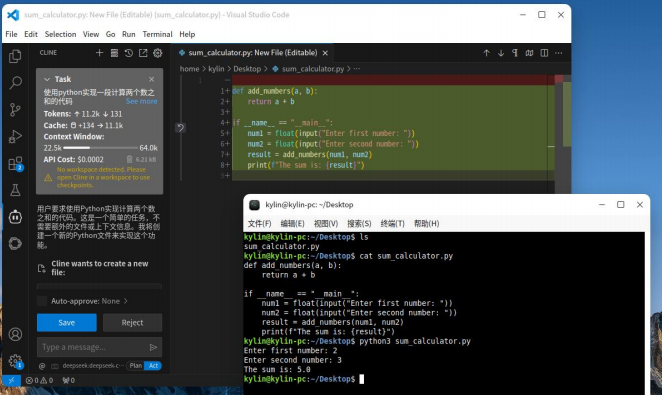
前言
双指针
唯一的雪花 Unique Snowflakes
#include<iostream>
#include<unordered_map>
using namespace std;
//这道题的意思就是在一个数组找一个最大的1区间的长度,这个区间里面没有重复数据
//如果暴力解法,每次求出以a[i]开头的满足条件的数组长度的话,时间复杂度就很高
//我们采取滑动窗口
//left,right,map记录每个的次数
//unordered_map<int,int> 第一个int存的是值,第二个存的是这个值的数量
//当right的数量大于2时,left++,还大于2,就继续加加
//小于2时,right就加加,每一次right加加都要更新最大长度
//left加加一定不是最长的
const int N = 1e6 + 10;
long long arr[N] = { 0 };
int main() {
int T = 0;
cin >> T;
while (T--) {
int n = 0;
cin >> n;
for (int i = 1; i <= n; i++) cin >> arr[i];
int left = 1;
int right = 1;
unordered_map<int, int> map;
int ret = 0;
while (right <= n) {
map[arr[right]]++;
while (map[arr[right]] > 1) {
map[arr[left]]--;
left++;
}
ret = max(ret, right - left + 1);
right++;
}
cout << ret;
}
return 0;
}
离散化
火烧赤壁
火烧赤壁
#include<iostream>
#include<algorithm>
#include<unordered_map>
using namespace std;
//离散化适用于数据范围大,数据量少的,比如这样,n<2*10^4,a<2^32
//1,5,8,3,4,5,,9,5,把这些数按照从小到大的顺序离散化,1-》1,3-》2,4-》3,5-》4,8-》5,9-》6,,,,离散化之后,数据范围就不大了
//离散化的数据不能重复,所以可以先排序,在去重,然后再定义出离散化后的值,就用unordered_map<int,int> 第一个int是数值,第二个int是这个数值的离散化后的值
//
//
//const int N = 1e4 + 10;
//
//int a[N];//源数组--》不然无法根据原数组,打印出离散值了
//int b[N];//用来处理的数组
//
//int n1;//离散化前的数字个数
//int n2;//离散化后的数字个数
//
//int main() {
// cin >> n1;
// for (int i = 1; i <= n1; i++) {
// cin >> a[i];
// b[i] = a[i];
// }
// sort(b + 1, b+ 1 + n1);
// n2=unique(b + 1, b + 1 + n1)-(b+1);//unique这个函数是把这个左闭右开的区间进行去重的,返回去重后数组的最后一个位置,这样地址一减,就是最后的个数了
// unordered_map<int, int> map;
// for (int i = 1; i <= n2;i++) {
// //开始离散化,,,,,
// map[b[i]] = i;//这样就可以了
// }
// //打印出每个原数组的值对应的离散值
// for (int i = 1; i <= n1; i++) {
// cout << map[a[i]] << " ";
// }
// return 0;
//}
//这道题呢,相当于有一个很大的区间格子,比如-1 1时,就相当于把-1 1这个区间里面的-1,0格子涂上(+1),因为这个区间是左闭右开的,相当于整个区间+1,所以我们可以用差分的思想
//最后可以求出格子值大于1的,大于1的就是着火的地方,但是这个区间可能很大很大,所以我们要先把这个区间给离散化
const int N = 2e4 + 10;
int a1[N];//存储左区间
int b1[N];//存储右区间
int tmp[2 * N];//用来处理的,一个数组来处理
int n1;//离散化前的数字个数
int n2=0;//离散化后的数字个数
//int used[2 * N];//着火区间---->可以直接用gap差值区间转化而来
int gap[2 * N];//差值数组,因为差值数组是对tmp数组进行的处理,所以很大
int main() {
cin >> n1;
for (int i = 1; i <= n1; i++) {
cin >> a1[i]>>b1[i];
tmp[++n2] = a1[i];
tmp[++n2] = b1[i];//全部存在这个数组中,因为存在两个数组中,肯定会有值重复的
}
sort(tmp+1,tmp+1+n2);
n2=unique(tmp + 1, tmp + 1 + n2) - (tmp + 1);
unordered_map<int, int> map;
