系列文章
收录于【Linux】文件系统 专栏
关于文件描述符与文件重定向的相关内容可以移步 文件描述符与重定向操作。
可以到 浅谈文件原理与操作 了解文件操作的系统接口。
想深入理解文件缓冲区还可以看看文件缓冲区。
目录
系列文章
磁盘
结构介绍
定位数据
抽象管理
文件系统
分组管理
属性存储
内容存储
深入解析文件操作
如何理解inode
创建和删除文件
文件访问
如何存储大文件
磁盘
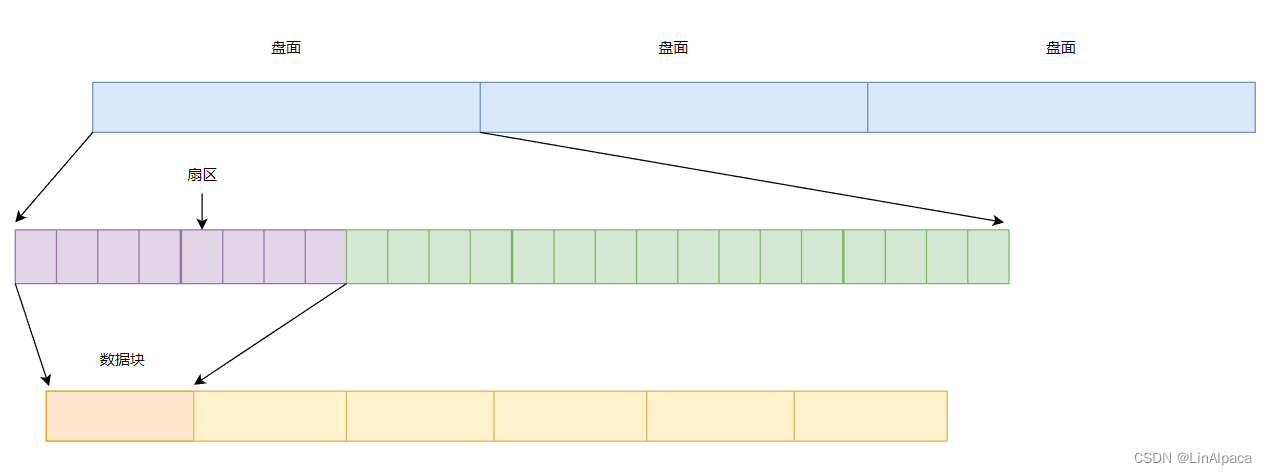
🧊以前的文章里,我们只讲了文件在内存中的打开时的状态,而今天便是要讲文件于磁盘中是如何存储的。
🧊相信大家虽然经常在讲磁盘,但是实际上对于磁盘的了解并不多,磁盘又分作机械硬盘与固态硬盘,而我们今天所讲的磁盘是机械硬盘,下面一起先来看看它的基本结构吧。


结构介绍
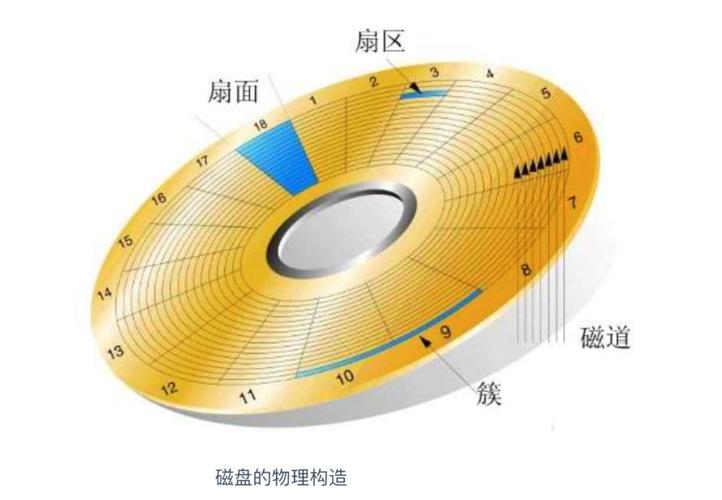
🧊盘片:
磁盘通常由一个或多个盘片组成,这些盘片通常是由金属或玻璃等材料制成的圆形薄片。一个盘片有正反两个面。
🧊磁头:
磁头负责读取和写入数据。每个扇面都有一个磁头,它浮动在盘片表面上方,通过微小的电流在磁盘表面上读写数据。
🧊磁道(柱面):
扇面表面被划分为许多同心圆,每个圆被称为一个磁道。数据被写入或读取时,磁头会在特定磁道上移动。
🧊扇区:
磁道被进一步划分为多个扇区,每个扇区存储一定量的数据。磁盘中存储的基本单元,通常为 512 字节或 4 KB。

🧊总结一下,我们存储的数据就是存在一个个扇区之中,通过磁头来对数据内容进行访问。
定位数据
🧊那我们该如何定义扇区的位置呢?
