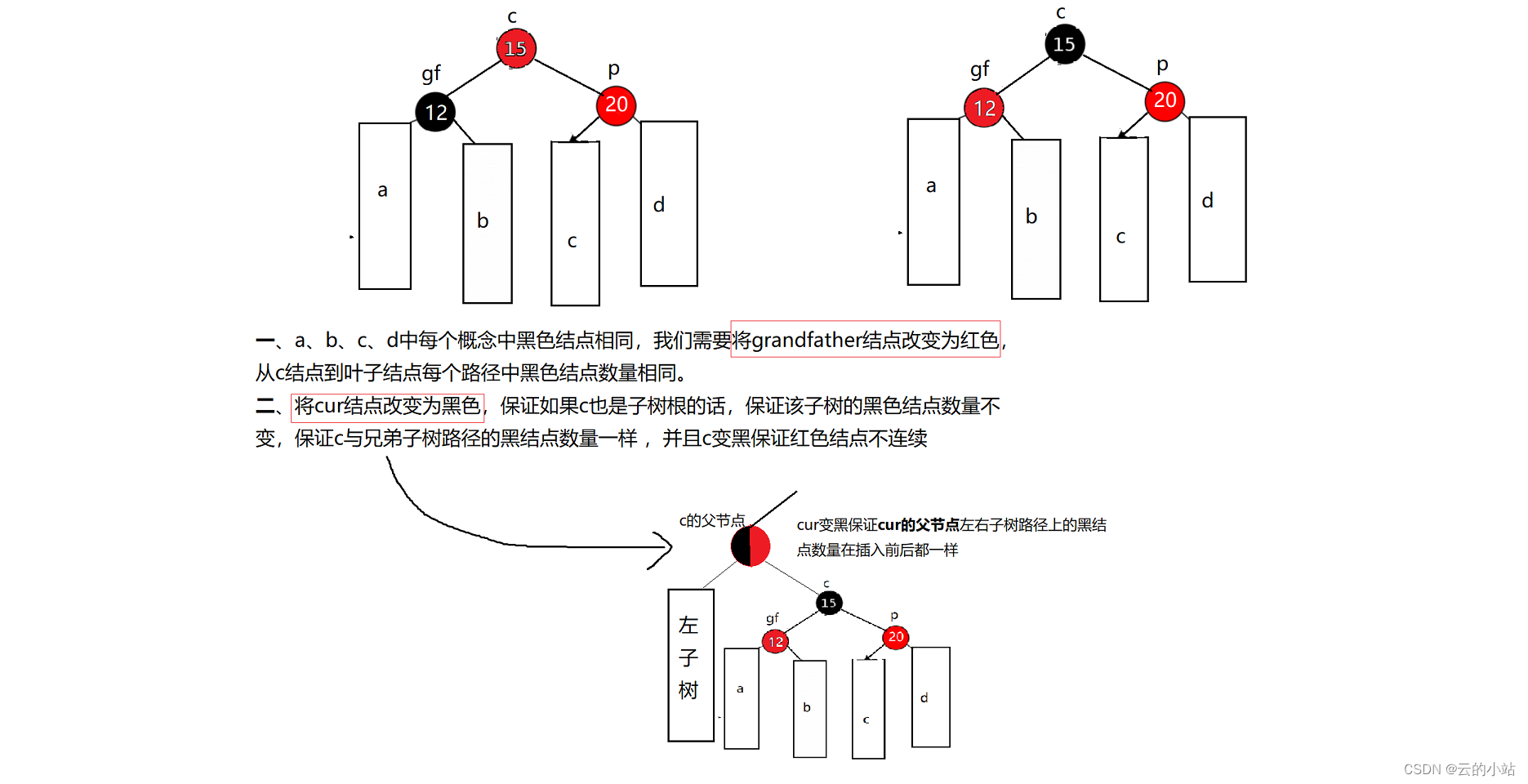
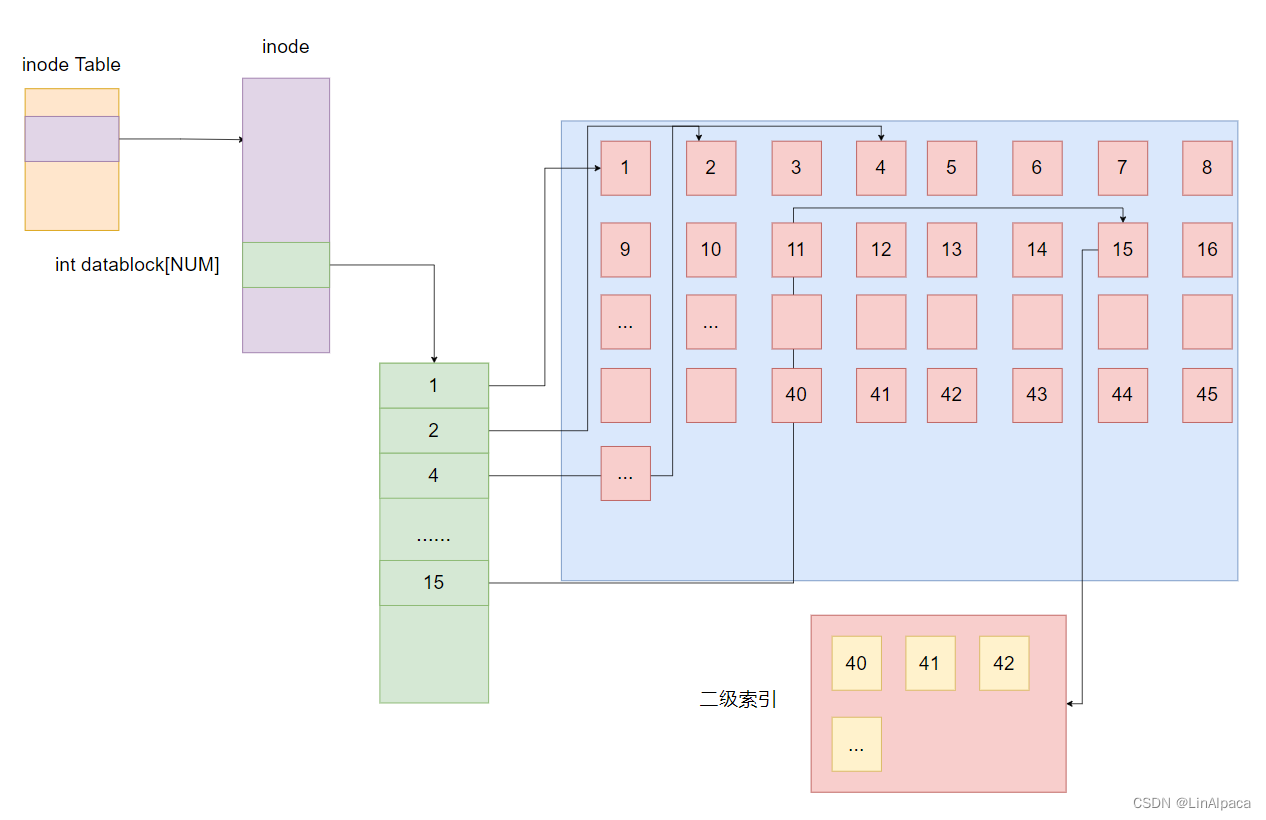
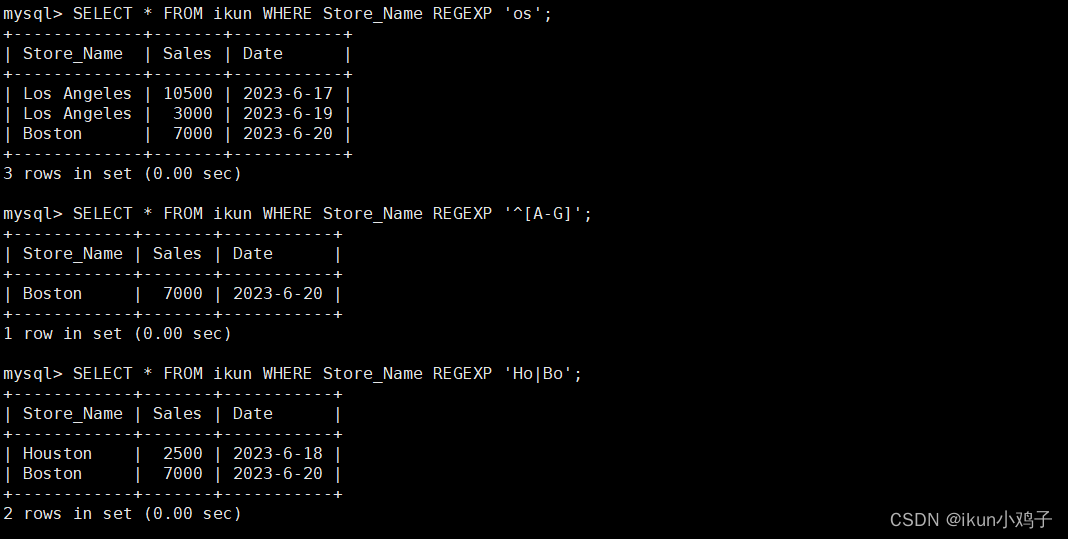
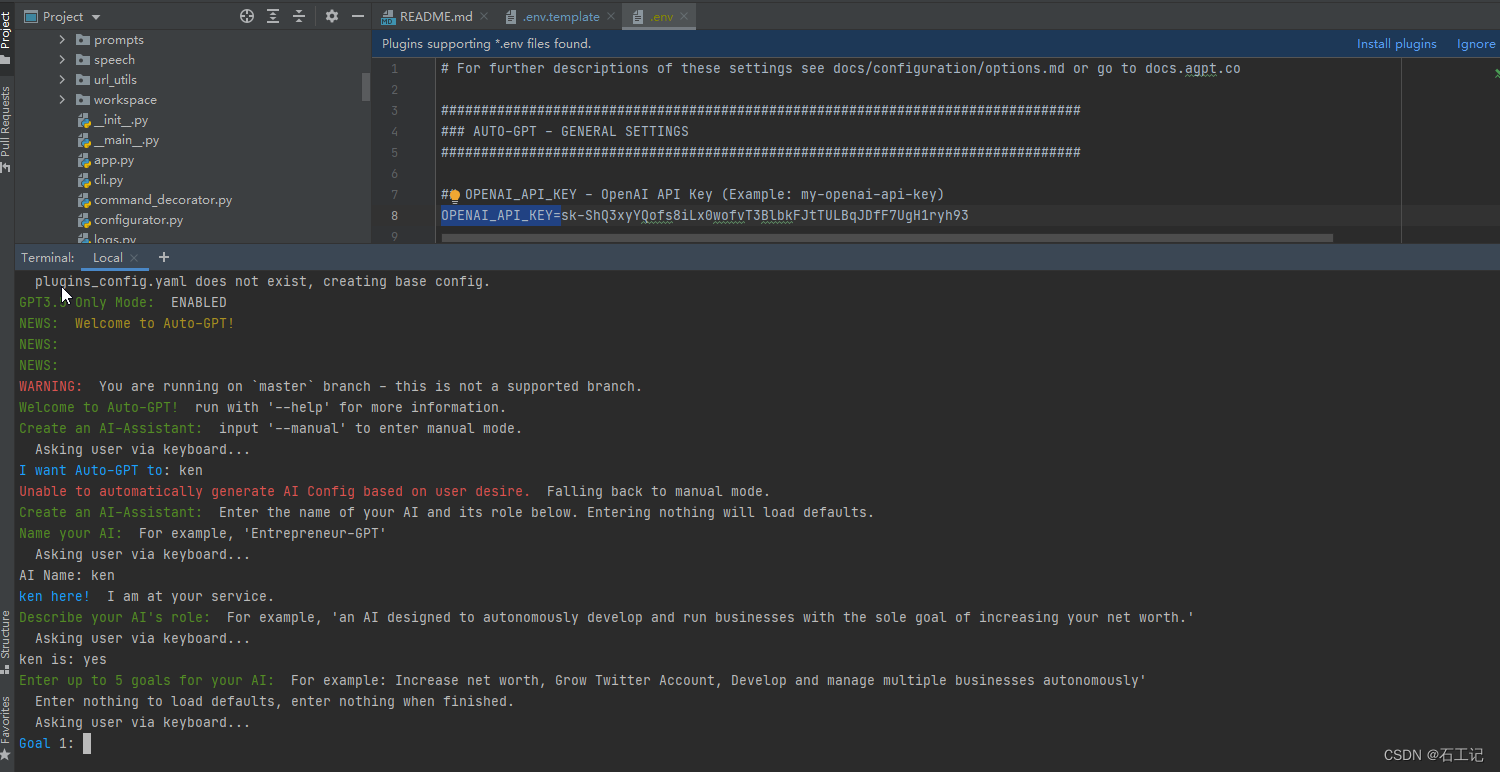
目录
1. C语言命名冲突
2. 命名空间定义
3. 命名空间使用
- 可能大家在看别人写的C++代码中,在一开始会包这个头文件:#include<iostream>
这个头文件等价于我们在C语言学习到的#include<stdio.h>,它是用来跟我们的控制台输入和输出的,这里简要提下,后续详谈。
- 除了上面这个头文件,还有这样一行代码:using namespace std;
namespace就是我们要接触C++的第一个关键字,它就是命名空间。
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
