博主介绍:擅长Java、微信小程序、Python、Android等,专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
Java项目精品实战案例(300套)
Java+小程序项目实战(200套)Python项目精品实战案例(100套)
目录
一、效果演示
二、前言介绍
三、主要技术
3.1、python语言
3.2、django框架
3.3、MySQL数据库
3.4、爬虫技术
四、系统设计
4.1、系统应用架构设计
4.2、系统总体功能设计
五、功能截图
5.1、核心功能模块设计与实现
5.1.1模块实现
六、数据库设计
6.1、关系型数据表设计
七、结论
八、源码获取
一、效果演示
基于Python的反爬虫技术的研究演示视频
二、前言介绍
当下的网络是复杂的,网络上的信息非常的丰富,但也造成了大量的信息堆积,特别是大量的重复信息被反复的推送给用户。这是一个流量的时代,很多社会群体都会聚焦具备流量潜力的信息,从而发生蹭热度等行为来提升自己的网站或者blog的点击率,爬虫就是当下最为高效的爬取重要信息的一项数据获取方式。爬虫通过伪装用户代理、设置代理服务器等方式来实现对网络上的数据进行爬取的操作,通过对网页发送请求来实现数据的信息爬取工作。此次主要是通过利用django、Python等技术来先搭建一款网站,通过网站来输入一些信息内容,再通过Python来进行数据的爬取操作,通过爬取操作来实现爬虫的工作。在通过Python来设计反爬虫的操作,通过反爬虫的操作设计最终使得网站内的数据不会被爬取,实现很好的信息保护工作。
三、主要技术
