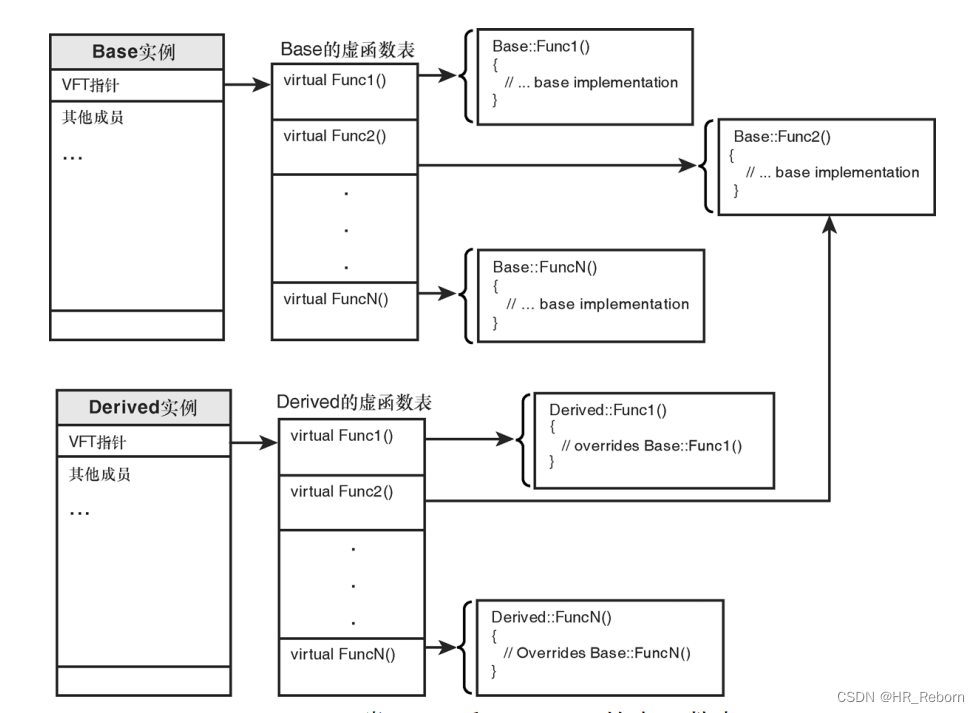
机器学习是我们现在接触人工智能领域首先要去掌握的知识,下面是我学习记录的一些关于机器学习的基础、常见的概念和定义。
目录
机器学习定义
机器学习过程
假设关系
训练数据
损失函数(正向传播)
优化(反向传播)
激活函数函数和向量化
训练
深度学习
机器学习定义
机器学习总的来说就是寻找一种适合的映射关系f,帮助我们将某些输入信息按照我们的需求转化输出为另外一种信号,教会机器去模仿人类的功能。例如将音频输出为文字、图片输出为文字等,而这种对应关系往往是我们所难以寻找到。
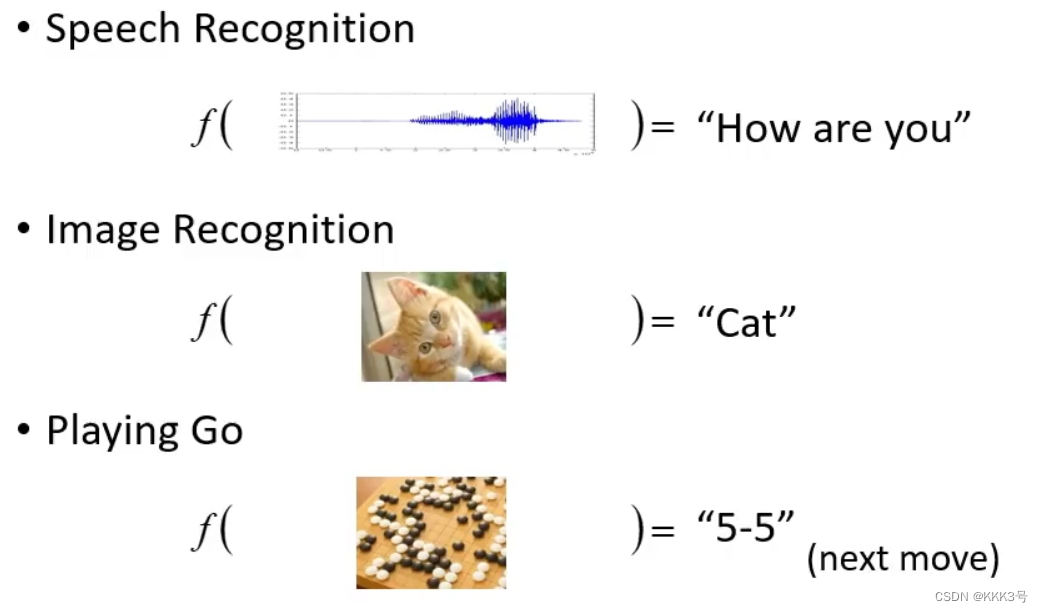
而深度学习是机器学习的一种分支,它继承自机器学习的部分概念,它与机器学习的区别是它的对应关系是一个神经网络。
