友情链接:C/C++系列系统学习目录
知识总结顺序参考C Primer Plus(第六版)和谭浩强老师的C程序设计(第五版)等,内容以书中为标准,同时参考其它各类书籍以及优质文章,以至减少知识点上的错误,同时方便本人的基础复习,也希望能帮助到大家
最好的好人,都是犯过错误的过来人;一个人往往因为有一点小小的缺点,将来会变得更好。如有错漏之处,敬请指正,有更好的方法,也希望不吝提出。最好的生活方式就是和努力的大家,一起奔跑在路上
文章目录
- 🚀一、类和对象概述
- ⛳(一)什么是类,类的定义
- ⛳(二)什么是对象,对象的使用
- ⛳(三)类定义精讲
- 🎈1.类定义中的访问控制
- 🎈2.类成员函数的实现
- 🎈3.构造函数
- (1)默认构造函数
- ①合成的默认构造函数(默认构造函数的隐式版本)
- ②手动定义的默认构造函数(平常说的默认构造函数)
- (2)拷贝(复制)构造函数
- ①合成的拷贝构造函数
- ②手动定义的拷贝构造函数
- (3)赋值构造函数
- (4)移动构造函数(C++11新增)
- ①改进的拷贝构造
- ②移动构造实现
- ③移动构造优点
- ④std::move
- 🎈4.析构函数
- 🚀二、基础小知识综合
- ⛳(一)this指针
- ⛳(二)对象数组
- ⛳(三)类作用域
- ⛳(四)类文件的分离
- ⛳(五)有关返回对象的说明
- 🚀三、静态数据成员与静态成员函数
- ⛳(一)静态数据成员
- ⛳(二)静态成员函数
- 🚀四、const数据成员与const成员函数
- ⛳(一)const数据成员
- ⛳(二)const成员函数
- 🚀五、建模的常用手段:组合与聚合
- ⛳(一)组合
- ⛳(二)聚合
🚀一、类和对象概述
⛳(一)什么是类,类的定义
最重要的OOP特性:
- 抽象;
- 封装和数据隐藏;
- 多态;
- 继承;
- 代码的可重用性。
为了实现这些特性并将它们组合在一起,C++所做的最重要的改进是提供了类。
类是一种将抽象转换为用户定义类型的C++工具,它将数据表示和操纵数据的方法组合成一个整洁的包,所以类的基本思想是数据抽象( data abstraction) 和封装( encapsulation)。
1.数据抽象:一种依赖于接口( interface)和实现(implementation) 分离的编程(以及设计)技术。类的接口包括用户所能执行的操作;类的实现则包括类的数据成员、负责接口实现的函数体以及定义类所需的各种私有函数。
抽象是至关重要的。也就是说,将问题的本质特征抽象出来,并根据特征来描述解决方案,在这里,本质特征就是各种数据,根据特征来描述解决方案就是负责接口实现的函数体
2.封装:类设计尽可能将接口与实现细节分开。接口表示设计的抽象组件。将实现细节放在一起并将它们与抽象分开被称为封装。数据隐藏(将数据放在类的私有部分中)是一种封装,将实现的细节隐藏在私有部分中。封装的另一个例子是,将类函数定义和类声明放在不同的文件中。
举例说明:
“人类”是一个抽象的概念,不是具体的某个人,我们可以抽象出一些本质特征(数据)比如性别、年龄、身高等
根据这些数据提出的我们需要解决的问题的方法,也叫做操纵数据的接口,比如我们为了要得到年龄设立一个函数接口

客户/服务器模型
OOP程序员常依照客户/服务器模型来讨论程序设计。在这个概念中,客户是使用类的程序。类声明(包括类方法)构成了服务器,它是程序可以使用的资源。客户只能通过以公有方式定义的接口使用服务器,这意味着客户(客户程序员)唯一的责任是了解该接口。服务器(服务器设计人员)的责任是确保服务器根据该接口可靠并准确地执行。服务器设计人员只能修改类设计的实现细节,而不能修改接口。这样程序员独立地对客户和服务器进行改进,对服务器的修改不会客户的行为造成意外的影响。
抽象、定义出一个人类:
class Human {
public: //公有的,对外的
void eat(); //方法, “成员函数”
void sleep();
void play();
void work();
string getName();
int getAge();
int getSalary();
private:
string name;
int age;
int salary;
};
void Human::eat() {
cout << "吃炸鸡,喝啤酒!" << endl;
}
void Human::sleep() {
cout << "我正在睡觉!" << endl;
}
void Human::play() {
cout << "我在唱歌! " << endl;
}
void Human::work() {
cout << "我在工作..." << endl;
}
string Human::getName() {
return name;
}
int Human::getAge() {
return age;
}
int Human::getSalary() {
return salary;
}
int main(void) {
Human zhangshan;
system("pause");
}
⛳(二)什么是对象,对象的使用
谈对象之前,要清楚到底什么是接口(方法):
接口是一个共享框架,供两个系统(如在计算机和打印机之间或者用户或计算机程序之间)交互时使用;例如,用户可能是您,而程序可能是字处理器。使用字处理器时,您不能直接将脑子中想到的词传输到计算机内存中,而必须同程序提供的接口交互。您敲打键盘时,计算机将字符显示到屏幕上;
对于类,交互系统由类对象组成,而接口由编写类的人提供的方法组成。接口让程序员能够编写与类对象交互的代码,从而让程序能够使用类对象
之前说过,类是一个泛指(抽象)的概念,不是特指某一个事物,而对象就是一个特定“类”的具体实例。可以像定义基本数据类型那样使用类类型定义一个对象:
Human chenQi;
//定义一个我们抽象出的类类型的对象叫chenQi

使用对象:
使用对象实际上就是上面说的接口让程序员能够编写与类对象交互的代码,从而让程序能够使用类对象
int main(void) {
Human chenQi; // 通过自定义的特殊数据类型“Human”类, 来创建一个“对象”
// 合法使用
chenQi.eat();
chenQi.play();
chenQi.sleep();
// 非法使用
//cout << "年龄" << chenQi.age << endl; //直接访问私有成员,将无法通过编译
//正确使用
cout << "年龄" << chenQi.getAge() << endl; //因为未初始化age,所以年龄值是一个很大的负数
system("pause");
}
-
这演示了对象的长处之一:不用了解对象的内部情况,就可以使用它。只需要知道它的接口,即如何使用它。
-
实际上访问类成员函数(如cin.getline( ))的方式是从访问结构成员变量(如vincent.price)的方式衍生而来的。
-
同样可以将指针用于类类型,类似于 C 语言的结构体用法,使用->
int main(void) { Human h1; // 通过自定义的特殊数据类型“Human”类, 来创建一个“对象” Human *p; p = &h1; // 合法使用 p->eat(); p->play(); p->sleep(); // 非法使用 //cout << "年龄" << p->age << endl; //直接访问私有成员,将无法通过编译 //正确使用 cout << "年龄" << p->getAge() << endl; //暴露问题,年龄值是一个很大的负数 system("pause"); } -
可以将一个对象赋给同类型的另一个对象,与给结构赋值一样,在默认情况下,将一个对象赋给同类型的另一个对象时,C++将源对象的每个数据成员的内容复制到目标对象中相应的数据成员中。
现在回过头来看看cout。它是一个ostream类对象。ostream类定义(iostream文件的另一个成员)描述了ostream对象表示的数据以及可以对它执行的操作,如将数字或字符串插入到输出流中。同样,cin是一个istream类对象,也是在iostream中定义的。
知道类是用户定义的类型,但作为用户,并没有设计ostream和istream类。就像函数可以来自函数库一样,类也可以来自类库。ostream和istream类就属于这种情况。从技术上说,它们没有被内置到C++语言中,而是语言标准指定的类。这些类定义位于iostream文件中,没有被内置到编译器中。如果愿意,程序员甚至可以修改这些类定义,虽然这不是一个好主意(准确地说,这个主意很糟)iostream系列类和相关的fstream(或文件I/O)系列类是早期所有的实现都自带的唯一两组类定义。然而,ANSI/ISO C++委员会在C++标准中添加了其他一些类库。另外,多数实现都在软件包中提供了其他类定义。事实上,C++当前之所以如此有吸引力,很大程度上是由于存在大量支持UNIX、Macintosh和Windows编程的类库。
⛳(三)类定义精讲
🎈1.类定义中的访问控制
在类的定义中用到了关键字private和public,它们描述了对类成员的访问控制,使用类对象的程序都可以直接访问公有部分,但只能通过公有成员函数(或友元函数)来访问对象的私有成员
公有成员函数是程序和对象的私有成员之间的桥梁,提供了对象和程序之间的接口。防止程序直接访问数据被称为数据隐藏
C++还提供了第三个访问控制关键字protected:
为什么要使用 protected 访问权限?
