目录
- 1 数据分组统计 groupby
- 1.1 按照单列进行分组统计df.groupby('列名').count()
- 1.2 按照多列进行分组统计 df.groupby(['列名1','列名2']).count()
- 1.3 分组填充缺失值 df.groupby('需填充列名').apply(lambda x:x.fillna(x.mean()))
- 2 分组运算 agg
- 2.1 传入标准函数 df.groupby('班级').agg(np.sum)
- 2.2 不同的列不同的聚合函数 df.groupby('班级').agg({'数量':np.sum,'分数':np.mean})
- 2.3 自定义函数
- 2.4 调用多个聚合函数
- 3 数据透视表
- 3.1 透视表 pivot_table
- 3.2 交叉表 crosstab
1 数据分组统计 groupby
分割 split: 按照键值(key)或者分组变量将数据分组
应用 apply: 对每个组应用函数, 通常是累计,转换或过滤函数
组合 combine: 将每一组的结果合并成一个输出组
常用功能
1. len(gp1) #组数
2. gp1.size() #每组的记录个数
3. df3.groupby(["小组","评级"]) #得到的结果是一个groupby对象
4. gp1.mean() #每组组内的平均值,还有sum、max、min、count
5. apply #自定义统计函数(自己定义一个函数,作为参数,会自动将函数应用到每一组数据当中去)
1.1 按照单列进行分组统计df.groupby(‘列名’).count()
# 创建示例DataFrame
data = {'班级': ['一班', '一班','一班','二班', '二班','二班','三班','三班','三班'],
'科目': ['物理', '化学', '生物','物理', '化学', '生物','物理', '化学', '生物'],
'数量': [17, 29, 18,37,48,32,17, 29, 18],
'分数': [87, 89, 88,77,98,82,97, 89, 78]}
df = pd.DataFrame(data)






# 创建示例DataFrame
data = {'班级': ['一班', '一班','一班','二班', '二班','二班','三班','三班','三班'],
'科目': ['物理','生物','生物','物理', '物理', '生物','化学', '化学', '生物'],
'姓名': ['张三', '章中', '贺天','紫瞳','西德','魏斯','明峰', '希方', '塞法'],
'分数': [87, 89, 88,77,98,82,97, 89, 78]}
df = pd.DataFrame(data)
#实现组内排序,排序的时候,科目作为第一排序依据,用来排序的数值字段(分数)作为第二排序依据
df.sort_values(['科目','分数'],ascending=[False,True]).groupby('科目').head(3)

1.2 按照多列进行分组统计 df.groupby([‘列名1’,‘列名2’]).count()
# 创建示例DataFrame
data = {'班级': ['一班', '一班','一班','二班', '二班','二班','三班','三班','三班'],
'科目': ['物理','生物','生物','物理', '物理', '生物','化学', '化学', '生物'],
'姓名': ['张三', '章中', '贺天','紫瞳','西德','魏斯','明峰', '希方', '塞法'],
'分数': [87, 89, 88,77,98,82,97, 89, 78]}
df = pd.DataFrame(data)
#按照科目、班级进行分组求平均
df[['科目','班级','分数']].groupby(['科目','班级']).mean()