深度学习的函数f也可以根据它的输入和输出分不同的类别。它的输入可以是一个向量、矩阵或者一组序列(语言、音频);而经过对应关系f的处理后,它的输出可以是一个数值(回归regression)、一种类别(分类classification)、文本或者一张图片(结构整体structured Learning)。
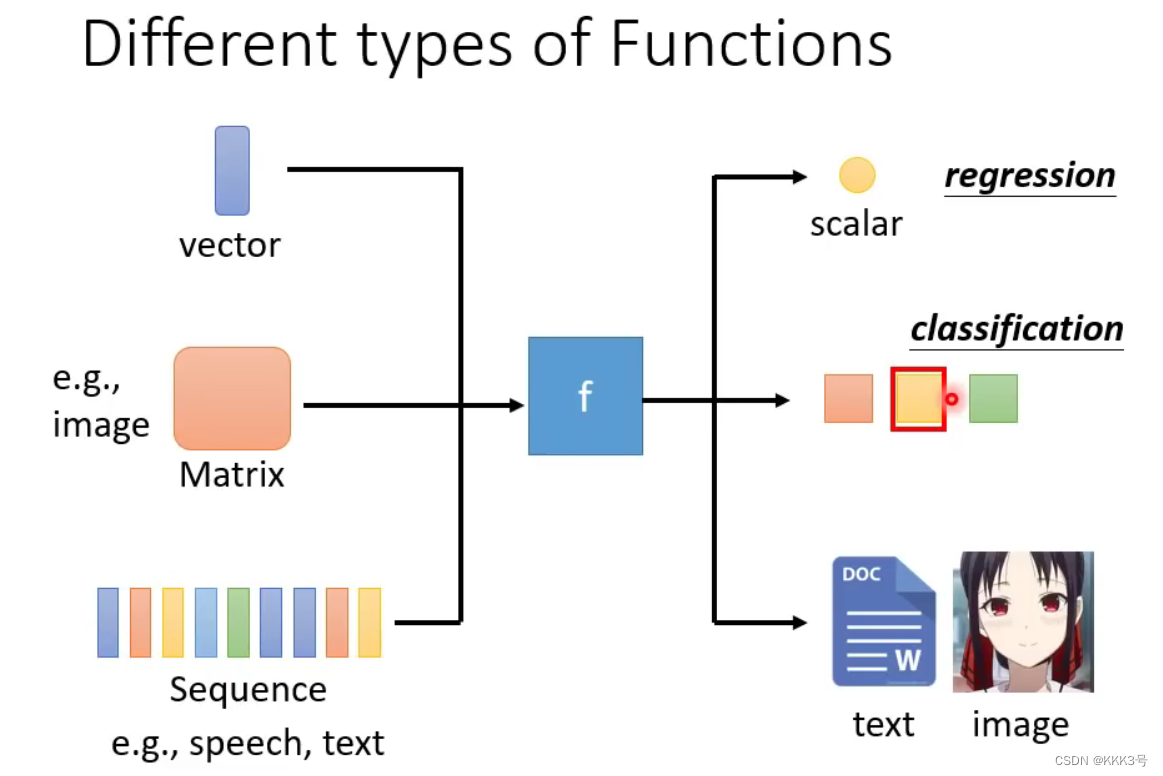
机器学习过程
假设关系
在进行机器学习之前,我们首先需要猜测这个对应的映射关系f。例如我们要根据今天的气温预测明天的气温。那我们可以先假设明天的气温为y,而映射关系是,当然,这个式子也是我假设的。其中w就是权重(weight),而b就是偏置(bias),b和w统称为参数(parameter)。而已有的数据x就是特征(feature),真实的数据
被称为标签(label)而整个函数式子就是模型(model)。
