文章目录
- 堆
- 维护堆的性质
- 建堆
- 堆排序算法
- 优先队列详解
- cpp标准库 priority_queue
- 参考文献
堆
虽然“堆”这个词源自堆排序,但是目前它已经被引申为“垃圾存储机制”,例如在Java和Lisp语言中所定义的。强调一下,我们使用的堆不是垃圾收集存储,并且在本文的任何部分,只要涉及堆,指的都是堆数据结构, 而不是垃圾收集存储。
堆是一个数组,它可以被看成是一个近似的完全二叉树。故堆经常也被称为二叉堆。堆和完全二叉树的不同点在于堆的最底层可能不是充满的,即除了最底层外,该树是完全充满的,而且是从左向右填充。
表示堆的数组A包括两个属性:A.length通常给出数组元素的个数, A.heap-size表示有多少个堆元素存储在该数组中。也就是说,虽然A[1…A.length]可能都存有数据,但只有A[1…A.heap-size]中存放的是堆的有效元素,这里0<=A.heap-size<=A.length. 树的根节点是A[1],这样给定一个节点的下标i, 我们很容易计算得到它的父节点、左孩子和右孩子的下标:
下标为i的结点的父亲节点的下标为:PARNET(i) = ⌊ i / 2 ⌋ \lfloor i/2\rfloor ⌊i/2⌋.
结点i的左孩子的下标为LEFT(i) = 2i, 右孩子的下标为RIGHT(i) = 2i+1;
注:完全二叉树的每个叶节点高度高度,也每个内部节点均有2个孩子。
二叉堆可以分为两种形式:最大堆和最小堆。在这两种堆中,结点的值都要满足堆的性质。
在最大堆中,最大堆性质是指出了根以外的所有结点i,都要满足: A[PARENT(i)]>=A[i]. 即除了根节点以外的所有结点的值至多与其父结点一样大。因此,最大堆中的最大元素存放在根节点中。最小堆的组织形式恰好相反。
堆中结点的高度: 如果把堆看成是一棵树,我们定义堆中一个结点的高度就为该结点到叶结点最长简单路径上边的数目;进而我们可以把堆的高度定义为根节点的高度。
我们要掌握如何建堆,如何调整,如何提取最大元素。
维护堆的性质
MAX-HEAPIFY是用于维护最大堆性质的重要过程。它的输入为一个数组A和一个下标i。在调用MAX-HEAPIFY的时候,**我们假定根节点为LEFT(i)和RIGHT(i)的二叉树都是最大堆,**但这时A[i]有可能小于其他孩子,这样就违背了最大堆的性质。MAX-HEAPIFY通过让A[i]的值在最大堆中“逐级下降”,从而使得下标i为根节点的子树重新遵循最大堆的性质。
MAX-HEAPIFY(A, i)
1 l = LEFT(i)
2 r = RIGHT(i)
3 if l<=A.heap-size and A[l]>A[i]
largest = l
else
larest = i
if r<=A.heap-size and A[r]>A[largest]
largest = r
if largest \ne i
exchange A[i] with A[largest]
MAX-HEAPIFY(A, largest)
对于一个树高为h的节点来说, MAX-HEAPIFY的时间复杂度是O(h).
建堆
我们可以用自底向上的方法利用过程MAX-HEAPIFY把一个大小为n = A.length的数组A[1…n]转化为最大堆。可知,当用数组存储n个元素的堆时,叶节点下标分别是 ⌊ n / 2 ⌋ + 1 , ⌊ n / 2 ⌋ + 2 , … , n \lfloor n/2\rfloor+1,\lfloor n/2\rfloor+2,\dots, n ⌊n/2⌋+1,⌊n/2⌋+2,…,n. (由于n的父节点的下标为 ⌊ n / 2 ⌋ \lfloor n/2\rfloor ⌊n/2⌋, 且PARENT(n)的下一个节点即为第一个叶节点,故叶节点下标分别是 ⌊ n / 2 ⌋ + 1 , ⌊ n / 2 ⌋ + 2 , … , n \lfloor n/2\rfloor+1,\lfloor n/2\rfloor+2,\dots, n ⌊n/2⌋+1,⌊n/2⌋+2,…,n. )每个叶节点都可以看成只包含一个元素的堆。过程BUILD-MAX-HEAP对树中的其他结点都调用一次MAX-HEAPIFY.
BUILD-MAX-HEAP(A)
1 A.heap-size = A.length
2 for i =
⌊
A
.
l
e
n
g
t
h
/
2
⌋
\lfloor A.length /2 \rfloor
⌊A.length/2⌋ downto 1
3 MAX-HEAPIFY(A, i)
时间复杂度为O(n).