首先要确定在哪个扇面上(根据磁头),之后确定在哪个磁道(根据半径),最后根据扇区编号定位目标扇区的位置。
🧊因此以后找一个扇区只要
- 磁道(柱面): cylinder
- 磁头: head
- 扇区: sector
🧊而这种定位扇区的方法被称作 CHS 定位法。
抽象管理
🧊而在 OS 内部并不是直接使用 CHS 定位法的。
[原因]:
- 万一硬件发生变化,则 OS 也要变化,因此 OS 的实现需要与硬件解耦。
- 一个扇区的大小(512B)不足 OS 一次 IO 的最小读取单位(4Kb)。
所以,OS 要有自己的一套地址,来进行块级别的管理。
🧊我们沿着磁道,将磁盘展开,将盘面抽象成一个数组。于是,我们定位一个扇区便可定位它的下标,因为 OS 是以 4KB 为单位进行 IO 的,故 OS 读取的数据块要包括 8 个扇区,在 OS 的角度甚至可以不关心扇区。
🧊只需要像计算机常规的访问方式那样: 起始地址 + 偏移量,即获取数据块第一个扇区的地址(下标) + 4KB(块的类型)即能访问的整个数据块。
🧊由此我们便可以通过线性下标定位任何一个块了,而这种 OS 管理磁盘的方式被称为逻辑块地址(LBA)。
🧊从 LBA 出发,我们还能够转化得到扇区的 CHS。
- C: LBA / 每个面的大小 / 每个磁道的大小
- H: LBA / 每个面的大小
- S: LBA % 每个磁道的大小
文件系统
分组管理
🧊学习完上面的知识后,我们知道 OS 通过先描述再组织的方式将磁盘抽象成一个大数组进行管理。
🧊而具体管理的方法,就是我们接下来要讲解的内容了。
由于磁盘抽象成的数组过于庞大,首先第一步就需要将其分作几个区域。每个区域的管理方式都是一样的,因此只要管理好一个区域就相当于管理好整个磁盘了。(类似于 begin 和 end 进行下标的划分)
🧊虽然磁盘已经经历过一次分区,但是每个区的大小依旧十分庞大,我们还需要再进行一次分组。
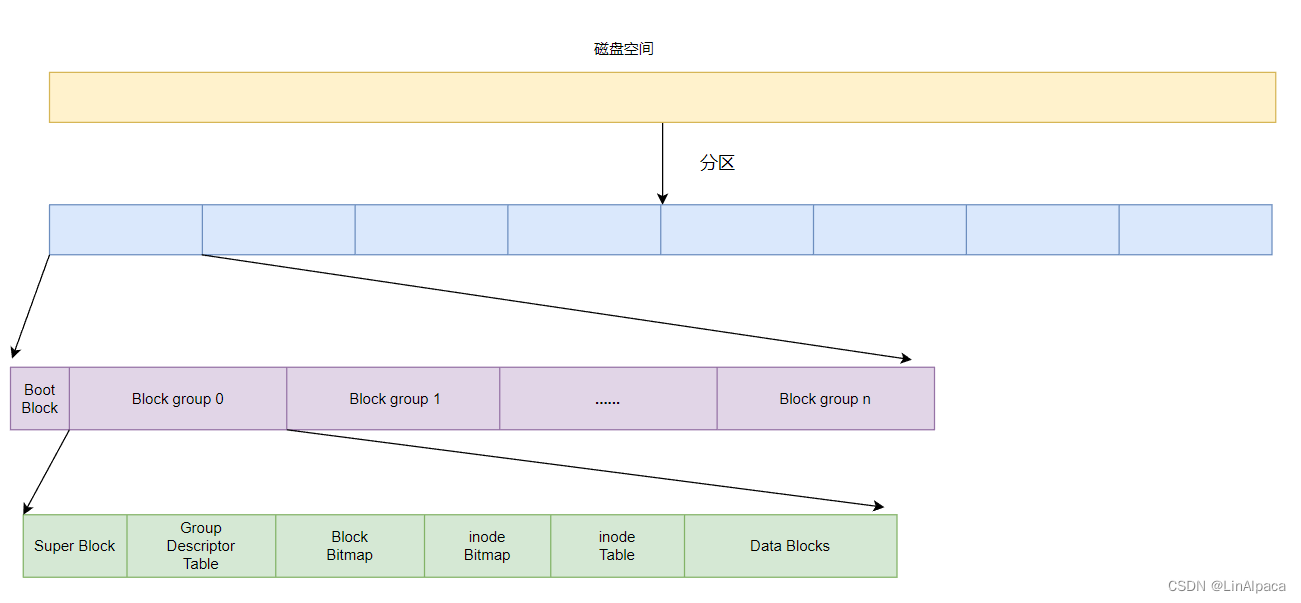
🧊由此管理每个区的任务就简化到了管理每个组,只要实现一个组的管理通过复制粘贴就可完成其他组的管理,进而完成整个区的管理,而管理好每个区就相当于管理好了整个盘。
🧊在每个区内都会有一个Boot Block,又名为启动块,在开机时会通过它读取 OS 镜像的地址,从而找到操作系统,若是这个区域损坏则会直接影响操作系统的启动。

🧊同时,组内还划分了不同的块承担了不同的职责:
- Super Block: 存储了文件系统的所有属性信息: 文件系统的类型、整个分组的情况等。
- Group Descriptor Table: 简称 GDT 又叫做组描述符,内部统计了该组内详细的属性信息,例如: 组内各个块如何划分。
- Block Bitmap: 块位图,标志数据块是否被使用。
- inode Bitmap: inode 位图,每个比特位表示 inode 是否可用。
- inode Table: 专门保存 group 内所有文件的 inode 节点。
- Data Blocks: 具体的数据块。
🧊其中,Super Block 在每个分组都存在,且统一更新,是为了防止万一其发生损坏导致整个分区都无法使用,因此做了多个备份。
属性存储
