https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
一、说明
本篇叙述了KL 散度的数学、直觉和如何实际使用;以及它如何最好地用于过程监测。Kullback-Leibler 散度度量(相对熵)是信息论中的一种统计测量方法,通常用于量化一个概率分布与参考概率分布之间的差异。
虽然 KL 散度很受欢迎,但它有时会被误解。在实践中,有时也很难知道何时使用一种统计距离检查而不是另一种。这篇博文介绍了如何使用 KL 散度、它在实践中的工作原理,以及何时应该和不应该使用 KL 散度来监控漂移。
二、背景知识
2.1 散度和距离的关系
统计模型的度量方法,因为部分满足距离空间的条件,因而不能叫距离,叫散度。
在统计学、概率论和信息论中,统计距离量化了两个统计对象之间的距离,可以是两个随机变量,也可以是两个概率分布或样本,也可以是单个样本点与总体或总体之间的距离。更广泛的点样本。
总体之间的距离可以解释为测量两个概率分布之间的距离,因此它们本质上是概率测量之间距离的测量。当统计距离度量与随机变量之间的差异相关时,这些可能具有统计相关性,[1] 因此这些距离与概率度量之间的距离度量没有直接关系。同样,衡量随机变量之间的距离可能与它们之间的依赖程度有关,而不是与它们各自的值有关。
统计距离度量通常不是度量,并且它们不必是对称的。某些类型的距离度量(概括平方距离)被称为(统计)散度。
2.2 如何计算 KL 散度?
KL散度(Kullback-Leibler divergence)也称为相对熵,是用来比较两个概率分布的差异性的度量。用KL散度来衡量两个概率分布之间的差异,可以用于模型选择、特征选取、模型融合等领域。KL散度是非对称的,也就是说,。 KL散度的公式如下:
其中, P(i) 、 Q(i) 分别表示事件i在两个概率分布P和Q中的概率。 KL散度是一个非负的实数,当且仅当两个概率分布完全相同时,KL散度为0。 KL散度越大,说明两个分布之间差异越大。
KL 散度是一种非对称指标,用于衡量两个分布所代表的信息的相对熵或差异。它可以被认为是测量两个数据分布之间的距离,显示两个分布之间的差异程度。
KL 散度同时存在连续形式
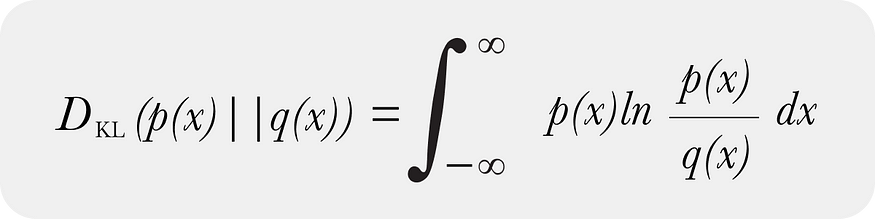
以及 KL 散度的离散形式:
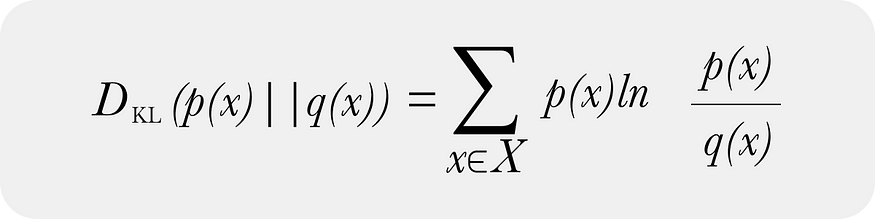