1. C语言命名冲突
在正式引入namespace前,再来回顾下C语言的命名冲突问题:
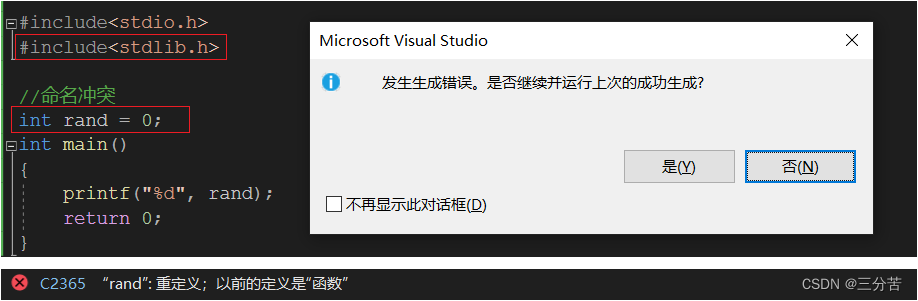
#include<stdio.h> //命名冲突 int rand = 0; int main() { printf("%d", rand); return 0; }如上的代码中,头文件我们只用了intclude<stdio.h>,暂无其它。我们定义了全局变量rand,并且代码可以正常编译没有任何错误。
但是要知道C语言存在一个库函数正是rand,但是要包上头文件#include<stdlib.h>,包上了这个头文件,再运行试试:
这里很明显发生命名冲突了,我们定义的全局变量rand和库里的rand函数冲突
想要解决此问题也非常简单,可能有人会说我修改变量名就可以了,确实可以,但并不是长久之计,如若我在不知情的状态下使用该变量超过100次,难道你要一个一个修改吗,这就充分体现了C语言的命名冲突。
