以下内容均整理来自deeplearning.ai的同名课程
Location 课程访问地址
DLAI - Learning Platform Beta (deeplearning.ai)
LangChain for LLM Application Development 基于LangChain开发大语言应用模型(上)
一、LangChain: Q&A over Documents基于文档的检索问答
langchain具有检索能力,可以通过检索用户提供的文档内容,进行相应的回答。以下具体讲解实现逻辑
技术原理
1、【准备阶段】将文档内容(如列表)拆分成多个分片
2、【准备阶段】将分片通过embed技术转换为空间向量数组
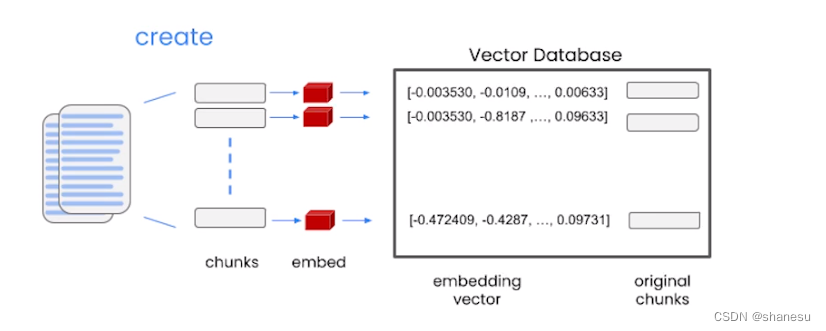
3、【提问阶段】用户提问时,程序自动将提问内容embed为空间向量
4、【提问阶段】将提问的空间向量和文档生成的空间向量数组比较,找到最相似的几个
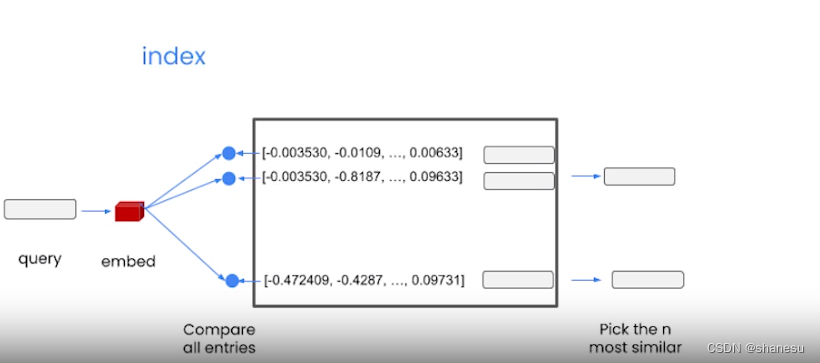
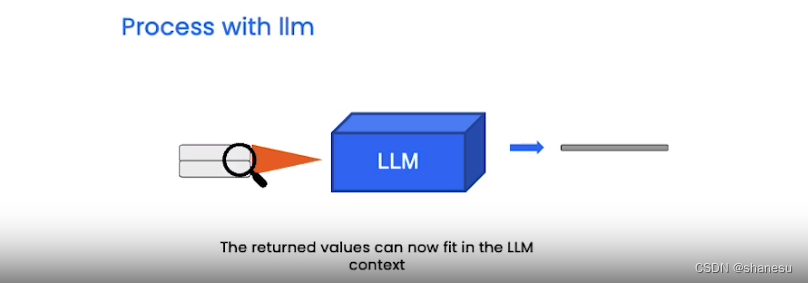
5、 【回答阶段】根据对应相关的文档切片,通过大预言模型,得到最终结果
实现方式1(检索csv进行回答)
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.vectorstores import DocArrayInMemorySearch
from IPython.display import display, Markdown
# 安装包
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
# 加载文件
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
# 将文件内容,转换成空间向量组
query ="Please list all your shirts with sun protection \
in a table in markdown and summarize each one."
