前言
关于图的最短路径问题,是图这种数据结构中的经典问题。也是与我们的生活息息相关的,比如上海四通八达的地铁线路,从一个地铁站,到另一个地铁站,可能有很多种不同的路线。那么,我们选哪种路线,用时最短?换乘最少?花费最少?
目标不同,选择的方案可能不一样。简单的图形网络,可以靠我们的经验和感觉,但是复杂的道路,或者地铁网络,需要计算机来帮我们提供最佳的方案。比如现在出行必备的百度地图,外卖软件上给骑手做的路线规划,都是通过各种算法,做出最合理的安排,也叫最短路径。
1. 问题描述
 ---------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------------------------------------
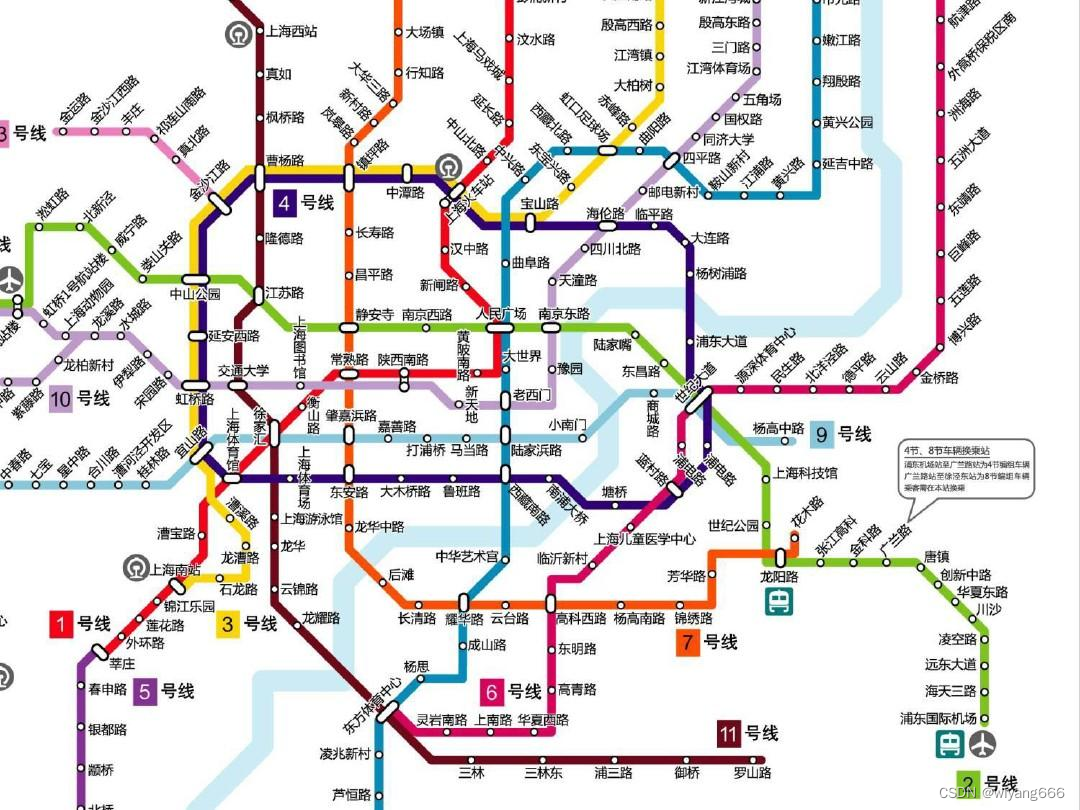
如上面的地铁路线图所示,这个路线图通过前面的学习,可以抽象为一个加权图。根据我们的目标不同,两个站点之间的权重可以设置为不同的值,比如追求时间最短,那我们两个站点之间的权重可以是这一段路程地铁运行耗费时间。这样当我们选定出发点(也叫源点)和终点后,通过计算不同路径的权重和,得到不同方案的最终权重,最终找到一种最省时间的方案。也就是计算两点之间的最短路径。
在我们计算最短路径的过程中,有下面几种经典的算法,帮助我们提高计算的效率,最终实现快速,方便,实时的给出出行方案。
为方便讲解,我们简化问题,以下图为例,

我们要求V0到V8的最短路径,如图可以看到,每条边上都有对应的权重。
2. 迪杰斯特拉算法(Dijkstra)
2.1 算法思想
迪杰斯特拉算法简单来说是按照路径长度的递增的次序,产生最短路径的算法。下面我们推演一下算法计算过程:
- 如果求V0到V1的最短距离,很明显答案就是1,路径是V0到V1的连线
- 同时,可以看到顶点V1与V2,V3,V4相连。此时,我们求得V0->V1->V2=1+3=4 ,V0->V1->V3=1+7=8,V0->V1->V4=1+5=6。
- 此时,可以得到V0到V2的最短路径是4 ,路线是V0-V1-V2,而不是V0到V2的直线距离
- 由于顶点V2还与V4、V5连线,所以此时我们同时求得了V0->V2->V4其实就是V0->V1->V2->V4=4+1=5,V0->V2->V5=4+7=11。这里V0-V2我们用的是刚才计算出来的较小的4。此时我们也发现V0-V1-V2-V4=5要比V0->V1->V4=6还要小。所以到v4目前的最小距离是5
- 当我们要求V0到V3的最短距离时,通向v3的三条边,除了V6没有研究过外,V0-V1-V3的结果是8,而V0-V4-V3=5+2=7。因此到v3的最短距离是7
- 可以看到,它并不是一下子就求出了vo到v8的最短路径,而是一步步求出它们之间顶点的最短路径,过程中都是基于已经求出的最短路径的基础上,求得更远顶点的最短路径,最终得到你要的结果。
2.2 代码实现
2.2.1 构造邻接矩阵
我们先将上面的路线图,通过邻接矩阵保存下来,方便后续计算使用。
package org.wanlong.algorithm;
/**
* @author wanlong
* @version 1.0
* @description: 迪杰斯特拉算法
* @date 2023/6/20 14:33
*/
public class DijkStra {
//邻接矩阵保存图的信息
private int[][] matrix;
/**
* 表示正无穷
*/
private int MAX_WEIGHT = Integer.MAX_VALUE;
/**
* 顶点集合
*/
private String[] vertexes;
/**
* @return void
* @Description:将图的信息维护到邻接矩阵中
* @Author: wanlong
* @Date: 2023/6/20 14:35
**/
private void createGraph() {
matrix = new int[9][9];
vertexes = new String[9];
vertexes[0] = "v0";
vertexes[1] = "v1";
vertexes[2] = "v2";
vertexes[3] = "v3";
vertexes[4] = "v4";
vertexes[5] = "v5";
vertexes[6] = "v6";
vertexes[7] = "v7";