3.1、python语言
Python语言是一种面向对象的技术,该语言是在1990年出现,该语言的开发者在进行开发时,就希望该语言能够成为一款简单的语言系统,该语言的底层实际上仍然是C语言以及C++语言,是在两者之上进行的扩展应用。该语言是现在全球非常流行的一款编程语言,是一种高级的脚本语言。
3.2、django框架
Django框架是基于python语言下的一款综合开发的框架技术,这款开发技术是免费的、开源的,在使用该技术进行开发时,其也是终于MVC三层结构进行开发,通过三层开发技术来实现模块的独立开发运行
3.3、MySQL数据库
本次系统设计的后台数据服务管理选择了常用的MySQL数据库管理工具,该工具在数据库的开发商可以保证有很好的开发效果,且该数据库的体积轻便,不占用用户过多的空间,可以高效的与服务器相连接使用,实现数据的稳定传输功能。该数据库所采用的标准SQL语言能够在数据的调用服务上提供便捷的操作,通过多线程的数据调用可以更准确的查找到所需数据,并且实现快速的调取服务。
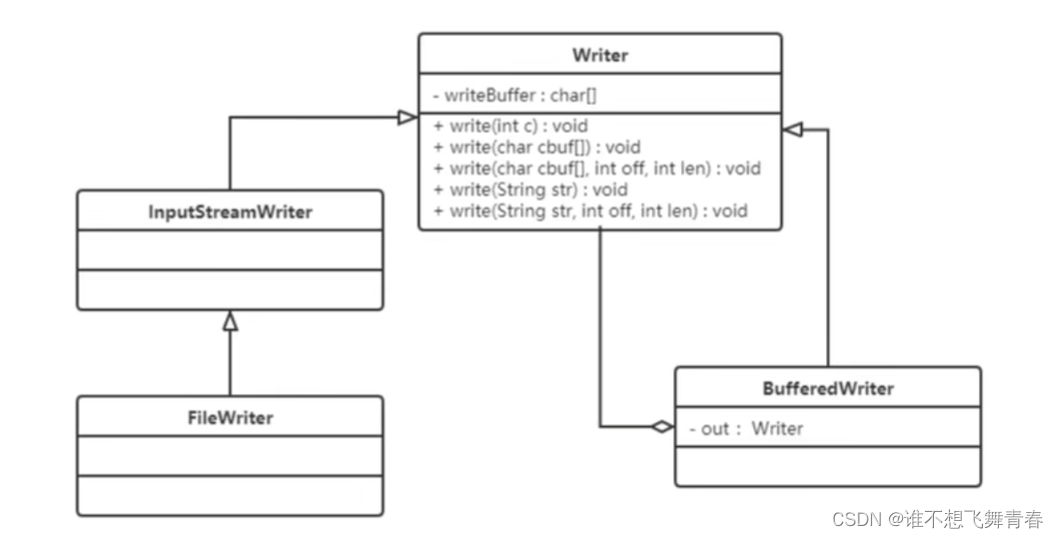
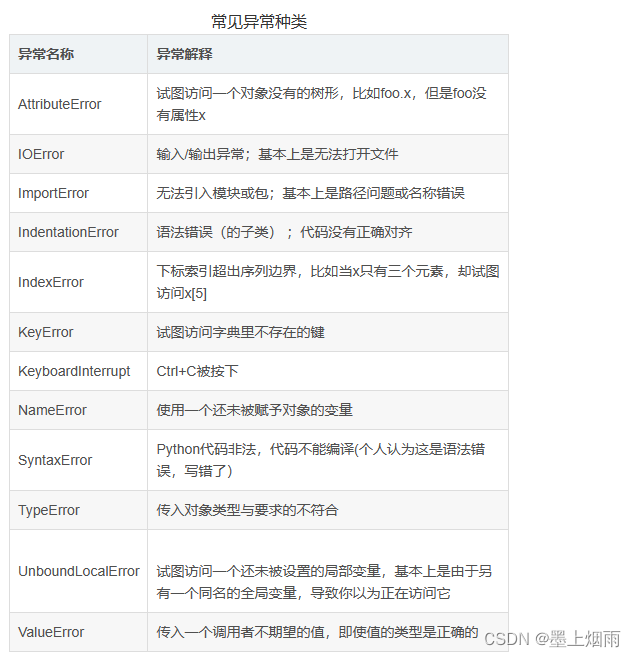
3.4、爬虫技术
实现现原理,爬虫技术的原理是是通过定时向HTTP来发送获取信息的请求来获取信息,通过获取 不同页面的内容来通过JSOUP进行爬取数据的解析,来找到被爬取页面的数据,并且分析得到想要得到的关键信息内容。
使用技术,爬虫技术主要是使用了java、python以及MySQL来进行程序的设计的,通过三种技术的 结合最终可以实现爬虫的功能。