在C++中,引入的命名空间namespace就很好解决了C语言的命名冲突问题。
2. 命名空间定义
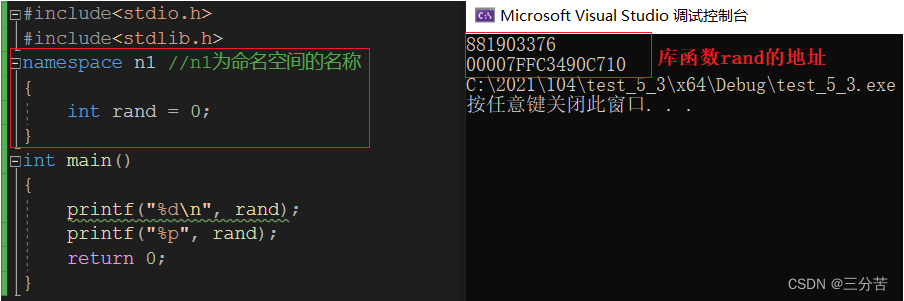
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{ }即可,{}中即为命名空间的成员。
如下:
同一个作用域不能出现两个相同变量,此时的rand被关在n1的命名空间域里了,跟其它东西进行了隔离。所以在stdlib.h头文件展开时并不会发生命名冲突。此时rand的打印均是库函数里rand的地址,rand就是一个函数指针,打印的就是地址。
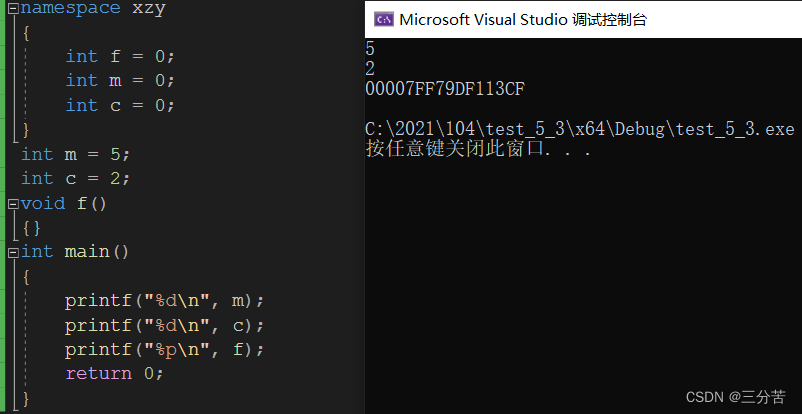
再比如:
此段代码更充分的体现了加上命名空间,不仅可以避免命名冲突,而且还告诉我们,此时再访问变量m、c、f,均是在全局域里访问的,而xzy这个命名空间域里的变量与全局域建立了一道围墙,互不干扰。不过这里c和m依旧是全局变量,命名空间不影响生命周期。