训练数据
然后需要收集一些足够的数据,这些数据需要有明确的类别标签。例如我们需要让机器分辨出猫🐱和狗🐕,那我们首先需要有许多分好类别的训练数据,传输给机器,让机器知道这只是猫、而那只是狗。这个过程就是对机器进行训练的过程。



损失函数(正向传播)
然后我们需要定义一个损失函数loss(L(w,b)它是w和b的函数),这个函数表示的是训练出来的数据和它原本真实的数据
之间的差距。就拿回预测天气的模型,假如我们初始设定
,而带入某天x算出来的温度是
而实际是
,我们记录它们之间的差距为
,
有很多种不同的计算方法:
①(MAE)
②(MSE)
③else..
而对于所有数据求出来的误差求平均就可以得到我们需要的损失函数。结合上面的例子,我们可以很明显看出损失函数Loss是w,b的函数关系式并且Loss函数最小时预测的数据和真实的数据最接近。取不同的w和b,得到的Loss函数的数值也不同。
优化(反向传播)
优化(optimization)就是寻找一组最优的w和b使得Loss函数最小的过程,而我们最常用的优化方式是梯度下降法。
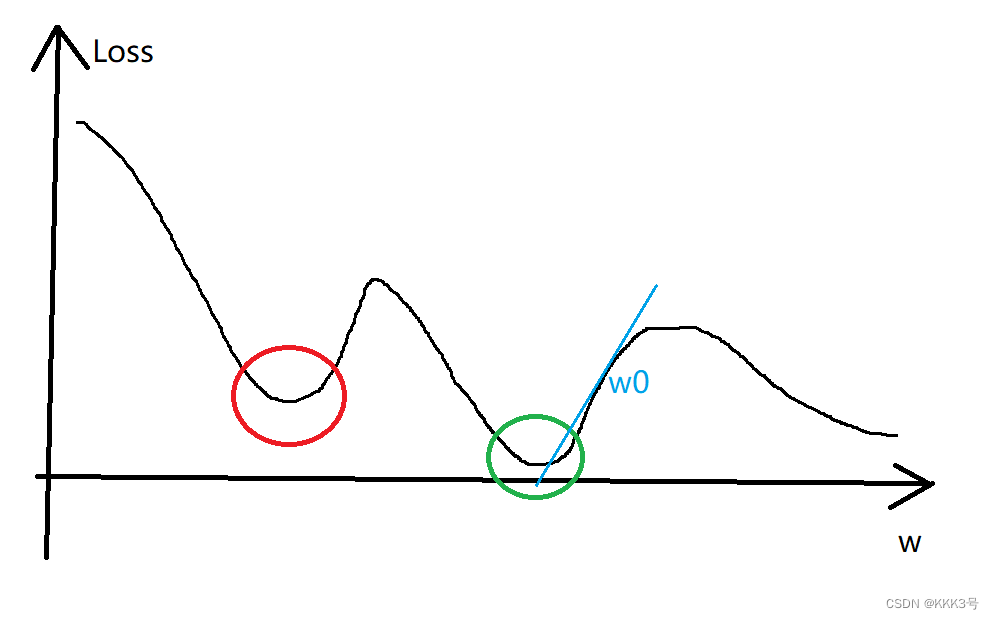
假设我们有了一个模型,现在我们要对这个模型进行优化。现在我们先固定住b,只取不同的w的情况下假设Loss函数的取值如下图所示。在图中我们任意取一个点
作为任意初始的w,现在我们需要让w往绿色圈内靠拢(Loss变小)。而我们的更新方法是对w进行微分,算出
,而这个算出的
就是当前w所在位置对应于Loss损失函数图线上点的斜率,利用这个斜率我们可以将w进行移动(更新),而更新的式子是
,仔细观察式子,我们可以看出式子里面的导数部分代表的是每次更新的方向,而α(学习率)表示的是每次更新的步长。假设是现在微分的是初始的
