有两种方法可以保存模型:
- ·使用检查点,一种简单的在硬盘上保存变量的方法
- ·使用SavedModel,模型结构及检查点
检查点不包含任何关于模型自身的描述:它们只是一种简单的存储参数并能让开发者正确恢复它的方法。
SavedModel格式在保存参数值的基础上加上了计算过程的序列化描述
在TensorFlow 2.0中可以用两个对象保存和恢复模型参数:
- ·tf.train.Checkpoint是一个基于对象的序列化/反序列化器。
- ·tf.train.CheckpointManager是一个能用tf.train.Checkpoint实例来存储和管理检查点的对象。

import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
def make_model(n_classes):
return tf.keras.Sequential(
[
tf.keras.layers.Conv2D(
32, (5, 5), activation=tf.nn.relu, input_shape=(28, 28, 1)
),
tf.keras.layers.MaxPool2D((2, 2), (2, 2)),
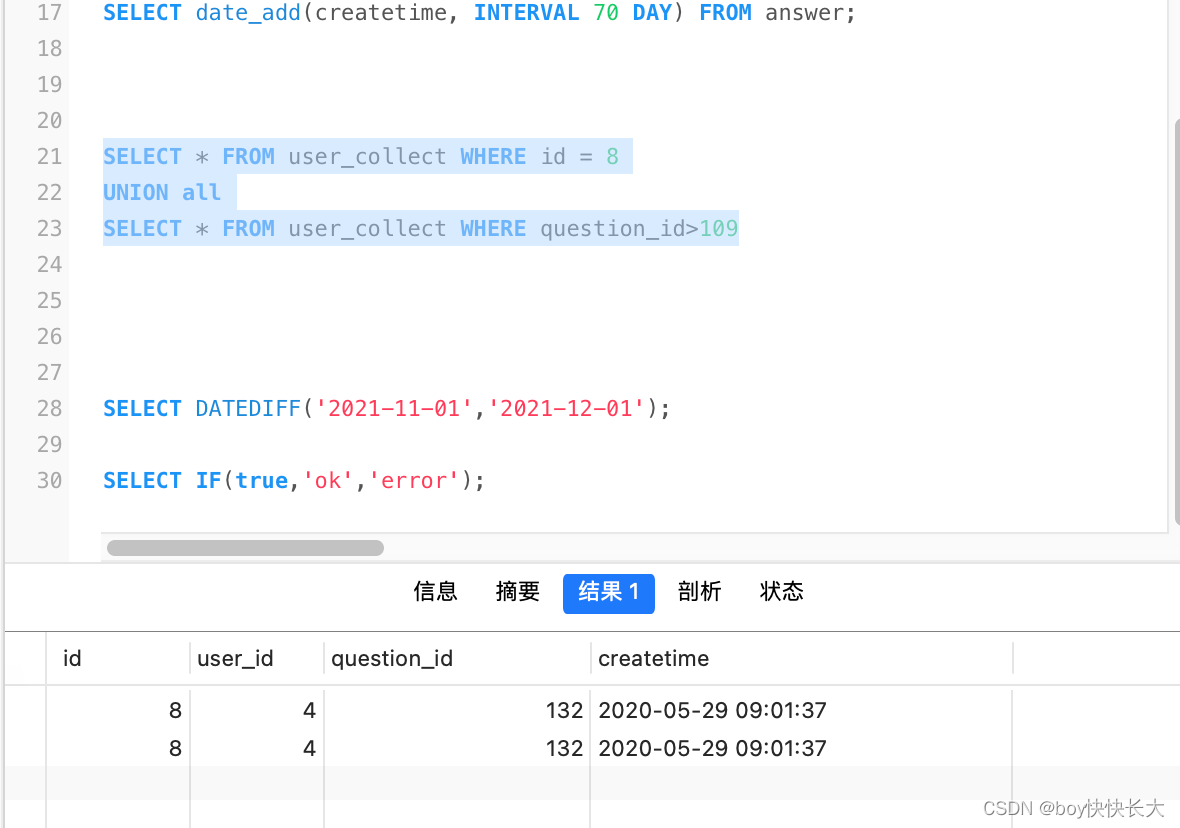
tf.keras.layers.Conv2D(64, (3, 3), activation=tf.nn.relu),
tf.keras.layers.MaxPool2D((2, 2), (2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(n_classes),
]
)
def load_data():
(train_x, train_y), (test_x, test_y) = fashion_mnist.load_data()
# Scale input in [-1, 1] range
train_x = tf.expand_dims(train_x, -1)
train_x = (tf.image.convert_image_dtype(train_x, tf.float32) - 0.5) * 2
train_y = tf.expand_dims(train_y, -1)
test_x = test_x / 255.0 * 2 - 1
test_x = (tf.image.convert_image_dtype(test_x, tf.float32) - 0.5) * 2
test_y = tf.expand_dims(test_y, -1)
return (train_x, train_y), (test_x, test_y)
def train():
# Define the model
n_classes = 10
model = make_model(n_classes)
# Input data
(train_x, train_y), (test_x, test_y) = load_data()
# Training parameters
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True)
step = tf.Variable(1, name="global_step")
optimizer = tf.optimizers.Adam(1e-3)
ckpt = tf.train.Checkpoint(step=step, optimizer=optimizer, model=model)
manager = tf.train.CheckpointManager(ckpt, "./tf_ckpts", max_to_keep=3)
ckpt.restore(manager.latest_checkpoint)
if manager.latest_checkpoint:
print(f"Restored from {manager.latest_checkpoint}")
else:
print("Initializing from scratch.")
accuracy = tf.metrics.Accuracy()
mean_loss = tf.metrics.Mean(name="loss")
# Train step function
@tf.function
