一、Dubbo服务发现设计
Dubbo提供的是一种Client-Based的服务发现机制,依赖第三方注册中心组件来协调服务发现过程,支持常用的注册中心如Nacos、Connsul、Zookeeper等
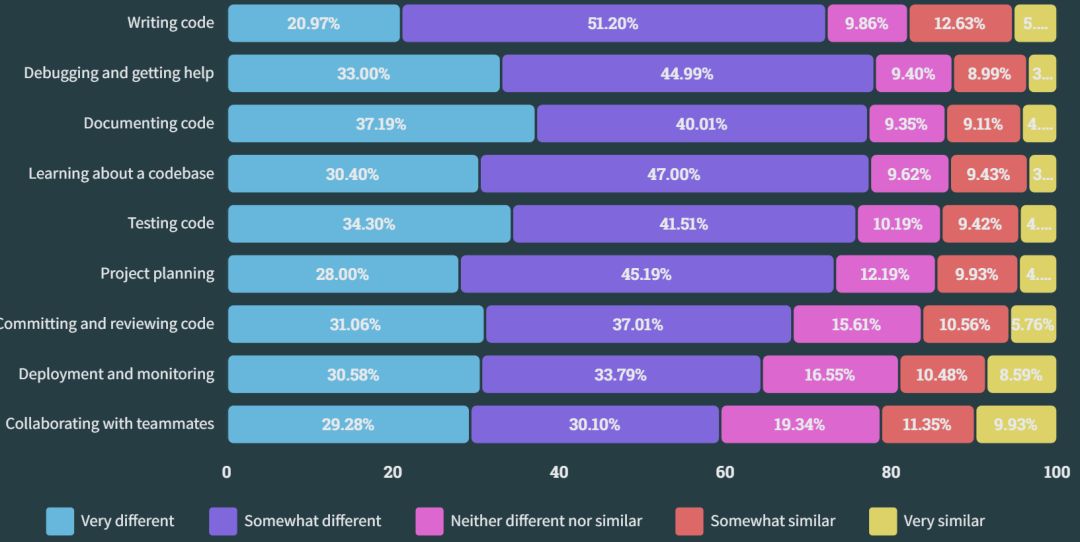
Dubbo服务发现机制的基本工作原理图:
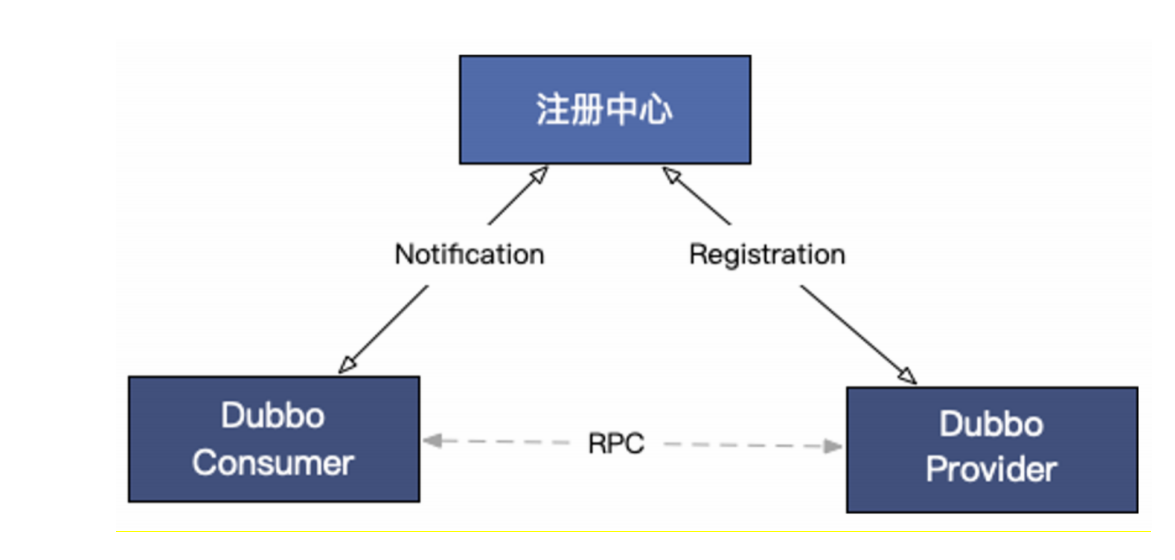
服务发现包含提供者、消费者和注册中心三个参与角色,其中,Dubbo提供者实例注册URL地址到注册中心,注册中心负责对数据进行聚合,Dubbo消费者从注册中心读取地址列表并订阅变更,每当地址列表发生变化,注册中心将最新的列表通知到所有订阅的消费者实例。
1.面向百万实例集群的服务发现机制
区别于其他很多微服务框架的是,Dubbo3的服务发现机制诞生于阿里巴巴超大规模微服务电商集群实践场景,因此,其在性能、可伸缩性、易用性等方面的表现大幅领先于业界大多数主流开源产品。是企业面向未来构建可伸缩的微服务集群的最佳选择。

首先,Dubbo注册中心以应用粒度聚合实例数据,消费者按消费需求精准订阅,避免了大多数开源框架如Istio、Spring Cloud等全量订阅带来的性能瓶颈。
其次,Dubbo SDK在实现上对消费端地址列表处理过程做了大量优化,地址通知增加了异步、缓存、bitmap等多种解析优化,避免了地址更新常出现的消费端进程资源波动。
最后,在功能丰富度和易用性上,服务发现除了同步IP、port等端点基本信息到消费者外,Dubbo还将服务端的RPC/HTTP服务及其配置的元数据信息同步到消费端,这让消费者,提供者两端的更细粒度的协作称为可能,Dubbo基于此机制提供了很多差异化的治理能力。
高效地址推送实现:
从注册中心视角来看,它负责以应用名(Dubbo.application.name)对整个集群的实例地址进行聚合,每个对外提供服务的实例将自身的应用名,实例ip:port地址信息(通过还包含少量的实例元数据,如机器所在区域、环境等)注册到注册中心。
Dubbo2.0版本注册中心以服务粒度聚合实例地址,比应用粒度更细,也就意味着传输的数据量更大,因此,在大规模集群下也遇到一些性能问题。