for (int i = 1; i <= n2;i++) {
map[tmp[i]] = i;
}
//gap默认为0,因为着火区间一开始每个格子都是0
//如果这个区间[n,m)着火了,这个着火区间的格子加1,那么对应差值数组gap[n]+1,gap[m]-1,,,,,,,这个n和m都是离散值,但是区间的对应又要利用上a和b数组
for (int i = 1; i <= n1; i++) {
gap[map[a1[i]]]++;
gap[map[b1[i]]]--;
}
//这样就求出了差值数组
//然后就可以求出着火区间了---->下标最大为n2
for (int i = 1; i <= n2; i++) {
gap[i] += gap[i-1];
}
//遍历着火区间,大于0的就是着火的地方
int count = 0;//存储着火的地方
for (int i = 1; i <= n2; i++) {
if (gap[i] > 0) {
//直接找到下一个gap[j]=0的地方,就是停火的区间
int j = i;
while (gap[j] > 0)j++;
//所以着火区间就是[i,j)但是这个是离散值,我们还要对应回去,离散值就是tmp的下标,所以很容易对应回去
count = count+(tmp[j] - tmp[i]);
i = j;//因为这个区间已经处理完了
}
}
cout << count;
return 0;
}
递归
汉诺塔问题
汉诺塔问题
#include<iostream>
using namespace std;
//子问题和父问题处理一样的话,就可以用递归的思想,函数你就相信它一定能成功,然后还要有一个停止的条件就是了
int n;
char a, b, c;
void dis(int n, char a, char b, char c) {
//我们可以先把n-1个盘子从a盘移到c盘上,借助b盘-----》这个可以用dis函数,因为处理的问题都是一样的
//然后把第n个盘子从a盘移到b盘,不用借助c盘了,,,,这个就是直接打印就可以实现了
//最后就是把剩下的n-1个盘子从c盘移到b盘,借助a盘,只有大于两个盘子的时候,才会借助多余的盘子
//截止条件就是只有零个盘子的时候,直接return,一个盘子都可以调用这个函数-->直接假设进去,看行不行
if (n == 0)return;
dis(n - 1, a, c, b);
printf("%c->%d->%c\n",a,n,b);
dis(n - 1, c, b, a);
}
int main() {
cin >> n >> a >> b >> c;
dis(n, a, b, c);//这个函数的作用就是把n个盘子把a移到b上,然后借助c
return 0;
}
分治
逆序对
逆序对
#include<iostream>
using namespace std;
//面对这道题我们先来回顾一下归并排序,所谓归并排序的话,就是一个函数具有排序功能,先排序左区间,然后排序右区间,最后把这左右区间合并排序
typedef long long ll;
const int N = 5e5 + 10;
//1 3 4 6 9 2 5 7 9 10 举个例子更好书写
ll a[N];//要排序的数组
ll tmp[N];//用来辅助a数组排序的数组------->用来暂时存着两个区间有序合并后的结果,最后赋值给a就可以了
ll n;
//void merge(int left, int right) {
// //递归终止条件
// if (left >= right)return;//这个不用排序,只要left<right就要排序,就可以调用merge函数
// int mid = (left + right) / 2;
// merge(left, mid);
// merge(mid+1,right);
// //默认merge已经分别实现了a的两个分区间的排序,然后我们只需要把这两个已经排好序的区间合并就可以了
// int cur1 = left;//指向左区间的指针
// int cur2 = mid+1;//指向右区间的指针
// int i = left;//用来指向tmp数组的指针
// while (cur1 <= mid&&cur2<=right) {
// if (a[cur1] >= a[cur2]) tmp[i++] = a[cur2++];
// else tmp[i++] = a[cur1++];
// }
// while (cur1 <= mid) tmp[i++] = a[cur1++];
// while (cur2 <= right) tmp[i++] = a[cur2++];
// //这样我们的tmp数组就是有序的了--->全部赋值给a数组就可以了
// for (int j = left; j <= right; j++) a[j] = tmp[j];
//}
//int main() {
// cin >> n;
// for (int i = 1; i <= n; i++) cin >> a[i];
// cout << endl;
// merge(1, n);
// for (int i = 1; i <= n; i++) cout << a[i] << " ";
// cout << endl;
// return 0;
