知识点汇总
- 看一个文件的前n行、指定行、末n行
- idea 创建快捷测试文件
- Mac版 pycharm 快捷键
- idea
- Mac 终端
- MySQL 安装完,初始密码一般存在
- vim操作
- 搜索引擎
看一个文件的前n行、指定行、末n行
# 先准备一个文件
➜ tmp cat a.txt
001
002
003
004
005
006
# 查看前2行
➜ tmp head -n 2 a.txt
001
002
# 查看后3行
➜ tmp tail -n 3 a.txt
004
005
006
# 查看第2~5行的数据:
➜ tmp sed -n '2,5p' a.txt
002
003
004
005
# 查看从第2行开始往后3行的数据(即2、3、4行):
➜ tmp cat a.txt | tail -n +2 | head -n 3
002
003
004
idea 创建快捷测试文件
创建快捷测试文件(以 Scala 为例):
- 如图所示,在 test 文件夹下,右击
java文件夹,新建一个Scala Worksheet文件,起名为test回车

- 在新建的
test.sc文件内编写代码(省略了print语句) - 点击编辑框左上角的三角号,即可执行查看到运行结果

Mac版 pycharm 快捷键
pep8规范: alt + command + l
注释代码: command + /
收起/放开代码: shift + command + 减号 或 加号
复制当前行: command + d
idea
shift + enter 从当前位置直接到下一行编辑
command + shift + U 英文大小写切换
alt + command + l 代码格式化(变规整)
调用的快捷键:
Windows: Ctrl+Alt+T
Mac: command+alt+T
调用方法:
alt(command) + Enter
Alt+Command+T 效果:

Control+Enter 效果:
Mac 终端
清屏 command + k
终止当前进程 control + z
强制退出 command + q
叠加终端窗口 command + t
字体变大/小 command + =/-
MySQL 安装完,初始密码一般存在
/root/.mysql_secret
/var/log/mysqld.log
/usr/local/mysql/data/ .err文件
vim操作
跳到首行 gg
跳到未行 G shift+g
跳到行首 0 或 ^ shift+6
跳到行尾 $ shift+4
删除当前行 dd
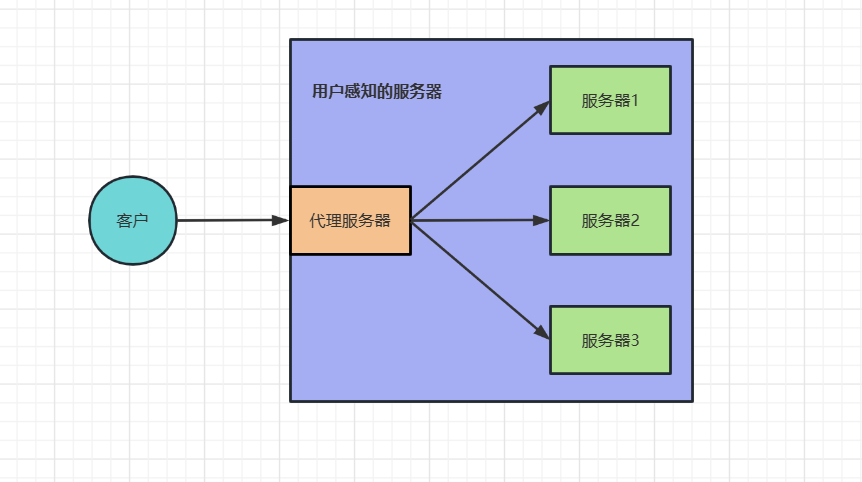
搜索引擎
一个搜索引擎由 搜索器、索引器、检索器、用户接口 四部分组成
class SearchEngineBase(object):
def __init__(self):
pass
def add_corpus(self, file_path):
# 添加语料(corpus):负责读取文件内容,将文件路径作为ID,连同内容一块送到process_corpus中
with open(file_path, 'r') as fin:
text = fin.read()
self.process_corpus(file_path, text)
def process_corpus(self, id, text):
# 对内容进行处理,然后文件路径为ID,将处理后的内容保存下来,处理后的内容叫做索引(index)
raise Exception('process_corpus not implemented.')
def search(self, query):
# 给定一个查询,处理询问,再通过索引检索,然后返回
raise Exception('search not implemented.')
def main(search_engine):
# 提供搜索器、用户接口
for file_path in ['1.txt', '2.txt', '3.txt', '4.txt', '5.txt']:
search_engine.add_corpus(file_path)
while True:
query = input()
results = search_engine.search(query)
# 以下if判断是我加的,为了能使循环终止程序,正常是不加的
if query == 'exit':
break
print('found {} result(s):'.format(len(results)))
for result in results:
print(result)
class SimpleEngine(SearchEngineBase):
'''继承SearchEngineBase类,实现一个算法引擎'''
def __init__(self):
super().__init__()
# 初始化自己的私有变量,用来存储文件名到文件内容的字典
self.__id_to_texts = {}
def process_corpus(self, id, text):
# 索引器
# 将文件内容插入到字典中。注意此处的ID是唯一的,不然相同ID的新内容会覆盖掉旧的内容
self.__id_to_texts[id] = text
def search(self, query):
# 检索器
# 枚举字典,从中找到要搜索的字符串,如果能找到就把ID放到结果列表中,最后返回
results = []
for id, text in self.__id_to_texts.items():
if query in text:
results.append(id)
return results
search_engine = SimpleEngine()
main(search_engine)
# 3 运行之后进入循环,等待用户输入需要搜索的内容query
'''
simple
found 0 result(s):
little
found 2 result(s):
1.txt
2.txt
will
found 5 result(s):
1.txt
2.txt
3.txt
4.txt
5.txt
in a
found 1 result(s):
1.txt
dream
found 3 result(s):
1.txt
2.txt
3.txt
'''