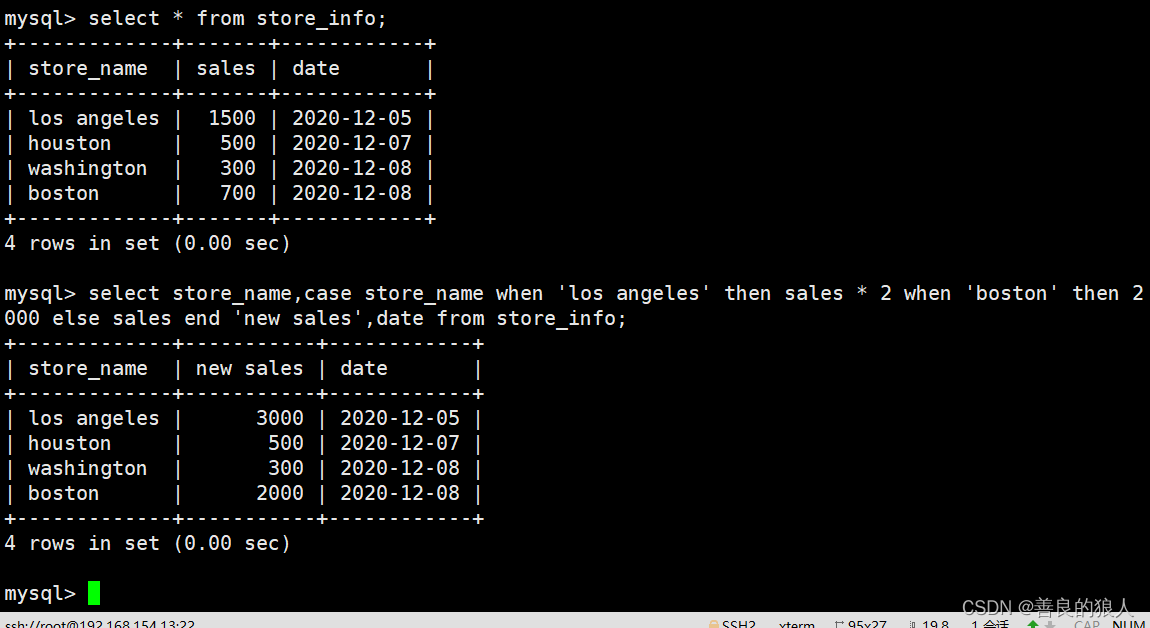
一个形如42的值被称作字面值常量(literal),这样的值一望而知。每个字面值常量都对应一种数据类型,字面值常量的形式和值决定了它的数据类型。
由单引号括起来的一个字符称为char型字面值,双引号括起来的零个或多个字符则构成字符串型字面值。
字符串字面值的类型实际上是由常量字符构成的数组(array)。编译期在每个字符串的结尾处添加一个空字符(‘\0’),因此,字符串字面值的实际长度要比它的内容多1。例如,字面值’A’表示的就是单独的字符A,而字符串”A”则代表了一个字符的数组,该数组包含两个字符:一个是字母A,另一个是空字符。
如果两个字符串字面值位置紧邻且仅由空格、缩进和换行符分隔,则它们实际上是一个整体。当书写的字符串字面值比较长,写在一行里不太合适时,就可以采取分开书写的方式。
有两类字符不能直接使用:一类是不可打印(nonprintable)的字符,如退格或其它控制字符,因为它们没有可视的图符;另一类是在C++语言中有特殊含义的字符(单引号、双引号、问号、反斜线)。在这些情况下需要用到转义序列(escape sequence),转义序列均以分斜线作为开始,C++语言规定的转义序列包括如下图所示:在程序中,下述转义序列被当作一个字符使用

我们也可以使用泛化的转义序列,其形式是\x后紧跟1个或多个十六进制数字,或者\后紧跟1个、2个或3个八进制数字,其中数字部分表示的是字符对应的数值。
注:如果反斜线\后面跟着的八进制数字超过3个,只有前3个数字与\构成转义序列。相反,\x要用到后面跟着的所有数字。因为大多数机器的char型数据占8位,超过8位的可能会报错。
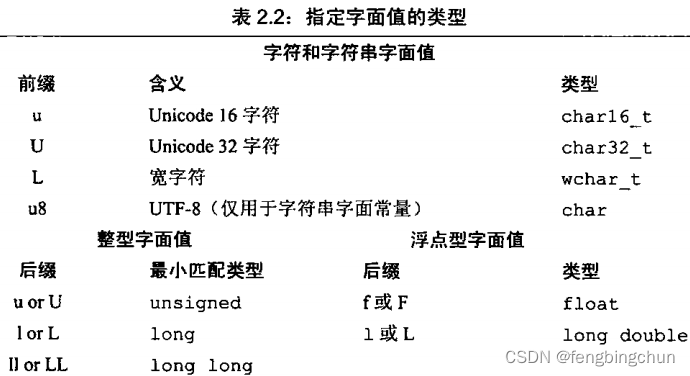
指定字面值的类型列表如下:
注:以上内容主要整理自《C++ Primer(Fifth Edition)》
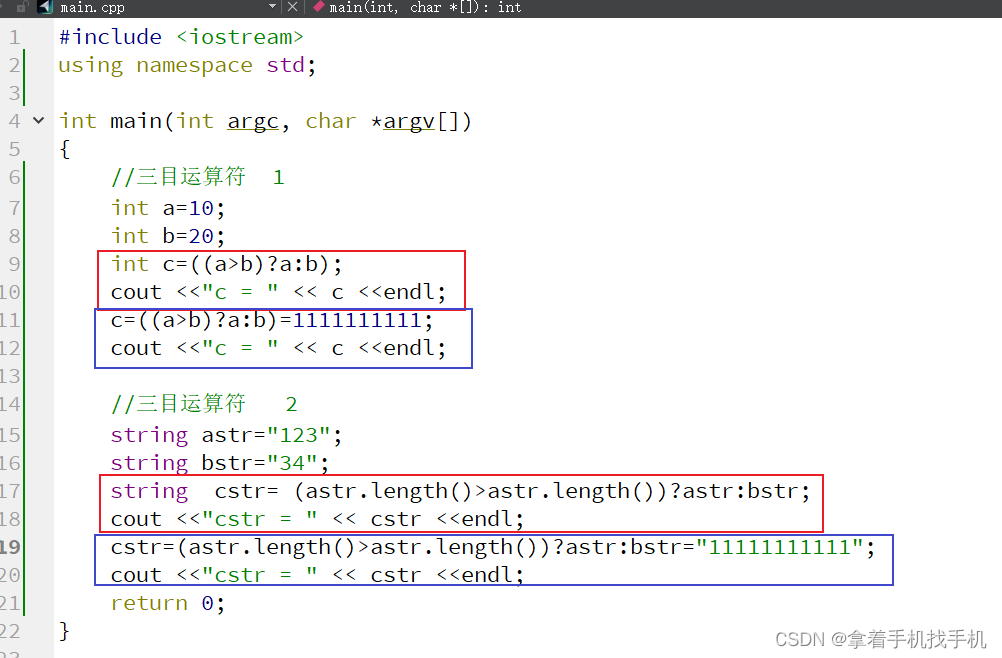
测试代码如下所示:
int test_literal_2()
{
char c = 'a'; // 字符字面值
char str[] = "hello world"; // 字符串字面值
std::cout << "csdn address: "
"https://blog.csdn.net/fengbingchun/; "
"github address: "
"https://github.com/fengbingchun"<< std::endl;
std::cout << "\12" << "\0" << "\115" << "\40" << "\x4d" << "\n";