子类的成员函数中,不能直接访问父类的 private 成员,这些成员已经被继承下来了,但是却不能访问。只有通过父类的 public 函数来间接访问,不是很方便。
解决方案:
把数据成员定义为 protected 访问访问权限。
效果:
类的成员函数中,可以直接访问它的父类的 protected 成员。但是在外部,别人又不能直接通过 Son 对象来访问这些成员。
一个类, 如果希望, 它的成员, 可以被自己的子类(派生类)直接访问, 但是, 又不想被外部访问那么就可以把这些成员, 定义为 protected访问权限!!!

无论类成员是数据成员还是成员函数,都可以在类的公有部分或私有部分中声明它。但由于隐藏数据是OOP主要的目标之一,因此数据项通常放在私有部分,组成类接口的成员函数放在公有部分;否则,就无法从程序中调用这些函数。
类对象的默认访问控制是private,所以对于数据不必在类声明中使用关键字private,不过为了习惯上以及代码美观,一般都写上private
访问权限总结:
public
- 外部可以直接访问.
- 可以通过对象来访问这个成员
- Fahter wjl(“王健林”, 65);
- wjl.getName();
private
- 外部不可以访问
- 自己的成员函数内, 可以访问
- Fahter wjl(“王健林”, 65);
- wjl.name; // 错误!!!
- Father内的所有成员函数内, 可以直接访问name
protected
- protected和private非常相似
- 和private的唯一区别:
- protecte: 子类的成员函数中可以直接访问
- private: 子类的成员函数中不可以访问
1.类和结构的区别:
类描述看上去很像是包含成员函数以及public和private可见性标签的结构声明。实际上,C++对结构进行了扩展,使之具有与类相同的特性。它们之间唯一的区别是,结构的默认访问类型是public,而类为private。C++程序员通常使用类来实现类描述,而把结构限制为只表示纯粹的数据对象(常被称为普通老式数据(POD,Plain Old Data)结构)。
2.在数据结构中我们常使用结构表示某种复杂数据类型而不是用类:
结构与类很相似,都表示可以包含数据成员和函数成员的数据结构。与类不同的是,结构是值类型并且不需要堆分配。结构类型的变量直接包含结构的数据,而类类型的变量包含对数据的引用(该变量称为对象)。 struct 类型适合表示如点、矩形和颜色这样的轻量对象。尽管可能将一个点表示为类,但结构在某些方案中更有效。在一些情况下,结构的成本较低。例如,如果声明一个含有 1000 个点对象的数组,则将为引用每个对象分配附加的内存。结构可以声明构造函数,但它们必须带参数。声明结构的默认(无参数)构造函数是错误的。总是提供默认构造函数以将结构成员初始化为它们的默认值。在结构中初始化实例字段是错误的。在类中,必须初始化实例对象. 使用 new 运算符创建结构对象时,将创建该结构对象,并且调用适当的构造函数。与类不同的是,结构的实例化可以不使用 new 运算符。如果不使用 new,那么在初始化所有字段之前,字段将保持未赋值状态且对象不可用。对于结构,不像类那样存在继承。一个结构不能从另一个结构或类继承,而且不能作为一个类的基。但是,结构从基类 Object 继承。
结构可实现接口,其方式同类完全一样。
一个是值类型(结构),一个是引用类型(类),结构在传递的时候如果没有指定ref,则传递的是内存中的一分副本,而class则是传递对他的引用。
类在堆中,结构在栈中,类传递的是类在堆中的地址,而结构是在栈中另复制了一个传递,你改变传递过来的结构不会影响原结构。而类是引用,共用一块内存,会改变堆中类的内容.
🎈2.类成员函数的实现
还需要创建类描述的第二部分:为那些由类声明中的原型表示的成员函数提供代码。成员函数定义与常规函数定义非常相似,它们有函数头和函数体,也可以有返回类型和参数。但是它们还有两个特殊的特征:
定义成员函数时,使用作用域解析运算符(::)来标识函数所属的类;例如:
string Human::getName() {
return name;
}
- 这将getName()标识为成员函数,还意味着我们可以将另一个类的成员函数也命名为getName()
- 标识符getName()具有类作用域(class scope),因此,在Human类中的其他成员函数不必使用作用域解析运算符,就可以使用getName()方法,这是因为它们属于同一个类,然而,在类声明和方法定义之外使用getName()时,需要采取特殊的措施,
- 方法可以访问类的私有成员,如果试图使用非成员函数访问私有数据成员,编译器禁止这样做(友元函数除外)
- 成员函数的实现同时放在类里面,也就是说直接在类里面定义的成员函数将自动成为内联函数,类声明常将短小的成员函数作为内联函数
- 所创建的每个新对象都有自己的存储空间,用于存储其内部变量和类成员;但同一个类的所有对象共享同一组类方法,即每种方法只有一个副本。例如,假设kate和joe都是Stock对象,则kate.shares将占据一个内存块,而joe.shares占用另一个内存块,但kate.show( )和joe.show( )都调用同一个方法,也就是说,它们将执行同一个代码块,只是将这些代码用于不同的数据。
🎈3.构造函数
构造函数的作用:
C++的目标之一是让使用类对象就像使用标准类型一样,然而,到现在为止,还不能让您像初始化int或结构那样来初始化对象。也就是说,常规的初始化语法不适用于类类型,为此,C++提供了一个特殊的成员函数——类构造函数,专门用于构造新对象、将值赋给它们的数据成员。更准确地说,C++为这些成员函数提供了名称和使用语法,而程序员需要提供方法定义。
在创建一个新的对象时,自动调用的函数,用来进行“初始化”工作:对这个对象内部的数据成员进行初始化
构造函数的特点:
- 自动调用(在创建新对象时,自动调用)
- 构造函数的函数名,和类名相同
- 构造函数没有返回类型,虽然没有返回值,但没有被声明为void类型。实际上,构造函数没有声明类型
- 可以有多个构造函数(即函数重载形式)
声明和定义构造函数:
既然是对这个对象内部的数据成员进行初始化,所以我们根据数据成员来声明和定义:由于需要为Human对象提供3个值,因此应为构造函数提供3个参数:
class Human {
public:
Human(string name,int age,int salary); //函数原型
private:
string m_name;
int m_age;
int m_salary;
};
//一种可能的定义实现
Human::Human(string name,int age,int salary){
if(age < 0) {
cout << "the age is error";
m_age = 0;
}
m_name = name;
m_age = age;
m_salary = salary;
}
- 成员名和参数名:为了方便易读,我们常将参数名设置成与类的数据成员名称相似,但参数名不能与类成员相同,为了避免这种混乱,一种常见的做法是在数据成员名中使用m_前缀,而在参数中使用原来的名称
- 构造函数的定义里不仅仅是给数据成员初始化,也可以有其它许多满足我们要求的实现
使用构造函数:
C++提供了两种使用构造函数来初始化对象的方式。
-
第一种方式是隐式地调用构造函数:
Human chenQi("陈七",20,1.25); -
第二种方式是显式地调用构造函数:
Human chenQi = Human("陈七",20,1.25);编译器有两种方式来执行这种语法:第一种与隐式地调用构造函数语法完全相同,另一种方式是允许调用构造函数来创建一个临时对象,然后将该临时对象复制到chenQi中,并丢弃它。初始化一般使用的是第一种,而在赋值语句中使用构造函数总会导致在赋值前创建一个临时对象:
chenQi = Human("陈七2",20,1.25);注意:
可能立刻删除临时对象,但也可能会等一段时间,在这种情况下,析构函数的消息将会过一段时间才显示。
由于这种自动变量被放在栈中,因此最后创建的对象将最先被删除,最先创建的对象将最后被删除
如果既可以通过初始化,也可以通过赋值来设置对象的值,则应采用初始化方式。通常这种方式的效率更高。
1.可以在构造函数中加入打印信息测试我们的构造结果:
Human::Human(string name, int age, int salary) { if (age < 0) { cout << "the age is error"; m_age = 0; } m_name = name; m_age = age; m_salary = salary; cout << m_name << endl << m_age << endl << m_salary; }2.构造函数初始化列表:
格式:构造函数(数据类型 数值1,数据类型 数值2):变量名1(数值1),变量名2(数值2){}
Human::Human(string name, int age, int salary) :m_name(name), m_salary(salary){}
(1)默认构造函数
没有参数的构造函数,称为默认构造函数。默认构造函数是在未提供显式初始值时,用来创建对象的构造函数。也就是说,它是用于下面这种声明的构造函数:
Human chenQi;
①合成的默认构造函数(默认构造函数的隐式版本)
class Human {
public:
void eat();
void sleep();
void play();
void work();
string getName();
int getAge();
int getSalary();
private:
string m_name;
int m_age;
int m_salary;
};
Human chenQi;
-
如果没有提供任何构造函数,则C++将自动提供默认构造函数。它是默认构造函数的隐式版本,不做任何工作,因此将创建chenQi对象,但不初始化其成员,默认构造函数可能如下
Human::Human() {} -
当我们使用类Human创建一个对象chenQi时,必须要调用一个构造函数,而此时调用的则是合成的默认构造函数,一般情况下,都应该定义自己的默认构造函数,不要使用“合成的默认构造函数”
在C++11中允许在类中提供初始值,如果数据成员使用了“类内初始值”,就使用这个值来初始化数据成员【C++11】即:
... private: string m_name = "陈七"; int m_age = 20; int m_salary = 1.25; ...仅当数据成员全部使用了“类内初始值”,才宜使用“合成的默认构造函数”
-
当且仅当没有定义任何构造函数时,编译器才会提供隐式默认构造函数。一旦我们为类定义了构造函数后,系统就不再提供默认构造函数,就必须为它提供默认构造函数。
默认构造函数等下会讲有两种:
public: Human(); /* 默认构造函数 */ Human(string name,int age,int salary); /* 构造函数 */ Human(string name = "陈七",int age = 20,int salary = 1.25); /* 默认构造函数 */如果提供了非默认构造函数,但没有提供默认构造函数,则下面的声明将出错:
Human chenQi; //类Human不存在默认构造函数 Human chenQi("陈七",20,1.25); //只能显式的调用构造函数这样做的原因就是禁止创建未初始化的对象。
②手动定义的默认构造函数(平常说的默认构造函数)
平常说的默认构造函数一般指这一个,如果要创建对象,而不显式地初始化,则必须定义一个默认构造函数。定义默认构造函数的方式有两种。
- 一种是给已有构造函数的所有参数提供默认值,并且要在函数体中给数据成员赋对应的初值(为了体现它是默认构造函数而不是普通构造函数,我们把初值放在声明当中):
Human(string name = "陈七",int age = 20,int salary = 1.25);
Human::Human(string name,int age,int salary){
if(age < 0) {
cout << "the age is error";
m_age = 0;
}
m_name = name;
m_age = age;
m_salary = salary;
}
Human chenQi;
- 另一种方式是通过函数重载来定义另一个构造函数——一个没有参数的构造函数:
Human();
Human::Human() {
m_name = "无名氏";
m_age = 18;
m_salary = 30000;
}
Human chenQi;
1.由于只能有一个默认构造函数,因此不要同时采用这两种方式。实际上,通常应初始化所有的对象,以确保所有成员一开始就有已知的合理值。因此,用户定义的默认构造函数通常给所有成员提供隐式初始值。即使用没有参数的方式
2.在C++11中,如果某数据成员使用类内初始值,同时又在构造函数中进行了初始化,那么以构造函数中的初始化为准。相当于构造函数中的初始化,会覆盖对应的类内初始值。
(2)拷贝(复制)构造函数
①合成的拷贝构造函数
class Human {
public:
Human(); //默认构造函数
Human(int age,int salary); //自定义的构造函数
private:
string name = "Unknown";
int age = 28;
int salary;
char *addr;
};
Human::Human() {
m_name = "无名氏";
m_age = 18;
m_salary = 30000;
}
Human::Human(int age, int salary) {
cout << "调用自定义的构造函数" << endl;
this->age = age; //this 是一个特殊的指针,指向这个对象本身
this->salary = salary;
name = "无名";
addr = new char[64];
strcpy_s(addr, 64, "China");
}
Human h1(25, 35000); //使用自定义的构造函数
Human h2; //使用默认构造函数
-
当我们使用一个对象来初始化另外一个对象时会调用拷贝构造函数,与默认构造函数一样,不定义拷贝构造函数,编译器会生成“合成的拷贝构造函数,如以下的方式:
Human h3(h1); //使用自定义的拷贝构造函数 Human h3 = h1; -
合成的拷贝构造函数的缺点: 使用“浅拷贝”,例如有以下方法,会发现,我们改变了h1的addr,但h3的addr也跟着变成了长沙,因为addr数据成员属于指针类型,拷贝结束后,h3和h1都是指向同一块内存空间
void Human::setAddr(const char *newAddr) { if (!newAddr) { return; } strcpy_s(m_addr, 64, newAddr); } const char* Human::getAddr() { return m_addr; } cout << "h1 addr:" << h1.getAddr() << endl; cout << "h3 addr:" << h3.getAddr() << endl; h1.setAddr("长沙"); cout << "h1 addr:" << h1.getAddr() << endl; cout << "h3 addr:" << h3.getAddr() << endl;