//}
//处理这道题的话,可以这样来,我们先计算出左半区间的逆序对个数,然后就是计算出右半区间的逆序对个数,然后是左右区间综合起来的逆序对个数,如果左右区间都是有序的话---》边排序边计算
//那么综合起来的逆序对个数就很好求了,所以可以这样来
//merge的作用是求出左区间的逆序对个数,然后对左区间进行排好序
//右区间也是如此
//因为个数可能是n^2级别的,所以我们用ll来返回,不然会存不下的,统一用大的ll,不要用int,防止出错
ll merge(int left, int right) {
if (left >= right)return 0;
int mid = (left + right) / 2;
ll ret = 0;
ret+=merge(left, mid);//默认可以求出左区间的逆序对个数,然后对左区间就排好序了---->排序和求个数的递归
ret+=merge(mid + 1, right);默认可以求出右区间的逆序对个数,然后对右区间就排好序了
//现在就是求出左右区间综合起来的逆序对个数,然后拍好整个区间的序,因为merge(int left, int right)的作用就是求出总的逆序对个数--》左右的+综合的,然后拍好序--》左右的+综合的
//这个我们只需要在原来的归并排序基础上修改就可以了
int cur1 = left;
int cur2 = mid + 1;
int i = left;
while (cur1 <= mid && cur2 <= right) {
if (a[cur1] > a[cur2]) {
//那么cur2就会匹配上cur1对应及其后面的逆序对,都是可以匹配的
ret += mid - cur1 + 1;//这个+1我们假设mid和cur1相邻就可以判断出了
tmp[i++] = a[cur2++];
}
else tmp[i++] = a[cur1++];
}
while (cur1 <= mid) tmp[i++] = a[cur1++];
while (cur2 <= right) tmp[i++] = a[cur2++];
//这样我们的tmp数组就是有序的了--->全部赋值给a数组就可以了
for (int j = left; j <= right; j++) a[j] = tmp[j];
return ret;
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i];
cout << merge(1, n);
return 0;
}
搜索
枚举子集(递归实现指数型枚举)
枚举子集(递归实现指数型枚举)
#include<iostream>
using namespace std;
//搜索就是枚举,就是把问题的枚举转化为对树的枚举树的遍历,这个树叫做决策树,枚举又分为深度优先和宽度优先
//我们这个问题就可以看做为树的枚举,就是遍历树的叶子结点,我们先写普通树的叶子结点遍历
//void dfs(root) {
// if(为叶子)打印叶子
// dfs(left);
// dfs(right);
//}
//我们这样来做
string tmp;//代表进入左还是右子树,,,并且记录当前结点的值
int n;//代表进入第几层了---》tmp和n就可以决定遍历的当前位置了
//我们的这个决策树总共有四层,最后一层就是第四层就是叶子结点
//我们要遍历到叶子结点,就是对树的遍历--》深度优先遍历
void dfs(int depth) {
//结束条件
if (depth == (n + 1)) {
//打印叶子结点
cout << tmp<<endl;
return;
}
//左子树遍历
tmp += 'N';//代表进入左子树,,,因为dfs(left);的意思就是对左子树的遍历,它代表的意思就是先判断为左lset,然后进入dfs,然后出这个dfs时,我们还是处于root结点
//所以要保证dfs结束以后,还是在n=1的结点上,所以要去掉N
dfs(depth + 1);//代表处理深度为depth + 1时的叶子结点,此时tmp为N,刚刚好对应住了,带着tmp进入二层,
tmp.pop_back();//回到原来,不然还是左子树的if判断,相当于,这就叫回溯,tmp为null了,又对应住了
//右子树遍历
tmp += 'Y';
dfs(depth + 1);
tmp.pop_back();
//本结点遍历:不处理
}
int main() {
cin >> n;
dfs(1);//代表遍历到第一层,第一层的根,遍历这个树,就是对左右树的遍历、、处理深度为1的叶子结点====处理深度为2的左右子树的叶子结点
return 0;
}
组合型枚举
组合型枚举
#include<iostream>
#include<vector>
using namespace std;
int n, m;//从n个数中选m个
vector<int> path;
//void dfs(int pos, int start) {//这个pos和start的意思就是,下次插入这个结点的第pos位置,然后从最小start开始插入,
// if (pos == (m + 1)) {
// //说明下次插的这个结点早就满了满了
// for (auto x : path) {
// cout << x << " ";
// }