🧊我们常说,在文件 = 内容 + 属性,在 Linux 中内容和属性是被分开存储的。
一般而言,一个文件内部所有属性的集合就是 inode 节点(128字节),同时一个文件对应一个 inode。
🧊在一个分区中便会有大量的文件,因此就会又大量的 inode,由此需要将 group 中所有的 inode 管理起来,即 inode Table。
其中每个 inode 都有自己对应的编号,也属于对应文件的属性 id。我们可以通过 ls -i 查看文件的 inode 编号。
ls -i //查看文件的inode编号
🧊在之后的访问中,OS 也是根据 inode 编号来进行文件查找或读取内容。
内容存储
🧊存完属性后,那考虑的便是如何存储文件内容。我们通过数据块来保存文件内容,所以一个有效文件保存内容至少需要 1 个数据块。
🧊而数据块在 Data Block 中,那么我们该如何定位文件对应的数据块呢?
🧊其实,在 inode 内部便会存入当前文件对应数据块的索引,之后在 Data Block 中定位即可。可以如此近似理解。
struct inode
{
int number;
...//其他文件属性
int datablocks[NUM];
};深入解析文件操作
如何理解inode
🧊Linux 系统中只识别 inode 编号,文件的 inode 中并不存在文件名,文件名提供给用户使用的。我们又该如何理解这层关系呢?
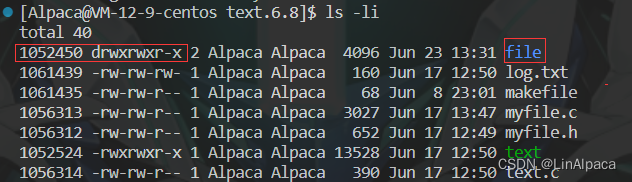
🧊创建一个目录文件后,我们可以观察到目录文件也有自己的 inode 编号,那目录中都存了什么数据呢?
🧊实际上,目录的数据块里保存的就是该目录下文件名与文件 inode 编号对应的映射关系,二者互为key值。
🧊因此,任何一个文件都应该在一个目录内部。
🧊同时,inode 可以用于确定分组,inode number 在一个分区中唯一有效,不能跨分区。(分组的起始位置 + 位图的位置)
创建和删除文件
- 当我们创建一个文件时,首先OS 会在 inode Bitmap 找一个未被使用的 inode 编号分配给当前 inode,填入相关信息后置于 inode Table 中。
- 再根据inode中的属性和 Block Bitmap 的情况分配对应的数据块,并填入 inode 中的索引表中。
- 最后再更改目录中的内容,将文件名与该文件 inode 关联起来。
🧊删除文件的话只需要修改两个 bitmap 即可,将空间空闲出来,下次便会直接覆盖写入。
🧊同样电脑文件中的删除操作也并不是直接将文件删除,也是调整空间的状态,因此只要这块空间还没有被写入数据,便能够进行恢复。
文件访问
🧊当我们访问文件时:
- 首先在当前目录下,找到输入文件名对应的 inode 编号。
- 一个目录一定隶属于一个分区,结合编号在该分区中找到对应分组,在该分组的 inode table 中找到文件的 inode。
- 通过 inode 与对应的 Data Block 关联起来,于是便找到了相关数据,进而根据命令进行其他操作。
如何存储大文件
🧊若是直接使用 inode 内部的数组直接索引 Data Block 中的内容,假设一个数组可以存 NUM 个内容,是否意味着我们最大只能存 NUM * 4KB 大小的文件呢?