针对Dubbo2与Dubbo3跨版本数据模型不一致的问题,Dubbo3给出了平滑迁移方案,可做到模型变更对用户无感。
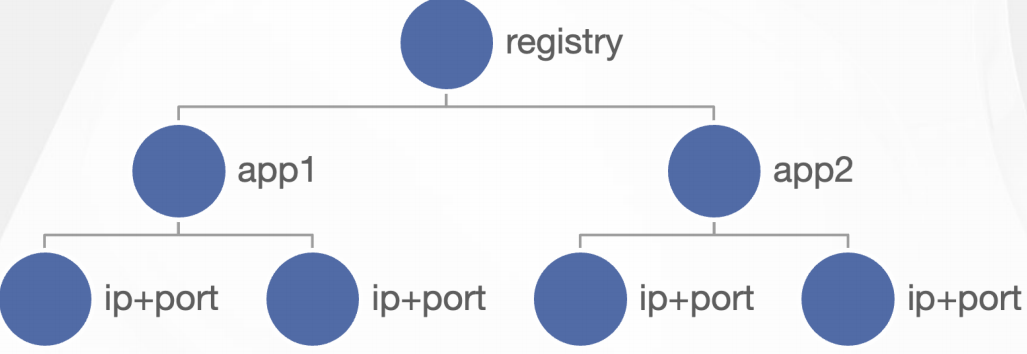
每个消费服务的实例从注册中心订阅实例地址列表,相比于一些产品直接将注册中心的全量数据(应用+实例地址)加载到本地进程,Dubbo实现了按需精准订阅地址信息。比如一个消费者应用依赖app1、app2,则只会订阅app1、app2的地址列表更新,大幅度减轻了冗余数据推送和解析的负担。

丰富的元数据配置
除了于注册中心的交互,Dubbo3的完整地址发现过程还有一条额外的元数据通路,称之为元数据服务(MetadataService),实例地址于元数据共同组成了消费者端有效的地址列表。
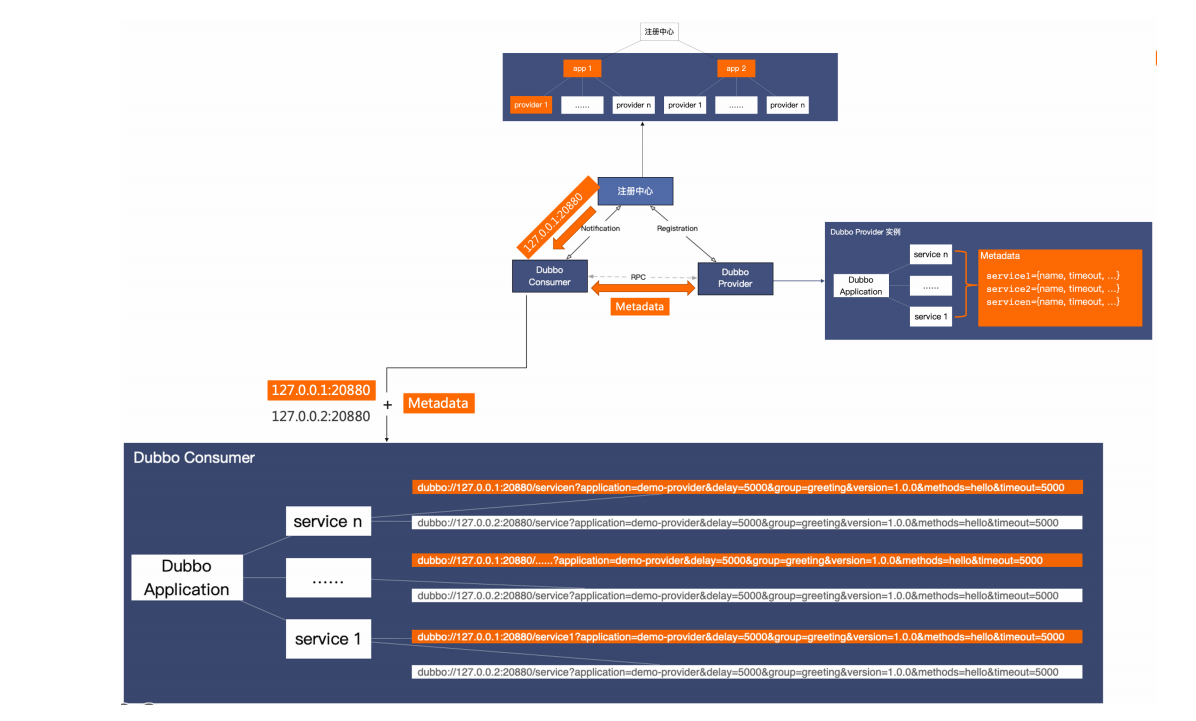
完整工作流程如上图所示,首先,消费者从注册中心接收到地址信息(ip:port),然后于提供者建立连接并通过元数据服务读取到端的元数据配置信息,两部分信息共同组成了Dubbo消费端有效的面向服务的地址列表。以上两个步骤都是在实际的RPC服务调用发生之前的。
2.配置方式
Dubbo服务发现扩展了多种注册中心组件支持,如Nacos、Zookeeper、Consul、Redis、Kubernetes等,可以通过配置切换不通实现,同时还支持鉴权、命名空间隔离等配置。具体配置方式请查看SDK文档。
Dubbo还支持一个应用内配置多注册中心的情形如双注册、双订阅等,这对于实现不同集群地址数据互通、集群迁移等场景非常有用处,官网任务里有关于这部分的示例说明。
3.自定义扩展
注册中心适配支持自定义扩展实现。
1.设计目标:
显著降低服务发现过程的资源消耗,包括提升注册中心容量上限、降低消费端地址解析资源占用等,使得Dubbo3框架能够支持更大规模集群的服务治理,实现无限水平扩展。
适配底层基础设施服务发现模型,如K8s、Service Mesh等。
2.背景:
Dubbo接口级别服务发现-基本原理

Dubbo的地址发现是通过借助注册中心组件协调Provider与Consumer实例地址的过程。
Provider实例通过待定key向注册本机可访问地址
注册中心通过key将Provider实例地址聚合
