前言
好久不见了各位!最近几个月都未更新,是因为从春招开始就在投简历面试实习岗位,然后入职,最后成功成为了一个半成品后端练习生,想说的话有太多太多
下面就站在一个在校实习生的身份,结合自己最近几个月来在企业开发环境中写代码的经历,与即将上岗,或者还在期待上岗的小伙伴们来分享分享——企业级项目与网络自学项目究竟有什么区别

公司主流技术栈:
SpringBoot+Dubbo+Flink+Kalfk+MyBatisPlus+Mysql+Redis+Seata+MongoDB+ES+React+区块链+人工智能
1.复杂的业务逻辑
在生产与开发环境之间往往还有一个qa环境(质量保障),当进入公司的第一天,连上了qa环境的数据库,给我的第一感受就是:“卧槽,这表里的字段也太多了吧“
繁多的字段对应的则是复杂的业务逻辑,实体类也不再具有单一属性,更多的则是不同的实体相互组合,返回多方作用的结果:
对于某些业务场景MybatisPlus的Wrapper存在一定的局限性,需要我们自己手动封装查表的方法。比如查询要使用稀奇古怪的函数、多表查询,连接查询,子查询等等…
现在我就来举两个我在开发过程中写出的两个Mapper来给大家看看,开开胃:
1.各种函数的灵活使用:
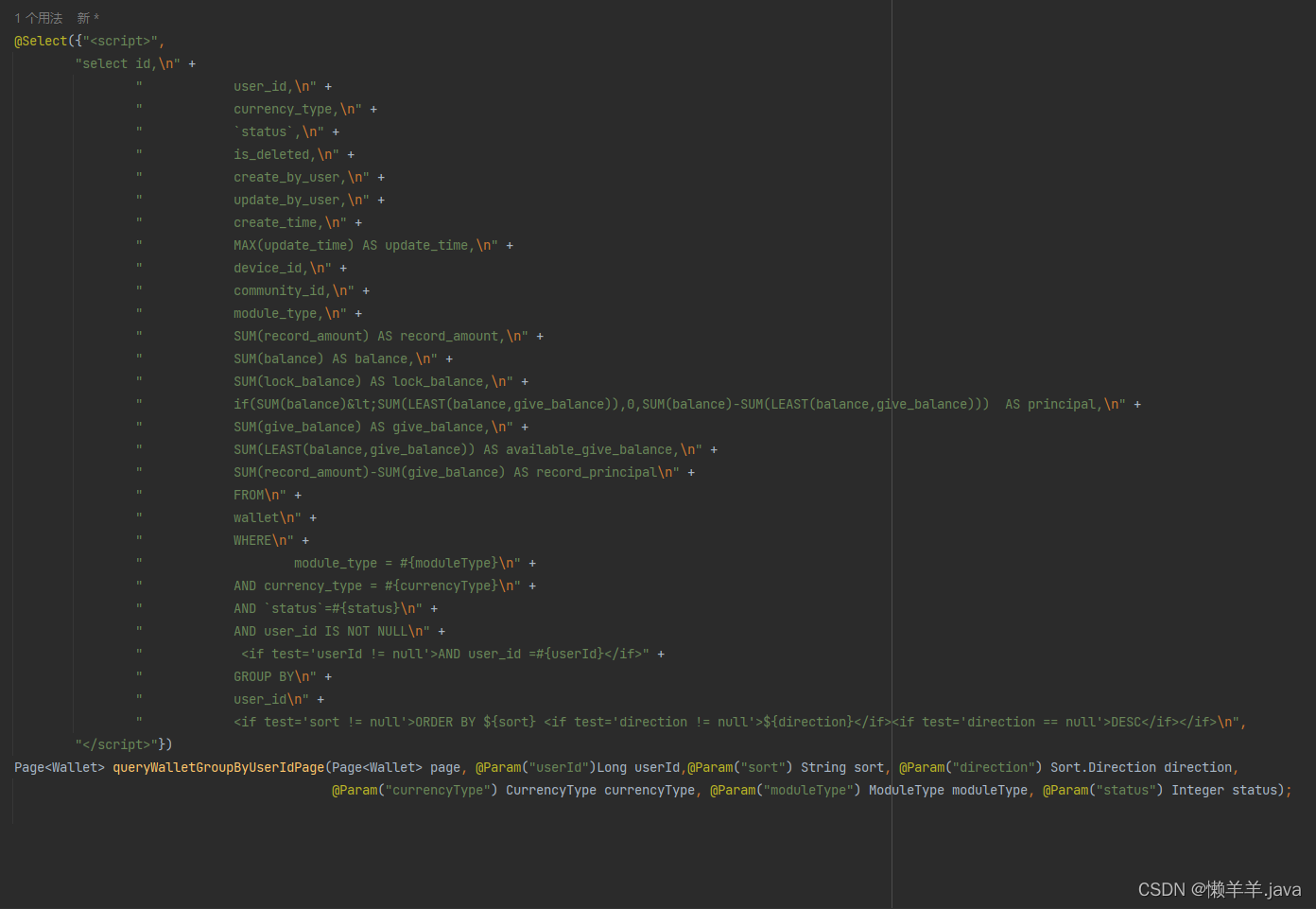
2.复杂的条件判断:
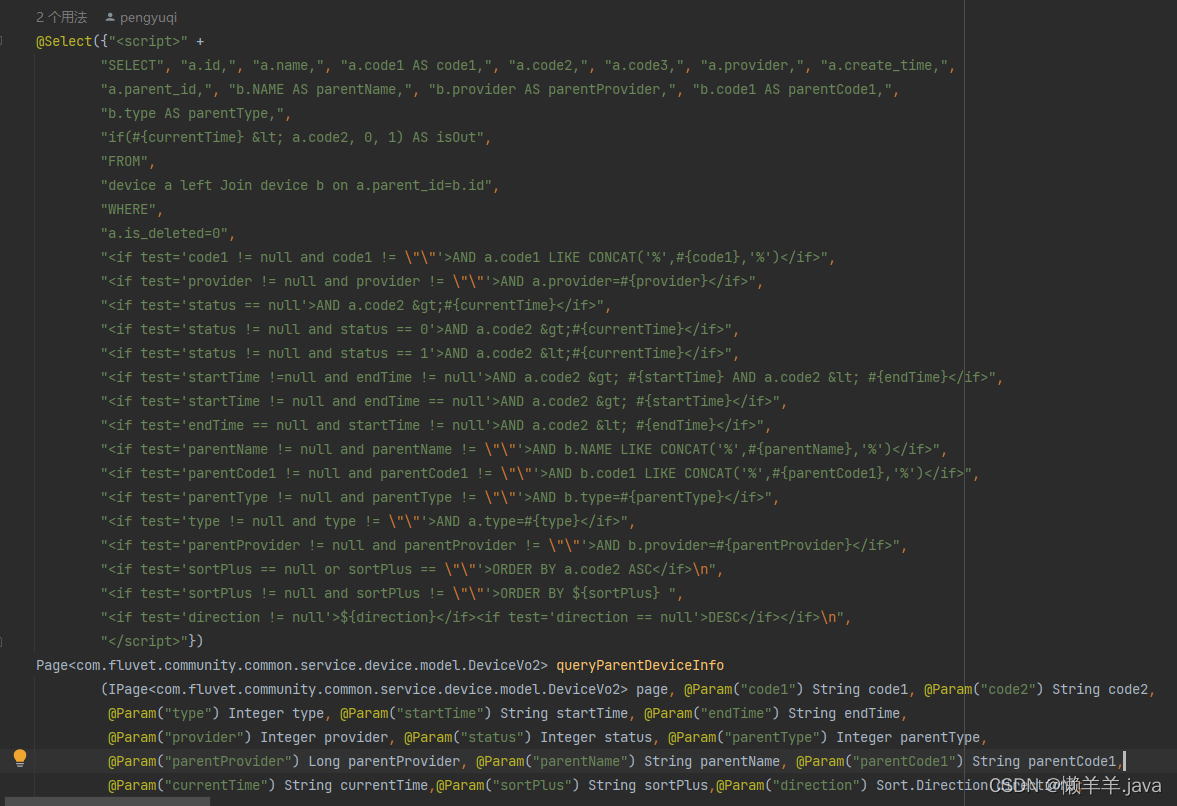
2.严格的参数校验
对于特殊数据的格式企业都会有统一的要求,因此在前端控制器(Controller)里要对接收到的参数做相应的参数校验
