7. Spark中的一些重要概念
7.1 Application
使用SparkSubmit提交的个计算应用,一个Application中可以触发多次Action,触发一次Action产生一个Job,一个Application中可以有一到多个Job
7.2 Job
Driver向Executor提交的作业,触发一次Acition形成一个完整的DAG,一个DAG对应一个Job,一个Job中有一到多个Stage,一个Stage中有一到多个Task
7.3 DAG
概念:有向无环图,是对多个RDD转换过程和依赖关系的描述,触发Action就会形成一个完整的DAG,一个DAG对应一个Job
7.4 Stage
概念:任务执行阶段,Stage执行是有先后顺序的,先执行前的,在执行后面的,一个Stage对应一个TaskSet,一个TaskSet中的Task的数量取决于Stage中最后一个RDD分区的数量
7.5 Task
概念:Spark中任务最小的执行单元,Task分类两种,即ShuffleMapTask和ResultTask
Task其实就是类的实例,有属性(从哪里读取数据),有方法(如何计算),Task的数量决定并行度,同时也要考虑可用的cores
7.6 TaskSet
保存同一种计算逻辑多个Task的集合,一个TaskSet中的Task计算逻辑都一样,计算的数据不一样
8. 任务执行原理分析
8.1 WordCount程序有多个RDD
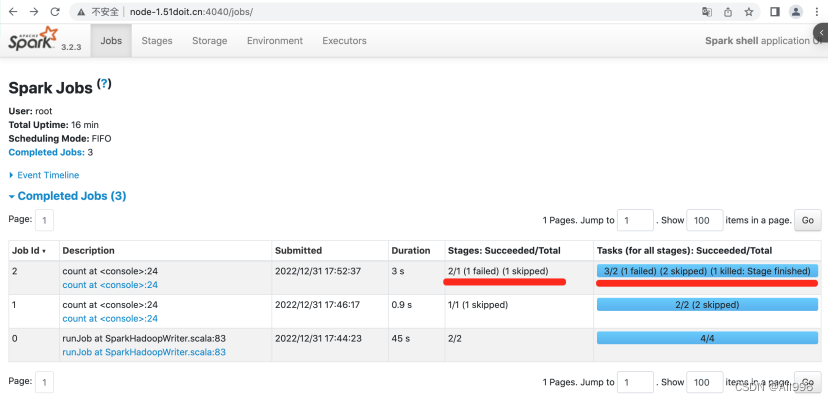
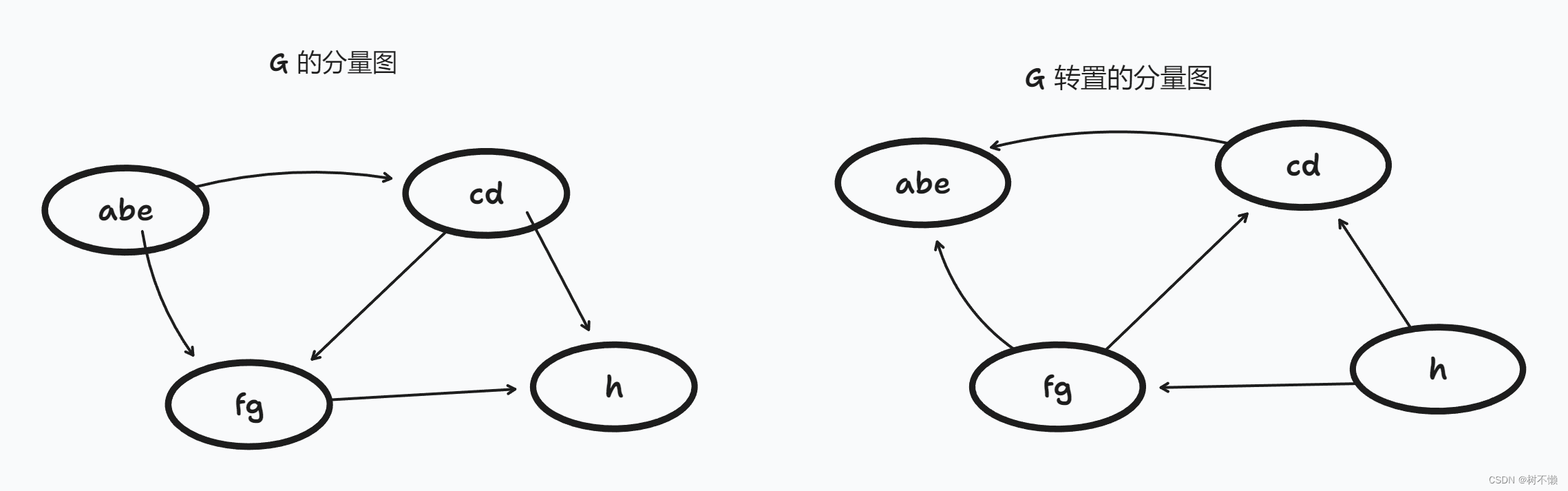
该Job中,有多少个RDD,多少个Stage,多少个TaskSet,多个Task,Task的类型有哪些?
