文章目录
- 前言
- 0. Vgg
- 1.RepVGG Block 详解
前言
论文名称:RepVGG: Making VGG-style ConvNets Great Again
论文下载地址:https://arxiv.org/abs/2101.03697
官方源码(Pytorch实现):https://github.com/DingXiaoH/RepVGG
大神的讲解:
bilibili视频讲解:https://www.bilibili.com/video/BV15f4y1o7QR
https://blog.csdn.net/qq_37541097/article/details/125692507
0. Vgg
VGG网络是2014年由牛津大学著名研究组VGG (Visual Geometry Group) 提出的。在2014到2016年(ResNet提出之前),VGG网络可以说是当时最火并被广泛应用的Backbone。后面由于各种新的网络提出,论精度VGG比不上ResNet,论速度和参数数量VGG比不过MobileNet等轻量级网络,慢慢的VGG开始淡出人们的视线-但因为其堆叠结构简单,是很多网络结构的backbone。当VGG已经被大家遗忘时,2021年清华大学、旷视科技以及香港科技大学等机构共同提出了RepVGG网络,希望能够让VGG-style网络Great Again。
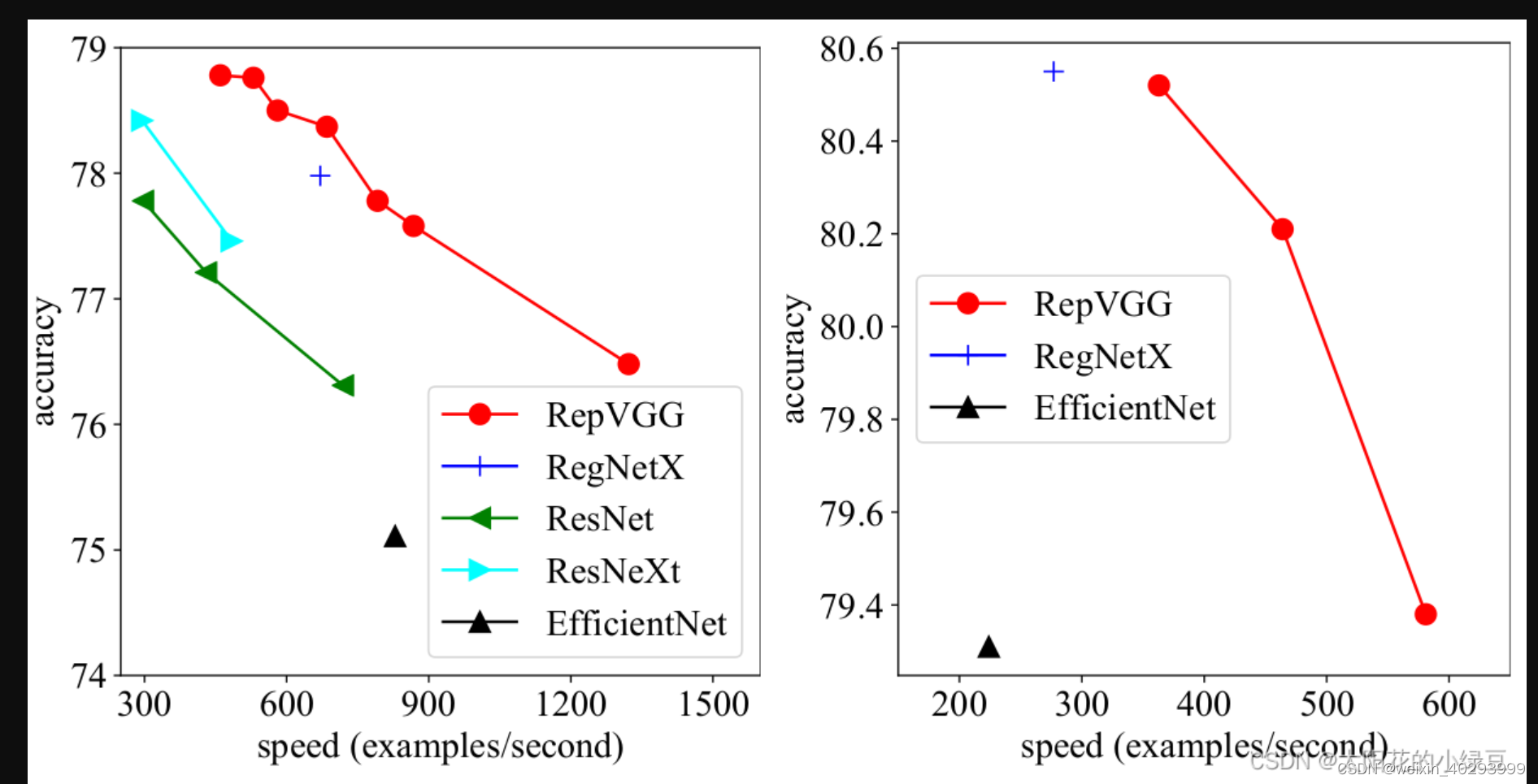
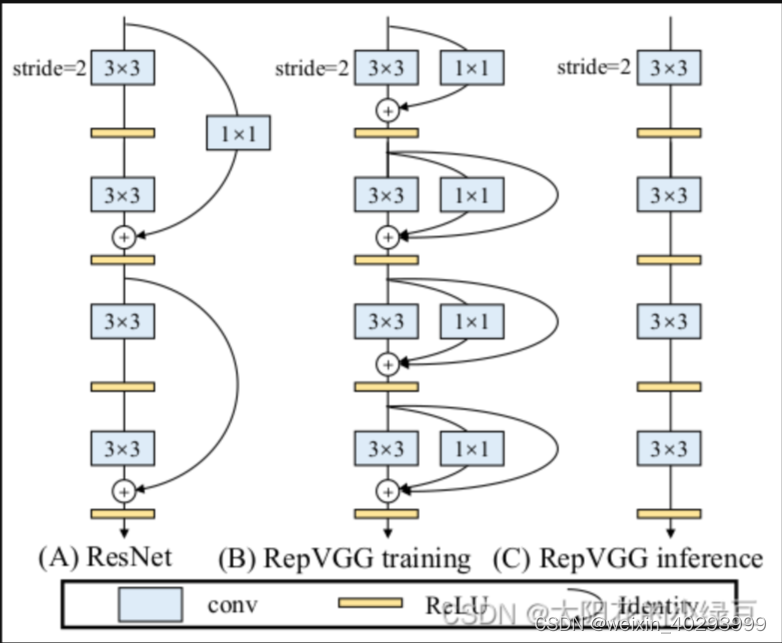
通过论文的图一可以看出,RepVGG无论是在精度还是速度上都已经超过了ResNet、EffcientNet以及ReNeXt等网络。那RepVGG究竟用了什么方法使得VGG网络能够获得如此大的提升呢,在论文的摘要中,作者提到了structural re-parameterization technique方法,即结构重参数化。实际上就是在训练时,使用一个类似ResNet-style的多分支模型,而推理时转化成VGG-style的单路模型。如下图所示,图(B)表示RepVGG训练时所采用的网络结构,而在推理时采用图(C)的网络结构。