Consumer通过订阅特定key实时从注册中心接收地址变更
Dubbo最经典的工作原理图来看,Dubbo从设计之初就内置了服务地址发现的能力,Provider注册地址到注册中心,Consumer通过订阅实时获取注册中心的地址更新,在收到地址列表后,consumer基于特定的负载均衡策略发起对Provider的RPC的调用。
在这个过程中:
- 每个Provider通过特定的key向注册中心注册本机可访问地址
- 注册中心通过这个key对Provider实例地址进行聚合
- Consumer通过同样的key从注册中心订阅,以便及时收到聚合后的地址列表
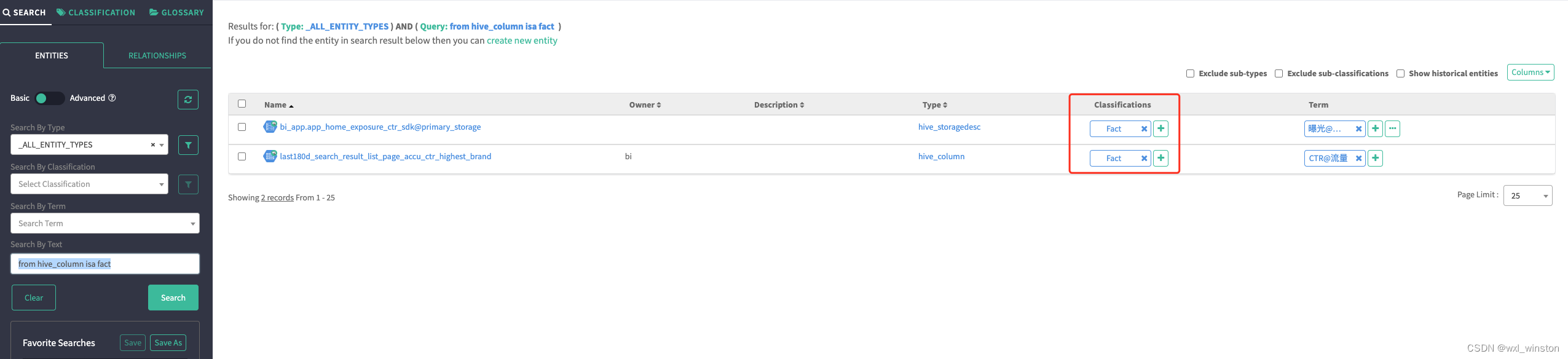
Dubbo接口级别2服务发现---数据与结构1
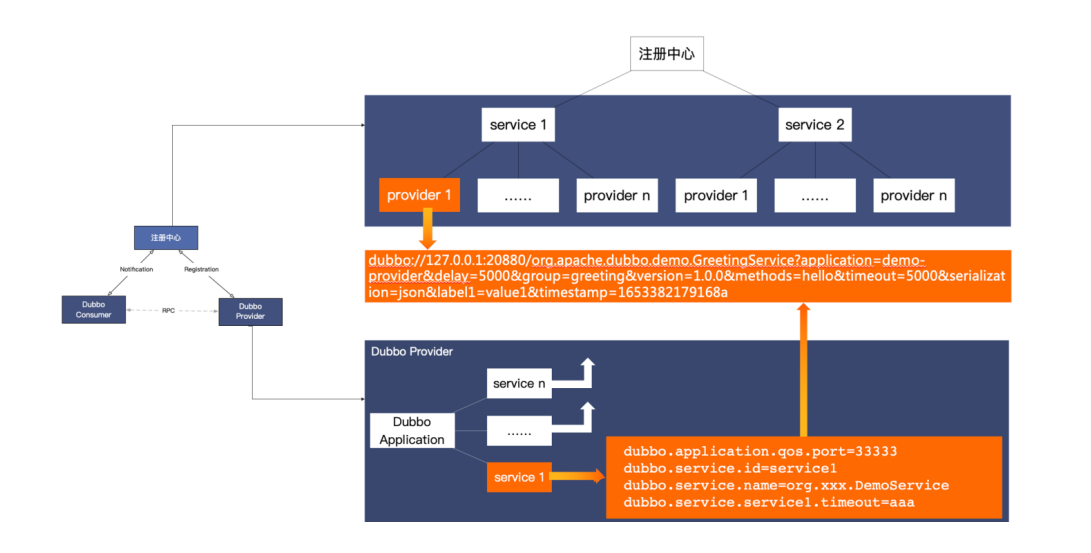
接口级别地址发现的内部数据结构进行详细分析如下:
首先,右下角Provider实例内部的数据与行为,Provider部署的应用中通常会有多个service,也就是Dubbo2中的服务,每个service都可能会有其独有的配置,通常情况下service服务发布的过程,其实就是基于这个服务配置生成地址URL的过程,生成的地址数据如图所示,同样的,其他服务也都会生成地址。
其次,看一下注册中心的地址数据存储结构,注册总线以service服务名为数据划分依据,将一个服务下的所有地址数据都作为子节点进行聚合,子节点的内容就是实际可访问的IP地址,也就是我们Dubbo中URL,格式就是刚才Provider实例生成的。

URL地址数据可以划分为几份:
- 首先是实例可访问地址,主要信息包含IP port,是消费端将基于这条数据生成tcp网络连接,作为后续RPC数据的传输载体。
- 其次是RPC元数据,元数据用于定义和描述一次RPC请求,一方面表明这条地址是与其具体的RPC服务有关的,它的版本号,分组以及方法相关信息
- 下一部分是RPC配置数据,部分配置用于控制RPC调用的行为,还有一部分配置用于同步Provider进程实例的状态,典型的如超时时间,数据编码的序列化方式等
- 最后一部分是自定义的元数据,这部分内容区别于以上框架预定于的各项配置,给了用户更大的灵活性,用户可任意扩展并添加自定义元数据,以进一步丰富实例状态。
