分类目录:《深入理解深度学习》总目录
《深入理解深度学习——Transformer》系列文章介绍了Transformer,该模型最初被用于机器翻译任务,其出色表现引起了学术界的极大兴趣,其优异的特征提取与语义抽象能力得到了学者的广泛认可,于是研究人员纷纷采用Transformer作为特征提取器,推出了新一代性能更优的预训练语言模型。在自然语言处理领域,最重要的预训练语言模型可以分为两个系列,一个是擅长自然语言生成任务的GPT(Generative Pre-Trained Transformer)系列模型,另一个是擅长自然语言理解任务的BERT(Bidirectional Encoder Representations from Transformers)模型。
GPT是OpenAI在论文《Improving Language Understanding by Generative Pre-Training》中提出的生成式预训练语言模型。该模型的核心思想是通过二段式的训练,以通用语言模型加微调训练的模式完成各项定制任务,即先通过大量无标签的文本训练通用的生成式语言模型,再根据具体的自然语言处理任务,利用标签数据做微调训练。这样一来,GPT就可以很好地完成若干下游任务,包括分类、蕴含、相似度、多选等。对使用者来说,直接使用训练好的模型参数作为初始状态,用少量标签数据进行微调,就可以得到针对特定领域与任务的高性能专用模型,不仅节省了训练成本,还大幅提高了模型的表现性能,而这也是预训练语言模型的魅力所在。在多个下游任务中,微调后的GPT系列模型的性能均超过了当时针对特定任务训练的SOTA模型,真正达到了“一法通,万法通”的境界。
GPT的结构:基于Transformer Decoder
GPT在无监督训练阶段,依然采用标准的语言模型,即给定无标签的词汇集合
u
=
{
u
1
,
u
2
,
⋯
,
u
n
}
u=\{u_1, u_2, \cdots, u_n\}
u={u1,u2,⋯,un},最大化以下似然函数:
L
1
(
u
)
=
∑
i
log
P
(
u
i
∣
u
i
−
k
,
u
i
−
k
+
1
,
⋯
,
u
i
−
1
;
Θ
)
L_1(u)=\sum_i\log P(u_i | u_{i-k}, u_{i-k+1}, \cdots, u_{i-1};\Theta)
L1(u)=i∑logP(ui∣ui−k,ui−k+1,⋯,ui−1;Θ)
其中,
k
k
k是上下文窗口的大小。在模型结构上,GPT选择了Transformer Decoder作为其主要组成部分。如下图所示,GPT由12层Transformer Decoder的变体组成,称其为变体,是因为与原始的Transformer Decoder相比,GPT所用的结构删除了Encoder-Decoder Attention层,只保留了Masked Multi-Head Attention层和Feed Forward层。GPT如此设计结构是合乎情理的。Transformer结构提出之始便用于机器翻译任务,机器翻译是一个序列到序列的任务,因此Transformer设计了Encoder用于提取源端语言的语义特征,而用Decoder提取目标端语言的语义特征,并生成相对应的译文。GPT的目标是服务于单序列文本的生成式任务,所以舍弃了关于Encoder的一切,包括Decoder中的Encoder-Decoder Attention层。GPT选择Decoder也因为其具有文本生成能力,且符合标准语言模型的因果性要求。
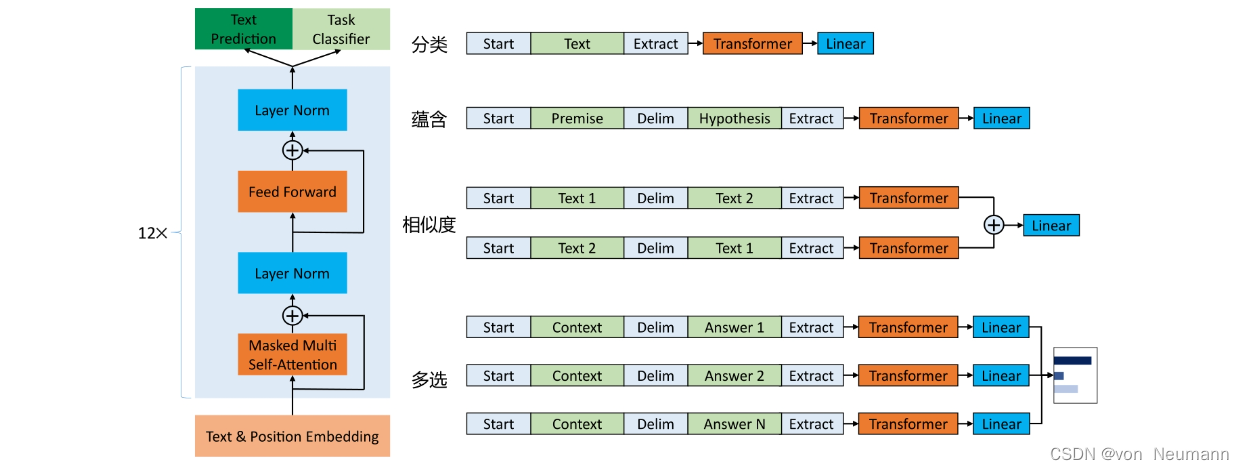