vertexes[8] = "v8";
int[] v0 = {0, 1, 5, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT};
int[] v1 = {1, 0, 3, 7, 5, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT};
int[] v2 = {5, 3, 0, MAX_WEIGHT, 1, 7, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT};
int[] v3 = {MAX_WEIGHT, 7, MAX_WEIGHT, 0, 2, MAX_WEIGHT, 3, MAX_WEIGHT, MAX_WEIGHT};
int[] v4 = {MAX_WEIGHT, 5, 1, 2, 0, 3, 6, 9, MAX_WEIGHT};
int[] v5 = {MAX_WEIGHT, MAX_WEIGHT, 7, MAX_WEIGHT, 3, 0, MAX_WEIGHT, 5, MAX_WEIGHT};
int[] v6 = {MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, 3, 6, MAX_WEIGHT, 0, 2, 7};
int[] v7 = {MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, 9, 5, 2, 0, 4};
int[] v8 = {MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, MAX_WEIGHT, 7, 4, 0};
matrix[0] = v0;
matrix[1] = v1;
matrix[2] = v2;
matrix[3] = v3;
matrix[4] = v4;
matrix[5] = v5;
matrix[6] = v6;
matrix[7] = v7;
matrix[8] = v8;
}
}
2.2.2 算法实现
public class Dijkstra {
/**
* Dijkstra最短路径。
* vs -- 起始顶点(start vertex) 即,统计图中"顶点vs"到其它各个顶点的最短路径。
*/
public void dijkstra(int vs) {
// flag[i]=true表示"顶点vs"到"顶点i"的最短路径已成功获取
boolean[] flag = new boolean[vertexes.length];
// U则是记录还未求出最短路径的顶点(以及该顶点到起点s的距离),与 flag配合使用,flag[i] == true 表示U中i顶点已被移除
int[] U = new int[vertexes.length];
// 前驱顶点数组,即,prev[i]的值是"顶点vs"到"顶点i"的最短路径所经历的全部顶点中,位于"顶点i"之前的那个顶点。
int[] prev = new int[vertexes.length];
// S的作用是记录已求出最短路径的顶点
String[] S = new String[vertexes.length];
// 步骤一:初始时,S中只有起点vs;U中是除vs之外的顶点,并且U中顶点的路径是"起点vs到该顶点的路径"。
for (int i = 0; i < vertexes.length; i++) {
flag[i] = false; // 顶点i的最短路径还没获取到。
U[i] = matrix[vs][i]; // 顶点i与顶点vs的初始距离为"顶点vs"到"顶点i"的权。也就是邻接矩阵vs行的数据。
prev[i] = 0; //顶点i的前驱顶点为0
}
// 将vs从U中“移除”(U与flag配合使用)
flag[vs] = true;
U[vs] = 0;
// 将vs顶点加入S
S[0] = vertexes[vs];
// 步骤一结束
//步骤四:重复步骤二三,直到遍历完所有顶点。
// 遍历vertexes.length-1次;每次找出一个顶点的最短路径。
int k = 0;
for (int i = 1; i < vertexes.length; i++) {
// 步骤二:从U中找出路径最短的顶点,并将其加入到S中(如果vs顶点到x顶点还有更短的路径的话,那么