def train_step(inputs, labels):
with tf.GradientTape() as tape:
logits = model(inputs)
loss_value = loss(labels, logits)
gradients = tape.gradient(loss_value, model.trainable_variables)
# TODO: apply gradient clipping here
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
step.assign_add(1)
accuracy.update_state(labels, tf.argmax(logits, -1))
return loss_value, accuracy.result()
epochs = 10
batch_size = 32
nr_batches_train = int(train_x.shape[0] / batch_size)
print(f"Batch size: {batch_size}")
print(f"Number of batches per epoch: {nr_batches_train}")
train_summary_writer = tf.summary.create_file_writer("./log/train")
with train_summary_writer.as_default():
for epoch in range(epochs):
for t in range(nr_batches_train):
start_from = t * batch_size
to = (t + 1) * batch_size
features, labels = train_x[start_from:to], train_y[start_from:to]
loss_value, accuracy_value = train_step(features, labels)
mean_loss.update_state(loss_value)
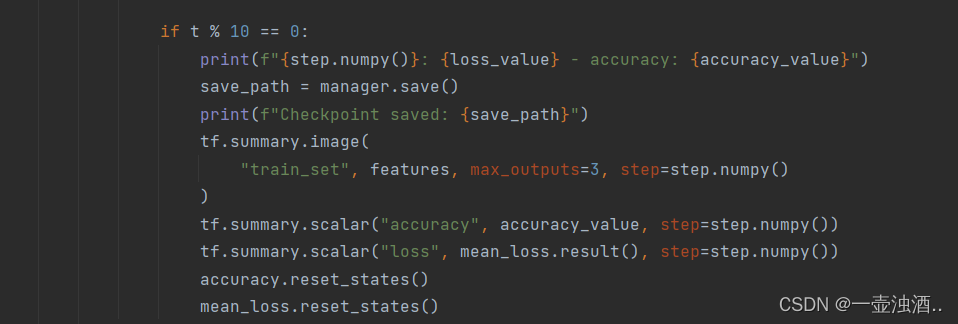
if t % 10 == 0:
print(f"{step.numpy()}: {loss_value} - accuracy: {accuracy_value}")
save_path = manager.save()
print(f"Checkpoint saved: {save_path}")
tf.summary.image(
"train_set", features, max_outputs=3, step=step.numpy()
)
tf.summary.scalar("accuracy", accuracy_value, step=step.numpy())
tf.summary.scalar("loss", mean_loss.result(), step=step.numpy())
accuracy.reset_states()
mean_loss.reset_states()
print(f"Epoch {epoch} terminated")
# Measuring accuracy on the whole training set at the end of epoch
for t in range(nr_batches_train):
start_from = t * batch_size
to = (t + 1) * batch_size
features, labels = train_x[start_from:to], train_y[start_from:to]
logits = model(features)
accuracy.update_state(labels, tf.argmax(logits, -1))
print(f"Training accuracy: {accuracy.result()}")
accuracy.reset_states()
if __name__ == "__main__":
train()import tensorflow as tf
# 模型
class Net(tf.keras.Model):
"""A simple linear model."""