// cout << endl;
// return;
// }
// for (int i = start; i <= n; i++) {
// path.push_back(i);//插入i
// dfs(pos + 1, i+1);
// path.pop_back();//回溯
// }
//}
//int main() {
// cin >> n >> m;
// dfs(1, 1);
// return 0;
//}
//我们发现pos的作用只是记录我们下次要插入第几个位置,其实就是记录有没有插满m个而已,插满了的话,就不用插了,所以我们用path其实也是可以记录的
void dfs(int start) {
if (path.size() == m ) {
//说明下次插的这个结点早就满了满了
for (auto x : path) {
cout << x << " ";
}
cout << endl;
return;
}
for (int i = start; i <= n; i++) {
path.push_back(i);//插入i
dfs(i + 1);
path.pop_back();//回溯
}
}
int main() {
cin >> n >> m;
dfs(1);
return 0;
}
[NOIP 2002 普及组] 选数
[NOIP 2002 普及组] 选数
#include<iostream>
using namespace std;
const int N = 100;
int n, m;
int a[N];
int ret=0;//记录有多少个素数
int path=0;//记录叶子结点和
bool isprime(int x) {
if (x <= 1)return false;//因为1既不是素数,反正什么都不是
//判断一个数是不是素数,直接去除以2~根号x就可以了,如果全部不能整除的话,那么就是素数,,i<=x/i就是i小于根号x了,两边同时平方来的
//整除就是取模为0
for (int i = 2; i <= x / i; i++) {
if (x % i == 0) {
return false;
}
}
return true;
}
void dfs(int pos, int start) {
if(pos>m){
if (isprime(path)) ret++;
return;
}
for (int i = start; i <= n; i++) {
path += a[i];
dfs(pos + 1, i + 1);
path -= a[i];
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) cin >> a[i];//输入的是有序的
dfs(1, 1);//表示下一个就是插入第一个位置,从数组下标为1开始插,
cout << ret;
return 0;
}
数的划分
数的划分
#include<iostream>
using namespace std;
int n, k;
int path;
int ret;
void dfs(int pos, int start) {
if (pos == (k + 1)) {
if (path == n)ret ++ ;
return;
}
for (int i = start; i <= n; i++) {
if (path + i * (k - pos + 1) > n)return;
path += i;
dfs(pos + 1, i);
path -= i;
}
}
int main() {
cin >> n >> k;
dfs(1, 1);
cout << ret;
return 0;
}
斐波那契数
斐波那契数
class Solution {
public:
int path[256];
int dfs(int n) {
if (n == 0 || n == 1)return n;
if (path[n] != -1)return path[n];
path[n] = dfs(n - 1) + dfs(n - 2);
return path[n];
}
int fib(int n) {
//初始化数组
memset(path,-1,sizeof(path)); //memset是把起始位置path的后面的sizeof(path)个字节每个字符都设置为-1,因为-1的补码就是1111,所以数组每个元素就是-1,sizeof(path)求的是数组的长度
return dfs(n);
}
};
Function
Function
#include<iostream>
using namespace std;
#define ll long long
ll a1, b1, c1;
//因为再大的数也会变为0~20,所以数组不用很长
ll path[25][25][25];//用来做备忘录,默认都是0
ll dfs(ll a, ll b, ll c) {
if (a <= 0 || b <= 0 || c <= 0)return 1;
if (a > 20 || b > 20 || c > 20) {
path[20][20][20] = dfs(20, 20, 20);
return path[20][20][20];
}
if (path[a][b][c])return path[a][b][c];//说明已经做了备忘录了