Dubbo的优势,
- 地址发现聚合的key就是RPC粒度的服务
- 注册中心同步的数据不止包含地址,还包含了各种元数据以及配置
- 得益于1与2,Dubbo实现了支持应用,RPC服务,方法粒度的服务治理能力
一、Dubbo服务发现设计
Dubbo提供的是一种Client-Based的服务发现机制,依赖第三方注册中心组件来协调服务发现过程,支持常用的注册中心如Nacos、Connsul、Zookeeper等
Dubbo服务发现机制的基本工作原理图:
服务发现包含提供者、消费者和注册中心三个参与角色,其中,Dubbo提供者实例注册URL地址到注册中心,注册中心负责对数据进行聚合,Dubbo消费者从注册中心读取地址列表并订阅变更,每当地址列表发生变化,注册中心将最新的列表通知到所有订阅的消费者实例。
1.面向百万实例集群的服务发现机制
区别于其他很多微服务框架的是,Dubbo3的服务发现机制诞生于阿里巴巴超大规模微服务电商集群实践场景,因此,其在性能、可伸缩性、易用性等方面的表现大幅领先于业界大多数主流开源产品。是企业面向未来构建可伸缩的微服务集群的最佳选择。
首先,Dubbo注册中心以应用粒度聚合实例数据,消费者按消费需求精准订阅,避免了大多数开源框架如Istio、Spring Cloud等全量订阅带来的性能瓶颈。
其次,Dubbo SDK在实现上对消费端地址列表处理过程做了大量优化,地址通知增加了异步、缓存、bitmap等多种解析优化,避免了地址更新常出现的消费端进程资源波动。
最后,在功能丰富度和易用性上,服务发现除了同步IP、port等端点基本信息到消费者外,Dubbo还将服务端的RPC/HTTP服务及其配置的元数据信息同步到消费端,这让消费者,提供者两端的更细粒度的协作称为可能,Dubbo基于此机制提供了很多差异化的治理能力。
高效地址推送实现:
从注册中心视角来看,它负责以应用名(Dubbo.application.name)对整个集群的实例地址进行聚合,每个对外提供服务的实例将自身的应用名,实例ip:port地址信息(通过还包含少量的实例元数据,如机器所在区域、环境等)注册到注册中心。
Dubbo2.0版本注册中心以服务粒度聚合实例地址,比应用粒度更细,也就意味着传输的数据量更大,因此,在大规模集群下也遇到一些性能问题。