response = index.query(query)
display(Markdown(response))
# 基于问题和空间向量的相似度,找到对应相关的内容进行回答。(通过markdown转换文本到表格)
实现方式2(检索docs进行回答)
# -------------------- 单个内容转换空间向量 --------------------
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# 加载包
embed = embeddings.embed_query("Hi my name is Harrison")
print(len(embed))
print(embed[:5])
# 将提问内容,转换为空间向量
# [-0.021913960576057434, 0.006774206645786762, -0.018190348520874977, -0.039148248732089996, -0.014089343138039112]
# ---------------- 在文档中检索相关内容进行解答 -----------------
db = DocArrayInMemorySearch.from_documents(
docs,
embeddings)
# 基于需要检索的文档,分片转换为空间向量组
query = "Please suggest a shirt with sunblocking"
docs = db.similarity_search(query)
len(docs)
docs[0]
# 在文档生成的空间向量组中检索和提问相关的内容
llm = ChatOpenAI(temperature = 0.0)
# 创建一个大语言进程
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
response = llm.call_as_llm(f"{qdocs} Question: Please list all your \
shirts with sun protection in a table in markdown and summarize each one.")
display(Markdown(response))
# 将文档中相关的内容+提问内容,通过llm进程获取解答
检索器
langchain支持直接通过标准检索器模板,进行内容检索。以下是一些检索器介绍。
1、stuff检索器直接将全文内容压缩,并通过语言模型进行回答。压缩过程中,可能导致信息缺失。

2、其他检索器:就不一一介绍了,看图理解
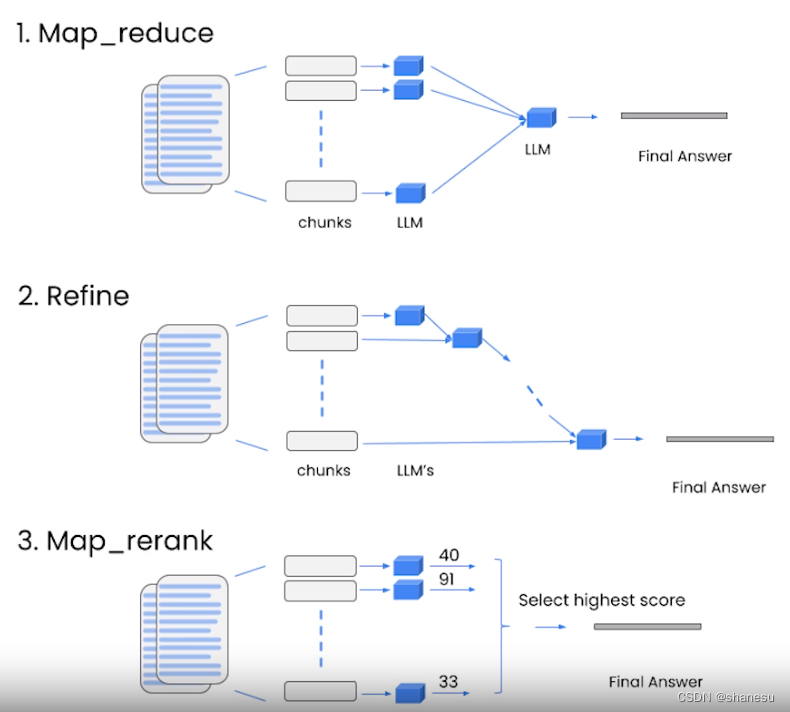
3、stuff检索器代码实现
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.vectorstores import DocArrayInMemorySearch
from IPython.display import display, Markdown
# 加载包
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
docs = loader.load()
# 加载docs
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
db = DocArrayInMemorySearch.from_documents(
docs,
embeddings
)
# 转换空间向量组
retriever = db.as_retriever()
# 基于空间向量组,创建检索器
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
# 创建会话
query = "Please list all your shirts with sun protection in a table \
in markdown and summarize each one."
