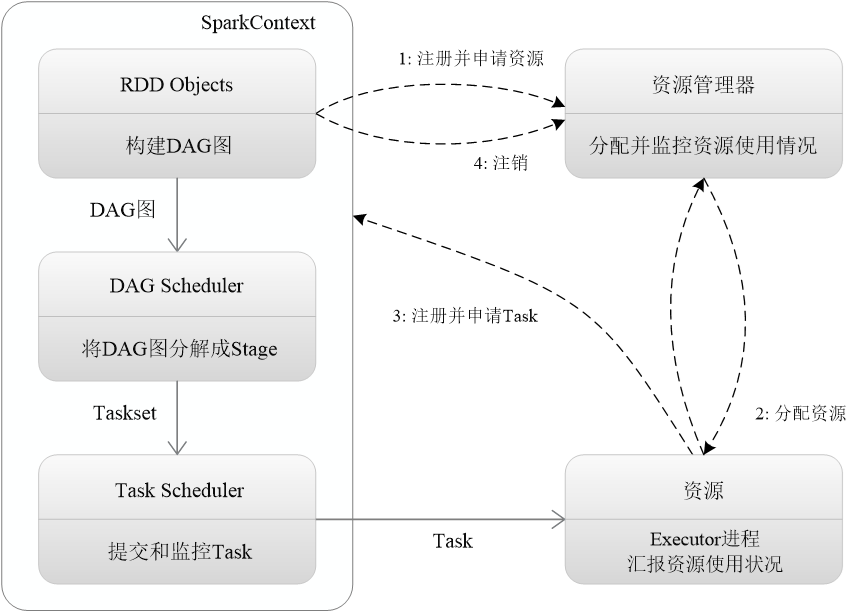
目标学习任务
检测出已经分割出的图像的分类
2 使用pytorch
pytorch 非常简单就可以做到训练和加载
2.1 准备数据
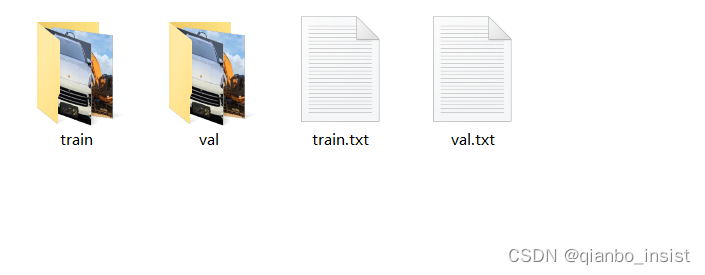
如上图所示,用来训练的文件放在了train中,验证的文件放在val中,train.txt 和 val.txt 分别放文件名称和分类类别,然后我们在代码中写名字就行
里面我就为了做一个例子,放了两种文件,1 是 卡宴保时捷,2 是工程车,如下图所示

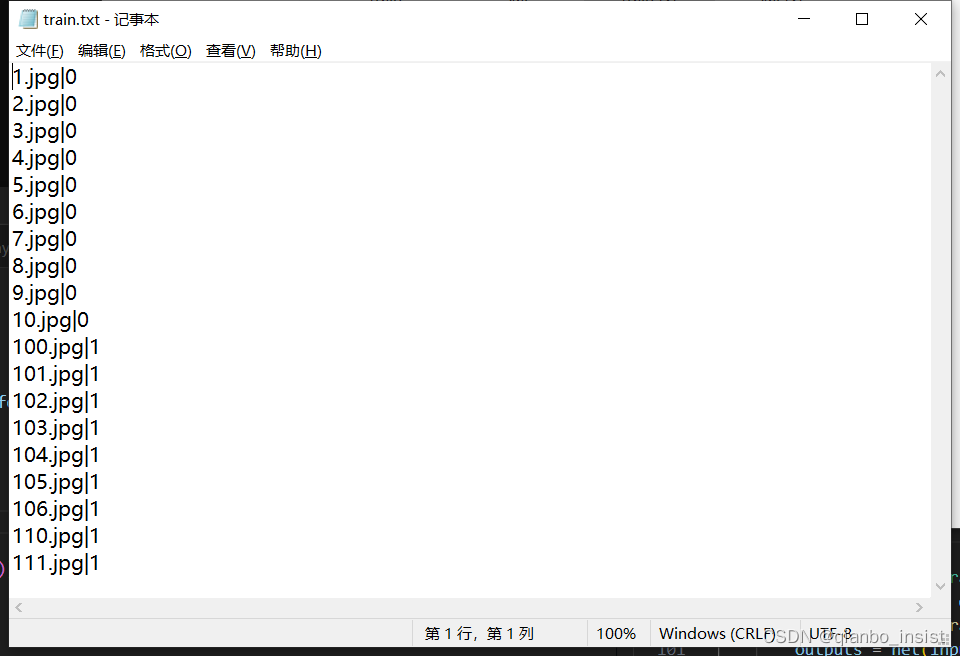
train.txt 如下图所示
val.txt 也是同样如此
3 show me the code
3.1 装载数据类
新增一个loaddata.py 文件
import torch
import random
from PIL import Image
class LoadData(torch.utils.data.Dataset):
def __init__(self, root, datatxt, transform=None, target_transform=None):
super(LoadData, self).__init__()
file_txt = open(datatxt,'r')
imgs = []
for line in file_txt:
line = line.rstrip()
words = line.split('|')
imgs.append((words[0], words[1]))
self.imgs = imgs
self.root = root
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
random.shuffle(self.imgs)
name, label = self.imgs[index]
img = Image.open(self.root + name).convert('RGB')
if self.transform is not None:
img = self.transform(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs)
LoadData 类是从torch.util.data.Dataset上继承下来的,需要一个transform类输入,实际上就是转化大小
3.2 网络类
定义一个网络类,只有两个输出
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3)
self.pool = nn.MaxPool2d((2, 2))
self.pool1 = nn.MaxPool2d((2, 2))
self.conv2 = nn.Conv2d(16, 32, 3)
self.fc1 = nn.Linear(36*36*32, 120)
self.fc2 = nn.Linear(120, 60)
self.fc3 = nn.Linear(60, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool1(F.relu(self.conv2(x)))
x = x.view(-1, 36*36*32)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
3.3 主要流程
import torch
from PIL import Image
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.optim as optim