1.时间类型参数的校验

2.手机号类型参数的校验
有人会问手机号这种数据前端不是会帮我们校验吗?为什么后端还要重复工作,其实这是因为我们要保证测试用例的成功执行,避免在使用PostMan等接口测试工具的情况下拿到token之后从而绕开了前端,将不正确的数据请求到后端服务器

3.分页参数的校验
分页的大小也要控制在合理的范围,分页数过大,或者不合常理都会导致出人意外的错误。比如传递一个超大的pageSize参数,并且库中的数据量很大的情况下,会导致一次请求查出海量数据。往复几次会占用大量的服务器带宽,最终让服务器挂掉~

3.生产环境对接口性能要求
1.循环查库使不得
举一个大家耳熟能详的例子——瑞吉外卖,这应该能算得上是自学项目的代表吧,我们来看一下其中一个接口的写法:
@GetMapping("/page")
public R<Page> page(int page, int pageSize, String name) {
log.info("查询的名称是:{}", name);
//分页构造器
Page<Dish> dishPage = new Page<>(page, pageSize);
Page<DishDto> dishDtoPage = new Page<>();
//条件构造器
LambdaQueryWrapper<Dish> dishLqw = new LambdaQueryWrapper<>();
//模糊查询,将前端输入的名字和Dish表中的name进行模糊查询并添加name不为空的条件
dishLqw.like(name != null, Dish::getName, name);