| Scala |
8.2 RDD的数量分析
- 读取hdfs中的目录有两个输入切片,最原始的HadoopRDD的分区为2,以后没有改变RDD的分区数量,RDD的分区数量都是2
- 在调用reduceByKey方法时,有shuffle产生,要划分Stage,所以有两个Stage
- 第一个Stage的并行度为2,所以有2个Task,并且为ShuffleMapTask。第二个Stage的并行度也为2,所以也有2个Task,并且为ResultTask,所以一共有4个Task
spark的任务上次的逻辑计划图
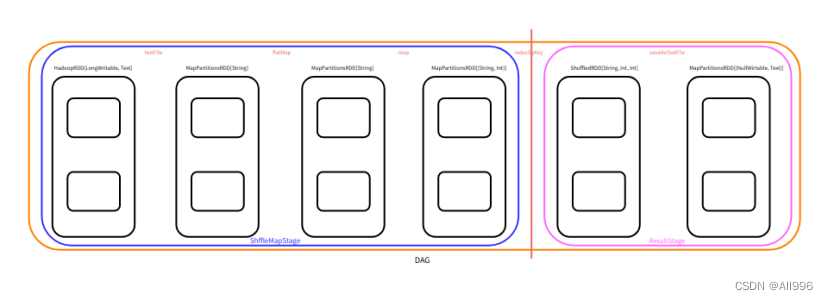
下面的的物理执行计划图,会生成Task,生成的Task如下
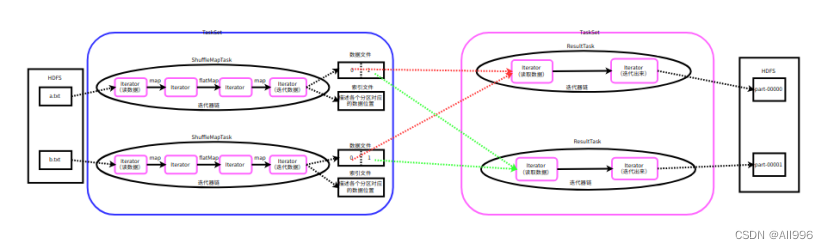
8.3 Stage和Task的类型
Stage有两种类型,分别是ShuffleMapStage和ResultStage,ShuffleMapStage生成的Task叫做ShuffleMapTask,ResultStage生成的Task叫做ResultTask