from loaddata import LoadData
from modelnet import Net
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
classes = ['工程车','卡宴']
transform = transforms.Compose(
[transforms.Resize((152, 152)),transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_data=LoadData(root ='./data/train/',
datatxt='./data/'+'train.txt',
transform=transform)
test_data=LoadData(root ='./data/val/',
datatxt='./data/'+'val.txt',
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=2, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=2)
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 200 == 0:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
print('Finished Training')
PATH = './test.pth'
torch.save(net.state_dict(), PATH)
net = Net()
net.load_state_dict(torch.load(PATH))
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (
100 * correct / total))
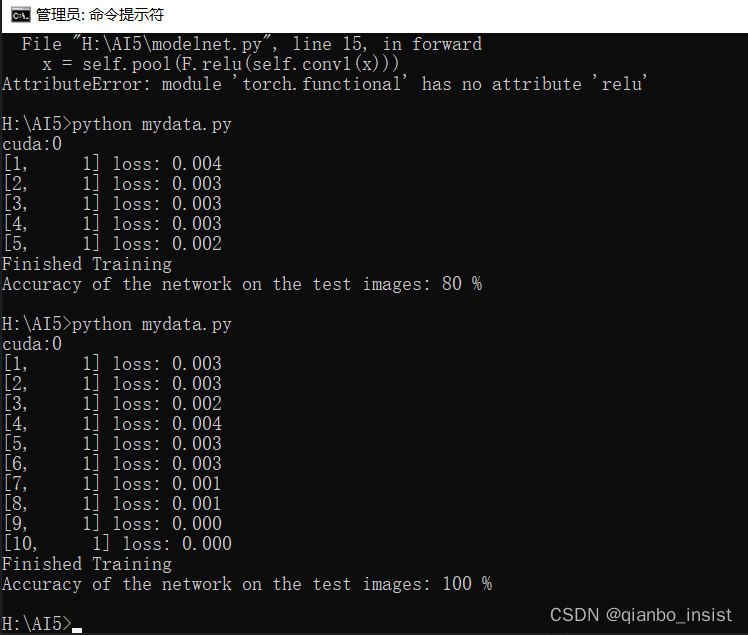
如上图所示,epoch为5时精确度为80%,为10时精确度为100%,各位不要当真,这这是训练集里面的数据集做识别,并不是真的精确度。
3.4 识别代码
import torch
from PIL import Image
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
from modelnet import Net
PATH = './test.pth'
transform = transforms.Compose(
[transforms.Resize((152, 152)),transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
net = Net()
net.load_state_dict(torch.load(PATH))
img = Image.open("./data/val/102.jpg").convert('RGB')
img = transform(img)
with torch.no_grad():
outputs = net(img)
_, predicted = torch.max(outputs.data, 1)
print("the 102 img lable is ",predicted)
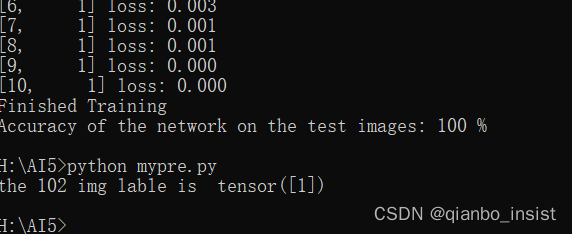
如下图所示,102 为卡宴识别为1 正确
后记
后面我们准备是从视频中传递过来图像进行分类,同时使用我们的工具VT解码视频后进行内存共享来生成图像,而不是从磁盘加载。要用到我们的c++ 解码工具,和pytorch进行交互
以下是第一篇文章:视频与AI,与进程交互(一)
VT 工具准备开源,端午节节后开出来