dishLqw.orderByDesc(Dish::getUpdateTime);
//调用Service查询
dishService.page(dishPage, dishLqw);
BeanUtils.copyProperties(dishPage, dishDtoPage, "records");
List<Dish> records = dishPage.getRecords();
List<DishDto> dtoList = records.stream().map((temp) ->{
DishDto dishDto = new DishDto();
//再次拷贝,将普通属性拷贝给dishDto
BeanUtils.copyProperties(temp, dishDto);
Long categoryId = temp.getCategoryId(); //拿到分类id
// 拿到分类对象,根据id查到对象
Category category = categoryService.getById(categoryId);
if(category!=null) { //避免出现空指针
//通过分类对象拿到name
String categoryName = category.getName();
//把name设置给dishDto
dishDto.setCategoryName(categoryName);//设置dishDto中CategoryName的值
}
return dishDto;
}).collect(Collectors.toList());
dishDtoPage.setRecords(dtoList);
return R.success(dishDtoPage);
}
细心的同学肯定会发现,在我们的流里针对每一次流中的元素都进行了一次查库的操作(i/o)。
Category category = categoryService.getById(categoryId);
在数据量非常小的情况下可能接口性能不会有什么影响,但流中数据如果很大,那这样的接口耗时肯定是非常长的,绝对是不会上生产环境的。这就是企业与自学最大的区别体现之一。
所以,为了避免这样的情况发生,我们会尽量减少查库的频率,就类似下面这样的写法(非常相似的场景,也是我入职的第一个接口):
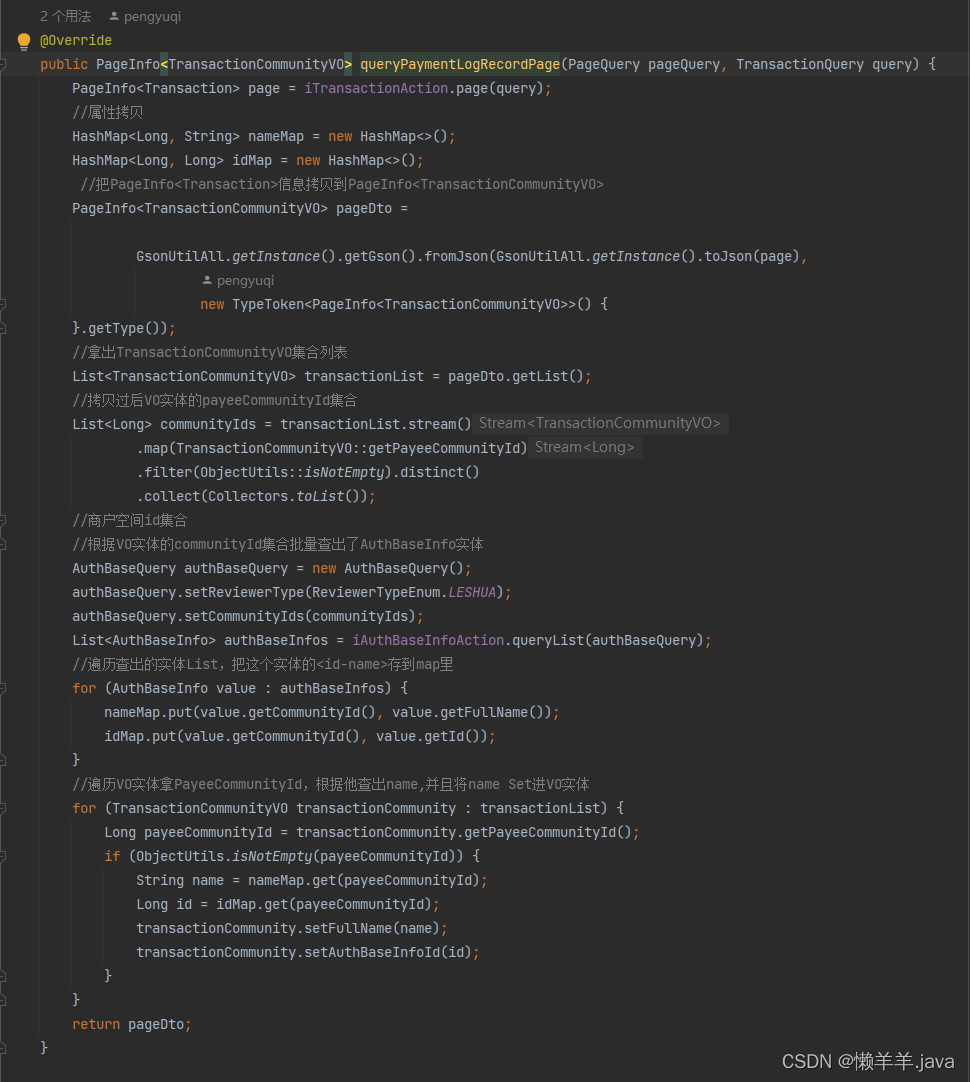
总而言之就一句话:能一次全部查出来尽量不要一次一次查
以后大家要是看到接口里存在循环交互数据库的地方,那这接口八成是个毒瘤
2.多线程异步处理
其实有一些场景对同步性的要求并非很强,同步处理反而会增加很多无效的等待时间。对于一些"不需要等待结果返回的地方"大胆可以进行异步处理。
举一个例子,现在的任务是根据一批未缴费的账单向业主一键推送消息,每当推送完成要更新提醒状态。而更新和推送都有很多前置数据要去准备,并且推送业务的调用链很长。如果是单线程的情况方法从上到下执行接口,耗时大概是5-6s,没有异步调用的机制在推送的时间内方法的调用者什么都做不了, 其他代码都按下了暂停键。但是当我使用线程池异步去一键推送消息,并更新状态就会减少大量的等待时间,接口的耗时也降低到了一秒以内!