堆排序算法
初始时候,堆排序算法利用BUILD-MAX-HEAP将输入数组A[1…n]建成最大堆,其中n = A.length. 因为数组中的最大元素总在根节点A[1]中,通过把它与A[n]进行互换,我们可以让该元素放到正确的位置。这时候,如果我们从堆中去掉结点n(这一操作可以通过减少A.heap-size的值来实现),剩余的结点中,原来根的孩子结点仍然是最大堆,而新的根节点可能会违背最大堆的性质。为了维护最大堆的性质,我们要做的是调用MAX-HEAPIFY(A, 1), 从而在A[1…n-1]上构造一个新的最大堆。堆排序算法会不断重复这一个过程,直到堆的大小从n-1降到2.
HEAPSORT(A)
1 BUILD-MAX-HEAP(A)
2 for i = A.length downto 2
3 exchange A[1] with A[i]
4 A.heap-size -= 1
5 MAX-HEAPIFY(A,1)
时间复杂度为O(n logn).
优先队列详解
优先队列虽然也叫做队列,但是和队列的内部实现是不同的。优先队列的数据结构基础是堆,是通过堆来实现的。所以要想学会优先队列,首先要学会堆的思想。
优先队列有两种形式:最大优先队列和最小优先队列。
优先队列(priority queue)是一种用来维护由一组元素构成的集合S的数据结构,其中的每一个元素都有一个相关的值,称为关键字(key)。优先程度是基于关键字的。一个最大优先队列支持以下操作:
INSERT(S, x): 把元素x插入集合S中。这一操作等价于 S = S ∪ x S = S\cup {x} S=S∪x.
MAXIMUM(S): 返回S中具有最大关键字的元素。
EXTRACT-MAX(S): 去掉并返回S中的具有最大关键字的元素。
INCREASE-KEY(S, x, k): 将元素x的关键字值增加到k, 这里假设k的值不小于x的原关键字值。 这里x可以是索引。
下面我们讨论如何实现最大优先队列的操作。
HEAP-MAXIMUM(A)
1 return A[1]
HEAP-EXTRACT-MAX(A)
1 if A.heap-size < 1
2 error "heap underflow"
3 max = A[1]
4 A[1] = A[A.heap-size]
5 A.heap-size = A.heap-size - 1
5 MAX-HEAPIFY(A,1)
6 return max
HEAP-EXTRACT-MAX的时间复杂度为O(log n).
在优先队列中,我们希望增加关键字的优先队列元素由对应的数组下标来标识。
这一操作需要首先将元素A[i]的关键字更新为新值。因为增大A[i]的关键字可能会违反最大堆的性质,所以需要调整该元素的位置。当前元素会不断地与其父结点比较,如果当前元素的关键字较大,则当前元素与其父结点进行交换。这一过程会不断地重复,直到当前元素的关键字小于其父结点时终止,因为此时已经重新符合了最大堆的性质。
HEAP-INCREASE-KEY(A, i, key)