解决方案:在自定义的拷贝构造函数中,使用‘深拷贝,拷贝出单独的一块内存空间出来
- 静态成员不受影响,因为它们属于整个类,而不是各个对象
②手动定义的拷贝构造函数
手动定义我们自己的拷贝构造函数的主要目的是解决默认拷贝构造函数在使用到指针时产生的浅拷贝的问题,同时可以自定义我们拷贝的规则:
Human::Human(const Human &man) {
cout << "调用自定义的拷贝构造函数" << endl;
m_age = man.m_age; //this 是一个特殊的指针,指向这个对象本身
m_salary = man.m_salary;
m_name = man.m_name;
m_addr = new char[64]; // 深度拷贝
strcpy_s(m_addr, 64, man.m_addr);
}
注意:在C++中,复制构造函数不可以使用形参,必须使用实参。这是因为如果用形参,编译器会生成一个临时的实参变量用于赋值,而它本身就要用到这个构造函数。假如通过了编译,也会造成死循环。
对象参数传递之前需要进行一次对象拷贝,将原对象的内容完整的拷贝到参数对象内部,函数执行时访问的是参数对象,而不是原对象。
对象返回时,也需要将函数处理的结果进行一次对象拷贝,不过被拷贝的返回值对象内存已经在函数调用之前已经开辟出来了,函数只需要记录它的地址即可,然后调用拷贝构造函数初始化它。
函数调用结束后,eax寄存器保存了返回值对象的地址,供调用者使用。
到底什么时候会自动调用拷贝构造函数:
- 新建一个对象并将其初始化为同类现有对象时,复制构造函数都将被调用。
- 调用函数时,实参是对象,形参不是引用类型,会产生一个临时对象,会发生拷贝,如果函数的形参是引用类型,就不会调用拷贝构造函数
- 函数的返回类型是类,而且不是引用类型
- 对象数组的初始化列表中,使用对象
- 进行初始化操作时
void test(Human man) {
cout << man.getSalary() << endl;
}
void test2(Human &man) { //不会调用拷贝构造函数,此时没有没有构造新的对象
cout << man.getSalary() << endl;
}
Human test3(Human &man) {
return man;
}
Human& test4(Human &man) {
return man;
}
Human h1(25, 35000); // 调用构造函数
Human h2(h1); // 调用拷贝构造函数
Human h3 = h1; // 调用拷贝构造函数
test(h1); // 因为参数为形参,会产生副本,有临时对象,调用拷贝构造函数
test2(h1); // 参数为实参,不会调用拷贝构造函数
test3(h1); // 因为返回值不是引用,会创建一个临时对象,接收 test3 函数的返回值,调用 1 次拷贝构造函数
test4(h1); // 因为返回的是引用类型,所以不会创建临时对象,不会调用拷贝构造函数
Human men[] = { h1, h2, h3 }; //调用 3 次拷贝构造函数
注意:
Human h4 = test3(h1);// 仅调用 1 次拷贝构造函数,返回的值直接作为 h4 的拷贝构造函数的参数
但实际上这样使用会报错:类"Human"没有适当的复制构造函数,因为test3的返回值为普通对象,而之前说过,普通对象并不能作为拷贝构造函数的参数,换成:
Human h4;
h4 = test3(h1);
这样可以,这样使用的是赋值构造函数

(3)赋值构造函数
Human& operator=(const Human &);
Human& Human::operator=(const Human &man) {
cout << "调用" << __FUNCTION__ << endl;
if (this == &man) {
return *this; //检测是不是对自己赋值:比如 h1 = h1;
}
// 如果有必要,需要先释放自己的资源(动态内存)
//delete addr;
//addr = new char[ADDR_LEN];
// 深拷贝
strcpy_s(addr, ADDR_LEN, other.addr);
// 处理其他数据成员
name = man.name;
age = man.age;
salary = man.salary;
// 返回该对象本身的引用, 以便做链式连续处理,比如 a = b = c;
return *this;
}
int main(void) {
Human h1(25, 35000); // 调用构造函数
// 特别注意,此时是创建对象 h2 并用h1进行初始化,调用的是拷贝构造函数,
// 不会调用赋值构造函数
Human h2 = h1;
h2 = h1; //调用赋值构造函数
h2 = test3(h1); //调用赋值构造函数
Human h3 = test3(h1); //调用拷贝构造函数
system("pause");
return 0;
}
-
如果没有定义赋值构造函数,编译器会自动定义“合成的赋值构造函数”,与其他合成的构造函数一样,是“浅拷贝”(又称为“位拷贝”)
-
实际上,这是一种运算符重载
-
将已有的对象赋给另一个对象时,将使用重载的赋值运算符(注意不是初始化)
-
赋值构造函数也存在深拷贝和浅拷贝的问题,所以在这里我们时手动定义(重载)的赋值构造函数,采用的是深拷贝
(4)移动构造函数(C++11新增)
先举个生活例子,你有一本书,你不想看,但我很想看,那么我有哪些方法可以让我能看这本书?有两种做法,一种是你直接把书交给我,另一种是我去买一些稿纸来,然后照着你这本书一字一句抄到稿纸上。
显然,第二种方法很浪费时间,但这正是有些深拷贝构造函数的做法,而移动构造函数便能像第一种做法一样省时,第一种做法在 C++ 中叫做完美转发。
在C++11之前,如果要将源对象的状态转移到目标对象只能通过复制。而现在在某些情况下,我们没有必要复制对象,只需要移动它们。
C++11引入移动语义:源对象资源的控制权全部交给目标对象。
复制构造和移动构造对比:
复制构造是这样的:在对象被复制后临时对象和复制构造的对象各自占有不同的同样大小的堆内存,就是一个副本。从下图中可以看到,临时对象和新建对象a申请的堆内存同时存在。(在深拷贝的情况下)
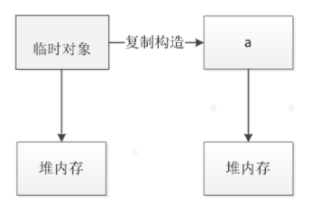
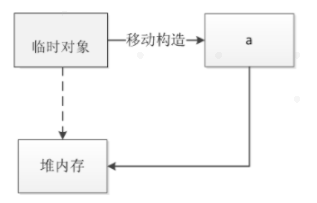
移动构造是这样的:就是让这个临时对象它原本控制的内存的空间转移给构造出来的对象,这样就相当于把它移动过去了。从下图中可以看到,原本由临时对象申请的堆内存,由新建对象a接管,临时对象不再指向该堆内存。
①改进的拷贝构造
设想一种情况,我们用对象a初始化对象b后,对象a我们就不在使用了,但是对象a的空间还在呀(在析构之前),既然拷贝构造函数,实际上就是把a对象的内容复制一份到b中,那么我们可以对指针进行浅复制,这样就避免了新的空间的分配,大大降低了构造的成本。
但是我们知道,指针的浅层复制是非常危险的,浅层复制之所以危险,是因为两个指针共同指向一片内存空间,若第一个指针将其释放,另一个指针的指向就不合法了。所以我们只要避免第一个指针释放空间就可以了。避免的方法就是将第一个指针(比如a->value)置为NULL,这样在调用析构函数的时候,由于有判断是否为NULL的语句,所以析构a的时候并不会回收a->value指向的空间(同时也是b->value指向的空间),注意,即使没有判断NULL的语句,直接delete null也是不会发生什么事的。