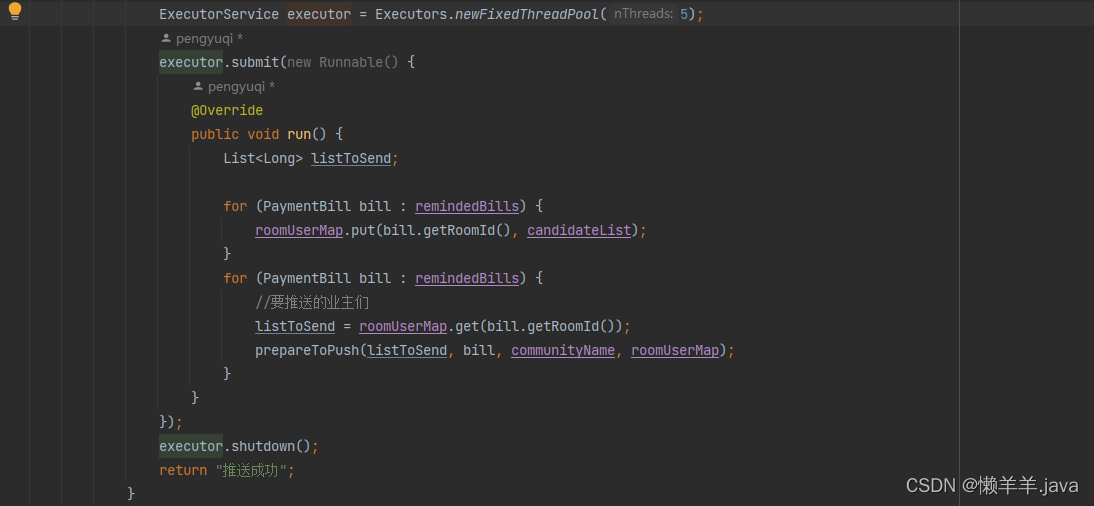
由此可见,对于一些特殊的场景,采用异步还是同步的方式真的非常重要。而多线程只是人让我们实现异步的一种手段之一
4.编码规范
4.1流式编程
以单个微服务为单位分库的特性导致了很多强相关联的数据不在一个数据库里,这样我们就失去了很多的多表联查机会。
相反,更多则是处理、、组装多个来自不同微服务接口的数据,而这个过程中就会不禁用到流式编程。
学会并且习惯使用流式编程真的可以让自己开发的如鱼得水,流式写法+Lambda表达式我愿称之为绝杀,不仅可以简化业务代码更让让开发者的思路更加清晰
下面我就举几个我入职后用到流式开发、lambda表达式的几个场景:
1.过滤去重List
List<Long> communityIds = transactionList.stream()
.map(TransactionCommunityVO::getPayeeCommunityId)
.filter(ObjectUtils::isNotEmpty).distinct()
.collect(Collectors.toList());
2.MyBatisPlus使用lambda表达式来进行“选择模糊组合查询”
LambdaQueryChainWrapper<Device> deviceLambdaQueryChainWrapper = iDeviceService.lambdaQuery();
if (ObjectUtils.isNotEmpty(deviceQuery2.getFuzz())) {
deviceLambdaQueryChainWrapper.and(x -> {
x.like(Device::getName, deviceQuery2.getFuzz()).or().like(Device::getCode1, deviceQuery2.getFuzz());
});
}
3.通过分组的方法对List中“某字段的值和该字段出现的次数”以 < k-v > map的方式进行收集
Map<Long, Long> idCountMap = deviceVo2s.stream()
.filter(index -> ObjectUtils.isNotEmpty(index.getOwnerId()))
.collect(Collectors.groupingBy(DeviceVo2::getOwnerId, Collectors.counting()));
4.流里处理字符串
list= list.stream().map(x -> {
String[] strings = new String[x.length];
for (int i = 0; i < x.length; i++) {
if (null == x[i]) {
x[i] = "";
}
strings[i] = x[i].trim();
}
return strings;
}).collect(Collectors.toList());