关于如何将图(B)转换到图(C)以及为什么要这么做后面再细说,如果对模型优化部署有了解就会发现这和做网络图优化或者说算子融合非常类似。
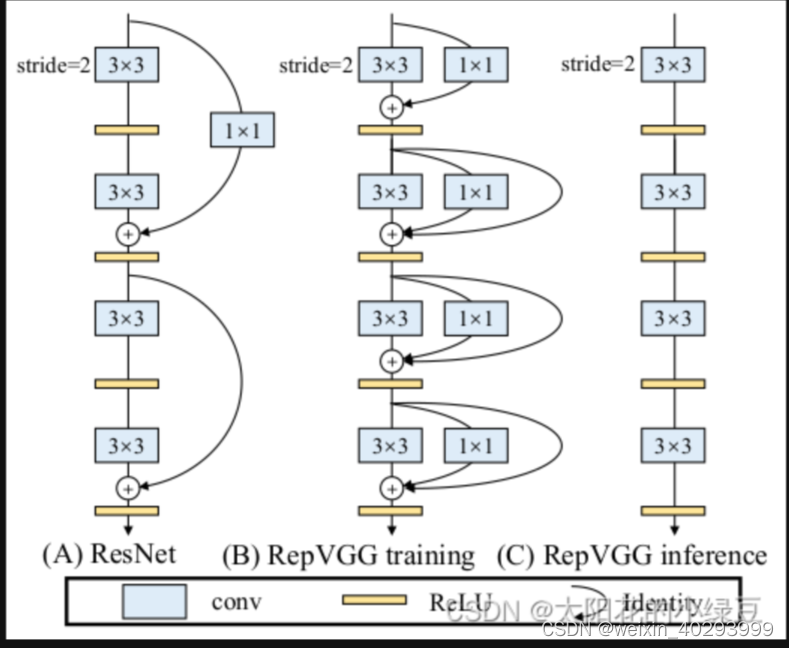
1.RepVGG Block 详解
其实关于RepVGG整个模型没太多好说的,就是在不断堆叠RepVGG Block,只要之前看过VGG以及ResNet的代码,那么RepVGG也不在话下。这里主要还是聊下RepVGG Block中的一些细节。由于论文中的图都是简化过的,于是我自己根据源码绘制了下图的RepVGG Block(注意是针对训练时采用的结构)。其中图(a)是进行下采样(stride=2)时使用的RepVGG Block结构,图(b)是正常的(stride=1)RepVGG Block结构。通过图(b)可以看到训练时RepVGG Block并行了三个分支:一个卷积核大小为3x3的主分支,一个卷积核大小为1x1的shortcut分支以及一个只连了BN的shortcut分支。