四、系统设计
4.1、系统应用架构设计
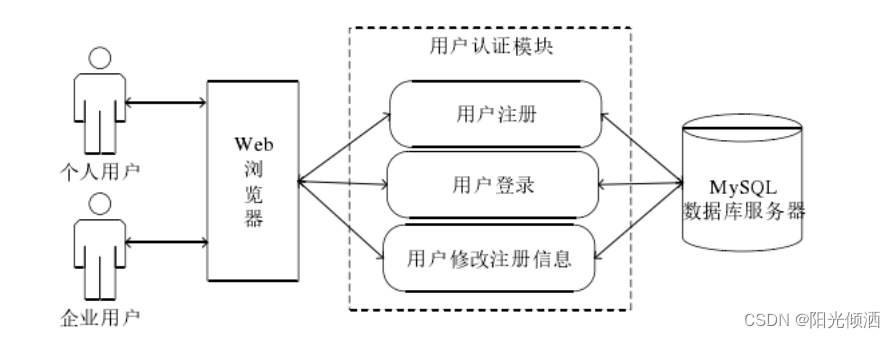
4.2、系统总体功能设计
此次的总体设计包括了网站的设计,在网站的设计中运用了django来进行内容设计工作。通过python进行爬虫的设计以及反爬虫的设计,整体的设计最终的目的是达到完成反爬虫功能。
五、功能截图
5.1、核心功能模块设计与实现
5.1.1模块实现
通过此次的开发设计最终可以正常进行爬虫操作,当此次爬取天气信息时,可以看到,爬虫程序能够爬取到近十天的天气信息,并且能够很好的进行信息的展示,当爬取新闻信息时,也能够正常的爬取到相关的新闻资讯内容,具体如下图所示:
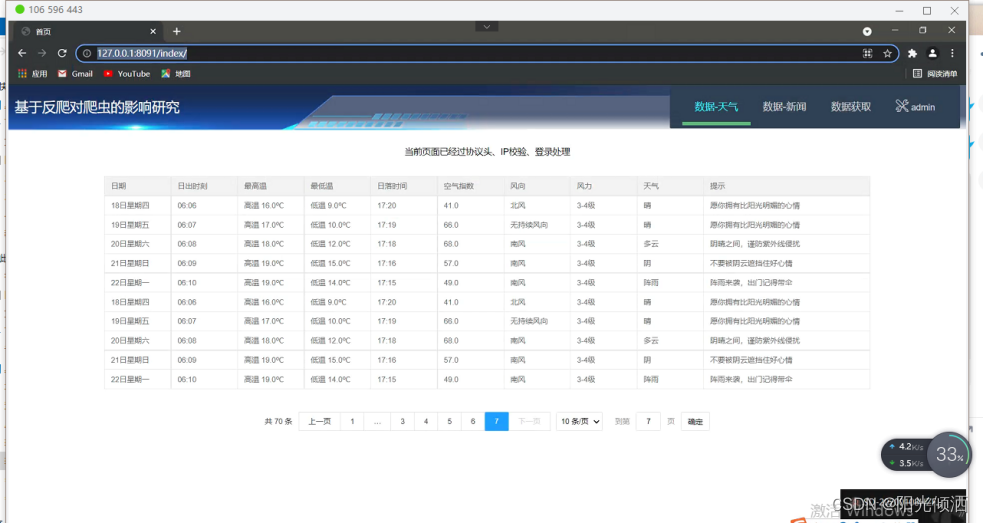
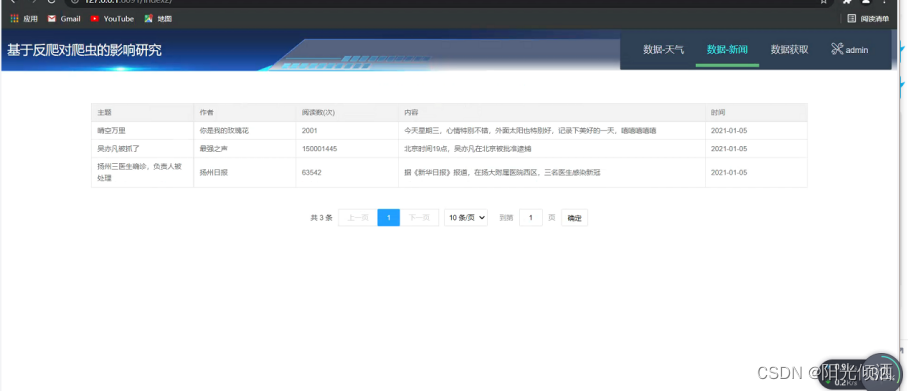
图5.1爬取数据图
当加入了反爬虫的程序之后,在此通过爬虫进行数据的爬取,以天气为例,在第二次爬取时,天气数据已无法进行爬取,但新闻信息仍然可以获取,在保证天气数据反爬虫成功后,在此对信息数据进行反爬虫的设计,最终使得天气、新闻等等信息都完全实现反爬操作。最终实现的反爬虫结果界面如下:
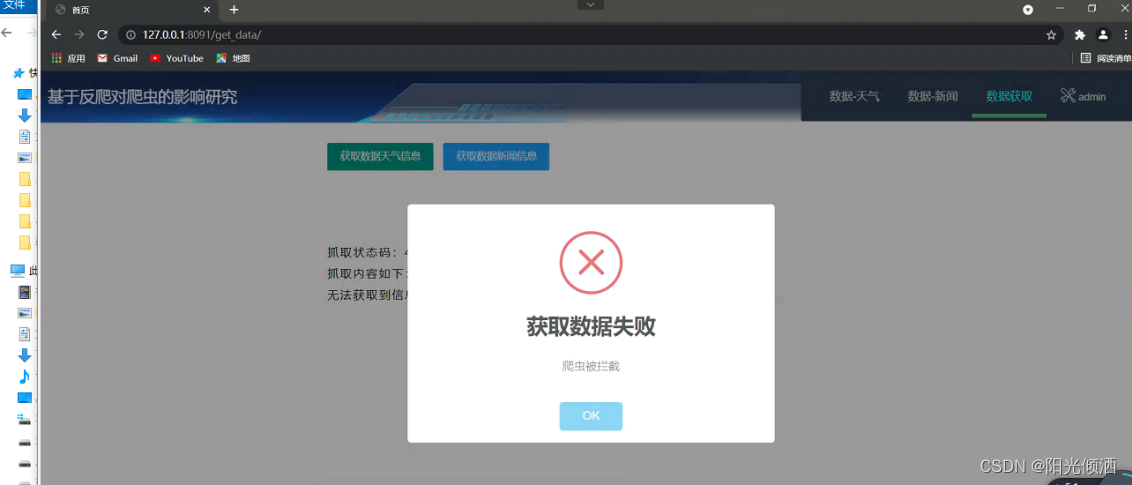
图5.2反爬虫结果图
这里功能太多,就不一一展示了
六、数据库设计
在此次的系统以及爬虫程序的设计过程中均需要用到数据库。网站的搭建不用多说,所以的信息内容均需要数据库进行处理,而此次设计的爬虫程序中也需要对通过爬虫来存储数据,因此此次的数据库是设计的关键内容。