def __init__(self):
super(Net, self).__init__()
self.l1 = tf.keras.layers.Dense(5)
def call(self, x):
return self.l1(x)
net = Net()
# keras保存权重
net.save_weights('easy_checkpoint') # 从 tf.keras 训练 API 保存
# 加载数据
def toy_dataset():
inputs = tf.range(10.)[:, None]
labels = inputs * 5. + tf.range(5.)[None, :]
return tf.data.Dataset.from_tensor_slices(
dict(x=inputs, y=labels)).repeat().batch(2)
dataset = toy_dataset()
# 更新梯度步骤
def train_step(net, example, optimizer):
"""Trains `net` on `example` using `optimizer`."""
with tf.GradientTape() as tape:
output = net(example['x'])
loss = tf.reduce_mean(tf.abs(output - example['y']))
variables = net.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss
# 优化器
opt = tf.keras.optimizers.Adam(0.1)
# 迭代数据
iterator = iter(dataset)
# 设置检查点
ckpt = tf.train.Checkpoint(step=tf.Variable(1), optimizer=opt, net=net, iterator=iterator)
# 设置检查点管理
manager = tf.train.CheckpointManager(ckpt, './tf_ckpts', max_to_keep=3)
# 输入训练网络和检查点管理,开始训练
def train_and_checkpoint(net, manager):
ckpt.restore(manager.latest_checkpoint)
if manager.latest_checkpoint:
print("Restored from {}".format(manager.latest_checkpoint))
else:
print("Initializing from scratch.")
for _ in range(50):
example = next(iterator)
loss = train_step(net, example, opt)
ckpt.step.assign_add(1)
if int(ckpt.step) % 10 == 0:
save_path = manager.save()
print("Saved checkpoint for step {}: {}".format(int(ckpt.step), save_path))
print("loss {:1.2f}".format(loss.numpy()))
train_and_checkpoint(net, manager)import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
import numpy as np
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension
x_train = x_train[..., tf.newaxis].astype(np.float32)
x_test = x_test[..., tf.newaxis].astype(np.float32)
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(x_test.shape[0])
class MyModel(keras.Model):
# Set layers.
def __init__(self):
super(MyModel, self).__init__()
# Convolution Layer with 32 filters and a kernel size of 5.
self.conv1 = layers.Conv2D(32, kernel_size=5, activation=tf.nn.relu)
# Max Pooling (down-sampling) with kernel size of 2 and strides of 2.
self.maxpool1 = layers.MaxPool2D(2, strides=2)
# Convolution Layer with 64 filters and a kernel size of 3.
self.conv2 = layers.Conv2D(64, kernel_size=3, activation=tf.nn.relu)
# Max Pooling (down-sampling) with kernel size of 2 and strides of 2.
self.maxpool2 = layers.MaxPool2D(2, strides=2)
# Flatten the data to a 1-D vector for the fully connected layer.
self.flatten = layers.Flatten()
# Fully connected layer.
self.fc1 = layers.Dense(1024)
# Apply Dropout (if is_training is False, dropout is not applied).
self.dropout = layers.Dropout(rate=0.5)
# Output layer, class prediction.
self.out = layers.Dense(10)
# Set forward pass.
def call(self, x, is_training=False):
x = tf.reshape(x, [-1, 28, 28, 1])
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.dropout(x, training=is_training)
x = self.out(x)
if not is_training:
# tf cross entropy expect logits without softmax, so only
# apply softmax when not training.
x = tf.nn.softmax(x)
return x
model = MyModel()
loss_object = keras.losses.SparseCategoricalCrossentropy()
optimizer = keras.optimizers.Adam()
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
"""
# 保存模型参数
# 2.1 不限制 checkpoint 文件个数
EPOCHS = 5
checkpoint = tf.train.Checkpoint(myAwesomeModel=model)
for epoch in range(EPOCHS):
for images, labels in train_ds:
train_step(images, labels)
path = checkpoint.save('./save/model.ckpt')
print("model saved to %s" % path)
"""
# 2.2 限制 checkpoint 文件个数
EPOCHS = 5
checkpoint = tf.train.Checkpoint(myAwesomeModel=model)
manager = tf.train.CheckpointManager(checkpoint, directory='./save', max_to_keep=3)
for epoch in range(EPOCHS):
for batch,(images, labels) in enumerate(train_ds):
print(batch)
train_step(images, labels)
path = manager.save(checkpoint_number=epoch)
print("model saved to %s" % path)
# 加载模型参数并进行测试
model_to_be_restored = MyModel()
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save'))
for test_images, test_labels in test_ds:
y_pred = np.argmax(model_to_be_restored.predict(test_images), axis=-1)
print("test accuracy: %f" % (sum(tf.cast(y_pred == test_labels, tf.float32)) / x_test.shape[0]))
模型的存取
"""
保存模型方式一:
tf.keras提供了使用HDF5标准提供基本的保存格式
这种方法保存了以下内容:
1)模型权重值
2)模型结构
3)模型/优化器配置
"""
model. Save("./my_model.h5")
#将模型加载出来---可以直接进行预测
save_model = tf.keras.models.load_model("./my_model.h5")"""
保存模型方式二:
仅仅保存模型结构----这种方式要将模型结构保存成json格式,仅仅保存模型的结构,优化器、损失函数都未指定
"""
model_jsons = model.to_json()
#将该json文件写入到磁盘
with open("./model_structure.json","w") as my_writer:
my_writer.write(model_jsons)
#将以json文件保存的结构加载出来
with open("./model_structure.json","r") as my_reader:
model_structure = my_reader.read()
new_model_structure = tf.keras.models.model_from_json(model_structure)"""
保存方式三:
仅保存权重,有时我们只需要保存模型的状态(其权重值),而对模型架构不感兴趣。在这种情况下,
可以通过get_weights()获取权重值,并通过set_weights()设置权重值
"""
model_weights = model.get_weights()
#使用第二种模式只加载出模型的结构
new_model_structure2 = tf.keras.models.model_from_json(model_structure)
new_model_structure2.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#测试该模型的分数,即训练程度
new_model_structure2.set_weights(model_weights)
new_model_structure2.evaluate(test_images,test_labels)
"""
保存方式四:
在训练过程中,保存检查点,在训练期间或者训练结束的时候自动保存检查点。这样一来,在训练中断了后,
可以从该检查点继续向下训练。
使用的回调函数:tf.keras.callbacks.ModelCheckpoint()
"""
checkpoint_path = "./model.ckpt"
check_point_callback = tf.keras.callbacks.ModelCheckpoint(filepath = checkpoint_path,
save_weights_only = True)
#添加fit的callbacks中,这步切记不能忘,这样在训练的时候可以自动帮我们保存参数的检查点
model2.fit(dataset, epochs=5, steps_per_epoch=steps_per_epoch,callbacks=[check_point_callback])
"""
加载检查点,继续开始训练
"""
#加载检查点的权重
new_model_structure3.load_weights(checkpoint_path)
new_model_structure3.evaluate(test_images,test_labels)模型的检查点的保存和恢复
方式1 不限次次数保存
"""
保存模型方式五:
自定义训练保存模型
"""
"""
第一步:创建检查点保存路径
"""
cp_dir = "./custom_train_save"
cp_profix = os.path.join(cp_dir,"ckpt")
"""
第二步:创建模型检查点对象
"""
check_point = tf.train.Checkpoint(optimizer = optimizers,
model = model)
"""
第三步:在自定义训练函数中保存检查点
"""
if step % 2 == 0:
check_point.save(file_prefix = cp_profix)"""
第一步:提取最新的检查点
"""
latestnew_checkpoint = tf.train.latest_checkpoint(cp_dir)
"""
第二步:创建模型检查点对象
注意:这个optimizers与model属于新创建的,还没有加载参数.