1 if(key<A[i])
2 error "new key is smaller than current key"
3 A[i] = key
4 while i>1 and A[PARENT(i)] < A[i]
5 exchange A[i] with A[PARENT(i)]
6 i = A[PARENT(i)]
插入操作
MAX-HEAP-INSERT能够实现INSERT操作。它的输入是要被插入到最大堆A中的新元素的关键字。MAX-HEAP-INSERT首先通过增加一个关键字为 − ∞ -\infty −∞的叶节点来扩展最大堆。然后调用HEAP-INCREASE-KEY为新结点设置对应的关键字,同时保持最大堆的性质。
MAX-HEAP-INSERT(A, key)
1 A.heap-size = A.heap-size + 1
2 A[A.heap-size] = -\infty
3 HEAP-INCREASE-KEY(A, A.heap-size, key)
cpp标准库 priority_queue
cpp标准库priority_queue提供了优先队列的实现,优先队列定义于 https://cplusplus.com/reference/queue/ 这个头文件中。该头文件存在两个容器类,一个是queue, 另一个是priority_queue. 第一个是先进先出队列,第二个是优先队列。
优先队列是一类容器适配器(container adaptor), 专门设计来使得**它的第一个元素总是它所包含的“最优先“的那个元素,**优先的标准某种strict weak ordering 标准(严格弱序列标准)。
template<
class T,
class Container = std::vector<T>,
class Compare = std::less<typename Container::value_type>
> class priority_queue;
上述是priority_queue的模板类定义。Compare提供了”优先”的定义。
关于Compare: 如果Compare的第一个参数位于第二个参数的前面,则返回true. 例如上述模板类的默认参数是std::less ,即数字小的位于前面,而优先队列的的第一个(front)元素是最大的元素,故在compare函数中位于前面的元素实际上后输出。即队列的front包含了根据Compare所规定的弱排序的位于后边的元素。仍然以less为例,2<3, 2位于3的前面。 故2后输出。可以形象地记忆为:位于小于号左边的人先来,先来的人在售票大厅门口等着,将前面的位置留给后来的德高望重的人。
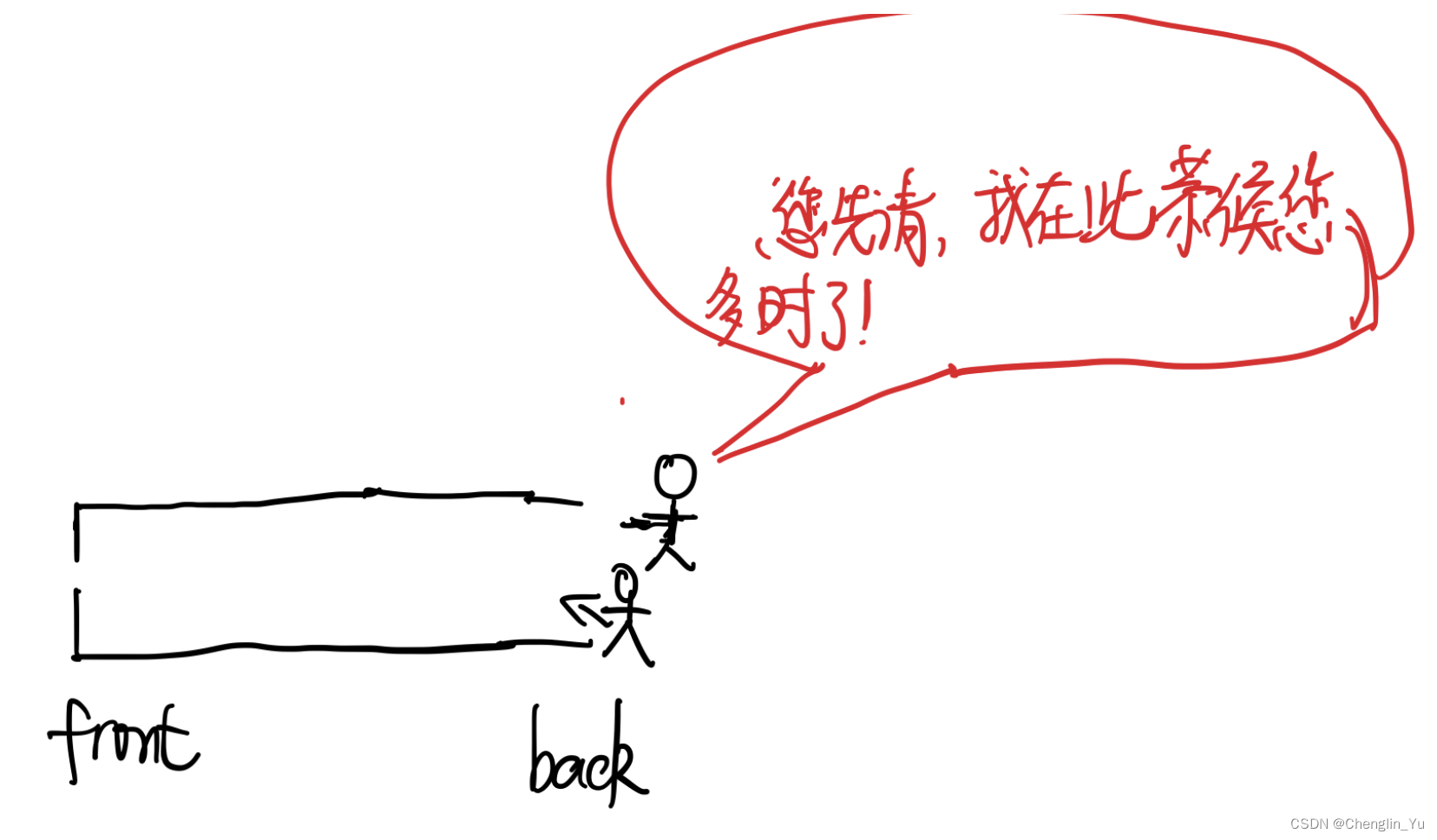
总之,记忆一点:排序位于后面的元素是优先级更高的。
参考文献
[1] 算法导论 第6章 堆排序
[2] https://cplusplus.com/reference/queue/