6.1、关系型数据表设计
此次的数据库表设计主要是以简单的网站内容进行设计的,包括了管理员的设定以及信息的设定,具体的展示如下。
1.管理员信息表
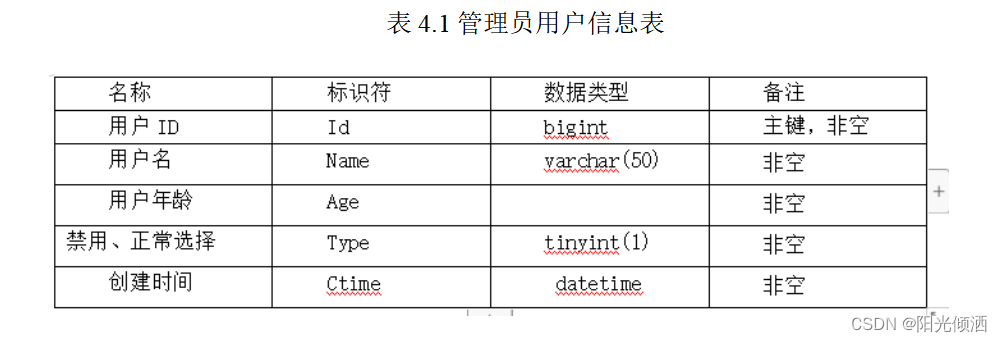
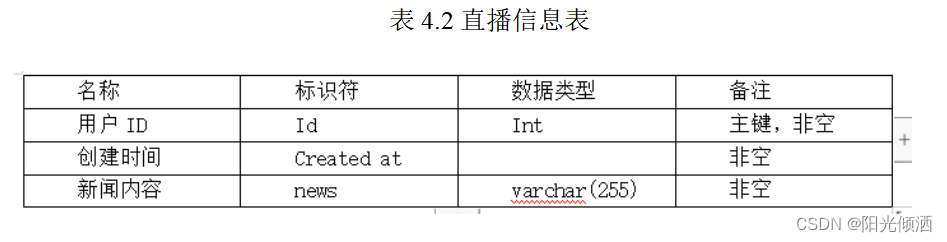
2.新闻信息表
七、结论
网络虽然是一个虚拟的世界,但是大量的信息也是需要被存储在相应的服务器里的,当用户进行访问时,由于访问的时间不同,同一时间访问的人数不同,数据库、服务器都能够提供很好的支撑服务。但是随着网络爬虫的发展,爬虫会模拟人们的IP、访问习惯去高频次的对网站进行访问,这样会对网站的服务器造成很大的伤害,如果爬虫数量少,服务器还能够承担这些访问压力,而一旦爬虫数量增加,则相应的服务器的压力就是非常大,这样对于网站的运营来说是灾难性的,因为这些爬虫一不会带来任何有利的信息,二还会大量的侵占网络资源,并且在网络上上传递着很多重复的信息内容,这些重复的信息增加了浏览用户的选择难度,让网络垃圾更加横行,也增加了网络运行的负担,这些都是网络发展所带来的一些弊端。
八、源码获取
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java项目精品实战案例(300套)
Java+小程序项目实战(200套)
Python项目精品实战案例(100套)









![[数字图像处理]第六章 彩色图像处理](https://img-blog.csdnimg.cn/ffabb3df109c4422ba6f5447423562c6.png)