1 基本概念
机器学习
机器学习是指一段程序或者和一个系统从输入数据中训练一个模型。完成训练的模型可以对全新的数据进行预测,其中,新数据的分布是与被训练数据的分布保持一致。
训练
一个确定组成模型的实际参数的过程,这些参数包括权重以及偏差。在训练的过程中,一个系统读取用于训练的数据样本并且逐渐地调整这些参数,在多次重复训练的过程中,不断地调整这些参数的准确度。
参数
在训练过程中,一个模型学习到的权重与偏差,例如,在线性回归模型(在后续章节中详细描述)中,参数是由偏差(b)以及所有权重(w1、w2…)组成,公式如下所示:
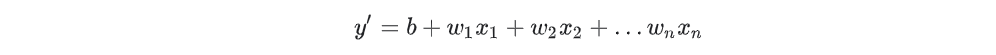
超级参数
由用户指定的一个常量,用于控制模型训练的可持续运行。例如,学习速率是一个超级参数,在一个训练会话开始之前可以设置为0.01,用户可以根据实际情况增加或者降低该值。
模型
通常情况下,模型是指一个数学结构,该数学结构接受输入的数据以及返回输出的数据,而在计算机领域,模型是指一个系统使用参数集以及结构对输入的数据作出预测与分析。例如,在监督型机器学习中,一个模型使用样本数据作为输入,从而推断一个预测作为输出,如下所示列举一些模型:
-
线性回归模型包括一个权重集以及一个偏差
-
一个神经网络,包括一个隐藏层集,每个隐藏层内包括一个或者多个神经元,而每个神经元都与一个权重集以及一个偏差相关
-
一个决策树,由一个树形的结构组成,叶子节点与条件节点相互连接,根据输入的条件做出合适的决策
从软件工程的角度看,模型可保存、可重用、可分发。
非监督型机器学习也产生模型,其模型一般对应一个函数,该函数使用输入的数据样本进行聚簇处理。
一个代数函数的模型如下所示:

如上所示,代数模型输入一个元组(x,y),计算一个输出。
同样,一个程序的函数也是一个模型,如下所示:

如上所示,调用者输入二元组(x,y)作为参数,函数计算一个输出。
虽然,一个深度神经网络模型与代数模型或者程序的函数模型是一个不同的数学结构,但是,深度神经网络模型也是接受输入,然后计算输出。其最大的不同是,深度神经网络使用机器学习的模式调整参逐渐数以达到更加准确的输出。
分类模型
一个用于预测分类的模型,如下所示是分类模型:
|
相对而言,回归模型(在后续章节中描述)是用于预测数值而不是分类。
两种常用的分类模型是:二元分类以及多元分类。
2 文本分类与情感分析
本章节主要从代码的角度以及文本数据的角度描述情感分析的处理过程,使用最新的TF技术框架(keras)对IMDB数据集执行二元分类的训练。
获取数据集

如上所示,首先,导入python的库文件,其中,包括图形库、系统读取文件库、字符串工具集、tensorflow技术框架库以及keras技术框架库。


如上所示,其中,url提供IMDB数据集的下载地址,该数据集包括观众对电影的观后感,观众对电影的正面以及负面的评价,因此,正面评价以及负面评价形成了情感分析的二元分类。dataset是根据url下载的数据集,dataset_dir是获取到的数据目录。


如上所示,listdir显示数据集所在目录的文件以及子目录列表。


如上所示,文件夹aclImdb/train/pos表示电影的正面评价,文件夹aclImdb/train/neg表示电影的负面评价。
加载数据集
使用keras技术框架的工具集text_dataset_from_directory加载数据集,然后转换成机器学习能识别的合适格式,该工具集方法参数需要的目录结构如下所示:

如上所示,目录结构格式包括两个子目录:class_a以及class_b,每个目录对应二元分类中一个分类的数据集,每个分类数据集内包括数据样本的原文,该格式对应aclImdb数据集的目录结构的aclImdb/train/pos(正面评价)以及aclImdb/train/neg(负面评价)。
如前面所述,监督型机器学习的数据集包括两个部分,训练数据样本集以及每个数据样本对应的标签数据集,因此,aclImdb数据集对应的数据样本是train子目录,而数据样本对应的标签是labeledBow.feat文件。按照机器机器学习的训练过程,需要提供三个阶段的数据样本,其中包括训练数据集、验证数据集、测试数据集,而验证数据集是从训练数据集中以2比8的比例获取,测试数据集在aclImdb/test子目录中,数据分割的代码如下所示:
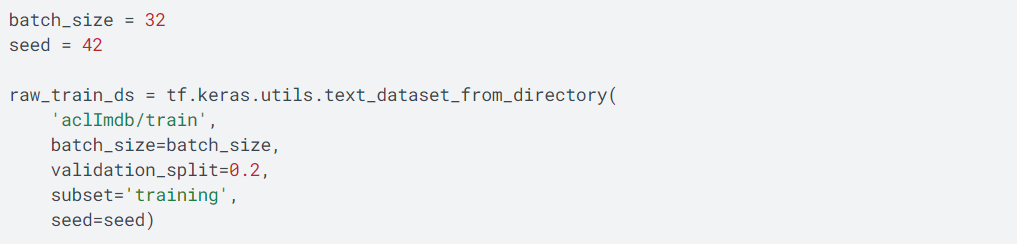

如上所示,在训练数据集中提供了25k的数据样本,提取其中的80%作为训练数据集(20k),剩余的20%数据集用于验证数据集(5k),根据之前的实验证明,top-20k的数据样本训练集是最适合的数据量。


如上所示,加载样本数据集完成,对应raw_train_ds,其中,Review表示电影评价原文,Label表示原文对应的情感分析的类别标签。


如上所示,显示raw_train_ds数据集的类别标签,标签0对应负面评价,标签1对应正面评价。


如上所示,从aclImdb原始数据集中创建验证数据集,该数据集用于机器学习的验证阶段。


如上所示,从aclImdb原始数据集中创建测试数据集,该数据集用于机器学习测试阶段。
训练数据集
Keras(tf.keras.layers.TextVectorization)技术框架支持对数据集进行原文规范化、对原文分词、原文向量化。其中,原文规范化是对原文的预处理,删除原文中的一些特殊符号或者标签(例如,HTML中的分行标签),其目的是简化原文。对原文分词是将规范化的原文按照空格间隔分割成单词集合。原文向量化是将原文分词所得的单词集合转换成神经网络能识别的数值。

如上所示,该函数提供原文规范化的功能,首先转换成小写字母、将HTML标签替换成空格、将标点符号替换成空格。

如上所示,以序列模型创建一个向量化的层,其中,max_features是最大的特征数,也就是单词词汇总数,sequence_length是根据词汇集索引化原文的最大序列长度,原文的单词数大于sequence_length长度的序列则丢弃。

如上所示,从训练数据集中获取原文集,然后,使用以上定义的向量化层对其进行序列向量化。


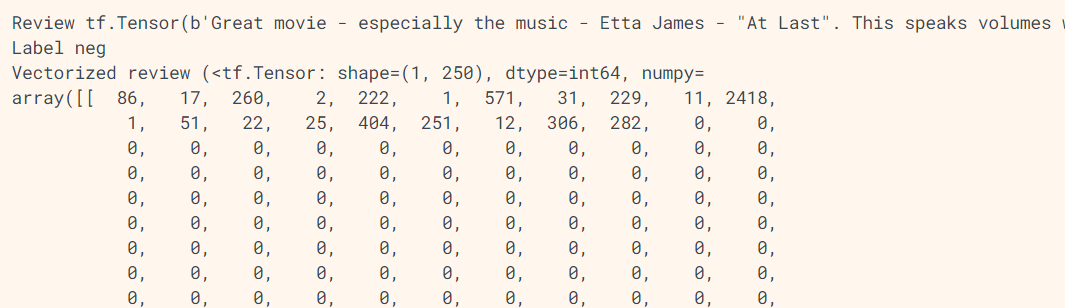
如上所示,自定义单元测试函数显示第一个原文的序列化向量集以及第一个原文对应的标签,其中,序列向量集的长度等于sequence_length。


如上所示,使用向量化层输出序列索引对应的单词,其中,单词词汇集的总数是10000。

如上所示,使用向量化文本函数分别对训练数据集、验证数据集、测试数据集执行序列向量化,后续使用这些序列化向量集进行机器学习。
(未完待续)
![[附源码]Python计算机毕业设计Django小区物业管理系统](https://img-blog.csdnimg.cn/f805482647e846f8a7db67844265303e.png)

![[附源码]JAVA毕业设计仁爱公益网站(系统+LW)](https://img-blog.csdnimg.cn/94967b8d072a48b7979ede031dc45b6e.png)

![[附源码]Python计算机毕业设计Django校园快递柜存取件系统](https://img-blog.csdnimg.cn/e674792252ab4dc0adfe4ca12adc8f83.png)