5.流里收集指定条件的数据
Map<String, String> map2 = list4.stream().filter(temp -> "男".equals(temp.split("-")[1]))
.collect(Collectors.toMap(
temp -> temp.split("-")[0]
,
temp -> temp.split("-")[2]));
4.2复用性要求
一个好的接口不仅仅局限于现有的功能,更多的是要做到向上兼容。复用性的高低很大程度上决定了业务代码的篇幅。在业务开发中经常会看到底层的一个接口左上角显示“xxx次用法”而这样的接口就拥有会很高的复用性。
对于如何个提升代码复用性,这里,举两个我感触很深的地方。
1.减少不必要的参数传递:
有大量参数需要传递的方法,通常很难阅读。我们可以将所有参数封装到一个对象中来完成对象的传递,要用到时直接get就好,这也有利于错误跟踪。许多开发因为太多层的对象包装对系统效率有影响。但是,和它带来的好处相比,我们宁愿做包装。毕竟,"封装"也是OOP的基本特性之一,而且,“每个对象完成尽量少(而且简单)的功能”,也是OOP的一个基本原则。
2.尽可能地去解耦:
"将可变的部分和不可变的部分分离"是面向对象设计的第三个原则。如果使用继承的复用技术,我们可以在抽象基类中定义好不可变的部分,而由其子类去具体实现可变的部分,不可变的部分不需要重复定义,而且便于维护。如果使用对象组合的复用技术,我们可以定义好不可变的部分,而可变的部分可以由不同的组件实现,根据需要,在运行时动态配置。这样,我们就有更多的时间关注可变的部分。对于对象组合技术而言,每个组件只完成相对较小的功能,相互之间耦合比较松散,复用率较高,通过组合,就能获得新的功能。
3.底层方法少写固定条件:
特别是在Mapper或者Wapper方法里,尽可能地去少写不必要的定值查询条件,比如限定状态,类型等方面,留出一个可更改的传递参数去向上兼容。
4.3枚举类的使用
一年前刚学习到枚举时,别人问我,你怎么看待枚举这个类。我说他就是一个定义规范的类

现在到了企业开发中,这一点表现得更加明显。很多时候,数据库里的一些字段往往都会有很多值。比如,表里的status这一字段,它的值可能是0,1,2或者3…不同的值代表这条数据不同的状态。
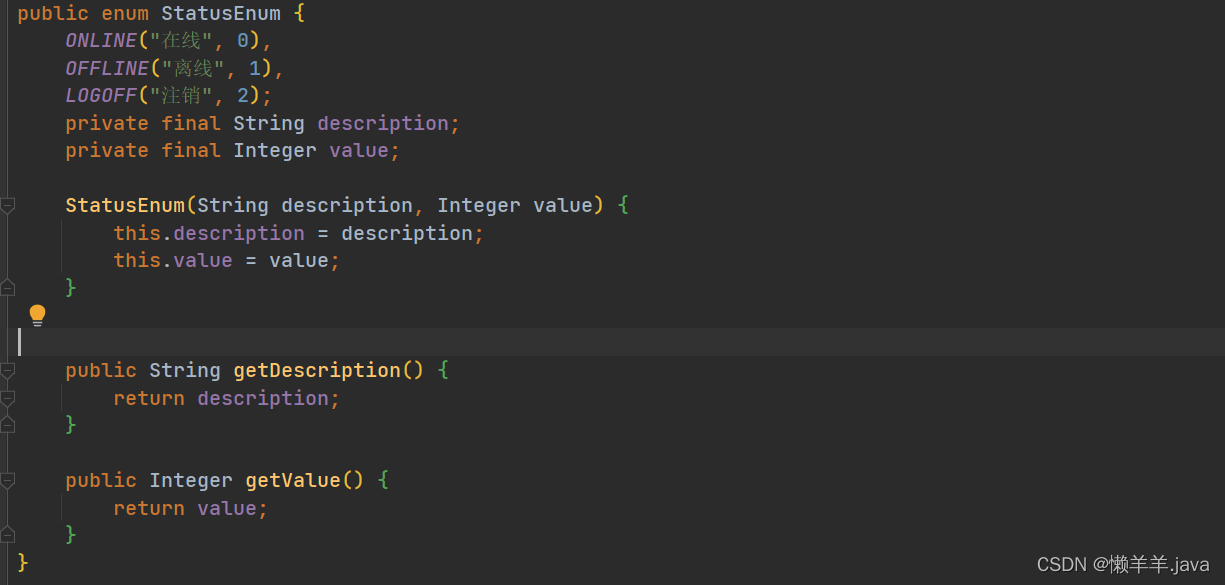
在数据处理的过程中,遇到对状态的限定就不要再去用xxx=0,xxx=2…取而代之的是xxx=StatusEnum.ONLINE.getValue()这样做不仅更加直观让别的开发一看就明白,而且还做到了某种意义上的解耦!
把公用的放在一个地方,这种场景是不是很像配置文件。想当初IOC就是靠的一手DOM4J和XML
4.4查询类的使用
企业级的项目往往需求十分复杂,就比如一个查询的接口可能要接收很多的参数,这些字段参数从Controller层下来,逐层向下传递可能就会导致一个不好的现象——实现方法接收的形参太多!