,我们可以求出它的
是一个正的数值, 而我们带入式子刚好对
进行减法操作,将w的值正合我们意地变小了,那么更新后的
可以很明显看出是往左边移动的,更加靠近绿圈。
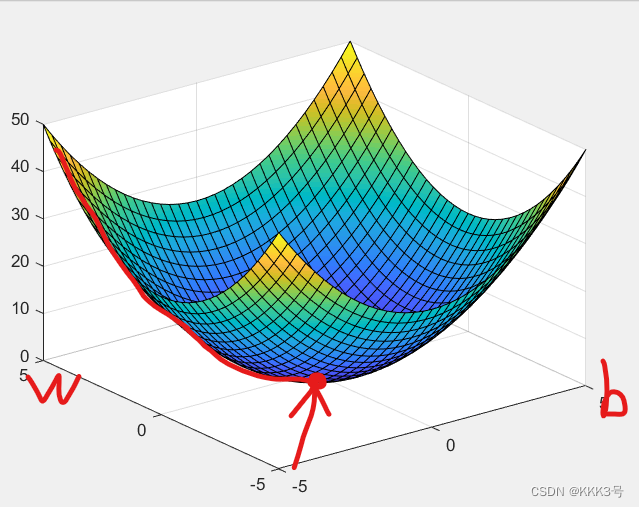
类似地,我们可以将b和w同时考虑,只不过此时的Loss函数变成一个三维立体的函数,而微分不是求导而是求偏导了。
激活函数函数和向量化
我们知道,前面我们假设的模型是一个一次函数模型,也是一个线性的模型(Linear Model),但是很多情况下我们实际情况的模型不一定非得是一个一次函数状的模型,它可以是折线组成的图形,也可以是曲线图形。
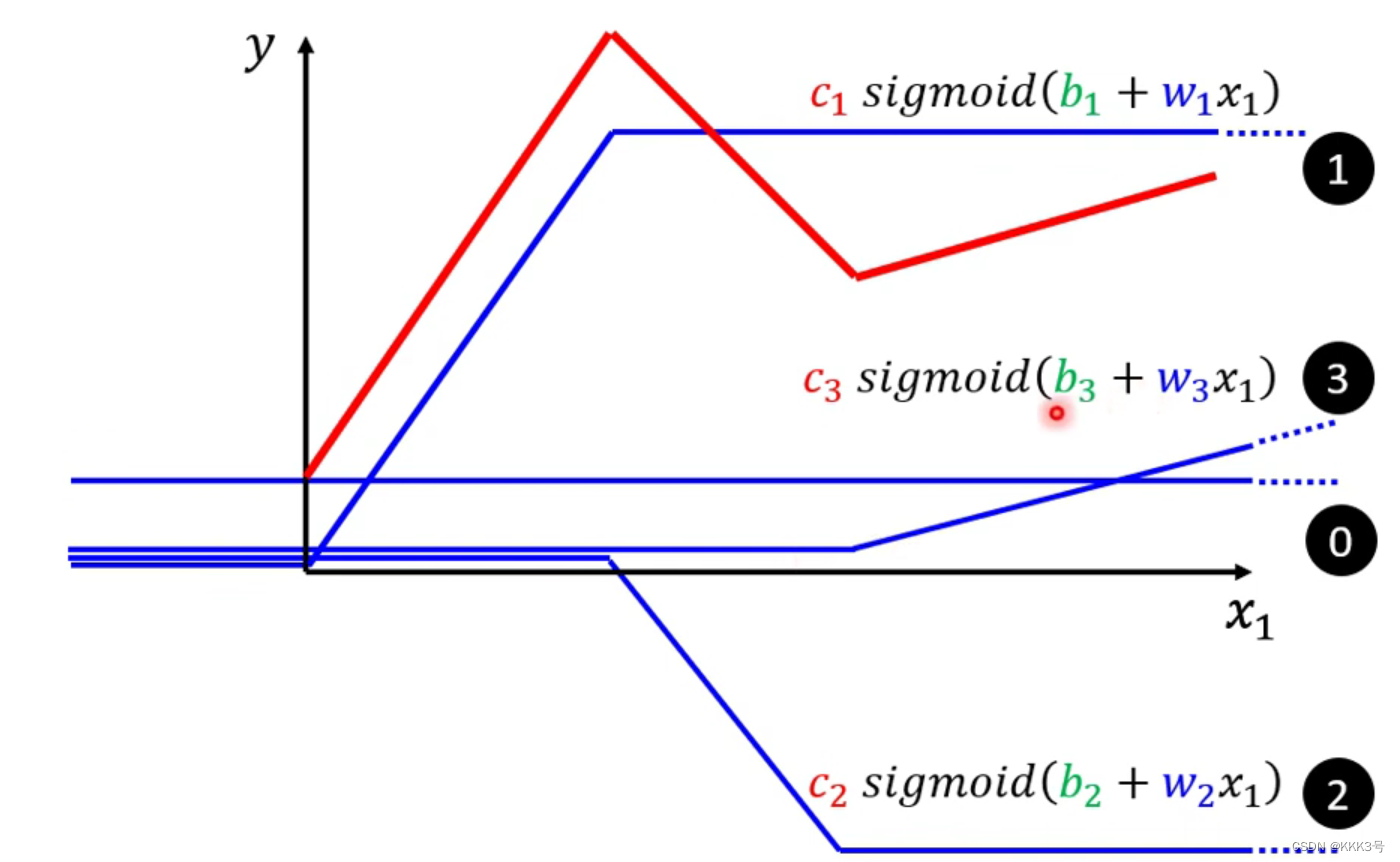