1.3 分组填充缺失值 df.groupby(‘需填充列名’).apply(lambda x:x.fillna(x.mean()))
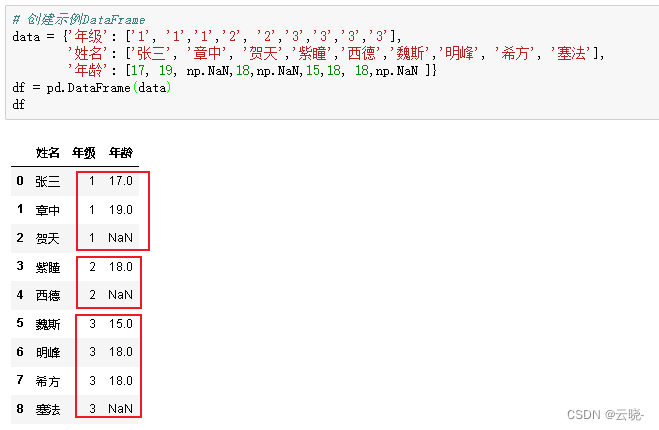
# 创建示例DataFrame
data = {'年级': ['1', '1','1','2', '2','3','3','3','3'],
'姓名': ['张三', '章中', '贺天','紫瞳','西德','魏斯','明峰', '希方', '塞法'],
'年龄': [17, 19, np.NaN,18,np.NaN,15,18, 18,np.NaN ]}
df = pd.DataFrame(data)
df
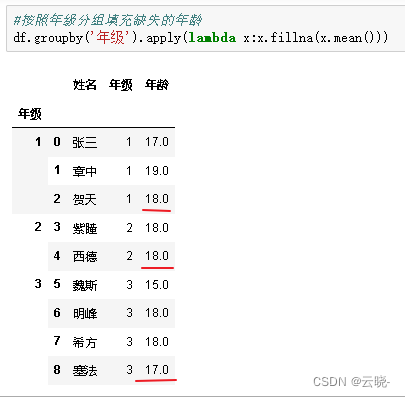
#按照年级分组填充缺失的年龄
df.groupby('年级').apply(lambda x:x.fillna(x.mean()))
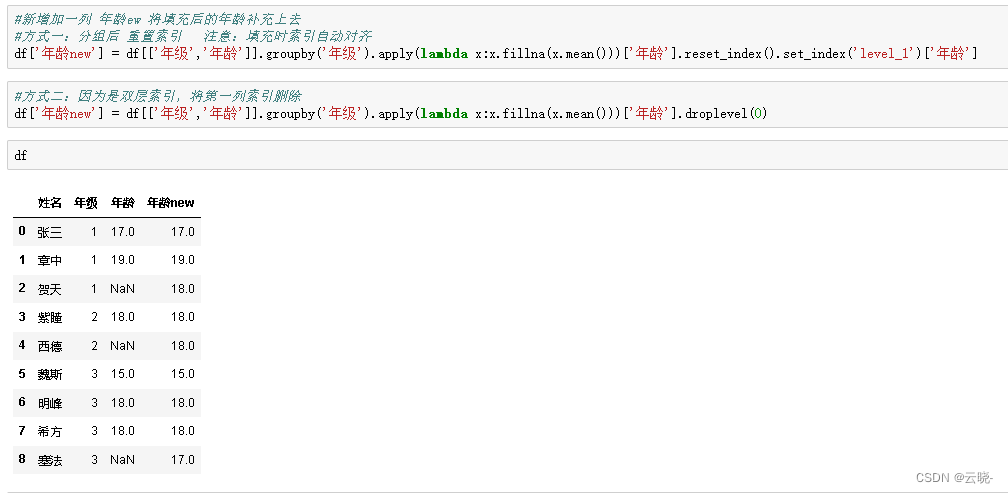
新增加一列 年龄ew 将填充后的年龄补充上去
2 分组运算 agg
数据聚合(agg):一般指的是能够从数组产生的标量值的数据转换过程,常见的聚合运算都有相关的统计函数快速实现,也可以自定义聚合运算。
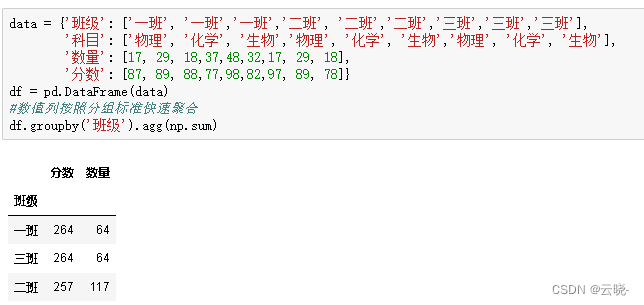
2.1 传入标准函数 df.groupby(‘班级’).agg(np.sum)
data = {'班级': ['一班', '一班','一班','二班', '二班','二班','三班','三班','三班'],
'科目': ['物理', '化学', '生物','物理', '化学', '生物','物理', '化学', '生物'],
'数量': [17, 29, 18,37,48,32,17, 29, 18],
'分数': [87, 89, 88,77,98,82,97, 89, 78]}
df = pd.DataFrame(data)
#数值列按照分组标准快速聚合
df.groupby('班级').agg(np.sum)
2.2 不同的列不同的聚合函数 df.groupby(‘班级’).agg({‘数量’:np.sum,‘分数’:np.mean})
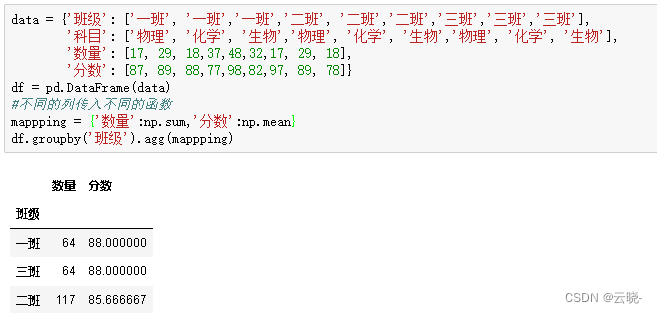
#不同的列传入不同的函数
mappping = {'数量':np.sum,'分数':np.mean}
df.groupby('班级').agg(mappping)
2.3 自定义函数
#求针对各科目最高分数与最低分数之间的差值
def cha(x):
return x.max() - x.min()
df[['科目','分数']].groupby('科目').agg([cha])