就像这样:
PageInfo<Device> getDeviceList(Integer current, Integer size, List<Long> ownerIds, List<DeviceTypeEnum> typeList,
String code1, String code2, List<Integer> providerList, List<IsDeletedType> isDeletedList, List<Long> communityIdList,
String nameLike, List<Long> physicalCommunityIdList, List<Integer> statusList, List<Long> parentIdList, List<Long>
idList, List<String> areaPathList, List<String> sortList, Sort.Direction direction, List<String> communityPathList,
List<DeviceSubTypeEnum> deviceSubTypeEnumList, String code1Like, String code2Like);
这形参是不是老长了~这样的写法看起来“中规中矩”,但是调用起来特别费眼睛,一个参数传错位置就得调试半天!

所以,为了解决这样的问题,我们使用查询类来进行查询(查询类就是把属性字段放到实体类里封装好,并通过set、get方法来操作属性),会使接口方法看起来简洁很多,并且大大降低了出错的概率,就像这样:

4.5RestFul风格
以前在自学SpringMVC时就讲到RestFul风格的应用,当时没接触到企业级项目觉得这种风格的东西无关紧要,但其实不然,接口遵循这样的风格规范十分重要!
客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。在企业级应用中往往一个模块有好几十个Controller,当你去其中浏览,你会发现在仅看了请求方式(post/get/delete/update)和请求路径之后就会了解到这个Controller方法的大致功能。RestFul风格无疑是一种优良的开发规范!
4.6注释
Last but not least!
切记写代码要记得写注释,所谓注释绝对不是写什么注释什么,而对关键地方进行的一种声明。
比如:
1.接口的具体功能的说明
2.形参传递的说明
3.返回值的类型以及内容的说明
4.实体类中属性字段的说明
5.共性字段特殊使用的说明




![[易语言][部署]使用易语言部署paddleocr的onnx模型api接口推理直接调用](https://i1.hdslb.com/bfs/archive/e37a5562f478e7b699888069f72b2191694ede8e.jpg@100w_100h_1c.png@57w_57h_1c.png)