在模型监控中,大多数从业者几乎专门使用 KL 散度的离散形式,并通过数据分箱获得离散分布。 KL 散度的离散形式和连续形式确实随着样本数和 bin 限制移动到无穷大而收敛。对于接近连续形式的 bin 数量,存在最佳选择方法。在实践中,箱的数量可能远远小于上述数字所暗示的数量 - 并且如何创建这些箱来处理 0 个样本箱的情况实际上比其他任何事情都更重要(未来的代码帖子将解决如何处理自然为零垃圾箱)。
三、KL散度如何用于模型监控
在模型监控中,KL 散度用于监控生产环境,特别是围绕特征和预测数据。 KL 散度用于确保生产中的输入或输出数据不会从基线发生巨大变化。基线可以是数据的训练生产窗口或训练或验证数据集。
对于接收延迟的地面事实以与生产模型决策进行比较的团队来说,漂移监控特别有用。这些团队可以依靠预测和特征分布的变化作为性能的代理。
KL 散度通常独立应用于每个特征;它不是被设计为协变特征度量,而是一个显示每个特征如何独立于基线值的指标。
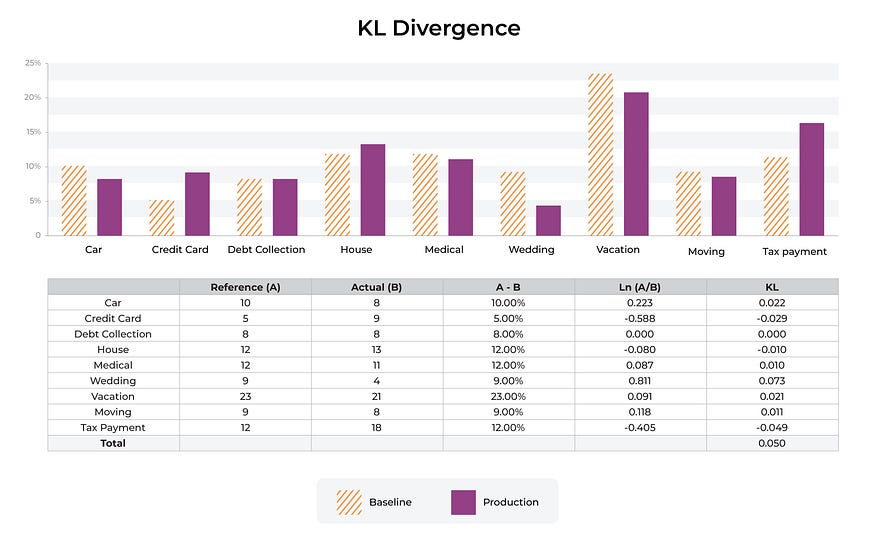
上面以橙色条纹显示的 p(x) 是参考或基线分布。最常见的基线是生产数据的跟踪窗口或训练数据集。每个 bin 都会对 KL 散度产生附加贡献。这些箱加起来就是总的百分比分布。
✏️ 注意:有时,非实践者有一个有点过于热心的目标,即完善捕获数据变化的数学。在实践中,重要的是要记住,实际数据在生产中一直在变化,并且许多模型可以很好地扩展到这些修改后的数据。使用漂移指标的目标是拥有可靠、稳定且非常有用的指标来进行故障排除
四、KL 散度是不对称度量吗?
是的。如果你交换基线分布 p(x) 和样本分布 q(x),你会得到一个不同的数字。作为一个非对称指标有许多缺点,因为团队使用 KL 散度来解决数据模型比较问题。有时,团队希望在故障排除工作流程中将比较基线替换为不同的分布,并且 A/B 与 B/A 不同的指标可能会使比较结果变得困难。

这是 Arize(全面披露:我是 Arize 的联合创始人)等模型监控工具默认使用群体稳定性指数 (PSI)(KL 散度的对称推导)作为用于分布模型监控的主要指标之一的原因之一。
五、连续数值特征和分类特征之间的差异
KL 散度可用于衡量数值分布和分类分布之间的差异。
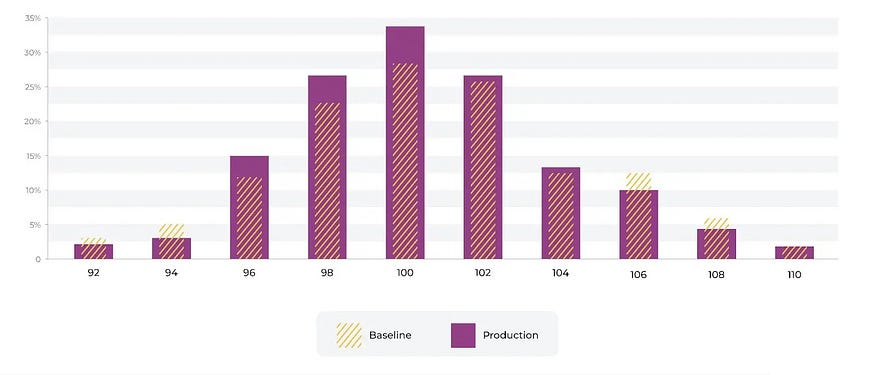
5.1 数值属性
对于数值分布,数据根据截止点、箱大小和箱宽度分为箱。分箱策略可以是均匀分箱、五分位数和复杂的策略组合,并且确实会在很大程度上影响 KL 散度。
5.2 分类属性(Categorical)
