Step by step lldb/gdb调试多线程
0.叙谈1.断点分析2.多线程切换 2.1 并发队列 2.1.1 两次入队 2.2 线程调度 2.2.1 执行build端子MetaPipeline 2.2.1.1 Thread6调度第一个PipelineInitializeTask 2.2.1.2 Thread7调度第二个PipelineInitializeTask 2.2.1.3 Thread8调度build端PipelineEvent 2.2.2 执行下一个Metapipeline
书接上回,我们分析了InitializeInternal的ScheduleEvents函数,了解了如何从MetaPipeline构建各种Event事件,上一节中还提到在最终会进行调度,对无依赖节点发起Schedule(),那么本节就继续这一内容,详细从多线程角度看看这些Event对应的Task如何被调度的呢?
本节将会从lldb/gdb角度Step by step断点调试分析多线程如何玩转task执行。
0.叙谈
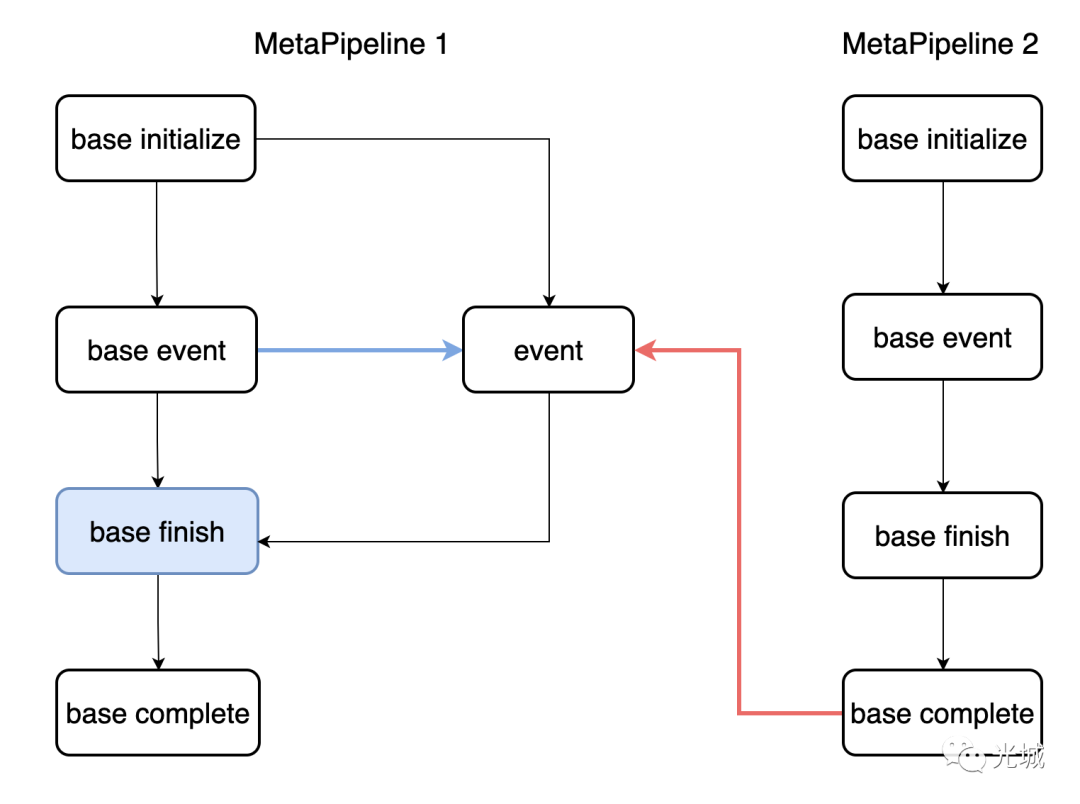
下面展示了一段无依赖的事件调度,初始化阶段会循环所有events,找到无依赖的event,并发起Schedule(),这里的event是PipelineInitializeEvent,两个MetaPipline各自一个,按照顺序入并发队列,接下来详细聊聊如何调试以及具体怎么调度多任务的呢?