#include <string>
using namespace std;
class Integer {
private:
int* m_ptr;
public:
Integer(int value)
: m_ptr(new int(value)) {
cout << "Call Integer(int value)有参" << endl;
}
//参数为常量左值引用的深拷贝构造函数,不改变 source.ptr_ 的值
Integer(const Integer& source): m_ptr(new int(*source.m_ptr)) {
cout << "Call Integer(const Integer& source)拷贝" << endl;
}
//参数为左值引用的浅拷贝构造函数,转移堆内存资源所有权,改变 source.m_ptr的值 为nullptr
Integer(Integer& source): m_ptr(source.m_ptr) {
source.m_ptr= nullptr;
cout << "Call Integer(Integer& source)" << endl;
}
~Integer() {
cout << "Call ~Integer()析构" << endl;
delete m_ptr;
}
int GetValue(void) { return *m_ptr; }
};
Integer getNum()
{
Integer a(100);
return a;
}
int main(int argc, char const* argv[]) {
Integer a(getNum());
cout << "a=" << a.GetValue() << endl;
cout << "-----------------" << endl;
Integer temp(10000);
Integer b(temp);
cout << "b=" << b.GetValue() << endl;
cout << "-----------------" << endl;
return 0;
}
结果:

在程序中,参数为常量左值引用的浅拷贝构造函数的做法相当于前面说的的移动构造。
由运行结果可以看出,当同时存在参数类型为常量左值引用Integer(const Integer& source)和左值引用Integer(Integer& source)的拷贝构造函数时,getNum()返回的临时对象(右值)只能选择前者,非匿名对象 temp (左值)可以选择后者也可以选择前者,系统选择后者是因为该情况后者比前者好。为什么getNum()返回的临时对象(右值)只能选择前者?这是因为常量左值引用可以接受左值、右值、常量左值、常量右值,而左值引用只能接受左值。因此,对于右值,参数为任何类型左值引用的深拷贝构造函数Integer(Integer& source)无法实现完美转发。还有一种办法——右值引用。看下一节。
当右值引用和模板结合的时候,T&& 并不一定表示右值引用,它可能是个左值引用又可能是个右值引用 (这里的 && 是一个未定义的引用类型,称为通用引用universal references ),它必须被初始化,它是左值引用还是右值引用却决于它的初始化:
- 如果它被一个左值初始化,它就是一个左值引用;
- 如果被一个右值初始化,它就是一个右值引用。
②移动构造实现
移动构造函数的参数和拷贝构造函数不同,拷贝构造函数的参数是一个左值引用,但是移动构造函数的初值是一个右值引用。这意味着,移动构造函数的参数是一个右值或者左值的引用。也就是说,只有当用一个右值,或者用左值初始化另一个对象的时候,才会调用移动构造函数。移动构造函数的例子如下:
#include <iostream>
#include <string>
using namespace std;
class Integer {
private:
int* m_ptr;
public:
Integer(int value)
: m_ptr(new int(value)) {
cout << "Call Integer(int value)有参" << endl;
}
Integer(const Integer& source)
: m_ptr(new int(*source.m_ptr)) {
cout << "Call Integer(const Integer& source)拷贝" << endl;
}
Integer(Integer&& source)
: m_ptr(source.m_ptr) {
source.m_ptr= nullptr;
cout << "Call Integer(Integer&& source)移动" << endl;
}
~Integer() {
cout << "Call ~Integer()析构" << endl;
delete m_ptr;
}
int GetValue(void) { return *m_ptr; }
};
Integer getNum()
{
Integer a(100);
return a;
}
int main(int argc, char const* argv[]) {
Integer a(getNum());
cout << "a=" << a.GetValue() << endl;
cout << "-----------------" << endl;
Integer temp(10000);
Integer b(temp);
cout << "b=" << b.GetValue() << endl;
cout << "-----------------" << endl;
return 0;
}
结果:
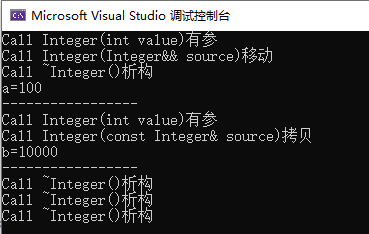
解释:
上面的程序中,getNum()函数中需要返回的是一个局部变量,因此它此时就是一个临时变量,因为在函数结束后它就消亡了,对应的其动态内存也会被析构掉,所以系统在执行return函数之前,需要再生成一个临时对象将a中的数据内容返回到被调的主函数中,此处自然就有两种解决方法:1、调用复制构造函数进行备份;2、使用移动构造函数把即将消亡的且仍需要用到的这部分内存的所有权进行转移,手动延长它的生命周期。
显然,前者需要深拷贝操作依次复制全部数据,而后者只需要“变更所有权”即可。
上面的运行结果中第一次析构就是return a; 这个临时对象在转移完内存所用权之后就析构了。
此处更需要说明的是:遇到这种情况时,编译器会很智能帮你选择类内合适的构造函数去执行,如果没有移动构造函数,它只能默认的选择复制构造函数,而同时存在移动构造函数和复制构造函数则自然会优先选择移动构造函数。比如上述程序如果只注释掉移动构造函数而其他不变,运行后结果如下:
原来调用了移动构造函数的地方变成了拷贝构造。
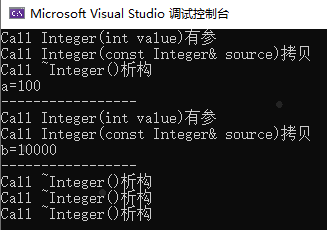
注:
移动构造的&&是右值引用,而getNum()函数返回的临时变量是右值
移动构造函数的第一个参数必须是自身类型的右值引用(不需要const,为啥?右值使用const没有意义),若存在额外的参数,任何额外的参数都必须有默认实参
看移动构造函数体里面,我们发现参数指针所指向的对象转给了当前正在被构造的指针后,接着就把参数里面的指针置为空指针(
source.m_ptr= nullptr;),对象里面的指针置为空指针后,将来析构函数析构该指针(delete m_ptr;)时,是delete一个空指针,不发生任何事情,这就是一个移动构造函数。有个疑问希望有识之士解答:匿名变量也是右值,为什么上面的程序换成 Integer a(Integer(100)); 后运行却不会调用移动构造函数?