//如果不为0,可能没有备忘录,也可能备忘了的,但是多一层而已,不关事
if (a < b && b < c) {
//先备忘
path[a][b][c] = dfs(a, b, c - 1) + dfs(a, b - 1, c - 1) - dfs(a, b - 1, c);
return path[a][b][c];
}
path[a][b][c] = dfs(a-1, b, c ) + dfs(a-1, b - 1, c ) + dfs(a-1, b, c-1)-dfs(a-1,b-1,c-1);
return path[a][b][c];
}
int main() {
while (1) {
cin >> a1 >> b1 >> c1;
if (a1 == -1 && b1 == -1 && c1 == -1) break;
printf("w(%lld, %lld, %lld) = %lld\n", a1, b1, c1, dfs(a1, b1, c1));
}
return 0;
}
马的遍历
马的遍历
#include<iostream>
//宽度搜索主要是解决最短路径问题的,而且每条路径的权值还得一样才行
//宽度搜索就要用队列了
#include<queue>
#include<cstring>//声明menset函数
using namespace std;
const int N = 410;
typedef pair<int, int> ll;//用来记录每个坐标的数据结构
int path[N][N];//用来记录最短路径
int n, m, x, y;
//以x,y作为原点,标出这个马可以跳到的其它点的横纵坐标
int lx[8] = { 1,2,2,1,-1,-2,-2,-1 };
int ly[8] = { 2,1,-1,-2,-2,-1,1,2 };
void bfs() {
//初始化最短路径,因为最短路径的最小值为0,所以我们初始化为-1
memset(path, -1, sizeof(path));
//一个点入队列,然后出队列时,又带入它可以跳到的点进入队列
queue<ll> q;
q.push({ x,y });
path[x][y] = 0;//初始化第一个点的步数
while (q.size()) {
auto point = q.front();//队列的第一个点的值
q.pop();//取出第一个点
int tmpx = point.first;//取出当前点的横坐标
int tmpy = point.second;//取出当前点的纵坐标
for (int i = 0; i < 8; i++) {
int insertx = tmpx + lx[i];
int inserty = tmpy + ly[i];//这个就是这个取出来的点要跳到的一个点的位置
if (insertx<1 || insertx>n || inserty<1 || inserty>m)continue;//说明越过棋盘了
if (path[insertx][inserty] != -1)continue;//说明被跳到过了
path[insertx][inserty] = path[tmpx][tmpy] + 1;//这里就是没有被跳到过了
q.push({ insertx,inserty });//插入队列
}
}
}
int main() {
cin >> n >> m >> x >> y;
bfs();
//输出最短路径
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cout << path[i][j] << " ";
}
if(i!=n)
cout << endl;
}
return 0;
}
矩阵距离
矩阵距离
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 1010;
int n, m;
char arr[N][N];//存储矩阵
int path[N][N];//输出的矩阵
int dx[4] = { 0,0,-1,1 };
int dy[4] = { 1,-1,0,0 };
void bfs() {
//求每个0到最近1的最短距离,就是求每个0到总体1的最近距离,那这样的话,就要对每个0进行bfs,时间复杂度很高,还不如对总体1bfs,直接一次bfs就OK了
memset(path, -1, sizeof(path));//因为总体1到1的最短距离就是0,所以不能初始化为0,初始化为-1,就代表这个点还没到达,但凡到达这个点的,都是第一名,都是最短的
//对总体1bfs的意思就是,一开始就把全部1插入队列,从一开始的全部1开始bfs,就是对总体1的dfs
queue<pair<int, int>> q;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (arr[i][j] == '1') {
q.push({ i,j });
path[i][j] = 0;
}
}
}
while (q.size()) {
auto tmp=q.front();
q.pop();
int x = tmp.first;
int y = tmp.second;
for (int i = 0; i < 4; i++) {
