos+g和 P o s + g + p P_{os+g+p} Pos+g+p对单显卡显存的需求降低分别是4倍、8倍和 N d N_d Nd倍。上表是模型状态显存占用的例子,其中包含了在改变DP程度的情况下ZeRO-DP三个阶段的显存占用。不使用ZeRO,显存消耗是上表的第一行。当 N d = 1024 N_d=1024 Nd=1024且ZeRO使用所有三阶段的优化,能够训练1 T参数的模型。若没有ZeRO,标准DP单独训练的最大模型参数小于1.5B。
2. ZeRO-DP通信量
ZeRO通过去除显存的冗余来提升模型尺寸,那么该方法是否是通过通信量换取的显存效率。换句话说,ZeRO-DP相较于标准DP来说,通信量增大了吗?答案分为两部分:(1) ZeRO-DP在使用 P o s P_{os} Pos和 P g P_{g} Pg的情况下,能够带来8倍的显存降低且不增加额外的通信量;(2) 当同时使用 P o s P_{os} Pos、 P g P_{g} Pg和 P p P_{p} Pp时,通信量增加1.5倍,同时降低 N d N_d Nd倍的显存。
2.1 标准数据并行的通信量
在标准的数据并行训练中,在反向传播结束后,跨显卡的梯度会被平均。这个平均的过程使用all-reduce。对于大尺寸的模型,all-reduce通信是整个通信带宽的上界,因此分析主要集中在all-reduce上。
目前all-reduce的最优实现就是前面介绍的Ring的方式,分为reduce-scatter和all-gather两部分。总的来说,单个显卡在reduce-scatter或者all-gather的过程中,都会有 Ψ \Psi Ψ的通信量。那么,整个all-reduce的单显卡通信量为 2 Ψ 2\Psi 2Ψ。
2.2 ZeRO-DP通信量
- P o s P_{os} Pos的通信量
在单独使用 P o s P_{os} Pos的情况下,单个显卡会保存完整的模型参数和梯度。随后使用reduce-scatter将梯度reduce至不同的显卡上(此时不同显卡仅拥有完整平均梯度的一部分),该步骤的通信量是 Ψ \Psi Ψ。各个显卡使用部分梯度更新对应的优化器状态,然后再更新对应的参数(此时每个显卡上的模型都更新了一部分参数)。最后,使用all-gather将分布在各个显卡上的更新后参数分发自所有显卡上(此时所有显卡上都有了完整的更新后参数),该步骤的通信量是 Ψ \Psi Ψ。总的来说,各个显卡仅需要持有部分优化器状态即可,且总的通信量仍然是 2 Ψ 2\Psi 2Ψ。
- P o s + g P_{os+g} Pos+g的通信量
上面介绍 P o s P_{os} Pos通信量时,假设每个显卡都经过反向传播后得到全部梯度。但是,梯度是逐层计算的。这里假设所有模型都计算出了最后一层的梯度,那么对最后一层的梯度进行reduce并将结果保存至某个显卡上,其他显卡就可以丢弃最后一层的梯度了(此时持有最后一层参数对应的优化器状态的显卡已经拥有了用于更新的梯度)。之后,所有显卡算出倒数第二层的梯度,然后执行相同的操作,依次类推。整个过程可以看做是梯度的reduce-scatter操作,同 P o s P_{os} Pos相同,但每个显卡不再持有完整的梯度。所以, P o s + g P_{os+g} Pos+g和 P o s P_{os} Pos具有相同的通信量,即 2 Ψ 2\Psi 2Ψ。
- P o s + g + p P_{os+g+p} Pos+g+p的通信量
若使用参数划分,每个显卡仅保存部分参数。因此在前向传播和后向传播过程中需要从其他显卡那里接收必要的模型参数。为了避免参数广播的显存开销,可以使用流水线的方式。这里假设模型在计算第一层前向传播时,持有第一层参数的显卡会将参数广播至其他显卡。当所有显卡都拿到参数后,进行第一层的前向传播。得到前向传播结果后,其他显卡就可以丢弃这部分模型的参数。依次类推。
每个显卡都持有 Ψ N d \frac{\Psi}{N_d} NdΨ的模型参数,并且 N d N_d Nd个显卡则需要广播 N d N_d Nd次,所以前向传播过程中的参数广播通信量为 Ψ N d × N d = Ψ \frac{\Psi}{N_d}\times N_d=\Psi NdΨ×Nd=Ψ。此外,后向传播时也需要逆向完成一次参数广播,通信量同样是 Ψ \Psi Ψ。最后,梯度完成计算后还需要经过一次reduce-scatter,通信量也是 Ψ \Psi Ψ。由于各个显卡持有不同的参数,所以不需要前面将所有更新后参数进行all-gather的操作了。总的来说,通信量为"前向传播的参数广播"+“后向传播的参数广播”+“梯度的reduce-scatter”= Ψ + Ψ + Ψ = 3 Ψ \Psi+\Psi+\Psi=3\Psi Ψ+Ψ+Ψ=3Ψ,也就是标准通信量的1.5倍。
参考资料
https://arxiv.org/pdf/1910.02054.pdf
https://blog.csdn.net/dpppBR/article/details/80445569
https://zhuanlan.zhihu.com/p/607605729