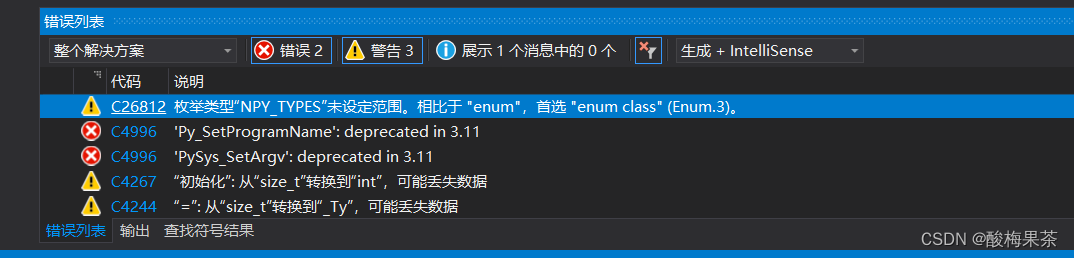
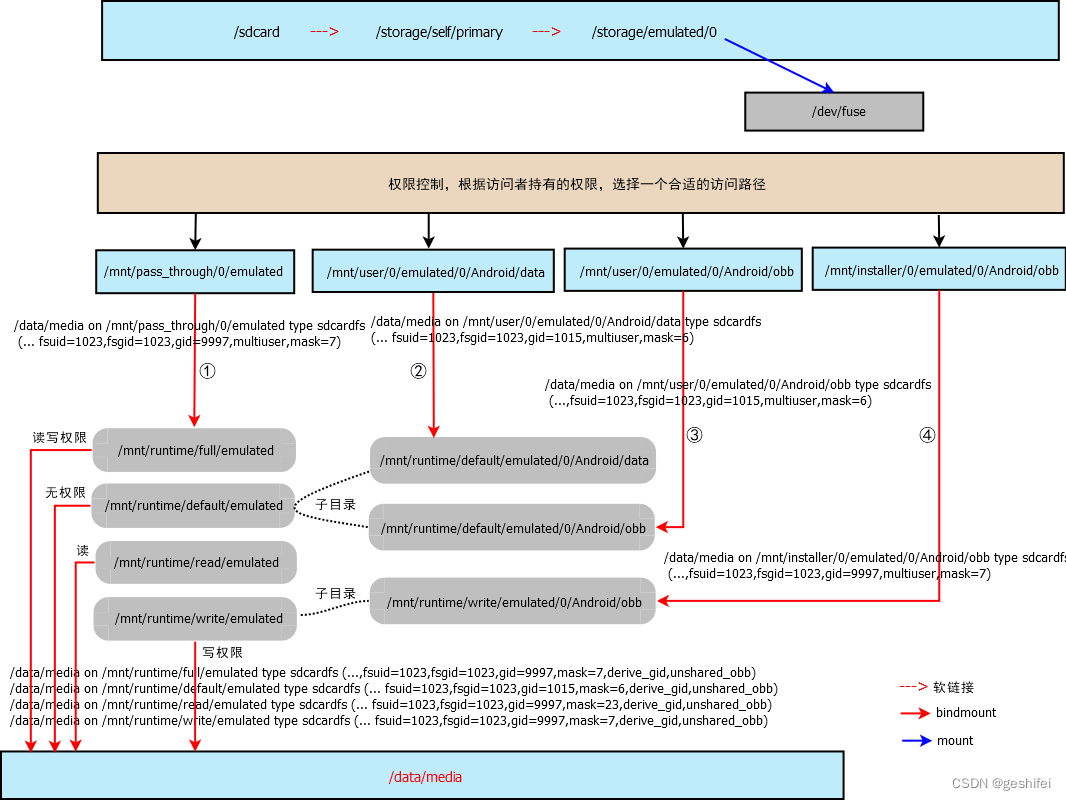
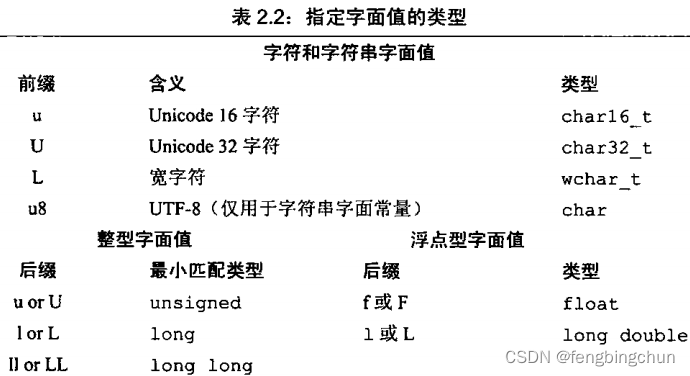
[0123456789] 普通字符
[0-9]简洁写法
在正则表达式中所有字符类型都有对应的编码
在匹配大写英文字母时,应该是
“”"
[a-zA-Z]或[A-Za-z]
“”"
元字符…
…
(.[0-9]{1,3}){3}进行重复三次操作
^\d{9}$
使用^和$匹配开始和结束位置,\d表示匹配数字,{9}表示要匹配的数字位数为9
引入模块re
import re
compile方法
re.compile(pattern[,flag])
pattern字符串形式的正则表达式
flag可选参数表示匹配模式.比如忽略大小写、多行模式等
re.I 忽略大小写匹配。比如即使使用表达式[A-Z],也不会匹配英文小写字母
re.M 多行模式,会改变^和 的 匹 配 方 式 。 匹 配 字 符 串 的 开 始 和 每 一 行 的 开 始 ( 换 行 符 后 面 紧 跟 的 字 符 ) 。 的匹配方式。^匹配字符串的开始和每一行的开始(换行符后面紧跟的字符)。 的匹配方式。匹配字符串的开始和每一行的开始(换行符后面紧跟的字符)。匹配字符串结尾的每一行的结尾(换行符前面那个字符)
re.S 点(.)任意匹配模式,会改变.的匹配方式,可以匹配任意字符,包括换行符。
re.X 详细模式,该模式下的正则表达式可以是多行的,也可以添加注释。空白符号会被忽略
re.compile() 方法生成的是一个正则表达式的对象,通过compile()方法获取pattern对象的示例如下。该方法传入的是一个正则表达式
pattern = re.compile(r"\w+")
下面示例在compile方法中通过三个引号编写多行的字符串形式的正则表达式,匹配模式指定为re.X
pattern = re.compile(r"\d+#匹配数字的整数部分" “\n”