- ShuffleMapTask
1.可以读取各种数据源的数据
2.可以读取Shuffle的中间结果(Shuffle Read)
3.为shuffle做准备,即应用分区器,将数据溢写磁盘(ShuffleWrite),后面一定还会有其他的Stage
- ResultTask
1.可以读取各种数据源的数据
2.可以读取Shuffle的中间结果(Shuffle Read)
3.是整个job中最后一个阶段对应的Task,一定会产生结果数据(就是将产生的结果返回的Driver或写入到外部的存储系统)
多种情况:
第一种:
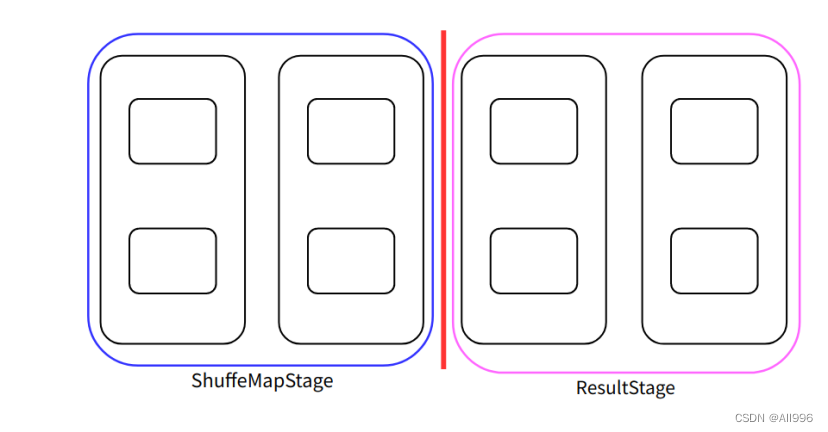
第二种
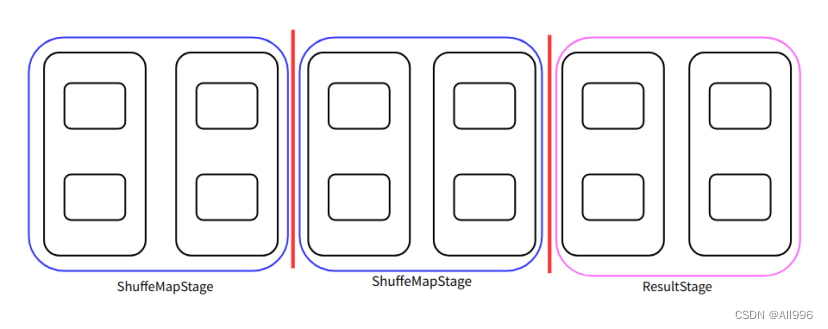
第三种:
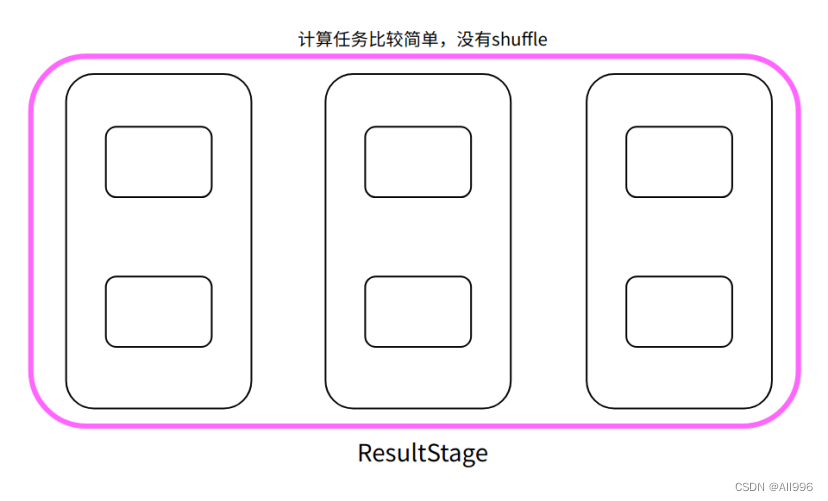
9. Shuffle的深入理解
什么是Shuffle,本意为洗牌,在数据处理领域里面,意为将数打散。
问题:shuffle一定有网络传输吗?有网络传输的一定是Shuffle吗?
