文章目录
- 一、背景
- 二、方法
- 2.1 框架总览
- 2.1.1 Text-based classifiers from language descriptions
- 2.1.2 Vision-based Classifiers from Image Exemplars
- 2.1.3 Constructing Classifiers via Multi-Modal Fusion
- 三、效果
- 3.1 数据集
- 3.2 实现细节
- 3.3 开集目标检测结果
论文:Multi-Modal Classifiers for Open-Vocabulary Object Detection
代码:https://github.com/prannaykaul/mm-ovod
官网:https://www.robots.ox.ac.uk/~vgg/research/mm-ovod/
出处:ICML 2023
一、背景
本文的目的是为了实现开集目标检测(open-vocabulary object detection),也就是希望能构建一个能够检测在训练过程中没见过的类别样本的模型,让使用者不需要进行重新训练就能够检测出其感兴趣的类别。
作者使用标准的两阶段检测器作为检测框架,并且探索了三种不同的方式来实现对新类别的输出:
- 语言描述
- 图像示例
- 语言描述和图像示例结合
贡献点:
- 提出了一个 large language model(LLM)来对目标类别生成有用的语言描述
- 在图像示例上使用了一个视觉聚合器,能够接受任意数量的图像作为输入
- 提出了一个简单的方法来将语言描述和图像示例进行融合,能够产生一个多模态的分类器
现有工作的回顾:
-
现有的工作已经探索了使用 text embedding 来代替传统检测器中的可学习分类器,主要是通过使用手工 prompt 将类别名称送入训练好的 text encoder 中进行重新编码,如 ’a photo of a dalmatian‘,但这种方式不是最优的,有下面三个问题:
-
这种方式很大程度上依赖于 text encoder 的能力,可能会导致词汇歧义,如 ’nail’ 即可以是指甲也可以表示钉子, “the hard surface on the tips of the fingers” 和 “a small metal spike with a flat tip hammered into wood to form a joint”,只对 class name 进行编码很难区分这两个概念
-
对使用者来说,class name 也可能是不知道的,但 image exemplar(图片示例)就可以和好的解决该问题
-
多模态信息可能更好,比如一个有罕见翅膀的蝴蝶,这就很难用语言来描述出来,如果使用图片示例就能够 ”tell a thousand words",也更有效率
-
本文工作是怎么解决的:
- 提出了 multi-modal 开集目标检测器,通过使用语言描述、图片示例、以及两者的结合来实现对样本的检测
- 作者建立了一个自动寻找目标类别视觉描述的方法,即先问 LLM 问题,在得到了回答之后,将该回答作为线索来加强 text encoder 生成的类别描述
- 此外,作者还提出了 image exemplers,来帮助更清楚的描述所需的样本
- 最后,作者提出了一个融合语言描述的图像示例的方式,产生了一个多模态分类器,比任意单模态的方法表现都要好
二、方法
整个问题描述:给定一个图片 I ∈ R 3 × H × W I \in R^{3 \times H \times W} I∈R3×H×W 输入开集目标检测器,会有两个输出:
- 类别标签 c j ∈ C T E S T c_j \in C^{TEST} cj∈CTEST(infer 时候定义的)
- 框位置,定义了检测目标的位置
如何训练:使用两个数据集来训练
- 检测数据集 D D E T D^{DET} DDET,包含 bbox 坐标,类别词汇标签 C D E T C^{DET} CDET
- 分类数据集 D I M G D^{IMG} DIMG,只包含图像的 label,对应的是类别词汇标签 C I M G C^{IMG} CIMG
- 且一般来说, C T E S T 、 C D E T 、 C I M G C^{TEST}、C^{DET}、C^{IMG} CTEST、CDET、CIMG 没有严格的重合或不重合的限制
2.1 框架总览