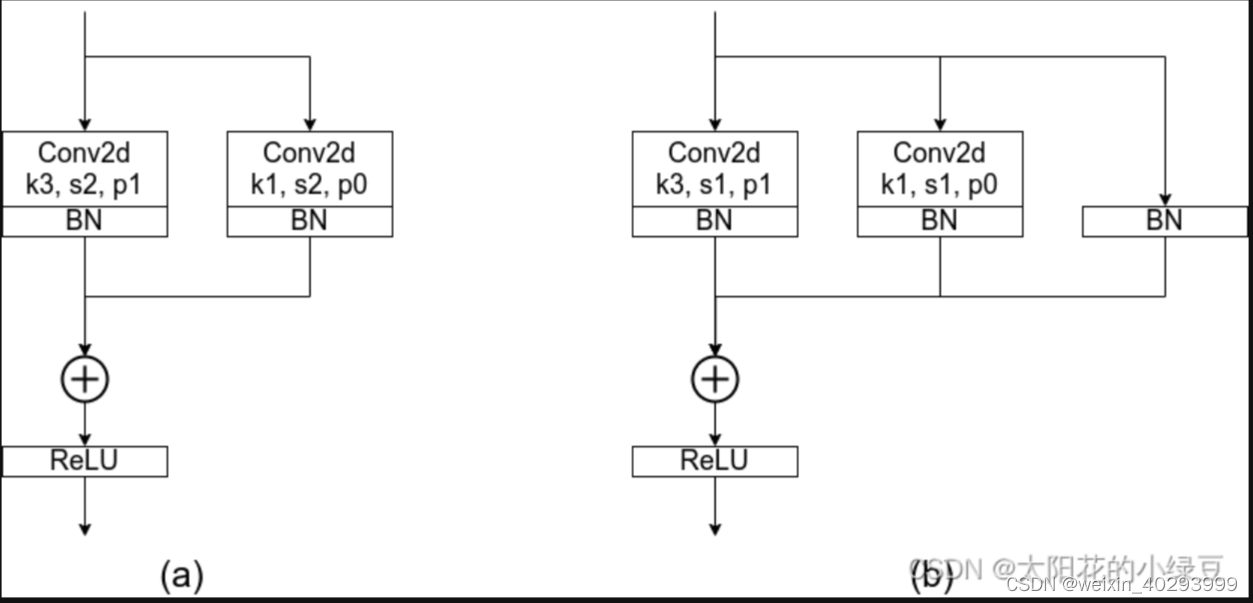
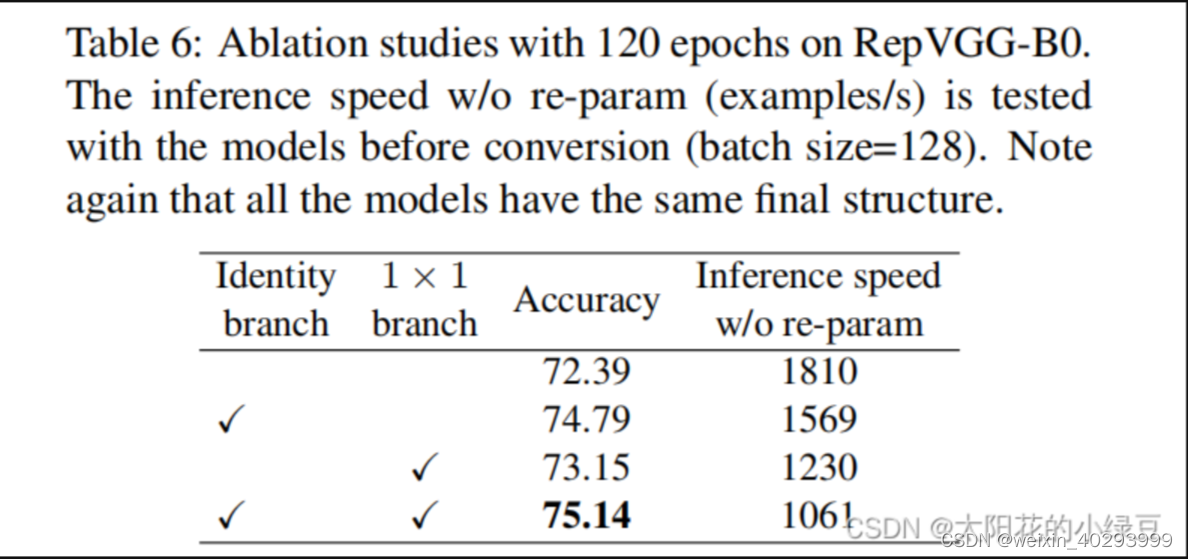
这里首先抛出一个问题,为什么训练时要采用多分支结构。如果之前看过像Inception系列、ResNet以及DenseNet等模型,我们能够发现这些模型都并行了多个分支。至少根据现有的一些经验来看,并行多个分支一般能够增加模型的表征能力。所以你会发现一些论文喜欢各种魔改网络并行分支。在论文的表6中,作者也做了个简单的消融实验,在使用单路结构时(不使用其他任何分支)Acc大概为72.39,在加上Identity branch以及1x1 branch后Acc达到了75.14。
接着再问另外一个问题,为什么推理时作者要将多分支模型转换成单路模型。根据论文3.1章节的内容可知,采用单路模型会更快、更省内存并且更加的灵活。
更快:主要是考虑到模型在推理时硬件计算的并行程度以及MAC(memory access cost),对于多分支模型,硬件需要分别计算每个分支的结果,有的分支计算的快,有的分支计算的慢,而计算快的分支计算完后只能干等着,等其他分支都计算完后才能做进一步融合,这样会导致硬件算力不能充分利用,或者说并行度不够高。