9.1 Shuffle的概念
通过网络将数据传输到多台机器,数据被打散,但是有网络传输,不一定就有shuffle,Shuffle的功能是将具有相同规律的数据按照指定的分区器的分区规则,通过网络,传输到指定的机器的一个分区中,需要注意的是,不是上游的Task发送给下游的Task,而是下游的Task到上游拉取数据。
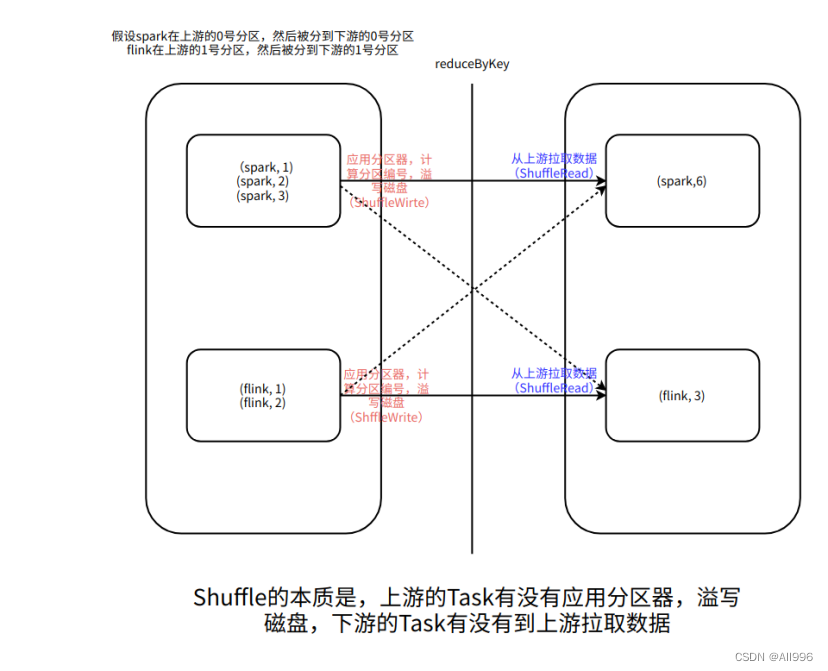
9.2 reduceByKey一定会Shuffle吗
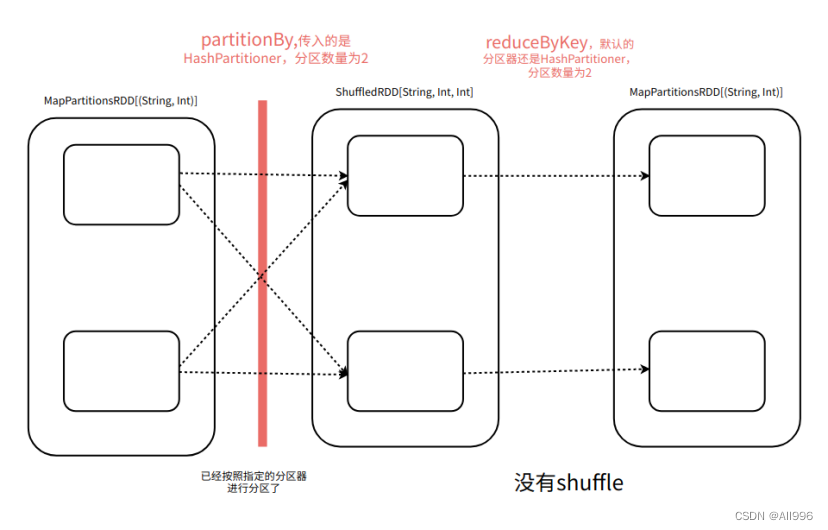
不一定,如果一个RDD事先使用了HashPartitioner分区先进行分区,然后再调用reduceByKey方法,使用的也是HashPartitioner,并且没有改变分区数量,调用redcueByKey就不shuffle
| 如果自定义分区器,多次使用自定义的分区器,并且没有改变分区的数量,为了减少shuffle的次数,提高计算效率,需要重新自定义分区器的equals方法 |
例如:
| Scala |