response = qa_stuff.run(query)
# 生成回答
二、Evaluation评估
Outline:概要内容
- Example generation 示例生成
- Manual evaluation (and debuging) 人工评估
- LLM-assisted evaluation 大语言模型辅助评估
Create our QandA application 创建一个基于stuff检索的会话
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import DocArrayInMemorySearch
# 加载包
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
data = loader.load()
# 加载数据
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
# 基于数据创建向量空间组
llm = ChatOpenAI(temperature = 0.0)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs = {
"document_separator": "<<<<>>>>>"
}
)
# 创建一个基于stuff检索的会话Hard-coded examples手工编写QA示例
examples = [
{
"query": "Do the Cozy Comfort Pullover Set\
have side pockets?",
"answer": "Yes"
},
{
"query": "What collection is the Ultra-Lofty \
850 Stretch Down Hooded Jacket from?",
"answer": "The DownTek collection"
}
]LLM-Generated examples通过大语言模型生成QA示例
from langchain.evaluation.qa import QAGenerateChain
# 加载包
example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI())
# 创建QA生成链
new_examples = example_gen_chain.apply_and_parse(
[{"doc": t} for t in data[:5]]
)
# 基于数据内容生成QA示例Combine examples合并人工示例和大语言模型生成的示例
examples += new_examples
# 合并Manual Evaluation人工评估
import langchain
langchain.debug = True
# 加载包
qa.run(examples[0]["query"])
# 生成示例提问的AI答案(用于印证)
langchain.debug = FalseLLM assisted evaluation大语言模型辅助评估
predictions = qa.apply(examples)
# 对所有的示例基于大语言模型,生成回答
from langchain.evaluation.qa import QAEvalChain
llm = ChatOpenAI(temperature=0)
eval_chain = QAEvalChain.from_llm(llm)
# 创建评估链
graded_outputs = eval_chain.evaluate(examples, predictions)
# 对示例问题和回答进行评估
for i, eg in enumerate(examples):
print(f"Example {i}:")
print("Question: " + predictions[i]['query'])
print("Real Answer: " + predictions[i]['answer'])
print("Predicted Answer: " + predictions[i]['result'])
print("Predicted Grade: " + graded_outputs[i]['text'])
print()
# 显示评估结果三、 Agents代理
大语言模型一般来说并不能完成用于知识的问答(因为其知识是被压缩的,不完整),而更适合作为一个可以链接和调用工具的真人。
我们只要提供给大语言模型一些工具和信息,他就能更好的帮助我们处理特定问题
Outline:概要
- Using built in LangChain tools: DuckDuckGo search and Wikipedia使用langchain提供的工具
- Defining your own tools自定义工具
Built-in LangChain tools使用自带工具
from langchain.agents.agent_toolkits import create_python_agent
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.chat_models import ChatOpenAI
# 加载包
llm = ChatOpenAI(temperature=0)
tools = load_tools(["llm-math","wikipedia"], llm=llm)
# 创建一个工具箱
agent= initialize_agent(
tools,
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose = True)
# 创建一个代理,加载工具箱。
agent("What is the 25% of 300?")
# 调用代理回答问题,代理会自动识别此问题需要调用math数学计算,并调用计算函数获得结果
question = "Tom M. Mitchell is an American computer scientist \
and the Founders University Professor at Carnegie Mellon University (CMU)\
what book did he write?"
result = agent(question)
# 调用代理回答问题,代理会自动判断此问题需要调用wiki百科页面,获取相关百科的词条信息,并基于词条信息,生成最终的答案
Python Agent使用python代理工具
agent = create_python_agent(
llm,
tool=PythonREPLTool(),
verbose=True
)
# 创建一个python代理
customer_list = [["Harrison", "Chase"],
["Lang", "Chain"],
["Dolly", "Too"],
["Elle", "Elem"],
["Geoff","Fusion"],
["Trance","Former"],
["Jen","Ayai"]
]
agent.run(f"""Sort these customers by \
last name and then first name \
and print the output: {customer_list}""")
# 运行代理,代理会自动判断完成词任务需要用到sorted()方法,进行如下计算sorted_customers = sorted(customers, key=lambda x: (x[1], x[0])),并最终获得结果。
langchain.debug=True
agent.run(f"""Sort these customers by \
last name and then first name \
and print the output: {customer_list}""")
langchain.debug=False
# 可以通过debug查看具体的运行细节
Define your own tool自定义工具
from langchain.agents import tool
from datetime import date
# 加载包
@tool
def time(text: str) -> str:
"""Returns todays date, use this for any \
questions related to knowing todays date. \
The input should always be an empty string, \
and this function will always return todays \
date - any date mathmatics should occur \
outside this function."""
return str(date.today())
# 自定义函数工具
agent= initialize_agent(
tools + [time],
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose = True)
# 创建代理,调用自定义函数工具
try:
result = agent("whats the date today?")
except:
print("exception on external access")