而且每个分支都需要去访问一次内存,计算完后还需要将计算结果存入内存(不断地访问和写入内存会在IO上浪费很多时间)。
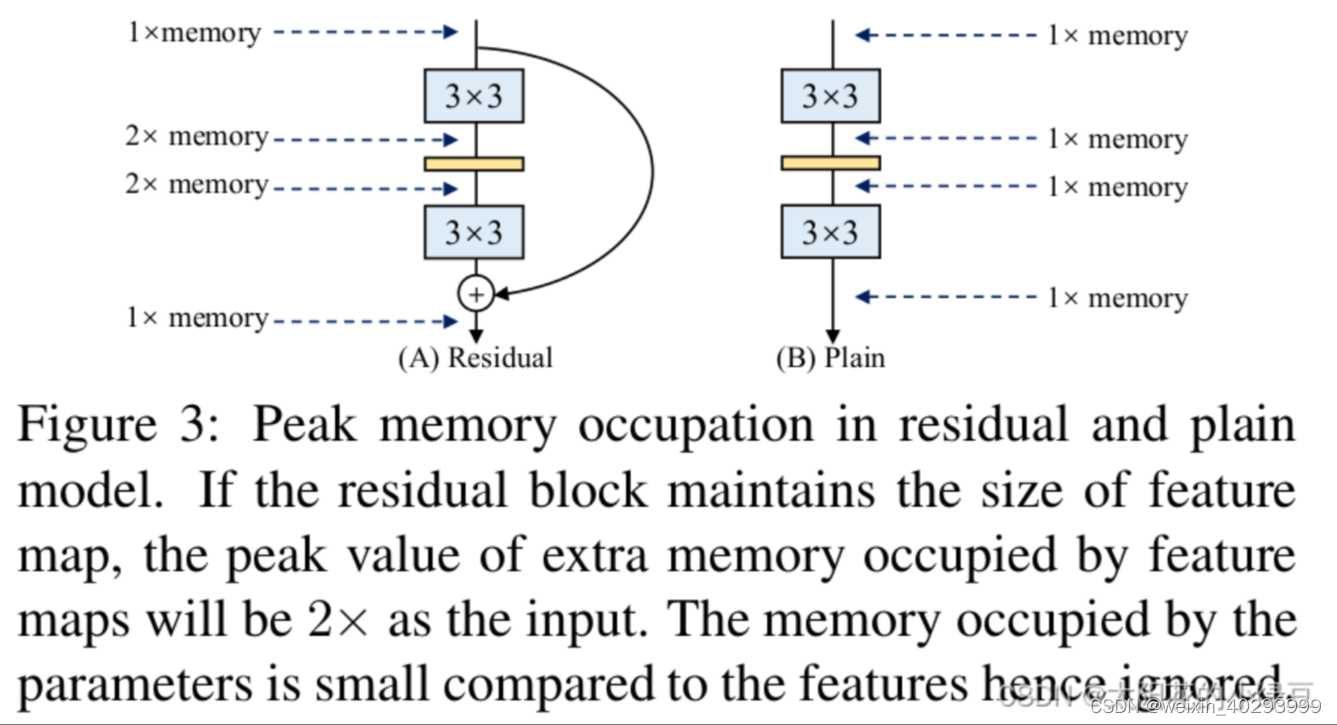
更省内存:在论文的图3当中,作者举了个例子,如图(A)所示的Residual模块,假设卷积层不改变channel的数量,那么在主分支和shortcut分支上都要保存各自的特征图或者称Activation,那么在add操作前占用的内存大概是输入Activation的两倍,而图(B)的Plain结构占用内存始终不变。
更加灵活:作者在论文中提到了模型优化的剪枝问题,对于多分支的模型,结构限制较多剪枝很麻烦,而对于Plain结构的模型就相对灵活很多,剪枝也更加方便。
其实除此之外,在多分支转化成单路模型后很多算子进行了融合(比如Conv2d和BN融合),使得计算量变小了,而且算子减少后启动kernel的次数也减少了(比如在GPU中,每次执行一个算子就要启动一次kernel,启动kernel也需要消耗时间)。