LOMO:Full Parameter Fine-Tuning for large language models with limited resources
- Introduction
- Method
- Rethink the functionality of optimizer
- Using SGD
- LOMO: LOw-Memory Optimization
- 实验
- 参考
Introduction
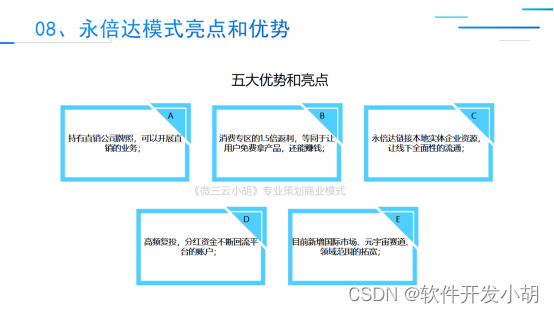
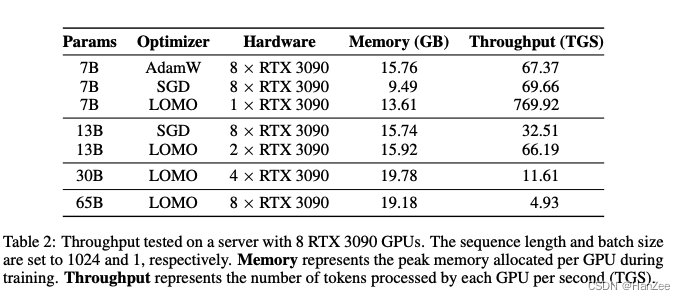
在这篇文章中,作者的目的是探索在有限资源上的全参数微调,作者通过各种分析,发现SGD在LLM场景下的全参数微调是很有前景的。于是作者进一步的改进SGD,最终版本称之为LOMO,可以在8块3090上微调65B。
这篇文章的主要贡献有:
- 提供为何SGD在LLM领域有前景。
- 提出了LOMO optimizer。
- 验证了LOMO的高效性。
Method
Rethink the functionality of optimizer
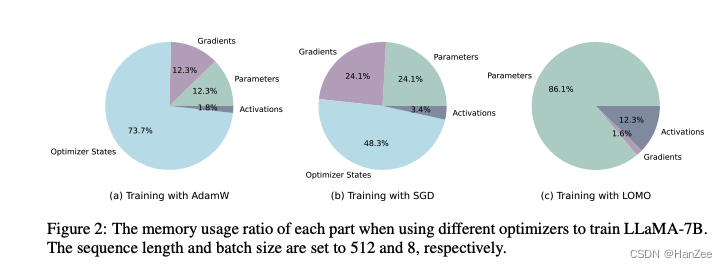
现在流行的optimizer是Adam一脉,但是储存它的的中间状态,也就是optimizer state,就多占用了2倍参数的内存,dominate 了内存使用。
Using SGD
尽管Adam目前已经十分成功在深度学习领域,但是由于内存的占用,作者想寻找一个更便宜的optimizer,于是SGD就进入了视野,它的内存占用更小。
以前的工作中,讨论了SGD的挑战有:
- large curvature surface
- local optimum
- saddle points
Smoother loss surface
上述的问题大多是基于以前的研究,那个时候模型还没有特别大,只是能解决特定的类别问题。然而到了大模型领域,作者发现损失函数的损失平面要比小模型的光滑很多,也就是模型训练要跟稳定(主要预训练语料与下游任务差别不大)。
Local optimum is good enough
作者认为在微调LLM的时候,不需要LLM彻底的大改变(也就是避免灾难性遗忘),而让损失函数到达局部最优解,也是一个不错的选择。
Distant saddle points
预训练后的模型损失函数的点一般位于山谷,但是如果在指令微调时,两种语料有一定的差异,可能造成模型陷入鞍点(鞍点多位于山顶与山谷中间),作者认为在预训练时期就引入指令数据可以有效的缓解此问题。
上述三点可能无法证明此问题,作者进行了进一步的公示推倒,证明了LLM的loss surface是光滑的。
LOMO: LOw-Memory Optimization

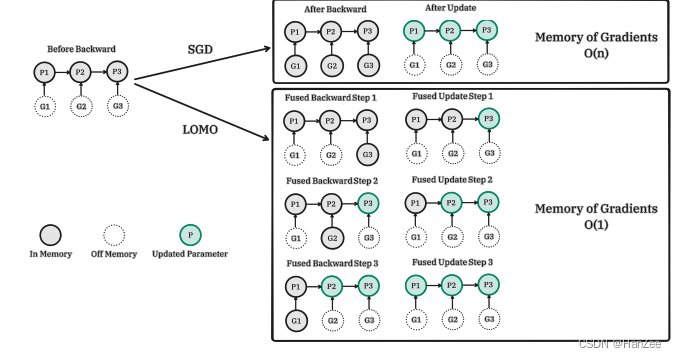
由于SGD不像Adam那样需要计算一些中间参数,也就不需要储存optimizer state,于是作者在SGD的基础上,合并了计算梯度与更新的参数的过程:

但是这样也无法normalize和clipping梯度,会对训练造成一定的弊端,为了缓解这个问题作者是用了一个人值得商榷的解决方案:
当前的训练框架根据所有参数计算梯度范数,并需要两个反向传播过程。节省额外的反向传播过程的一种解决方案是使用一组参数近似梯度张量的范数,例如,相邻的层。然而,这种方法实际上是有偏差的,因为它导致不同参数的更新步长不同。在更新过程中,根据梯度范数,参数会乘以一个比例因子。由于不同参数组之间的梯度范数不同,这样的近似会导致比例因子的差异。尽管存在这个限制,这种分组梯度剪裁方法可以被视为根据梯度范数向不同参数组应用动态学习率。
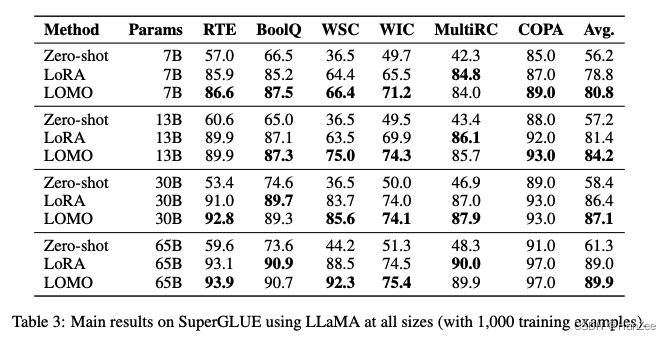
实验
参考
https://arxiv.org/pdf/2306.09782.pdf