int a = x + dx[i];
int b = y + dy[i];
if (a >= 1 && a <= n && b >= 1 && b <= m && path[a][b] == -1) {
//第一次走到
path[a][b] = path[x][y] + 1;
q.push({ a,b });
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cin >> arr[i][j];
}
}
bfs();
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cout << path[i][j] <<" ";
}
cout << endl;
}
return 0;
}
Lake Counting
Lake Counting
#include<iostream>
#include<queue>
using namespace std;
const int N = 110;
int n, m;
char a[N][N];
bool path[N][N];//默认为flase,因为全是0
int ret = 0;
int dx[8] = { 0,0,1,-1,1,1,-1,-1 };
int dy[8] = { 1,-1,0,0,1,-1,1,-1 };
void dfs(int x,int y) {
path[x][y] = true;
for (int i = 0; i < 8; i++) {
int tmpx = x + dx[i];
int tmpy = y + dy[i];
if (tmpx >= 1 && tmpx <= n && tmpy >= 1 && tmpy <= m && a[tmpx][tmpy]=='W'&& path[tmpx][tmpy]==false) {
dfs(tmpx, tmpy);
}
}
}
void bfs(int x, int y) {
queue<pair<int, int >> q;
q.push({ x,y });
path[x][y] = true;
while (q.size()) {
auto point = q.front();
q.pop();
int x = point.first;
int y = point.second;
for (int i = 0; i < 8; i++) {
int tmpx = x + dx[i];
int tmpy = y + dy[i];
if (tmpx >= 1 && tmpx <= n && tmpy >= 1 && tmpy <= m && a[tmpx][tmpy] == 'W' && path[tmpx][tmpy] == false) {
path[tmpx][tmpy] = true;
q.push({ tmpx,tmpy });
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cin >> a[i][j];
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++) {
if (path[i][j])continue;//说明已经被划分为一个水坑了
else if(path[i][j]==false&&a[i][j]=='W') {
ret++;
//dfs(i, j);//将坐标为i,j的划分为一个水坑,还有它附近的
bfs(i, j);
}
}
cout << ret;
return 0;
}
单调栈
发射站
发射站
#include<iostream>
#include<stack>
using namespace std;
const int N = 1e6 + 10;
typedef long long ll;
int n;
ll h[N];
ll v[N];
ll path[N];//接收到的新的能量
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> h[i] >> v[i];
}
//单调递减栈
stack<int> s;
for (int i = 1; i <= n; i++) {
while (s.size() && h[s.top()] <= h[i])s.pop();//这个时候top就比i高了
if (s.size()) {
path[s.top()] += v[i];
}
s.push(i);
}
//清空栈,从右到左
while (s.size()) s.pop();
for (int i = n; i >= 1; i--) {
while (s.size() && h[s.top()] <= h[i])s.pop();//这个时候top就比i高了
if (s.size()) {
path[s.top()] += v[i];
}
s.push(i);
}
ll ret = 0;
for (int i = 1; i <= n; i++) {
ret = max(ret, path[i]);
}
cout << ret;
return 0;
}
单调队列
滑动窗口 /【模板】单调队列
滑动窗口 /【模板】单调队列
#include<iostream>
#include<deque>
using namespace std;