在这种情况下,我们之前使用的一次函数斜线模型就没有办法很好地去表示了。不过我们还是有方法的。我们可以用很多条折线通过重叠去逼近这个图形,当我们的将该图形分成的折线越多,那么我们模拟出来的图形将会更加接近真实的图形。例如下面红色的连续折线可以通过将4条(第0条是y轴的偏置平行于x轴)分别表示不同x区域特性的蓝色折线相加而成。
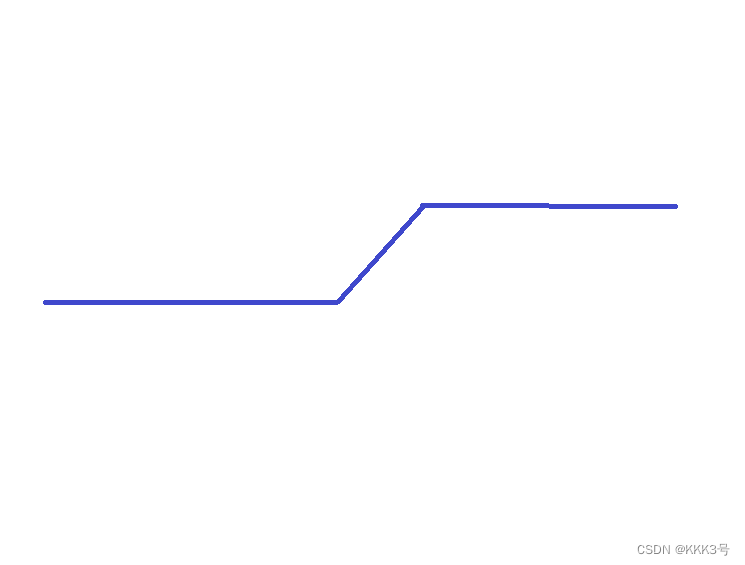
而这些蓝色折线我们可以看到它们都有一个相似的结构特点,它们都是从下面左图这种类型的曲线演变而来(或平移、对称、拉伸等)。
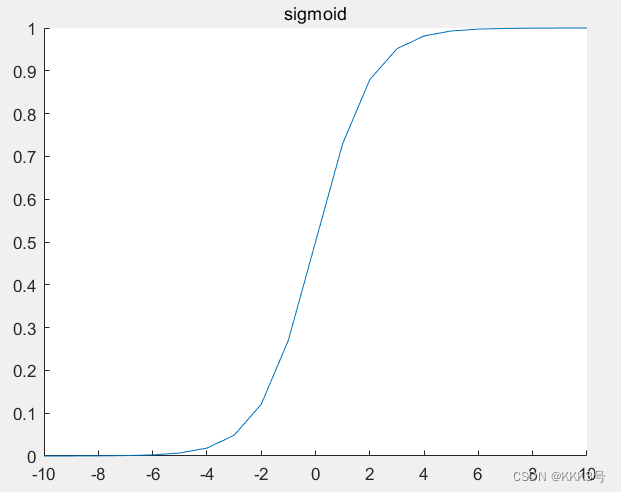
而这类折线我们可以通过一个曲线函数来模拟,这个函数就是sigmoid函数(激活函数),它如上面右图所示,长得还是很像左边的折线的。它的表达式是,我们可以通过变换w,b和c的值来让sigmoid函数平移、拉伸和对称,让它和折线一样可以进行变换。当然我们的一个图形可不止一段折线,它可以由多段折线堆叠而成,即我们需要多个sigmoid函数。所以往往最后我们的的结果是:
也可以将其写为:
现在假如我们y不仅取决于一个特征x,而是取决于多个特征,那么上面的式子我们可以重写为:
,如果m=3那么每一个 i 列出的式子如下:
为了方便运算,我们可以将其转换为矩阵的形式:
即最后的式子是:,对应的变换关系如下。
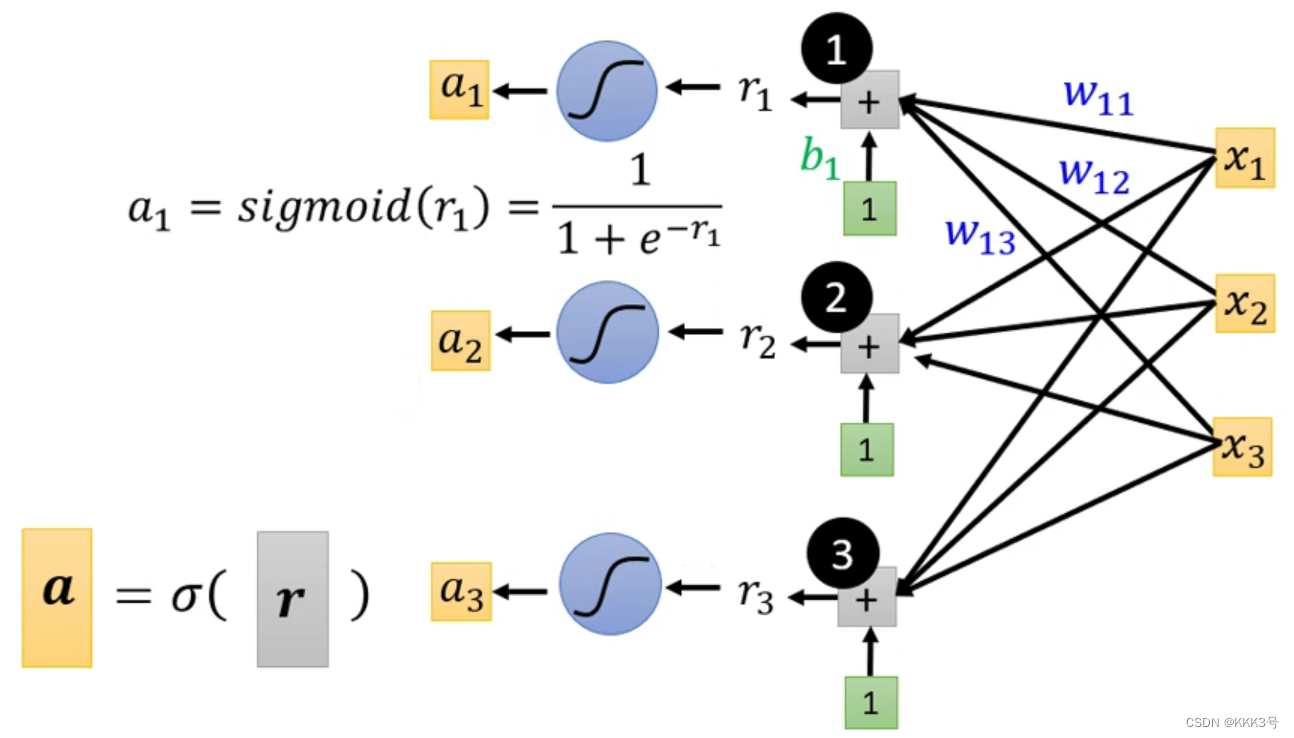
我们可以将这个模型所有需要训练的参数w、b、c等都竖向放入堆叠入一个向量里面,并且无论是w、b还是c我们都用θ符号来统一标号代替它们。并且将这些θ都创建为向量可以帮助我们更好地去更新参数。
训练
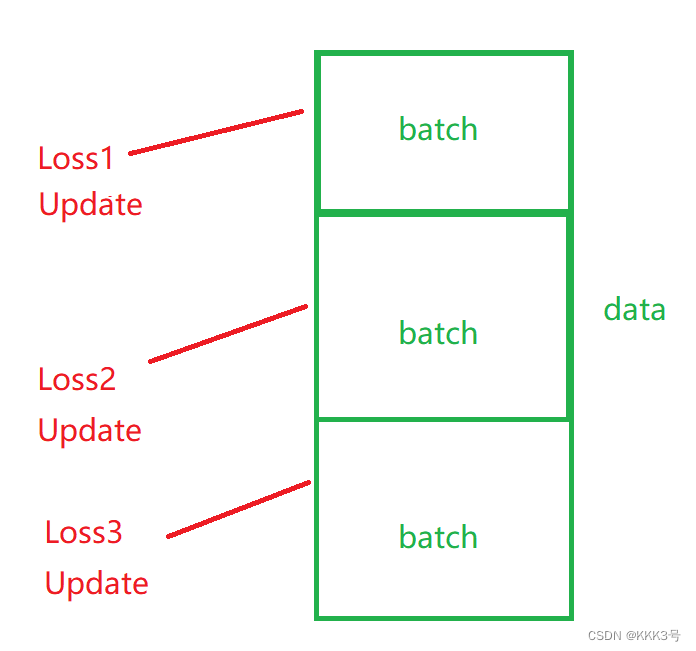