// 必然会有一个y顶点到vs顶点的路径比前者更短且没有加入S中
// 所以,U中路径最短顶点的路径就是该顶点的最短路径)
// 即,在未获取最短路径的顶点中,找到离vs最近的顶点(k)。
int min = MAX_WEIGHT;
for (int j = 0; j < vertexes.length; j++) {
if (flag[j] == false && U[j] < min) {
min = U[j];
k = j;
}
}
//将k放入S中
S[i] = vertexes[k];
//步骤二结束
//步骤三:更新U中的顶点和顶点对应的路径
//标记"顶点k"为已经获取到最短路径(更新U中的顶点,即将k顶点对应的flag标记为true)
flag[k] = true;
//修正当前最短路径和前驱顶点(更新U中剩余顶点对应的路径)
//即,当已经"顶点k的最短路径"之后,更新"未获取最短路径的顶点的最短路径和前驱顶点"。
for (int j = 0; j < vertexes.length; j++) {
//以k顶点所在位置连线其他顶点,判断其他顶点经过最短路径顶点k到达vs顶点是否小于目前的最短路径,是,更新入U,不是,不做处理
int tmp = (matrix[k][j] == MAX_WEIGHT ? MAX_WEIGHT : (min + matrix[k][j]));
if (flag[j] == false && (tmp < U[j])) {
U[j] = tmp;
//更新 j顶点的最短路径前驱顶点为k
prev[j] = k;
}
}
//步骤三结束
}
//步骤四结束
// 打印dijkstra最短路径的结果
System.out.println("起始顶点:" + vertexes[vs]);
for (int i = 0; i < vertexes.length; i++) {
System.out.print("最短路径(" + vertexes[vs] + "," + vertexes[i] + "):" + U[i] + " ");
List<String> path = new ArrayList<>();
int j = i;
while (true) {
path.add(vertexes[j]);
if (j == 0)
break;
j = prev[j];
}
for (int x = path.size() - 1; x >= 0; x--) {
if (x == 0) {
System.out.println(path.get(x));
} else {
System.out.print(path.get(x) + "->");
}
}
}
System.out.println("顶点放入S中的顺序:");
for (int i = 0; i < vertexes.length; i++) {
System.out.print(S[i]);
if (i != vertexes.length - 1)
System.out.print("-->");
}
}
2.3 测试验证
@Test
public void testDijkstra(){
Dijkstra dijkstra = new Dijkstra();
dijkstra.createGraph();
dijkstra.dijkstra(0);
}
输出结果为:
起始顶点:v0
最短路径(v0,v0):0 v0
最短路径(v0,v1):1 v0->v1
最短路径(v0,v2):4 v0->v1->v2
最短路径(v0,v3):7 v0->v1->v2->v4->v3
最短路径(v0,v4):5 v0->v1->v2->v4
最短路径(v0,v5):8 v0->v1->v2->v4->v5
最短路径(v0,v6):10 v0->v1->v2->v4->v3->v6
最短路径(v0,v7):12 v0->v1->v2->v4->v3->v6->v7
最短路径(v0,v8):16 v0->v1->v2->v4->v3->v6->v7->v8
顶点放入S中的顺序:
v0-->v1-->v2-->v4-->v3-->v5-->v6-->v7-->v8
3. 弗洛伊德算法(Floyd)
3.1 算法思想
在求解图的最短路径的方法中,最朴素的方法是:以图中每个顶点为源点共调用n次算法。这种计算时间复杂度是O(n^3)。 那么实际上,还有一种算法,时间复杂度还是O(n^3),这就是弗洛伊德算法。相对于常规求解,弗洛伊德的优势是形式上会简单一点。