🧊答案是否定的,我们可以使指向的数据块里的内容并非直接的数据,而是其他数据块的编号,由此拓宽文件的存储大小。
🧊这种索引方式称为二级索引。
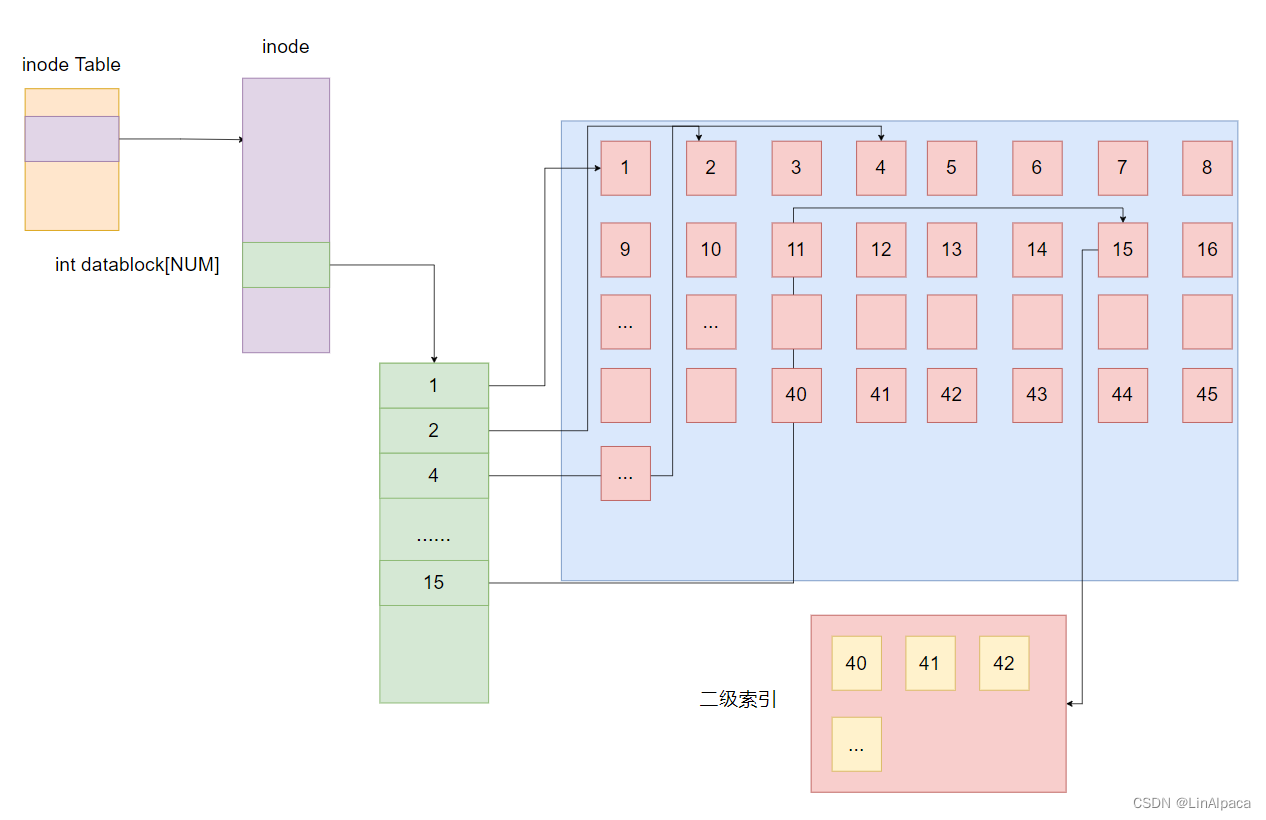
🧊若使用二级索引还是不足以构建出文件,那可以继续套娃,使用三级索引,在数据块中存储二级索引。这样只要磁盘空间允许,便可以构建出足够大的文件。
🧊好了,今天 文件系统 的相关内容到这里就结束了,如果这篇文章对你有用的话还请留下你的三连加关注。





![强化学习从基础到进阶-常见问题和面试必知必答[3]:表格型方法:Sarsa、Qlearning;蒙特卡洛策略、时序差分等以及Qlearning项目实战](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)