for (auto &event : events) {
if (!event->HasDependencies()) {
event->Schedule();
}
}1.断点分析
下面是本次调试的断点list,每个都break一下便可以快速学习了。
Enqueue函数
Task入队的函数。
b task_scheduler.cpp:47
ExecuteForever函数
线程从队列中获取Task的函数。
b task_scheduler.cpp:135
打上这两个断点后,就可以调试多线程了。
Event::CompleteDependency函数
处理事件依赖关系,能够定位当前线程处理了哪些event。
Event::Finish函数
能够知道当前事件的依赖有哪些,下一步处理哪一个,这个跟上面的函数一起用。
2.多线程切换
2.1 并发队列
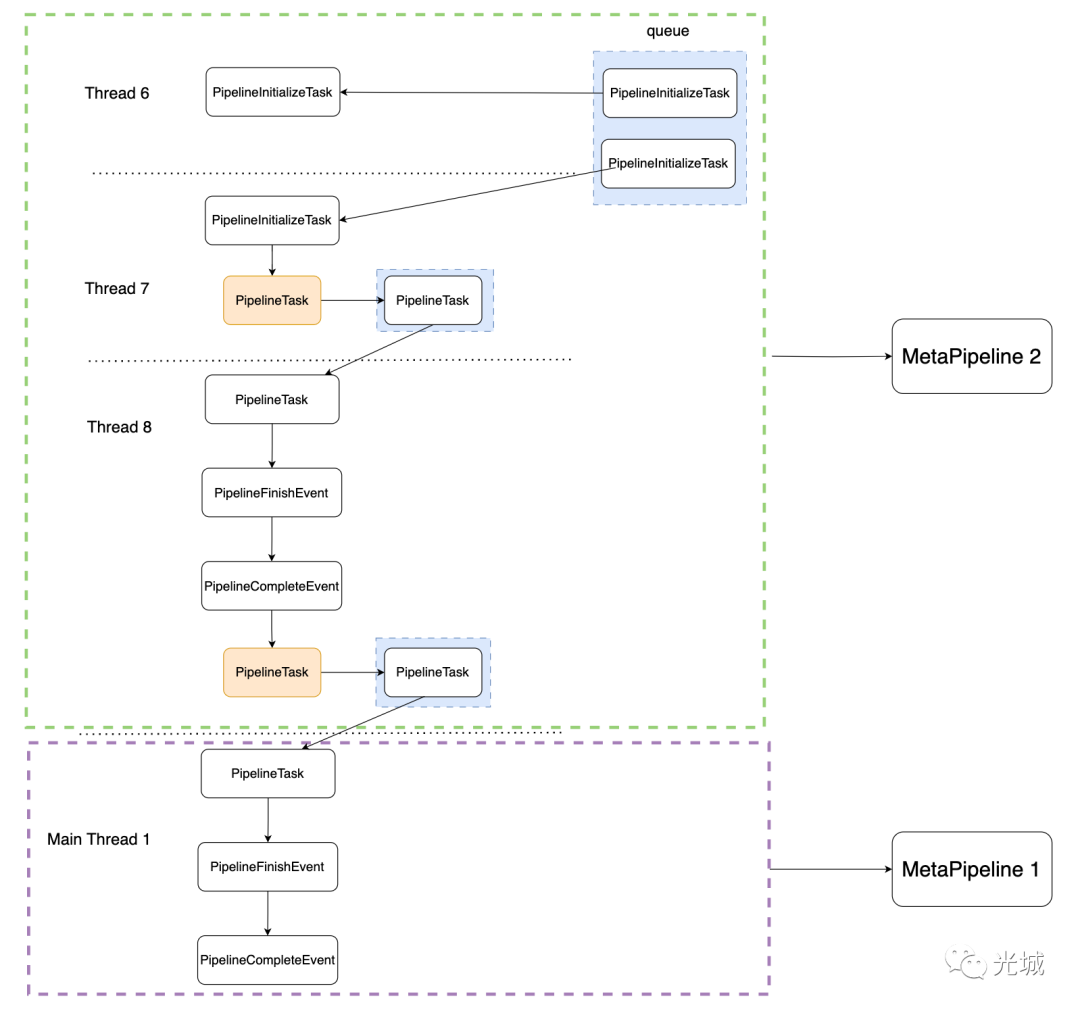
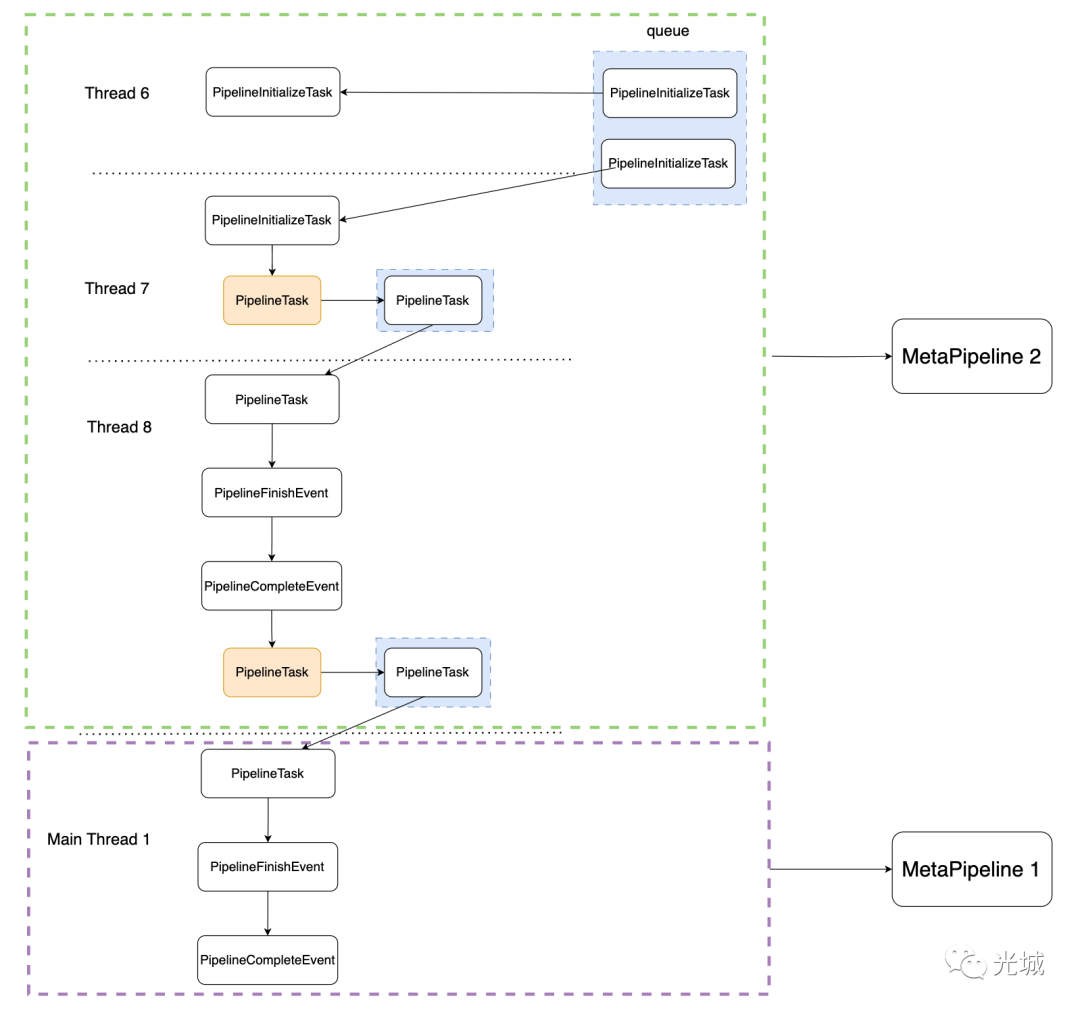
初始化时,当调用Schedule()后,会把PipelineInitializeTask放入并发队列中,见下图的queue(蓝色部分)。
2.1.1 两次入队
1)入队第一个PipelineInitializeTask
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 9.1
frame #0: 0x00000001160be794 duckdb`duckdb::ConcurrentQueue::Enqueue(this=0x0000616000000680, token=0x00006070000414e0, task=std::__1::shared_ptr<duckdb::Task>::element_type @ 0x000060600007cb20 strong=1 weak=2) at task_scheduler.cpp:47:8
44
45 void ConcurrentQueue::Enqueue(ProducerToken &token, shared_ptr<Task> task) {
46 lock_guard<mutex> producer_lock(token.producer_lock);
-> 47 if (q.enqueue(token.token->queue_token, std::move(task))) {
48 semaphore.signal();
49 } else {
50 throw InternalException("Could not schedule task!");
(lldb) p task.get()
(duckdb::PipelineInitializeTask *) $126 = 0x000060600007cb20
(lldb) p ((duckdb::PipelineInitializeTask *)task.get())->event->PrintPipeline()此时在sql终端输出的pipeline为:
┌───────────────────────────┐
│ RESULT_COLLECTOR │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ name │
│ score │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ stu_id │
│ score │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
└───────────────────────────┘2)入队第二个PipelineInitializeTask
(lldb) c
Process 23807 resuming
Process 23807 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 9.1
frame #0: 0x00000001160be794 duckdb`duckdb::ConcurrentQueue::Enqueue(this=0x0000616000000680, token=0x00006070000414e0, task=std::__1::shared_ptr<duckdb::Task>::element_type @ 0x000060600007d300 strong=1 weak=2) at task_scheduler.cpp:47:8
44
45 void ConcurrentQueue::Enqueue(ProducerToken &token, shared_ptr<Task> task) {
46 lock_guard<mutex> producer_lock(token.producer_lock);
-> 47 if (q.enqueue(token.token->queue_token, std::move(task))) {
48 semaphore.signal();
49 } else {