事实上,我们每一次训练都不是一次性对全部的数据都跑一次,然后再统一更新参数。而是将数据都分成几个部分,每一个部分的数据拿去跑一遍,然后每一次跑完都更新一次参数。而这些分成的部分我们称其为batch,每跑完全部的batch我们称为epoch。
深度学习
前面我们设计的模型是有特征的矩阵输入到激活函数,然后激活函数计算后输出,里面的每一个计算单元就是一个神经元,而一层竖排的神经单元就是一层这一整套构成的系统就是神经网络。但是我们仍可以在第一层的激活函数后面再加上一套相同的神经网络,这样我们就可以构成深层神经网络,这种技术就叫做深度学习。
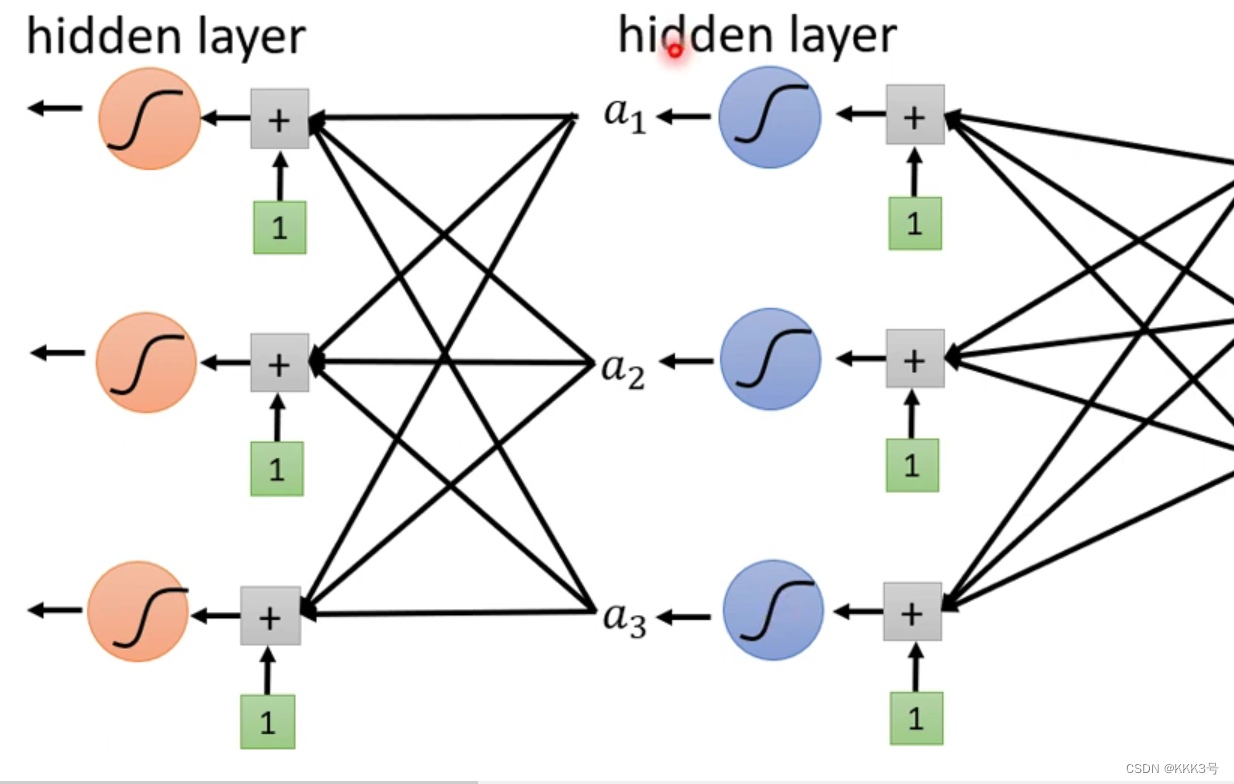
虽然层数对于预测的精准度有很大的影响,但是这并不代表着层数越深就越精确。有时候过深的层数对于已知数据可能比较精确但是对于位置数据的预测可能甚至不如低层的神经网络,这就是过拟合问题。
参考资料:
李宏毅老师网课