针对Dubbo2与Dubbo3跨版本数据模型不一致的问题,Dubbo3给出了平滑迁移方案,可做到模型变更对用户无感。
每个消费服务的实例从注册中心订阅实例地址列表,相比于一些产品直接将注册中心的全量数据(应用+实例地址)加载到本地进程,Dubbo实现了按需精准订阅地址信息。比如一个消费者应用依赖app1、app2,则只会订阅app1、app2的地址列表更新,大幅度减轻了冗余数据推送和解析的负担。
丰富的元数据配置
除了于注册中心的交互,Dubbo3的完整地址发现过程还有一条额外的元数据通路,称之为元数据服务(MetadataService),实例地址于元数据共同组成了消费者端有效的地址列表。
完整工作流程如上图所示,首先,消费者从注册中心接收到地址信息(ip:port),然后于提供者建立连接并通过元数据服务读取到端的元数据配置信息,两部分信息共同组成了Dubbo消费端有效的面向服务的地址列表。以上两个步骤都是在实际的RPC服务调用发生之前的。
2.配置方式
Dubbo服务发现扩展了多种注册中心组件支持,如Nacos、Zookeeper、Consul、Redis、Kubernetes等,可以通过配置切换不通实现,同时还支持鉴权、命名空间隔离等配置。具体配置方式请查看SDK文档。
Dubbo还支持一个应用内配置多注册中心的情形如双注册、双订阅等,这对于实现不同集群地址数据互通、集群迁移等场景非常有用处,官网任务里有关于这部分的示例说明。
3.自定义扩展
注册中心适配支持自定义扩展实现。
1.设计目标:
显著降低服务发现过程的资源消耗,包括提升注册中心容量上限、降低消费端地址解析资源占用等,使得Dubbo3框架能够支持更大规模集群的服务治理,实现无限水平扩展。
适配底层基础设施服务发现模型,如K8s、Service Mesh等。
2.背景:
Dubbo接口级别服务发现-基本原理
Dubbo的地址发现是通过借助注册中心组件协调Provider与Consumer实例地址的过程。
Provider实例通过待定key向注册本机可访问地址
注册中心通过key将Provider实例地址聚合
Consumer通过订阅特定key实时从注册中心接收地址变更