检测器:CenterNet2
输出: { c j , b j } j = 1 M \{c_j,b_j\}_{j=1}^M {cj,bj}j=1M
输出可以被重写如下:
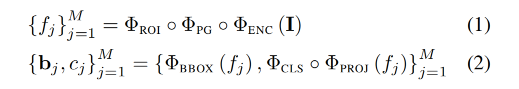
- 每个输入都会按顺序经过:image encoder、proposal generator、RoI feature pooling module,得到最终的 RoI features f j f_j fj
- RoI features 会被输入 bbox module 来产生位置坐标,也会被输入 classification module 来产生分类结果
在闭集目标检测中,上面所有部件都是固定好的,但在开集目标检测中,分类器 Φ C L S \Phi_{CLS} ΦCLS 不是在训练中固定的,可以从其他途径获得。
这就允许推理的类别可以和检测训练的类别不一样,可以在推理的时候重新设置检测的类别。
下面会介绍不同的分类器类别设置方式:
- 从自然语言获得
- 从图像示例获得
- 从两者的结合获得
2.1.1 Text-based classifiers from language descriptions
现有的 OVOD 方法,如 Detic 和 ViLD,都是简单的使用 text-based 分类器来实现,也就是使用手工定制的 prompt 来编码类别名称,如 a photo of a(n) {class name} 或者 a(n) {class name}
这种方法主要依赖于 text encoder 对 class name 的理解来产生 text-based 分类
本文的方法,作者使用 LLM 来先生成对一个类别的描述,该描述会包括很多额外的细节信息,有两个好处:
- 能够缓解词汇意思的混淆(比如一个 class name 可能有两种不同的含义)
- 也能够避免人们要花费很多的时间来斟酌描述词来实现对想要的类别的描述
如图 2 展示了基于 text 来生成的描述信息
提问的 prompt 为:what does a(n) {class name} look like?
作者使用 GPT-3 来为每个类别生成 10 个描述,图 2 展示了 3 个,更多的示例见附录。
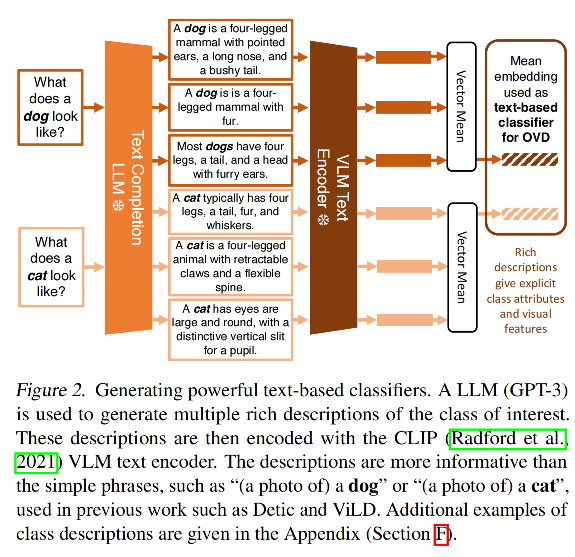
对类别 c,给定 M 个简单文本描述,作者使用 CLIP text encoder 对所有关键元素进行了 encode,然后对这几个描述求平均即可得到对该类别的描述。
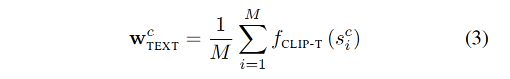
在检测推理阶段,text-based 分类器是被冻结的,其他参数是可以更新的,也就是公式 1-2 中除了 Φ C L S \Phi_{CLS} ΦCLS 外,其余都更新。
一些回答示例:

2.1.2 Vision-based Classifiers from Image Exemplars
当无法很明确的用语言描述想要的类别特征时,使用图像示例是一个很不错的选择。
所以,本文作者提出了使用图像示例的方式来指导分类器,如图 3 所示
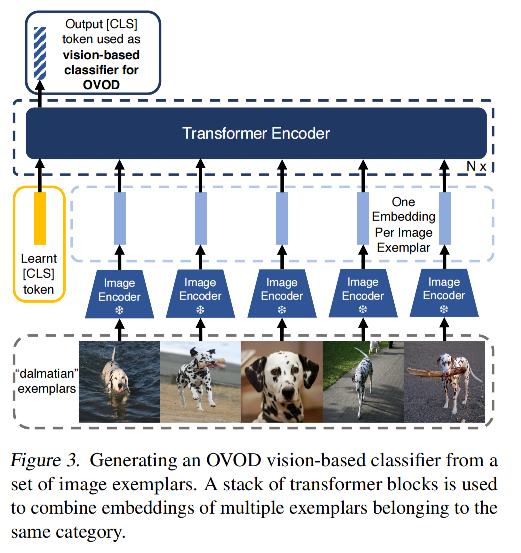
针对类别 c,给定 K 个 RGB 图像示例,使用 CLIP visual encoder 对每个图像示例进行编码,产生 K 个编码特征,然后输入 Transformer 结构中(有一个可学习的 token [CLS] —— t C L S t_{CLS} tCLS)
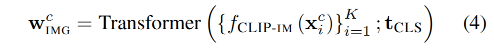
Transformer 结构能很好的聚合这 K 个图像示例,并且使用 [CLS] token 来作为类别
训练 transformer 聚合器的所有图像示例都来自于 ImageNet-21k-P
如何离线训练视觉聚合器:
视觉聚合器是离线训练的,不会在训练检测模型时更新
训练的目标是学习如何结合多个图像示例来产生对 OVOD 有效的 vision-based 分类器
作者使用 CLIP image encoder来对每个图像示例进行特征提取,且在训练时会冻结参数来提高训练效率,并且防止忘记一些类别。
为了得到强有力的 vision-based 分类器,作者使用了对比学习:
- 对每个类别,从 visual aggregator 中输出的 embedding 都期望和其他类别的 embedding 的相似度变大,和同类样本的相似度变小
- 所以,作者使用 infoNCE loss,且使用 ImageNet-21k-P 训练图像分类,大约包括 11 M 图像(11K 类别)
一些 image exemplers 示例:



2.1.3 Constructing Classifiers via Multi-Modal Fusion
对于给定的类别 c,同时使用 text-based 和 vision-based 分类器的多模态分类器计算如下:

如图 1 展示了整个 pipeline
三、效果
3.1 数据集
标准 LVIS Benchmark:
本文的很多实验都基于 LVIS 目标检测数据集,包含大量的词汇类别和长尾分布的目标实例。
LVIS 包含 1203 个类别,约 100k 图像,基于没类的样本数量将图像被分为三大类:稀缺、常见、频繁出现
训练数据集:
- 移除了 LVIS 中稀缺类别 317 个,但不移除整个图像,也就是对稀缺类别目标移除标注框
- 使用常见、频繁出现的数据作为 LVIS-base,即使用 LVIS-base 作为 D D E T D^{DET} DDET
测评:
- 之前的方法都是使用 LVIS 测试集来测评,将 rare classes 作为新类别
- rare classes 的 mask AP 为 APr
- 所有类别的 mask AP 为 mAP
3.2 实现细节
1、目标检测框架
框架使用 CenterNet2,backbone 为 resnet-50,在 ImageNet-21k-P 上进行了预训练
2、检测器的训练
训练方式类似 Detic,使用联合 loss
作者只使用检测数据集 D D E T D^{DET} DDET 来训练 OVOD 模型,使用 4x schedule(大约 LVIS-base 58 个 epochs,或使用 batch size 64 训练 90k iterations )。
当使用额外的 image-labelled data(LN-L)时,同时训练 D D E T D^{DET} DDET 和 D I M G D^{IMG} DIMG 训练 4x schedule(90k iterations),采样比例为 1:4,batch size 为 64 和 256。
对于图像级别标注的数据 D I M G D^{IMG} DIMG,只有图像级别的标签,没有 bbox,作者参考 Detic,选择了类别未知的最大 proposal 框,送入检测器进行训练,更多的细节见 Detic 文章。
3、基于文本的分类器构建
对 LVIS 的每个类别,先使用 GPT-3 生成 10 个描述,然后计算得到平均的 text encoder
4、基于视觉的分类器构建
视觉聚合器是使用 Transformer,训练数据使用的是 ImageNet-21-P 数据集
5、多模态分类器的构建
作者计算的是类别-wise 的每个模态的 l 2 l^2 l2-normalised
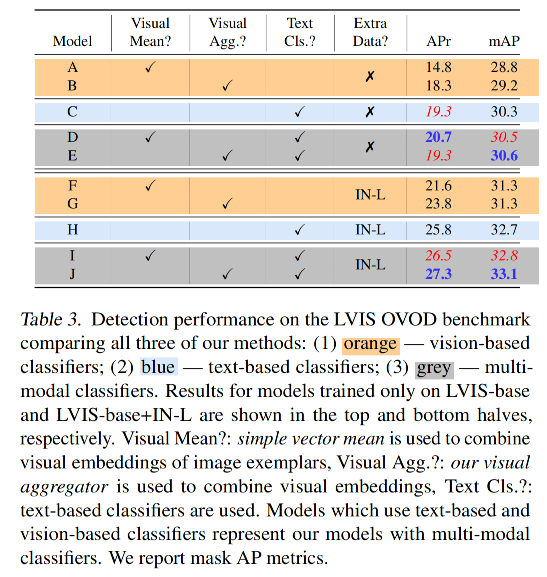
3.3 开集目标检测结果
LVIS OVOD Benchmark:
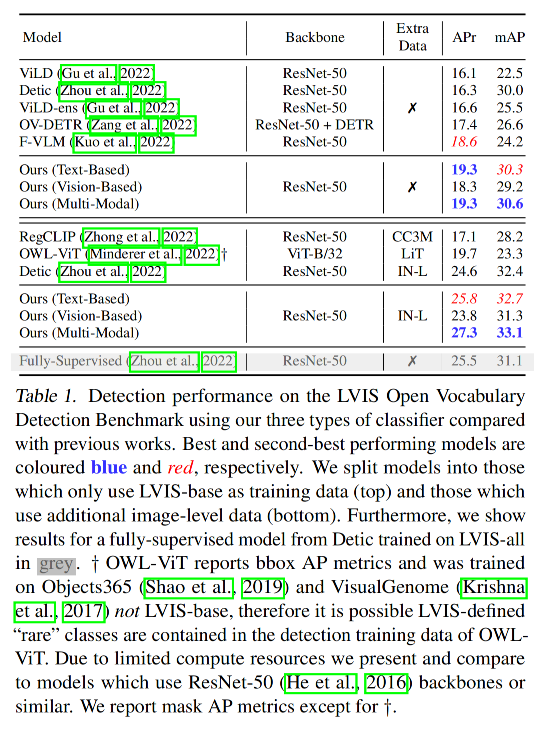
Cross-dataset Transfer:

消融实验:
- 使用视觉特征的分类器为橘色行
- 使用文本特征的分类器为蓝色行
- 使用多模态特征的分类器为灰色行