50 throw InternalException("Could not schedule task!");
(lldb) p task.get()
(duckdb::PipelineInitializeTask *) $127 = 0x000060600007d300
(lldb) p ((duckdb::PipelineInitializeTask *)task.get())->event->PrintPipeline()此时的pipeline为:
┌───────────────────────────┐
│ HASH_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ stu_id = id │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 4 │
│ Cost: 4 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ student │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ id │
│ name │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 3 │
└───────────────────────────┘2.2 线程调度
2.2.1 执行build端子MetaPipeline
2.2.1 Thread6调度第一个PipelineInitializeTask
继续c之后,可以看到出队,第一个PipelineInitializeTask出来了,会发现被thread 6调度。
* thread #6, stop reason = breakpoint 8.1
frame #0: 0x00000001160c19cc duckdb`duckdb::TaskScheduler::ExecuteForever(this=0x000060c000000280, marker=0x0000602000003fb0) at task_scheduler.cpp:135:26
132 // wait for a signal with a timeout
133 queue->semaphore.wait();
134 if (queue->q.try_dequeue(task)) {
-> 135 auto execute_result = task->Execute(TaskExecutionMode::PROCESS_ALL);
136
137 switch (execute_result) {
138 case TaskExecutionResult::TASK_FINISHED:
(lldb) p task.get()
(duckdb::PipelineInitializeTask *) $128 = 0x000060600007cb20此时会调用ExecuteTask,里面会FinishTask()。
event->FinishTask();而FinishTask表示我完成了当前event的事情,接着处理父节点,由于由两个依赖,所以不会进行Schedule()。
(lldb) p total_dependencies
(duckdb::idx_t) $129 = 2只有当满足下面条件时才会Schedule(),所以这个线程任务完成了,只处理了PipelineInitializeTask。
if (current_finished == total_dependencies) {
// all dependencies have been completed: schedule the event
D_ASSERT(total_tasks == 0);
Schedule();
if (total_tasks == 0) {
Finish();
}
}2.2.2 Thread7调度第二个PipelineInitializeTask
随后切到另外一个线程,此时处理的是右侧build端的pipeline,可以看到获取到的是队列当中的第二个PipelineInitializeTask,此时线程是7号线程。
* thread #7, stop reason = breakpoint 17.1
(lldb) f 2
frame #2: 0x00000001161d8910 duckdb`duckdb::PipelineInitializeTask::ExecuteTask(this=0x000060600007d300, mode=PROCESS_ALL) at pipeline_initialize_event.cpp:23:10
20 public:
21 TaskExecutionResult ExecuteTask(TaskExecutionMode mode) override {
22 pipeline.ResetSink();
-> 23 event->FinishTask();
24 return TaskExecutionResult::TASK_FINISHED;
25 }