const int N = 1e6 + 10;
int n;
int k;
int arr[N];
int main() {
cin >> n >> k;
for (int i = 1; i <= n; i++) cin >> arr[i];
//找最小值的话,就维护一个从头到尾单调递增的队列
deque<int> d;;
for (int i = 1; i <= n; i++) {
while (d.size() && arr[d.back()] >= arr[i]) d.pop_back();
d.push_back(i);
if (i - d.front() + 1 > k)d.pop_front();//每次都会这样,所以最多长度超过一个,这样就不会太长了
if (i >= k) cout << arr[d.front()]<<" ";
}
cout << endl;
d.clear();//栈没有这个函数
//找最大值
for (int i = 1; i <= n; i++) {
while (d.size() && arr[d.back()] <= arr[i]) d.pop_back();
d.push_back(i);
//这个就是比单调栈多余的一个操作
if (d.size() && (i - d.front() + 1) > k)d.pop_front();
//这个是因为题意才这样干的
if (d.size()&&i>=k) cout <<arr[d.front()]<<" ";
}
return 0;
}
质量检测
质量检测
#include<iostream>
#include<deque>
using namespace std;
const int N = 1e6 + 10;
int n,m;
int arr[N];
int main() {
cin >> n >> m;
deque<int> d;
for (int i = 1; i <= n; i++) {
cin >> arr[i];
while (d.size() && arr[d.back()] >= arr[i]) d.pop_back();
d.push_back(i);
if (i - d.front() + 1 > m) d.pop_front();
if (i >= m)cout << arr[d.front()]<<endl;
}
return 0;
}
并查集
【模板】并查集
【模板】并查集
#include<iostream>
using namespace std;
const int N = 2e5 + 10;
int fa[N];//每个fa[x]代表x的父亲是fa[x]
int n,m;
int find(int x) {
//find的意思就是找x的祖先
if (fa[x] == x) {//它的父亲等于它自己
return x;
}
return fa[x] = find(fa[x]);//既然x不是祖先,那就找x的父亲的祖先,并将x的父亲设置为x的祖先,
}
int main() {
cin >> n>>m;
//初始化并查集
for (int i = 1; i <= n; i++)fa[i] = i;
while (m--) {
int z, x, y;
cin >> z >> x >> y;
if (z == 1) {
int fx = find(x);
int fy = find(y);
fa[fx] = fy;
}
else {
if (find(x) == find(y))cout << "Y" << endl;
else cout << "N" << endl;
}
}
return 0;
}
亲戚
亲戚
#include<iostream>
using namespace std;
const int N = 5010;
int n, m, p;
int fa[N];
int find(int x) {
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
bool issame(int x, int y) {
return find(x) == find(y);
}
void un(int x, int y) {
int a = find(x);
int b = find(y);
fa[a] = b;
}
int main() {
cin >> n >> m >> p;
for (int i = 1; i <= n; i++)fa[i] = i;
while (m--) {
int x, y;
cin >> x >> y;
un(x, y);
}
while (p--) {
int x, y; cin >> x >> y;
if (issame(x,y)) {
cout << "Yes" << endl;
}
else {
cout << "No" << endl;
}
}
return 0;
}
扩展域并查集
亲戚
亲戚
#include<iostream>
using namespace std;
const int N = 1010;
int fa[2 * N];
int n, m;
int find(int x) {
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
void un(int x, int y) {