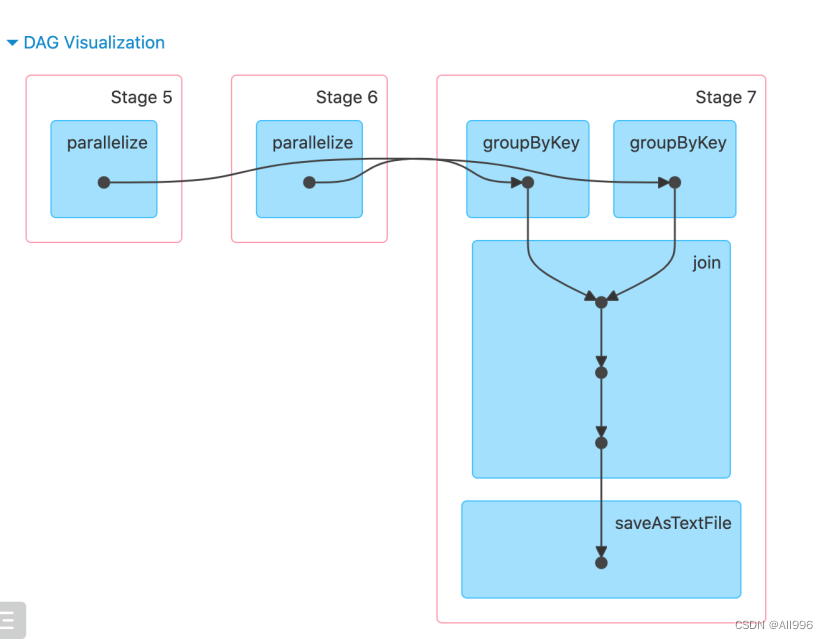
9.3 join一定会Shuffle吗
不一定,join一般情况会shuffle,但是如果两个要join的rdd实现都使用相同的分区去进行分区了,并且join时,依然使用相同类型的分区器,并且没有改变分区数据,那么不shuffle
| Scala |
分析一下下面的图片,有几次shuffle,有几个Stage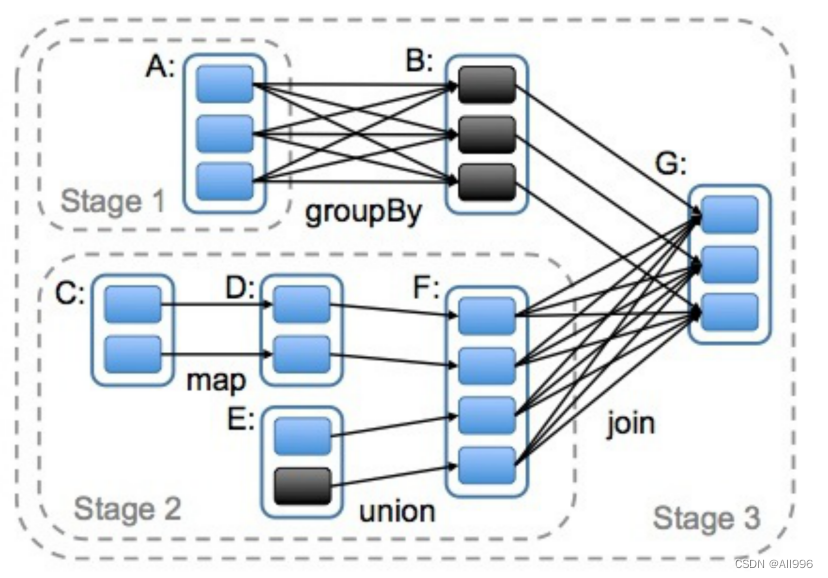
上面的分支没有shuffle,因为实现已经使用groupBy进行分区了(使用了HashPartitioner,分区数量为3),在join是,使用的分区器也是HashPartitioner,分区数量为3,所有不shuffle
下面的分支没有实现进行分区(即使使用了HashPartitioner进行分区,但是jion后的分区数量发生了变化),所有要shuffle
9.4 shuffle数据的复用
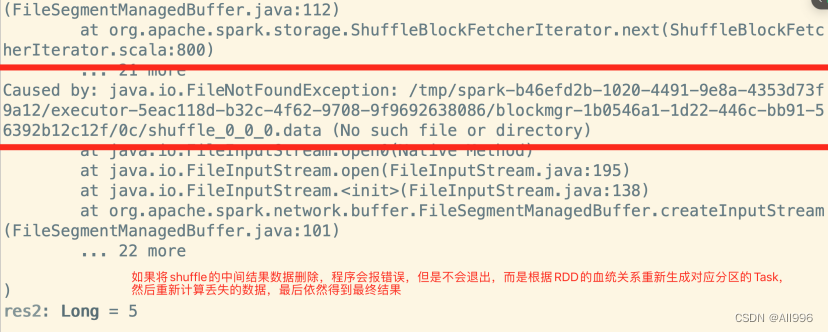