std::cout << "Hi \x4dO\115!\n"; // Hi MOM!
std::cout << "\1154\n"; // M4
//std::cout << "\x1234\n"; // error C2022: “4660”: 对字符来说太大
auto x1 = L'a'; // 宽字符型字面值,类型是wchar_t
auto x2 = u8"Hi"; // utf-8字符串字面值(utf-8用8位编码一个Unicode字符)
auto x3 = U"Bei";
std::cout << "x1 type:" << typeid(x1).name()
<< ", x2 type:" << typeid(x2).name()
<< ", x3 type:" << typeid(x3).name() << "\n"; // x1 type:wchar_t, x2 type:char const * __ptr64, x3 type:char32_t const * __ptr64
return 0;
}在C++17中增加了以u8开头的字符字面值(character literal),在以前的C++版本中,字符字面值的可用选择仅限于相对较小的ASCII字符集,C++17中支持的字符字面值涵盖了所有可用的Unicode字符。
字符串字面值的编码前缀(encoding-prefixes)有五种:none, L, u8, u, U,但在C++17之前,字符字面值的编码前缀有四种:none, L, u, U,缺少u8。
为了通过字符字面值表示Unicode字符,可以使用转义序列\u连接字符代码的十六进制表示,也可以使用转义序列\U。
在字符字面值和本机(native)字符串字面值中,任何字符都可以用通用字符名(universal character name)表示。通用字符名由前缀\U后跟八位Unicode码组成,或者由前缀\u后跟四位Unicode码组成。必须分别提供所有八位或四位数字,才能形成格式正确的通用字符名。
测试代码如下所示:
int test_literal_17_1()
{
char c1 = u8'A'; // C++17
char c2[2] = u8"A";
char u1 = 'A'; // 'A'
char u2 = '\101'; // octal, 'A'
char u3 = '\x41'; // hexadecimal, 'A'
char u4 = '\u0041'; // \u UCN 'A'
char u5 = '\U00000041'; // \U UCN 'A'
return 0;
}GitHub:https://github.com/fengbingchun/Messy_Test