我怀疑是VS有什么优化机制,但我看了优化是关了的“g++ demo1.cpp -o demo1 -fno-elide-constructors加上后面的参数关闭返回值优化就调用转移构造了
③移动构造优点
移动构造函数是c++11的新特性,移动构造函数传入的参数是一个右值 用&&标出。
首先讲讲拷贝构造函数:拷贝构造函数是先将传入的参数对象进行一次深拷贝,再传给新对象。这就会有一次拷贝对象的开销,拷贝的内存越大越耗费时间,并且进行了深拷贝,就需要给对象分配地址空间。而移动构造函数就是为了解决这个拷贝开销而产生的。
移动构造函数首先将传递参数的内存地址空间接管,然后将内部所有指针设置为nullptr,并且在原地址上进行新对象的构造,最后调用原对象的的析构函数,这样做既不会产生额外的拷贝开销,也不会给新对象分配内存空间。即提高程序的执行效率,节省内存消耗。
④std::move
std::move( )函数的返回值是remove_reference<_Ty>::type,其定义如下:
template <class _Ty>
using remove_reference_t = typename remove_reference<_Ty>::type;
template <class _Ty>
struct remove_reference {
using type = _Ty;
using _Const_thru_ref_type = const _Ty;
};
template <class _Ty>
struct remove_reference<_Ty&> {
using type = _Ty;
using _Const_thru_ref_type = const _Ty&;
};
template <class _Ty>
struct remove_reference<_Ty&&> {
using type = _Ty;
using _Const_thru_ref_type = const _Ty&&;
由代码可知,std::move()返回的是remove_reference类的type类型成员,而remove_reference的作用就是去掉引用。所以当传入的类型是int、int&、int&&时,返回的type都是int,再经过强制转换static_cast<int&&>转为右值。
所以,std::move()函数的作用就是能把左值强制转换为右值。
🎈4.析构函数
析构函数的作用:
用构造函数创建对象后,程序负责跟踪该对象,直到其过期为止。对象过期时,程序将自动调用一个特殊的成员函数,该函数的名称令人生畏——析构函数。
对象销毁前,做清理工作,具体的清理工作,一般和构造函数对应,比如:如果在构造函数中,使用 new 分配了内存,就需在析构函数中用 delete 释放,如果构造函数中没有申请资源(主要是内存资源),那么很少使用析构函数
析构函数的特点:
- 自动调用(在对象销毁时,自动调用)
- 析构函数的函数名,在类名前加上~
- 同样没有返回值,是没有而不是空
- 没有参数,最多只能有一个析构函数
什么时候调用析构函数:
- 什么时候应调用析构函数呢?这由编译器决定,通常不应在代码中显式地调用析构函数(有关例外情形,请参阅第12章的“再谈定位new运算符”)。如果创建的是静态存储类对象,则其析构函数将在程序结束时自动被调用。如果创建的是自动存储类对象(就像前面的示例中那样),则其析构函数将在程序执行完代码块时(该对象是在其中定义的)自动被调用。如果对象是通过new创建的,则它将驻留在栈内存或自由存储区中,当使用delete来释放内存时,其析构函数将自动被调用。
- 最后,程序可以创建临时对象来完成特定的操作,在这种情况下,程序将在结束对该对象的使用时自动调用其析构函数。
- 由于在类对象过期时析构函数将自动被调用,因此必须有一个析构函数。如果程序员没有提供析构函数,编译器将隐式地声明一个默认析构函数,并在发现导致对象被删除的代码后,提供默认析构函数的定义(什么也不做)。
声明和定义析构函数:
class Human {
public:
Human(); //默认构造函数
~Human(); //析构函数原型
private:
string m_name;
int m_age;
int m_salary;
};
Human::Human() {
name = "无名氏";
age = 18;
salary = 30000;
}
//一种可能的定义实现
Human::~Human() {
cout << "Bye";
}
- 和默认构造函数一样,可以在析构函数中加入打印信息测试析构函数何时被调用:
🚀二、基础小知识综合
⛳(一)this指针
我们在实现类成员函数时,比如说有个方法要比较两个对象,其中一个对象通过参数传递假设为Human chenYi,创建一个对象Human chenQi,在方法中,可以通过return chenYi返回,但如果要返回chen Qi呢,在方法中我们并不知道这个名字,如何称呼这个对象,C++解决这种问题的方法是:使用被称为this的特殊指针
this指针是一个特殊的指针,指向用来调用成员函数的对象,一般来说,所有的类方法都将this指针设置为调用它的对象的地址。
const Human* compare1(const Human *);
const Human* Human::compare1(const Human * other) {
if (this->age > other->age) {
return this;
}
else {
return other;
}
}
Human h1(25, 30000);
Human h2(18, 8000);
cout << h1.compare1(&h2)->getAge() << endl;
使用引用方式:
const Human& Human::compare2(const Human& other);
const Human& Human::compare2(const Human& other) {
if (age > other.age) {
return *this; //访问该对象本身的引用,而不是创建一个新的对象
}
else {
return other;
}
}
Human h1(25, 30000);
Human h2(18, 8000);
cout << h1.compare1(&h2)->getAge() << endl;
this 不能指向其他对象,堪称“永不迷失的真爱”:
void thisTestError(Human *other) {
this = other; // 将报错!
}
⛳(二)对象数组
Human mans[4]; //声明4个Human对象,调用默认构造函数
//使用构造函数来初始化数组元素
Human humans[] = {
Human("陈启",20,12.5),
Human("陈七",22,13),
Human("陈一",18,15),
};
//使用
humans[0].eat();
humans[1].play();
如果类包含多个构造函数,则可以对不同的元素使用不同的构造函数:
Human humans[10] = {
Human("陈启",20,12.5), //使用构造函数
Human(), //使用默认构造函数
Human("陈一",18,15),
};
由于该声明只初始化了数组的部分元素,因此余下的7个元素将使用默认构造函数进行初始化。
初始化对象数组的方案是,首先使用默认构造函数创建数组元素,然后花括号中的构造函数将创建临时对象,然后将临时对象的内容复制到相应的元素中。因此,要创建类对象数组,则这个类必须有默认构造函数。
⛳(三)类作用域
在类中定义的名称(如类数据成员名和类成员函数名)的作用域都为整个类,作用域为整个类的名称只在该类中是已知的,在类外是不可知的。因此,可以在不同类中使用相同的类成员名而不会引起冲突。
另外,类作用域意味着不能从外部直接访问类的成员,公有成员函数也是如此。也就是说,要调用公有成员函数,必须通过对象
Human chenQi;
chenQi.eat();
同样,在定义成员函数时,必须使用作用域解析运算符:
void Human::eat() {
cout << "吃炸鸡,喝啤酒!" << endl;
}
总之,在类声明或成员函数定义中,可以使用未修饰的成员名称(未限定的名称)。构造函数名称在被调用时,才能被识别,因为它的名称与类名相同。在其他情况下,使用类成员名时,必须根据上下文使用直接成员运算符(.)、间接成员运算符(->)或作用域解析运算符(::)。
⛳(四)类文件的分离
实际开发中,类的定义保存在头文件中,比如 Human.h【类的声明文件】(C++PrimerPlus)
类的成员函数的具体实现,保存在.cpp 文件中,比如 Human.cpp【类的方法文件】(C++PrimerPlus)
其他文件,如果需要使用这个类,就包含这个类的头文件。
和C语言一样,C++也允许甚至鼓励程序员将组件函数放在独立的文件中。第1章介绍过,可以单独编译这些文件,然后将它们链接成可执行的程序。(通常,C++编译器既编译程序,也管理链接器。)如果只修改了一个文件,则可以只重新编译该文件,然后将它与其他文件的编译版本链接。这使得大程序的管理更便捷。另外,大多数C++环境都提供了其他工具来帮助管理。例如,UNIX和Linux系统都具有make程序,可以跟踪程序依赖的文件以及这些文件的最后修改时间。运行make时,如果它检测到上次编译后修改了源文件,make将记住重新构建程序所需的步骤。大多数集成开发环境(包括Embarcadero C++ Builder、Microsoft Visual C++、Apple Xcode和Freescale CodeWarrior)都在Project菜单中提供了类似的工具。
- 头文件:包含结构声明和使用这些结构的函数的原型:
- 函数原型。
- 使用#define或const定义的符号常量。
- 结构声明。
- 类声明。
- 模板声明。
- 内联函数。
- 源代码文件:包含与结构有关的函数的代码。
- 源代码文件:包含调用与结构相关的函数的代码。