GPT保留了Decoder中的Masked Multi-Head Attention层和Feed Forward层,并扩大了网络的规模。除了将层数从6层扩展到12层,GPT还将Attention的维数扩大到768(原来为512),将Attention的头数增加到12(原来为8),将Feed Forward层的隐层维数增加到3072(原来为2048),总参数量达到1.5亿。GPT还优化了学习率预热算法,使用更大的BPE码表(融合次数为40000),将激活函数ReLU改为对梯度更新更友好的高斯误差线性单元GeLU,并将原始的正余弦构造的位置编码改成了待学习的位置编码(与模型其余部分一样,在训练过程中学习参数)。整体来说,GPT并没有提出结构上更新颖的改动,而是以Transformer Decoder为蓝本,搭建了语言模型的骨架,称为Transformer Block,扩大了模型的复杂度并更新了相应的训练参数。GPT的结构清晰,数据流如下:
- 输入语句的前 k k k个词通过词表转化为一维向量 U = { u − k , u − k + 1 , ⋯ , u − 1 , } U=\{u_{-k}, u_{-k+1}, \cdots, u_{-1}, \} U={u−k,u−k+1,⋯,u−1,}
- 输入 U U U右乘权重矩阵 W e W_e We和 W p W_p Wp(上图中的Text&Position Embedding模块,对应词向量编码和位置编码模块)转化为特征向量 h 0 h_0 h0: h 0 = U W e + W p h_0=UW_e+W_p h0=UWe+Wp
- 经过12层Transformer Block,最终的语义特征向量 h n h_n hn( n = 12 n=12 n=12)的计算公式为: h l = Tansformer_Block ( h l = 1 ) h_l=\text{Tansformer\_Block}(h_{l=1}) hl=Tansformer_Block(hl=1)
- Softmax输出下一个词 u u u的概率为: P ( u ) = Softmax ( h n W e T ) P(u)=\text{Softmax}(h_nW^T_e) P(u)=Softmax(hnWeT)
以上为无监督训练阶段语言模型的数据流,此阶段利用
L
1
L_1
L1似然函数作为优化目标训练语言模型。在监督微调阶段,GPT采用附加的线性输出层作为针对不同任务的自适应层(每个自适应层都是并列关系,各自拥有独立的权重矩阵
W
y
W_y
Wy,需要根据特定任务微调训练)。假定有带标签的数据集
C
C
C,其中每个实例由一系列输入词
x
1
,
x
2
,
⋯
,
x
m
x_1, x_2, \cdots, x_m
x1,x2,⋯,xm和标签
y
y
y组成。通过预训练的GPT先将输入转化成语义特征
h
l
m
h_l^m
hlm(下标
l
l
l表示层数,上标
m
m
m表示输入
x
m
x_m
xm对应的语义特征),再经过任务特定的线性输出层预测
y
y
y:
P
(
y
∣
x
1
,
x
2
,
⋯
,
x
m
)
=
Softmax
(
h
i
m
W
y
)
P(y|x^1, x^2, \cdots, x^m)=\text{Softmax}(h_i^mW_y)
P(y∣x1,x2,⋯,xm)=Softmax(himWy)
而需要优化的目标函数也变为:
L
2
=
∑
x
,
y
log
P
(
y
∣
x
1
,
x
2
,
⋯
,
x
m
)
L_2=\sum_{x, y}\log P(y|x^1, x^2, \cdots, x^m)
L2=x,y∑logP(y∣x1,x2,⋯,xm)
为了使微调训练后的模型有更好的泛化性能,在监督微调的优化目标函数中加入辅助优化函数是一个已被验证可行的方法,而且可以加速模型的微调收敛。在监督微调训练阶段,GPT使用的优化目标函数为:
L
3
(
C
)
=
L
2
(
C
)
+
λ
L
1
(
C
)
L_3(C) = L_2(C)+\lambda L_1(C)
L3(C)=L2(C)+λL1(C)
其中, L 1 L_1 L1是无监督训练阶段的目标函数, λ \lambda λ是辅助函数的权重常系数。总体来说,在GPT监督微调训练阶段,需要训练的最主要的额外权重矩阵就是 W y W_y Wy。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.