spark在shuffle时,会应用分区器,当读取达到一定大小或整个分区的数据被处理完,会将数据溢写磁盘磁盘(数据文件和索引文件),溢写持磁盘的数据,会保存在Executor所在机器的本地磁盘(默认是保存在/temp目录,也可以配置到其他目录),只要application一直运行,shuffle的中间结果数据就会被保存。如果以后再次触发Action,使用到了以前shuffle的中间结果,那么就不会从源头重新计算而是,而是复用shuffle中间结果,所有说,shuffle是一种特殊的persist,以后再次触发Action,就会跳过前面的Stage,直接读取shuffle的数据,这样可以提高程序的执行效率。
正常情况:
再次触发Action
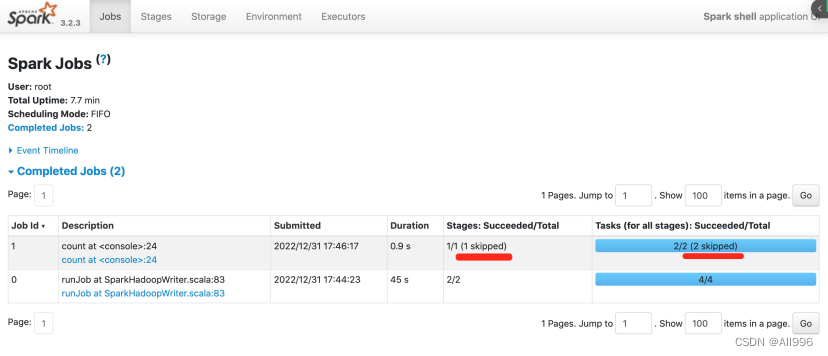
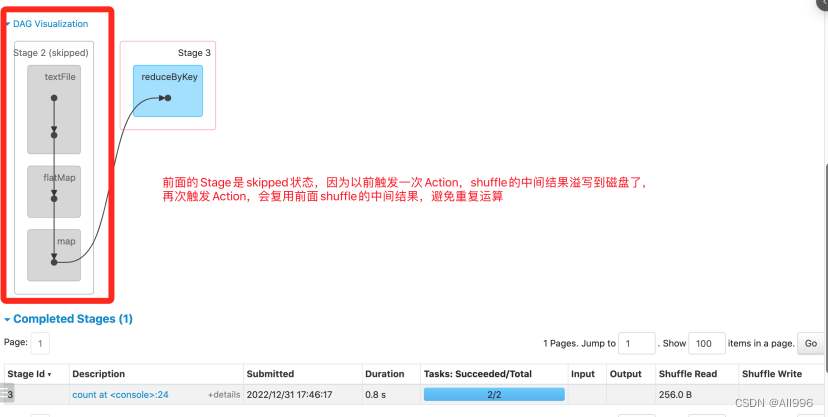
如果由于机器宕机或磁盘问题,部分shuffle的中间数据丢失,以后再次触发Action,使用到了shuffle中间结果数据,但是部数据无法访问,spark会根据RDD的依赖关系(RDD的血统)重新生成对应分区的Task,重新计算丢失的数据!