命名空间有三大特性:
- 1、命名空间可以定义变量,函数,类型
//1. 普通的命名空间 namespace N1 // N1为命名空间的名称 { // 命名空间中的内容,既可以定义变量,也可以定义函数,也可以定义类型 int a; //变量 int Add(int left, int right) //函数 { return left + right; } struct ListNode //类型 { int val; struct ListNode* next; } }
- 2、命名空间可以嵌套
//2. 命名空间可以嵌套 namespace N2 { int a; int b; int Add(int left, int right) { return left + right; } namespace N3 { int c; int d; int Sub(int left, int right) { return left - right; } } }
- 3、同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中
//3. 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。 namespace N1 { int Mul(int left, int right) { return left * right; } }
3. 命名空间使用
我们都清楚在C语言中,存在局部优先规则,如下:
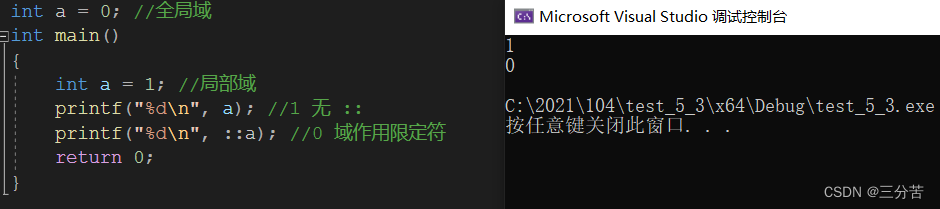
int a = 0; //全局域 int main() { int a = 1; //局部域 printf("%d\n", a); // 1 局部优先 return 0; }我们都清楚这里的结果是1,但是如若我非要打印全局域里的a呢?