- 另外,这种组织方式也与OOP方法一致。一个文件(头文件)包含了用户定义类型的定义;另一个文件包含操纵用户定义类型的函数的代码。这两个文件组成了一个软件包,可用于各种程序中。
警告:在IDE中,不要将头文件加入到项目列表中,也不要在源代码文件中使用#include来包含其他源代码文件。
头文件管理
在同一个文件中只能将同一个头文件包含一次。记住这个规则很容易,但很可能在不知情的情况下将头文件包含多次。例如,可能使用包含了另外一个头文件的头文件。有一种标准的C/C++技术可以避免多次包含同一个头文件。它是基于预处理器编译指令#ifndef(即if not defined)的。
多个库的链接
C++标准允许每个编译器设计人员以他认为合适的方式实现名称修饰(参见第8章的旁注“什么是名称修饰”),因此由不同编译器创建的二进制模块(对象代码文件)很可能无法正确地链接。也就是说,两个编译器将为同一个函数生成不同的修饰名称。名称的不同将使链接器无法将一个编译器生成的函数调用与另一个编译器生成的函数定义匹配。在链接编译模块时,请确保所有对象文件或库都是由同一个编译器生成的。如果有源代码,通常可以用自己的编译器重新编译源代码来消除链接错误。
⛳(五)有关返回对象的说明
通常,编写使用对象作为参数的函数时,应按引用而不是按值来传递对象。这样做的原因之一是为了提高效率。按值传递对象涉及到生成临时拷贝,即调用复制构造函数,然后调用析构函数。调用这些函数需要时间,复制大型对象比传递引用花费的时间要多得多。如果函数不修改对象,应将参数声明为const引用。
按引用传递对象的另外一个原因是,在继承使用虚函数时,被定义为接受基类引用参数的函数可以接受派生类。
当成员函数或独立的函数返回对象时,有几种返回方式可供选择。可以返回指向对象的引用、指向对象的const引用或const对象。
1.返回指向const对象的引用
使用const引用的常见原因是旨在提高效率,但对于何时可以采用这种方式存在一些限制。如果函数返回(通过调用对象的方法或将对象作为参数)传递给它的对象,可以通过返回引用来提高其效率。例如,假设要编写函数Max(),它返回两个Vector对象中较大的一个,其中Vector是第11章开发的一个类。该函数将以下面的方式被使用:
vector force1 ( 50 ,60);
vector force2 (10,70);
vector max;
max = Max (force1, force2);
//下面两种实现都是可行的:
// version 1
vector Max {const Vector & vl,const vector & v2)
if (vl.magval()> v2.magval())
return v1;
else
return v2;
}
//version 2
const Vector & Max (const Vector & v1, const vector & v2){
if(v1.magval() > v2.magval() )
return v1;
else
return v2;
}
- 首先,返回对象将调用复制构造函数,而返回引用不会。因此,第二个版本所做的工作更少,效率更高。
- 其次,引用指向的对象应该在调用函数执行时存在。在这个例子中,引用指向force1或force2,它们都是在调用函数中定义的,因此满足这种条件。
- 第三,v1和v2都被声明为const引用,因此返回类型必须为const,这样才匹配。
2.返回指向非const对象的引用
两种常见的返回非const对象情形是,重载赋值运算符以及重载与cout一起使用的<<运算符。前者这样做旨在提高效率,而后者必须这样做。
operator=()的返回值用于连续赋值:
string s1( "Good stuff" );
string s2,s3 ;
s3 = s2 = sl;
s2.operator=()的返回值被赋给s3。为此,返回String对象或String对象的引用都是可行的,但与Vector示例中一样,通过使用引用,可避免该函数调用String的复制构造函数来创建一个新的String对象。在这个例子中,返回类型不是const,因为方法operator=()返回一个指向s2的引用,可以对其进行修改。
Operator<<()的返回值用于串接输出:
string s1 ( "Good stuff");
cout << sl << "is coming ! ";
operator<<(cout, s1)的返回值成为一个用于显示字符串“is coming!”的对象。返回类型必须是ostream &,而不能仅仅是ostream。如果使用返回类型ostream,将要求调用ostream类的复制构造函数,而ostream没有公有的复制构造函数。幸运的是,返回一个指向cout的引用不会带来任何问题,因为cout已经在调用函数的作用域内。
3.返回对象
如果被返回的对象是被调用函数中的局部变量,则不应按引用方式返回它,因为在被调用函数执行完毕时,局部对象将调用其析构函数。因此,当控制权回到调用函数时,引用指向的对象将不再存在。在这种情况下,应返回对象而不是引用。通常,被重载的算术运算符属于这一类。
4.返回const对象
vector Vector::operator+(const Vector & b) const{
return vector (x + b.x,Y + b.y);
}
能够以下面这样的方式使用它:
net = force1 + force2;
然而,这种定义也允许您这样使用它:
force1 + force2 = net;
cout << (forcel + force2 = net ) .magval() << endl;
- 这种代码之所以可行,是因为复制构造函数将创建一个临时对象来表示返回值。因此,在前面的代码中,表达式force1 + force2的结果为一个临时对象。在语句1中,该临时对象被赋给net;在语句2和3中,net被赋给该临时对象。
- 使用完临时对象后,将把它丢弃。例如,对于语句2,程序计算force1和force2之和,将结果复制到临时返回对象中,再用net的内容覆盖临时对象的内容,然后将该临时对象丢弃。原来的矢量全都保持不变。语句3显示临时对象的长度,然后将其删除。
如果您担心这种行为可能引发的误用和滥用,有一种简单的解决方案:将返回类型声明为const Vector。例如,如果Vector::operator+()的返回类型被声明为const Vector,则语句1仍然合法,但语句2和语句3将是非法的。
总之,如果方法或函数要返回局部对象,则应返回对象,而不是指向对象的引用。在这种情况下,将使用复制构造函数来生成返回的对象。如果方法或函数要返回一个没有公有复制构造函数的类(如ostream类)的对象,它必须返回一个指向这种对象的引用。最后,有些方法和函数(如重载的赋值运算符)可以返回对象,也可以返回指向对象的引用,在这种情况下,应首选引用,因为其效率更高。
🚀三、静态数据成员与静态成员函数
⛳(一)静态数据成员
有的时候,我们不可避免的需要使用全局变量,但使用全局变量不方便,会破坏程序的封装性。
解决方案:
使用类的静态成员。
class Human {
public:
......
int getCount();
private:
string name = "Unknown";
int age = 28;
......
// 类的静态成员
static int count;
};
//初始化:
int Human::count = 0;
// 类的普通成员函数,可以直接访问静态成员(可读可写)
int Human::getCount() {
return count;
}
对于非 const 的类静态成员,只能在类的实现文件中初始化。
const 类静态成员,可以在类内设置初始值,也可以在类的实现文件中设置初始值。(但是不要同时在这两个地方初始化,只能初始化 1 次)
注意,不能在类声明中初始化静态成员变量,这是因为声明描述了如何分配内存,但并不分配内存。初始化语句指出了类型,并使用了作用域运算符,但没有使用关键字static。
但如果静态成员是整型或枚举型const,则可以在类声明中初始化。
⛳(二)静态成员函数
前面说过,需要通过对象去调用接口,但如果总是为了一个接口去建立一个对象,会非常的麻烦
解决方案:
是用静态成员函数
类的静态方法:
-
可以直接通过类来访问【更常用】,也可以通过对象(实例)来访问。
-
在类的静态方法中,不能访问普通数据成员和普通成员函数(对象的数据成员和成员函数)
#pragma once
......
class Human {
public:
......
static int getCount();
......
};
//静态方法的实现,不能加 static
int Human::getCount() {
// 静态方法中,不能访问实例成员(普通的数据成员)
// cout << age;
// 静态方法中,不能访问 this 指针,因为 this 指针是属于实例对象的
// cout << this;
//静态方法中,只能访问静态数据成员
return count;
}
// 直接通过类名来访问静态方法!用法:类名::静态方法
cout << Human::getCount();
- 所有的成员函数,都可以访问静态数据成员。
- 对象和类都可以访问静态成员函数
🚀四、const数据成员与const成员函数
⛳(一)const数据成员
和以前讲的const一样,const限定符修饰的对象不能修改,const 数据成员的初始化方式:
-
使用类内值(C++11 支持)
-
使用构造函数的初始化列表
(如果同时使用这两种方式,以初始化列表中的值为最终初始化结果)
注意: 不能在构造函数或其他成员函数内,对 const 成员赋值
class Human {
public:
......
private:
......
const string bloodType;
};
// 使用初始化列表,对 const 数据成员初始化
Human::Human():bloodType("未知") {
......