KL 散度的监控跟踪分类数据集中的大分布变化。在分类特征的情况下,通常存在基数太大以至于度量没有多大用处的大小。理想的大小是大约 50-100 个唯一值——因为一个分布具有更高的基数,两个分布有多大不同以及它是否真的重要的问题变得混乱。
5.3 高基数
在高基数特征监控的情况下,开箱即用的统计距离通常效果不佳 - 相反,我们通常推荐两种选择:
- 的 嵌入:在某些高基数情况下,正在使用的值(例如用户 ID 或内容 ID)已用于在内部创建嵌入。嵌入漂移监控可以提供帮助。
- 纯高基数分类:在其他情况下,模型将输入编码到一个大空间,只需监控 KL 散度的前 50-100 个顶级项目并将所有其他值作为“其他”可能会很有用。
最后,有时您想要监控的内容非常具体,例如一段时间内新值或分箱的百分比。这些可以通过数据质量监视器进行更具体的设置。
六、示例
以下是一组用用示例:
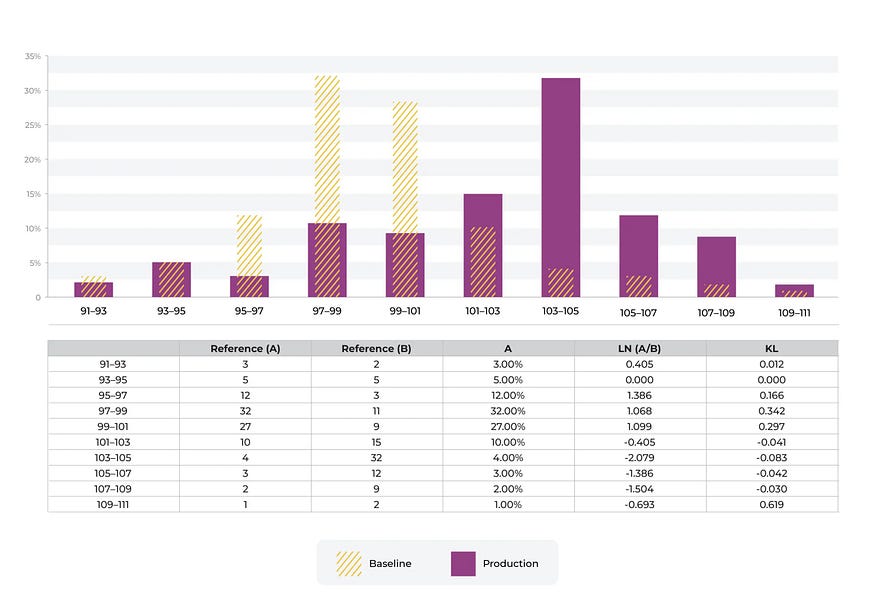
想象一下,我们有一个预测信用卡欺诈的模型的收费金额的数字分布。该模型是使用上图所示的训练基线构建的。我们可以看到费用的分布发生了变化。有许多关于阈值的行业标准,我们实际上建议使用生产跟踪值来设置自动阈值。生产中有很多示例 <> 的固定设置没有意义。
七、KL 散度背后的直觉
重要的是要对指标和基于分布变化的指标变化有一些直觉。
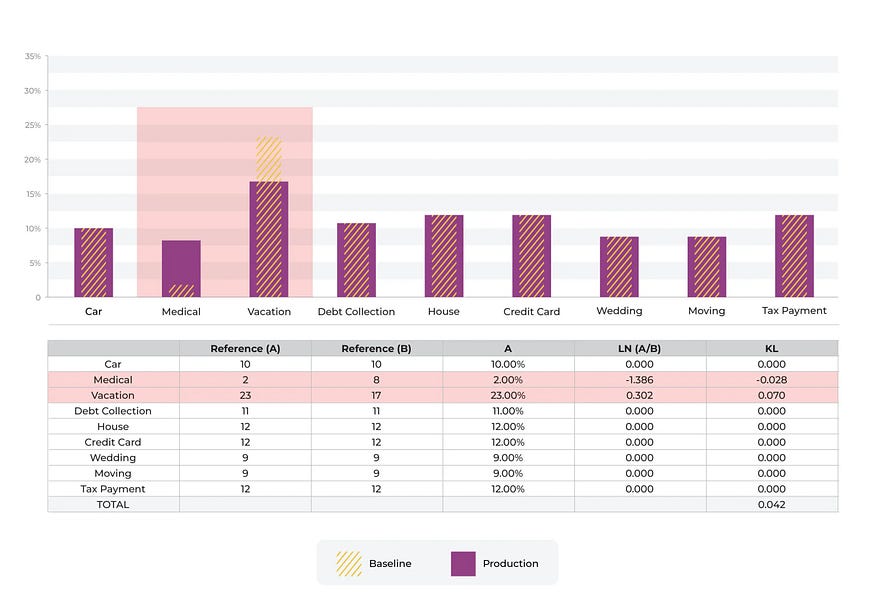
上面的示例显示了从一个分类箱移动到另一个分类箱的情况。将“医疗”作为特征(贷款收益的使用)输入的预测从 2% 增加到 8%,而将“假期”作为输入的预测从 23% 下降到 17%。
在此示例中,与“医疗”相关的 KL 散度分量为 -0.028,小于“假期”百分比移动的分量 0.070。
一般来说,减少百分比并将其移向 0 的移动将对该统计数据产生更大的影响,相对于百分比的增加。

相对于行业标准数字 0.2 获得较大移动的唯一方法是将 bin 向下移动到 0。在本例中,将 bin 从 9% 移动到 0.5% 会使 KL 散度移动很大。
这是一个电子表格,供那些想要使用和修改这些百分比以更好地理解直觉的人使用。值得注意的是,这种直觉与 PSI 有很大不同。
八、结论
如果您正在考虑使用 KL 散度来测量漂移,请务必记住以下几点。首先,大多数从业者发现最简单的方法是使用 KL 散度的离散形式,并通过对数据进行分箱来获得离散分布(更多关于分箱挑战的内容将在以后的文章中介绍)。其次,虽然了解 KL 散度背后的直觉和数学很重要,但有时其他指标(例如 PSI(KL 散度的对称推导))或方法可能更有用,具体取决于您的用例。