r".#匹配数字的小数点" “\n”
r"\d* #匹配数字的小数部分", re.X)
match方法
match(patter,string,flags)
pattern1 = re.compile(r"\w+")
result = pattern1.match(“life is short”)
print(result)
下面呢匹配是否以Py开头,且不区分大小写
pattern2 = r"Py\w+"
str = ‘python or Python’
result1 = re.match(pattern2, str, re.I)
print(result1)
在不区分字符串python or Python中Python符合要求,也不会进行匹配,因为match()方法只会匹配要求的第一个对象后返回结果
search方法
进行大小写区分的比配
patxt = r"Py\w+"
str1 = ‘我是python or Python’
resul = re.search(patxt, str1)
print(resul)
下面通过正则表达式检查文本中是否有危险发言
prtxt = r’(攻击)(窃听)(监听)’
text = ‘计算机网络管理员时刻保障服务器安全’
relus = re.search(prtxt, text)
if relus == None:
print(text, ‘--------安全’)
else:
print(text, ‘-------检测到危险发言’)
如果更改代码
prtxt = r’(攻击)|(窃听)|(监听)’
text = ‘计算机网络管理员时刻保障服务器安全,窃听,监听,攻击’
relus = re.search(prtxt, text)
if relus == None:
print(text, ‘--------安全’)
else:
print(text, ‘-------检测到危险发言’)
总代码如下:


谢谢观看,制作不易,不喜勿喷
如果喜欢,请点赞加关注哟
小白们,可以照着敲一遍哈