而且现在的硬件一般对3x3的卷积操作做了大量的优化,转成单路模型后采用的都是3x3卷积,这样也能进一步加速推理。如下图多分支模型(B)转换成单路模型图(C)。
2 结构重参数化
在简单了解RepVGG Block的训练结构后,接下来再来聊聊怎么将训练好的RepVGG Block转成推理时的模型结构,即structural re-parameterization technique过程。 根据论文中的图4(左侧)可以看到,结构重参数化主要分为两步,第一步主要是将Conv2d算子和BN算子融合以及将只有BN的分支转换成一个Conv2d算子,第二步将每个分支上的3x3卷积层融合成一个卷积层。关于参数具体融合的过程可以看图中右侧的部分,如果你能看懂图中要表达的含义,那么ok你可以跳过本文后续所有内容干其他事去了,如果没看懂可以接着往后看。
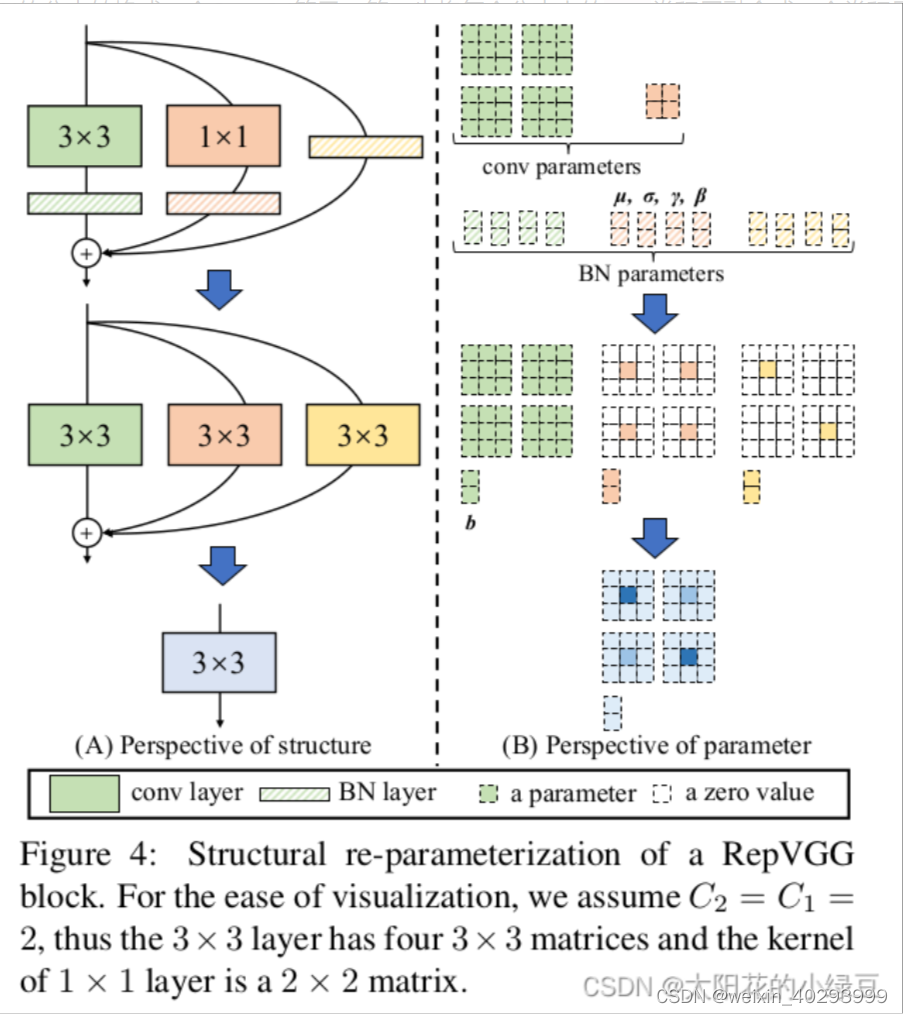
2.1 融合Conv2d和BN