Dubbo最经典的工作原理图来看,Dubbo从设计之初就内置了服务地址发现的能力,Provider注册地址到注册中心,Consumer通过订阅实时获取注册中心的地址更新,在收到地址列表后,consumer基于特定的负载均衡策略发起对Provider的RPC的调用。
在这个过程中:
- 每个Provider通过特定的key向注册中心注册本机可访问地址
- 注册中心通过这个key对Provider实例地址进行聚合
- Consumer通过同样的key从注册中心订阅,以便及时收到聚合后的地址列表
Dubbo接口级别2服务发现---数据与结构1
接口级别地址发现的内部数据结构进行详细分析如下:
首先,右下角Provider实例内部的数据与行为,Provider部署的应用中通常会有多个service,也就是Dubbo2中的服务,每个service都可能会有其独有的配置,通常情况下service服务发布的过程,其实就是基于这个服务配置生成地址URL的过程,生成的地址数据如图所示,同样的,其他服务也都会生成地址。
其次,看一下注册中心的地址数据存储结构,注册总线以service服务名为数据划分依据,将一个服务下的所有地址数据都作为子节点进行聚合,子节点的内容就是实际可访问的IP地址,也就是我们Dubbo中URL,格式就是刚才Provider实例生成的。
URL地址数据可以划分为几份:
- 首先是实例可访问地址,主要信息包含IP port,是消费端将基于这条数据生成tcp网络连接,作为后续RPC数据的传输载体。
- 其次是RPC元数据,元数据用于定义和描述一次RPC请求,一方面表明这条地址是与其具体的RPC服务有关的,它的版本号,分组以及方法相关信息
- 下一部分是RPC配置数据,部分配置用于控制RPC调用的行为,还有一部分配置用于同步Provider进程实例的状态,典型的如超时时间,数据编码的序列化方式等
- 最后一部分是自定义的元数据,这部分内容区别于以上框架预定于的各项配置,给了用户更大的灵活性,用户可任意扩展并添加自定义元数据,以进一步丰富实例状态。
Dubbo的优势,
- 地址发现聚合的key就是RPC粒度的服务
- 注册中心同步的数据不止包含地址,还包含了各种元数据以及配置
- 得益于1与2,Dubbo实现了支持应用,RPC服务,方法粒度的服务治理能力