"""
check_point = tf.train.Checkpoint(optimizer = optimizers,
model = model)
"""
第三步:开始恢复到最新检查点处
"""
check_point.restore(latestnew_checkpoint)方式2 通过checkpointManager
""
第一步:
创建检查点对象,并将模型(参数)、优化器等配置到检查点对象中
""
ckpt = tf.train.Checkpoint(step=tf.Variable(1), optimizer=opt, net=net, iterator=iterator)
""
第二步:
创建检查点管理器对象,它可以帮我们管理检查点对象
""
manager = tf.train.CheckpointManager(ckpt, './tf_ckpts', max_to_keep=3)
""
第三步:
在训练函数中,设置多少轮保存一下检查点,返回值为保存路径
""
save_path = manager.save()恢复
""
第一步:
创建优化器、模型对象
""
opt = tf.keras.optimizers.Adam(0.1)
net = Net()
""
第二步:
创建检查点、检查点管理器对象
""
ckpt = tf.train.Checkpoint(step=tf.Variable(1), optimizer=opt, net=net, iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, './tf_ckpts', max_to_keep=3)
""
第三步:
在训练前,恢复检查点
""
ckpt.restore(manager.latest_checkpoint)import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
import numpy as np
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension
x_train = x_train[..., tf.newaxis].astype(np.float32)
x_test = x_test[..., tf.newaxis].astype(np.float32)
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(x_test.shape[0])
class MyModel(keras.Model):
# Set layers.
def __init__(self):
super(MyModel, self).__init__()
# Convolution Layer with 32 filters and a kernel size of 5.
self.conv1 = layers.Conv2D(32, kernel_size=5, activation=tf.nn.relu)
# Max Pooling (down-sampling) with kernel size of 2 and strides of 2.
self.maxpool1 = layers.MaxPool2D(2, strides=2)
# Convolution Layer with 64 filters and a kernel size of 3.
self.conv2 = layers.Conv2D(64, kernel_size=3, activation=tf.nn.relu)
# Max Pooling (down-sampling) with kernel size of 2 and strides of 2.
self.maxpool2 = layers.MaxPool2D(2, strides=2)
# Flatten the data to a 1-D vector for the fully connected layer.
self.flatten = layers.Flatten()
# Fully connected layer.
self.fc1 = layers.Dense(1024)
# Apply Dropout (if is_training is False, dropout is not applied).
self.dropout = layers.Dropout(rate=0.5)
# Output layer, class prediction.
self.out = layers.Dense(10)
# Set forward pass.
def call(self, x, is_training=False):
x = tf.reshape(x, [-1, 28, 28, 1])
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.dropout(x, training=is_training)
x = self.out(x)
if not is_training:
# tf cross entropy expect logits without softmax, so only
# apply softmax when not training.
x = tf.nn.softmax(x)
return x
model = MyModel()
loss_object = keras.losses.SparseCategoricalCrossentropy()
optimizer = keras.optimizers.Adam()
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
"""
# 保存模型参数
# 2.1 不限制 checkpoint 文件个数
EPOCHS = 5
checkpoint = tf.train.Checkpoint(myAwesomeModel=model)
for epoch in range(EPOCHS):
for images, labels in train_ds:
train_step(images, labels)
path = checkpoint.save('./save/model.ckpt')
print("model saved to %s" % path)
"""
# 2.2 限制 checkpoint 文件个数
EPOCHS = 5
checkpoint = tf.train.Checkpoint(myAwesomeModel=model)
manager = tf.train.CheckpointManager(checkpoint, directory='./save', max_to_keep=3)
for epoch in range(EPOCHS):
for batch,(images, labels) in enumerate(train_ds):
print(batch)
train_step(images, labels)
path = manager.save(checkpoint_number=epoch)
print("model saved to %s" % path)
# 加载模型参数并进行测试
model_to_be_restored = MyModel()
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save'))
for test_images, test_labels in test_ds:
y_pred = np.argmax(model_to_be_restored.predict(test_images), axis=-1)
print("test accuracy: %f" % (sum(tf.cast(y_pred == test_labels, tf.float32)) / x_test.shape[0]))
参考文献:
TF2.0使用预训练网络与模型存取_tf_session = k.get_session() cmodel = vgg16(includ_我会像蜗牛一样努力的博客-CSDN博客
Tensorflow2.0之模型权值的保存与恢复(Checkpoint)_cofisher的博客-CSDN博客
TensorFlow 2.0 模型的保存和恢复_爱吃雪糕的鱼的博客-CSDN博客