26 };
(lldb) p this
(duckdb::PipelineInitializeTask *) $130 = 0x000060600007d300此时取PipelineInitializeTask的父亲,也就是右侧build端PipelineEvent,由于只有一个依赖,直接调度了,此时会放入队列中,当前线程完成任务,继续等待。
* thread #7, stop reason = breakpoint 9.1
frame #0: 0x00000001160be794 duckdb`duckdb::ConcurrentQueue::Enqueue(this=0x0000616000000680, token=0x00006070000414e0, task=std::__1::shared_ptr<duckdb::Task>::element_type @ 0x00006060000462e0 strong=1 weak=2) at task_scheduler.cpp:47:8
44
45 void ConcurrentQueue::Enqueue(ProducerToken &token, shared_ptr<Task> task) {
46 lock_guard<mutex> producer_lock(token.producer_lock);
-> 47 if (q.enqueue(token.token->queue_token, std::move(task))) {
48 semaphore.signal();
49 } else {
50 throw InternalException("Could not schedule task!");2.2.3 Thread8调度build端PipelineEvent
c之后,可以看到又切到了另一个线程,此时出队,拿到上一个入队的PipelineEvent。
* thread #8, stop reason = breakpoint 8.1
frame #0: 0x00000001160c19cc duckdb`duckdb::TaskScheduler::ExecuteForever(this=0x000060c000000280, marker=0x00006020000040b0) at task_scheduler.cpp:135:26
132 // wait for a signal with a timeout
133 queue->semaphore.wait();
134 if (queue->q.try_dequeue(task)) {
-> 135 auto execute_result = task->Execute(TaskExecutionMode::PROCESS_ALL);
136
137 switch (execute_result) {
138 case TaskExecutionResult::TASK_FINISHED:
(lldb) p task.get()
(duckdb::PipelineTask *) $132 = 0x00006060000462e0可以对比这个地址与上述的线程7号放入的task地址一样。
那么接着调度,我们可以看到依次处理了PipelineFinishEvent->PipelineCompleteEvent->PipelineEvent(HashJoin对应event)。
(lldb) p this
(duckdb::PipelineFinishEvent *) $134 = 0x000060e00002fb58
(lldb) p this
(duckdb::PipelineCompleteEvent *) $135 = 0x000060d0000028f8
(lldb) p this
(duckdb::PipelineEvent *) $137 = 0x000060e00002f6f8这两个Event的Schedule()时空实现,没有入队操作,所以直接调度即可,而PipelineEvent实现了Schedule(),所以会放入队列,可以看到进入了入队断点:
* thread #8, stop reason = breakpoint 9.1
frame #0: 0x00000001160be794 duckdb`duckdb::ConcurrentQueue::Enqueue(this=0x0000616000000680, token=0x00006070000414e0, task=std::__1::shared_ptr<duckdb::Task>::element_type @ 0x0000606000080660 strong=1 weak=2) at task_scheduler.cpp:47:8
44
45 void ConcurrentQueue::Enqueue(ProducerToken &token, shared_ptr<Task> task) {
46 lock_guard<mutex> producer_lock(token.producer_lock);