- 利用二维数组dist[i][j]记录当前vi到vj的最短路径长度,数组dist的初值等于图的带权邻接矩阵;
- 集合S记录当前允许的中间顶点,初值S={}
- 依次向S中加入v0 ,v1… vn-1,每加入一个顶点,对dist[i][j]进行一次修正:设S={v0 ,v1… vk-1},加入vk,则dist(k)[i][j] = min{ dist(k-1)[i][j],dist(k-1)[i][k]+dist(k-1)[k][j]}。
- 其中,dist(k)[i][j]的含义:允许中间顶点的序号最大为k时从vi到vj的最短路径长度。dist(n-1)[i][j]就是vi到vj的最短路径长度。
3.2 代码实现
package org.wanlong.graph;
import java.util.ArrayList;
import java.util.List;
/**
* 弗洛伊德算法
*/
public class Floyed {
private static int MAX_WEIGHT = Integer.MAX_VALUE;
//dist[i][j]=MAX_WEIGHT<==>i 和 j之间没有边
public int[][] dist;
//顶点i 到 j的最短路径长度,初值是i到j的边的权重
private int[][] path;
public List<Integer> result = new ArrayList<Integer>();
public void findShortestPath(int begin, int end, int[][] matrix) {
floyd(matrix);
result.add(begin);
findPath(begin, end);
result.add(end);
}
public void findPath(int i, int j) {
int k = path[i][j];
if (k == -1) {
return;
}
findPath(i, k); //递归
result.add(k);
findPath(k, j);
}
public void floyd(int[][] matrix) {
int size = matrix.length;
//initialize dist and path
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
path[i][j] = -1;
dist[i][j] = matrix[i][j];
}
}
for (int k = 0; k < size; k++) {
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
if (dist[i][k] != MAX_WEIGHT &&
dist[k][j] != MAX_WEIGHT &&
dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
path[i][j] = k;
}
}
}
}
}
public Floyed(int size) {
this.path = new int[size][size];
this.dist = new int[size][size];
}
}
3.3 测试验证
@Test
public void floyed(){
//构造邻接矩阵
createGraph();
//定义开始节点,和终点
int begin = 0;
int end = 4;
//调用构造方法,传入节点数
Floyed floyed = new Floyed(9);
floyed.findShortestPath(begin, end, matrix);
List<Integer> list = floyed.result;
System.out.println(begin + " 到" + end + ",最短路径是:");
System.out.println(list.toString());
System.out.println("路径长为:"+floyed.dist[begin][end]);
}
测试结果:
0 到4,最短路径是:
[0, 1, 2, 4]
路径长为:5
4. 参考文献
大话数据结构书籍
以上,本人菜鸟一枚,如有错误,请不吝指正。