这里引出域作用限定符 ( :: ),效果如下:
加上了( :: ) ,此时访问的a,就是全局域,这里是全局域的原因是“ ::”的前面是空白,如若是空白,那么访问的就是全局域,这么看的话,我在“ ::”前面换成命名空间域,不就可以访问命名空间域里的内容了吗。其实“ ::”就是命名空间使用的一种方式。
比如我们定义了如下的命名空间:
namespace n1 { int f = 0; int rand = 0; }现在该如何访问命名空间域里的内容呢?其实有3种方法:
- 加命名空间名称及作用域限定符“ ::”;
- 使用using namespace 命名空间名称全部展开;
- 使用using将命名空间中成员部分展开。
- 1、加命名空间及作用域限定符“ ::”
int main() { printf("%d\n", n1::f); //0 printf("%d\n", n1::rand);//0 return 0; }为了防止定义相同的变量或类型,我们可以定义多个命名空间来避免。
namespace ret { struct ListNode { int val; struct ListNode* next; }; } namespace tmp { struct ListNode { int val; struct ListNode* next; }; struct QueueNode { int val; struct QueueNode* next; }; }当我们要使用它们时,如下:
int main() { struct ret::ListNode* n1 = NULL; struct tmp::ListNode* n2 = NULL; return 0; }针对命名空间的嵌套,如下:
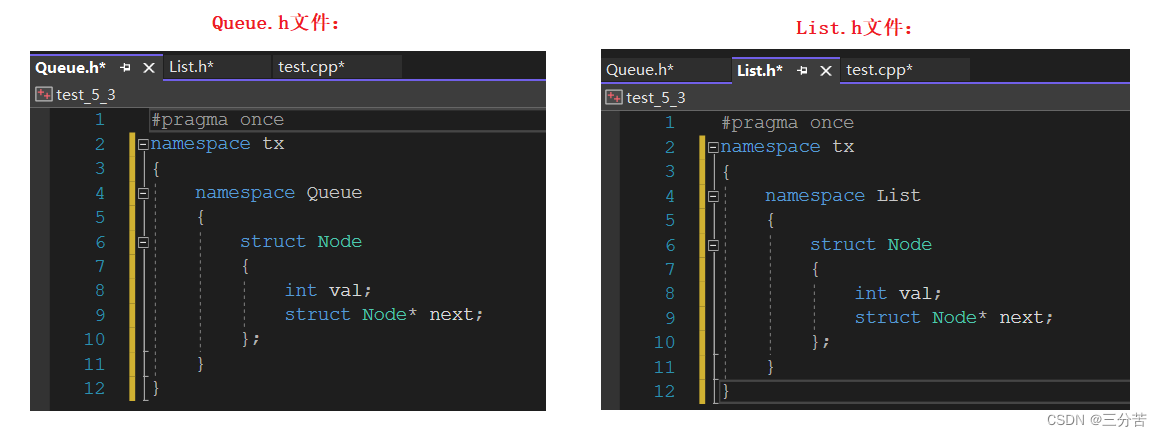
可以这样进行访问:
int main() { struct tx::List::Node* n1; //访问List.h文件中的Node struct tx::Queue::Node* n2;//访问Queue.h文件中的Node }但是上述访问的方式有点过于麻烦,可不可以省略些重复的呢?比如不写tx::,这里就引出命名空间访问的第二种方法:
- 2、使用using namespace 命名空间名称全部展开
using namespace tx;这句话的意思是把tx这个命名空间定义的东西放出来,所以我们就可这样访问:
int main() { struct List::Node* n1; //访问List.h文件中的Node struct Queue::Node* n2;//访问Queue.h文件中的Node }当然,我还可以再拆一层,如下:
using namespace tx; using namespace List; int main() { struct Node* n1; //访问List.h文件中的Node struct Queue::Node* n2;//访问Queue.h文件中的Node }展开时要注意tx和List的顺序不能颠倒
这种访问方式是可以达到简化效果,但是也会存在一定风险:命名空间全部释放又重新回到命名冲突。
所以针对某些特定会出现命名冲突问题的,需要单独讨论:
由此我们得知:全部展开并不好,我们需要按需索取,用什么展开什么,由此引出第三种使用方法。
- 3、使用using将命名空间中成员展开
针对上述代码,我们只放f出来:
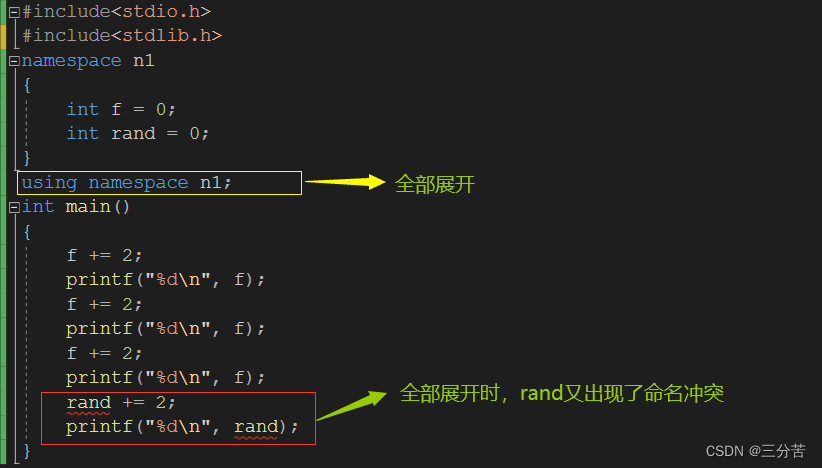
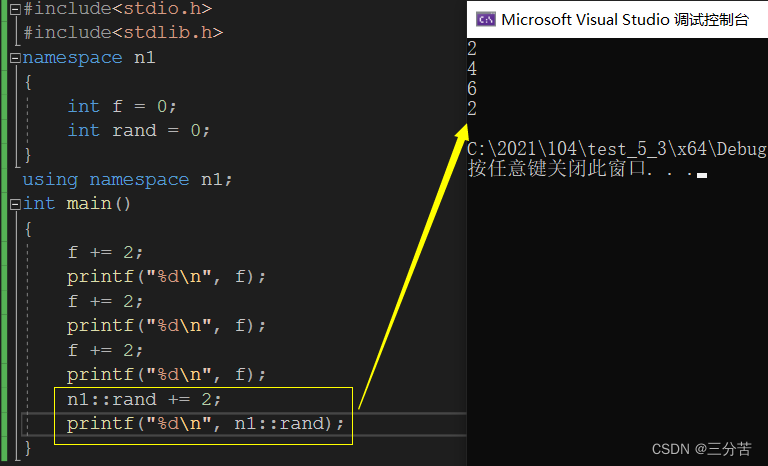
namespace n1 { int f = 0; int rand = 0; } using n1::f; int main() { f += 2; printf("%d\n", f); n1::rand += 2; printf("%d\n", n1::rand); }
- 下面来看下C++的标准库命名空间:
#include<iostream> using namespace std; //std 是封C++库的命名空间 int main() { cout << "hello world" << endl; // hello world return 0; }如若省去了这行代码:using namespace std;
想要输出hello world就要这样做:
#include<iostream> int main() { std::cout << "hello world" << std::endl; return 0; }当然也可以这样:
#include<iostream> using std::cout; int main() { cout << "hello world" << std::endl; return 0; }这就充分运用到了命名空间。





![强化学习从基础到进阶-常见问题和面试必知必答[3]:表格型方法:Sarsa、Qlearning;蒙特卡洛策略、时序差分等以及Qlearning项目实战](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)