-> 47 if (q.enqueue(token.token->queue_token, std::move(task))) {
48 semaphore.signal();
49 } else {
50 throw InternalException("Could not schedule task!");2.2.2 执行下一个Metapipeline
此时切回主线程thread 1,执行下一个MetaPipeline,可以看到Executor::ExecuteTask()的completed_pipelines已经为1,说明前面的ChildMetaPipeline已经finish了,并且从队列中拿到了上面的PipelineTask。
PendingExecutionResult Executor::ExecuteTask() {
while (completed_pipelines < total_pipelines) {
// there are! if we don't already have a task, fetch one
if (!task) {
scheduler.GetTaskFromProducer(*producer, task); // 队列中获取任务
}
if (task) {
auto result = task->Execute(TaskExecutionMode::PROCESS_PARTIAL);
}
}
return execution_result;
}debug信息:
(lldb) p completed_pipelines
(std::atomic<unsigned long long>) $142 = {
Value = 1
}
(lldb) p total_pipelines
(duckdb::idx_t) $143 = 2
(lldb) p task
(std::shared_ptr<duckdb::Task>) $147 = std::__1::shared_ptr<duckdb::Task>::element_type @ 0x0000606000080660 strong=1 weak=3 {
__ptr_ = 0x0000606000080660
}接下来要做的就是调度另外一个MetaPipeline,依次分别是:PipelieEvent(probe端)->PipelineFinishEvent->PipelineCompleteEvent->PipelieEvent(hashjoin->project->result的event)。
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 9.1
frame #0: 0x00000001160be794 duckdb`duckdb::ConcurrentQueue::Enqueue(this=0x0000616000000680, token=0x00006070000414e0, task=std::__1::shared_ptr<duckdb::Task>::element_type @ 0x000060600007e320 strong=1 weak=2) at task_scheduler.cpp:47:8
44
45 void ConcurrentQueue::Enqueue(ProducerToken &token, shared_ptr<Task> task) {
46 lock_guard<mutex> producer_lock(token.producer_lock);
-> 47 if (q.enqueue(token.token->queue_token, std::move(task))) {
48 semaphore.signal();
49 } else {
50 throw InternalException("Could not schedule task!");随后另一个线程继续出队列调度任务,依次在该线程上经历PipelieEvent->PipelineFinishEvent->PipelineCompleteEvent。
* thread #9, stop reason = breakpoint 8.1
frame #0: 0x00000001160c19cc duckdb`duckdb::TaskScheduler::ExecuteForever(this=0x000060c000000280, marker=0x0000602000004130) at task_scheduler.cpp:135:26
132 // wait for a signal with a timeout
133 queue->semaphore.wait();
134 if (queue->q.try_dequeue(task)) {
-> 135 auto execute_result = task->Execute(TaskExecutionMode::PROCESS_ALL);
136
137 switch (execute_result) {
138 case TaskExecutionResult::TASK_FINISHED:最后这个线程完成继续等待信号。