2.4 调用多个聚合函数
df[['班级','分数']].groupby('班级').agg([np.max,np.min,np.mean])

3 数据透视表
3.1 透视表 pivot_table
透视表(pivot table): 透视表指根据一个或多个键值对数据进行聚合,根据行或列的分组键将数据划分到各个区域中
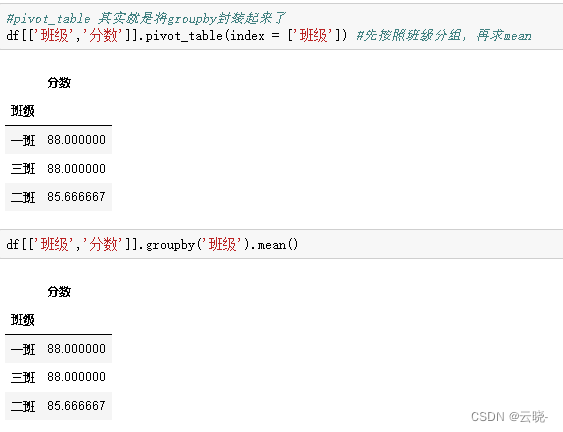
#pivot_table 其实就是将groupby封装起来了
df[['班级','分数']].pivot_table(index = ['班级']) #先按照班级分组,再求mean
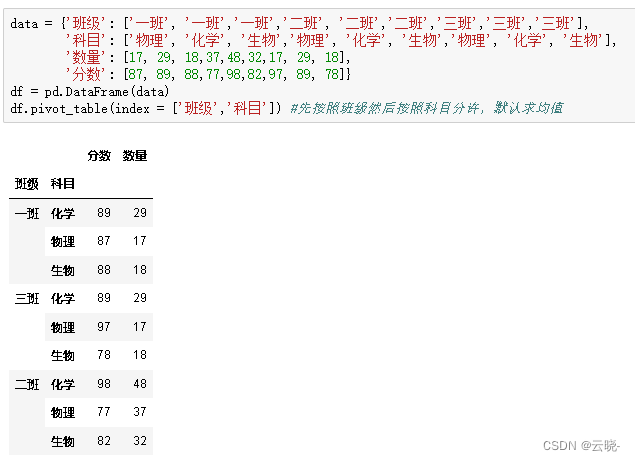
data = {'班级': ['一班', '一班','一班','二班', '二班','二班','三班','三班','三班'],
'科目': ['物理', '化学', '生物','物理', '化学', '生物','物理', '化学', '生物'],
'数量': [17, 29, 18,37,48,32,17, 29, 18],
'分数': [87, 89, 88,77,98,82,97, 89, 78]}
df = pd.DataFrame(data)
df.pivot_table(index = ['班级','科目']) #先按照班级然后按照科目分许,默认求均值
df.pivot_table(index = ['班级'],aggfunc = np.sum)#求和

pd.pivot_table(df3,values="总分",index="评级",columns=["班级","小组"])

3.2 交叉表 crosstab
交叉表(crosstab): 交叉表用于统计分组频率的特殊透视表
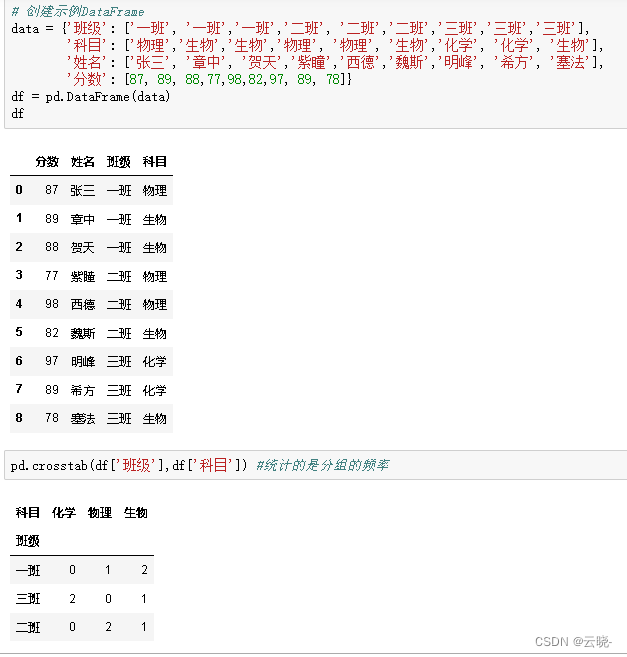
#groupby实现pd.crosstab(df['班级'],df['科目'])
df[['班级','科目','姓名']].groupby(['班级','科目']).count().unstack().fillna(0)