//在成员函数内,不能对 const 数据成员赋值
//bloodType = "未知血型";
count++;
}
⛳(二)const成员函数
C++认为,const(常量)对象,如果允许去调用普通的成员函数,而这个成员函数内部可能会修改这个对象的数据成员!而这讲导致 const 对象不再是 const 对象!为此,C++提出了const成员函数,同时const对象只能调用const成员函数,不能调用普通的成员函数。
- 如果一个成员函数内部,不会修改任何数据成员,就把它定义为 const 成员函数。
- const 成员函数内,不能修改任何数据成员!
class Human {
public:
......
void description() const; //注意,const 的位置
......
};
void Human::description() const {
cout << "age:" << age
<< " name:" << name
<< " salary:" << salary
<< " addr:" << addr
<< " bloodType:" << bloodType << endl;
}
const Human h1;
h1.description();
有时候,使符号常量的作用域为类很有用。例加,类声明可能使用字面量30来指定数组的长度,由于该常量对于所有对象来说都是相同的,因此创建一个由所有对象共享的常量是个不错的主意。您可能以为这样做可行.
class Bakery { private: const int Months = 12; // declare a constant? FAILS double costs[Months]; ... }但这是行不通的,因为声明类只是描述了对象的形式。并没有创建对象,因此。在创建对象前,将没有用于存储值的空间(实际上11提供了成员初始化,但不适用于前述数组声明)。然而,有两种方式可以实现这个目标,并且效果相同。
第一种方式是在类中声明一个枚举。在类声明中声明的枚举的作用域为整个类,因此可以用枚举为整型常量提供作用域为整个类的符号名称。也就是说,可以这样开始Eskery声明。
classBakery{ private: enum { Months = 12}; double costs [Months]; ... }注意,用这种方式声明枚举并不会创建类数据成员。也就是说,所有对象中都不包含枚举。另外,Mkonths只是一个符号名称,在作用城为整个类的代码中遇到它时,编泽器将用30来替换它
由于这里使用枚举只是为了创键符号常量,并不打算创建枚举类型的变量,因此不需要提供枚举名。顺便说一句,在很多实现中,ios_bse类在其公有部分中完成了类似的工作,诸如ios_base::fixed等标识符就来自这里。其中, fixed是ios_base类中定义的典型的枚举量。
C++提供了另一种在类中定义常量的方式—一使用关键字static.
class Bakery { private : static const int Months = 12; double costs [Months] ; ... }这将创建一个名为Month的常量,该常量将与其他静态变量存储在一起,而不是存储在对象中。因此。只有一个Months常量,被所有Bakery对象共享。在C++98中,只能使用这种技术声明值为整数或枚举的静态常量,而不能存储double常量。C++11消除了这种限制。
🚀五、建模的常用手段:组合与聚合
说明:组合和聚合,不是 C++的语法要求,是应用中的常用手段。
⛳(一)组合
需求:
构建一个计算机类,一台计算机,由 CPU 芯片,硬盘,内存等组成。CPU 芯片也使用类来表示。
CPU.h
#pragma once
#include <string>
class CPU
{
public:
CPU(const char *brand = "intel", const char *version="i5");
~CPU();
private:
std::string brand; //品牌
std::string version; //型号
};
CPU.cpp
#include "CPU.h"
#include <iostream>
CPU::CPU(const char *brand, const char *version)
{
this->brand = brand;
this->version = version;
std::cout << __FUNCTION__ << std::endl;
}
CPU::~CPU()
{
std::cout << __FUNCTION__ << std::endl;
}
Computer.h
#pragma once
#include "CPU.h"
class Computer
{
public:
Computer(const char *cpuBrand, const char *cpuVersion,
int hardDisk, int memory);
~Computer();
private:
//被组合的对象直接使用成员对象。
CPU cpu; // Computer 和 CPU 是“组合”关系
//CPU *cpu; 使用指针表示被组合的对象
int hardDisk; //硬盘, 单位:G
int memory; //内存, 单位:G
};
Computer.cpp
#include "Computer.h"
#include <iostream>
Computer::Computer(const char *cpuBrand, const char *cpuVersion,int hardDisk, int memory):cpu(cpuBrand, cpuVersion)
{
this->hardDisk = hardDisk;
this->memory = memory;
std::cout << __FUNCTION__ << std::endl;
//在构造函数中,创建被组合的对象;在析构函数中,释放被组合的对象
this->cpu = new cpu(cpuBrand,cpuVersion);
}
Computer::~Computer()
{
//delete cpu;
std::cout << __FUNCTION__ << std::endl;
}
Main.cpp
#include <iostream>
#include <Windows.h>
#include <string>
#include <string.h>
#include "Computer.h"
using namespace std;
void test() {
Computer a("intel", "i9", 1000, 8);
}
int main(void) {
test();
system("pause");
return 0;
}
- 被拥有的对象(芯片)的生命周期与其拥有者(计算机)的生命周期是一致的。计算机被创建时,芯片也随之创建。计算机被销毁时,芯片也随之销毁。拥有者需要对被拥有者负责,是一种比较强的关系,是整体与部分的关系。
- 具体组合方式:
- 被组合的对象直接使用成员对象。(常用)
- 使用指针表示被组合的对象,在构造函数中,创建被组合的对象;在析构函数中,释放被组合的对象
- 构造函数的调用顺序:
- 派生的类,首先调用基类的构造函数,再调用派生类内部定义的其他类的成员的构造函数,最后调用自己的构造函数。析构函数则是先执行自身的构造函数,在执行成员的构造函数、
- 类1中含有类2数据成员,类1的默认复制构造函数将使用类2的复制构造函数来复制该类2对象;类1的默认赋值运算符将使用类2的赋值运算符给该对象赋值;而类1的析构函数将自动调用类2的析构函数。

⛳(二)聚合
需求:给计算机配一台音响。
Computer.h
#pragma once
#include "CPU.h"
class VoiceBox;
class Computer
{
public:
Computer(const char *cpuBrand, const char *cpuVersion,
int hardDisk, int memory);
~Computer();
void addVoiceBox(VoiceBox *box);
private:
//被组合的对象直接使用成员对象。
CPU cpu; // Computer 和 CPU 是“组合”关系
//CPU *cpu; 使用指针表示被组合的对象
int hardDisk; //硬盘, 单位:G
int memory; //内存, 单位:G
VoiceBox *box; //音箱
};
Computer.cpp
#include "Computer.h"
#include <iostream>
#include "VoiceBox.h"
Computer::Computer(const char *cpuBrand, const char *cpuVersion,int hardDisk, int memory):cpu(cpuBrand, cpuVersion)
{
this->hardDisk = hardDisk;
this->memory = memory;
std::cout << __FUNCTION__ << std::endl;
//在构造函数中,创建被组合的对象;在析构函数中,释放被组合的对象
//this->cpu = new cpu(cpuBrand,cpuVersion);
}
void Computer::addVoiceBox(VoiceBox *box) {
this->box = box;
}
Computer::~Computer()
{
//delete cpu;
std::cout << __FUNCTION__ << std::endl;
}
Main.cpp
#include <iostream>
#include <Windows.h>
#include <string>
#include <string.h>
#include "Computer.h"
#include "VoiceBox.h
using namespace std;
void test(VoiceBox *box) {
Computer a("intel", "i9", 1000, 8);
a.addVoiceBox(box);
}
int main(void) {
VoiceBox box;
test(&box);
system("pause");
return 0;
}
聚合不是组成关系,被包含的对象,也可能被其他对象包含。拥有者,不需要对被拥有的对象的生命周期负责。
主要实现为,内部成员是个指针,指向我们在外部创建的VoiceBox实例