fa[find(y)] = fa[find(x)];
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n * 2; i++)fa[i] = i;
//我们只连接朋友关系
while (m--) {
char c;
int x, y;
cin >> c >> x >> y;
if (c == 'F') {
//x+n与y+n不一定是朋友,因为朋友的敌人不一定是敌人
un(x, y);
}
else {
//x与y是敌人,x+n与x是敌人,所以x+n与y是朋友
un(y, x + n);
un(x, y + n);
}
}
int ret = 0;
for (int i = 1; i <= n; i++) {
//统计个数的话,只需要统计1~n中fa[i]=i的,因为n+1~2n的都不是真正的人,所以祖先必须是1~n-->合并的时候处理
if (fa[i] == i)ret++;
}
cout << ret;
return 0;
}
食物链
食物链
#include<iostream>
using namespace std;
const int N = 5e4 + 10;
int fa[3 * N];
int n, k;
int find(int x) {
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
void un(int x, int y) {
fa[find(x)] = find(y);
}
int main() {
cin >> n >> k;
for (int i = 1; i <= 3 * n; i++)fa[i] = i;
int ret = 0;
while (k--) {
int o, x, y;
cin >> o >> x >> y;
if (x > n || y > n) {
ret++; continue;
}
if (o == 1) {
if (find(x) == find(y + n) || find(x) == find(y + n + n)) {
ret++;
}
else {
un(x, y);
un(x + n, y + n);
un(x + n + n, y + n + n);
}
}
else {//x->y
if (find(x) == find(y) || find(x) == find(y + n)) {
ret++;
}
else {
un(x + n, y);
un(x + n + n, y + n);
un(x, y + n + n);
}
}
}
cout << ret;
return 0;
}
带权并查集
食物链
食物链
#include<iostream>
using namespace std;
const int N = 5e4 + 10;
int n, k;
int fa[N];
int d[N];//这个就是到父节点的距离
int find(int x) {
if (fa[x] == x)return x;
int t = find(fa[x]);//把它的父节点接到祖先节点下面,并处理好距离
d[x] = d[x] + d[fa[x]];
return fa[x] = t;
}
void un(int x, int y,int w) {
int fx = find(x);
int fy = find(y);
if (fx != fy) {
fa[fx] = fy;
d[fx] = d[y] + w - d[x];
}
//if (find(x) != find(y)) {
// fa[find(x)] = find(y);
// d[find(x)] = d[y] + w - d[x];//不能这样,因为x的祖先已经变了
//}
}
int main() {
cin >> n >> k;
for (int i = 1; i <= n; i++)fa[i] = i;
int ret = 0;
while (k--) {
int o, x, y;
cin >> o >> x >> y;
if (x > n || y > n) {
ret++; continue;
}
int fx = find(x);
int fy = find(y);
if (o == 1) {
//判断什么时候为假话,
if (fx == fy&& ((d[x] - d[y]) % 3 + 3) % 3 != 0)ret++;//膜加膜,在同一个树,
else {
if (fx != fy) {//不在一个树默认为真话,
un(x, y, 0);//x与y的距离为0
}
}
}
else {//x->y
if (fx == fy && ((d[y] - d[x]) % 3 + 3) % 3 != 1)ret++;
else {
if (fx != fy) {//不在一个树默认为真话,
un(x, y, 2);//x与y的距离为2,,直线才是距离,到父节点的才是距离,我们以父节点为参照来做,记住吧
}
}
}
}
cout << ret;
return 0;
}









![[ctfshow web入门]burpsuite的下载与使用](https://i-blog.csdnimg.cn/direct/cffb49d3ab3a495e9baaf5853dfb92c5.png)