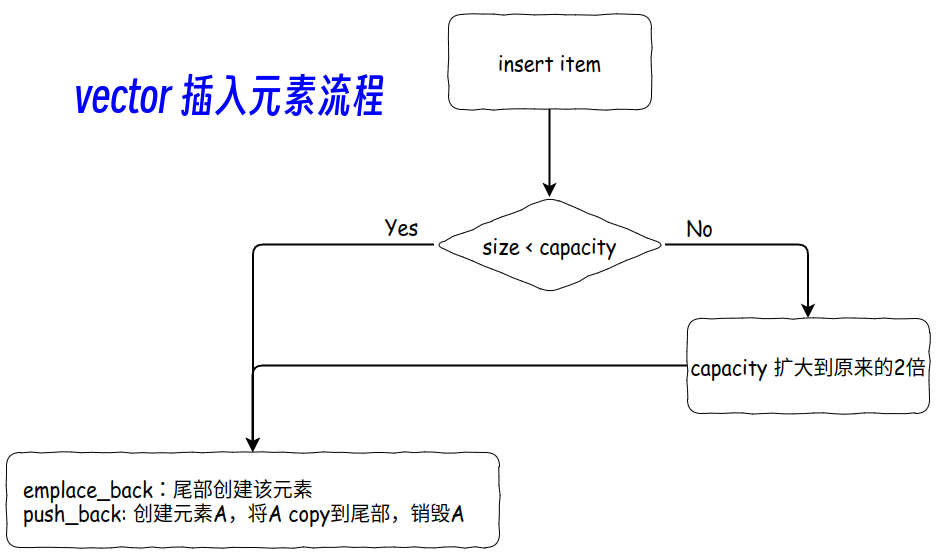
文章目录
- 图像生成简单介绍—使用GANs给出代码示例
- 1. 什么是生成对抗网络(GANs)
- 2. 准备数据集
- 3. 构建生成器和判别器
- 4. 训练GAN模型
- 5. 生成新图像
- 6. 总结
图像生成简单介绍—使用GANs给出代码示例
图像生成是指使用计算机算法生成图像的过程。这些图像可以是真实的照片、绘画、3D渲染或者是完全想象的图像。图像生成技术涵盖了一系列算法,包括基于规则的方法、基于统计学的方法、深度学习等。
基于规则的方法通常是通过手动设计规则来生成图像。例如,计算机图形学中的几何建模就是一种基于规则的方法,通过定义几何形状、光照、材质等参数来生成图像。
基于统计学的方法则是通过对大量图像数据进行分析,学习数据中的规律,然后使用这些规律来生成新的图像。这些方法包括基于纹理的方法、基于样式的方法等。
深度学习方法则是最近几年兴起的一种生成图像的方法,它利用神经网络模型进行训练,以学习输入图像和输出图像之间的映射关系。这些模型包括生成对抗网络(GAN)、变分自编码器(VAE)等,能够生成高质量、逼真的图像。
图像生成技术在许多领域都有应用,例如计算机游戏、电影制作、虚拟现实、视觉特效等。同时,它也在艺术创作、产品设计、医学图像处理等领域得到广泛应用。
图像生成是一种涉及生成新图像样本的技术,通常基于深度学习模型。在这份教程中,我们将介绍如何使用生成对抗网络(GANs)生成图像。
1. 什么是生成对抗网络(GANs)
生成对抗网络(GANs)是一种深度学习技术,由两个独立的神经网络组成:生成器(Generator)和判别器(Discriminator)。生成器的任务是生成与真实图像类似的图像,而判别器的任务是区分生成的图像是否为真实图像。这两个网络相互竞争,生成器试图生成越来越真实的图像,而判别器试图越来越准确地识别生成的图像。
2. 准备数据集
首先,我们需要一个用于训练的图像数据集。这里,我们以CIFAR-10数据集为例进行说明。CIFAR-10包含10个类别的60000张32x32彩色图像。我们将使用PyTorch框架,首先需要安装并导入相应的库:
!pip install torch torchvision
import torch
import torchvision
import torchvision.transforms as transforms
接下来,加载和预处理数据:
transform = transforms.Compose([
transforms.Resize(64),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
3. 构建生成器和判别器
接下来,我们需要构建生成器和判别器网络。这里,我们使用卷积层和反卷积层构建网络。生成器的输入是随机噪声,输出是生成的图像;判别器的输入是图像,输出是它判断图像是否为真实图像的概率。
import torch.nn as nn
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 64 * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(64 * 8),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 8, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 4, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 2, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, x):
x = self.main(x)
return x
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 2, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 4, 64 * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
x = self.main(x)
return x
generator = Generator()
discriminator = Discriminator()
4. 训练GAN模型
为了训练模型,我们需要定义损失函数和优化器。这里我们使用二元交叉熵损失(Binary Cross Entropy Loss)和Adam优化器。
criterion = nn.BCELoss()
optimizer_g = torch.optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_d = torch.optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
现在我们可以开始训练模型。在每个训练循环中,我们首先训练判别器,然后训练生成器。
save_every = 10 # 保存模型的频率,每训练十次保存一次
start_time = time.time() # 获取开始时间
log_file = open("training_log.txt", "a")
num_epochs = 100
for epoch in range(num_epochs):
for i, (images, _) in enumerate(trainloader):
# Train discriminator
discriminator.zero_grad()
real_images = images.to(device)
batch_size = real_images.size(0)
label = torch.full((batch_size,), 1, device=device, dtype=torch.float)
output = discriminator(real_images).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
noise = torch.randn(batch_size, 100, 1, 1, device=device)
fake_images = generator(noise).to(device)
label.fill_(0.0)
output = discriminator(fake_images.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
errD = errD_real + errD_fake
optimizer_d.step()
# Train generator
generator.zero_grad()
label.fill_(1)
output = discriminator(fake_images).view(-1)
errG = criterion(output, label)
errG.backward()
optimizer_g.step()
# 保存模型
if (epoch+1) % save_every == 0:
generator_name = f'generator_{epoch+1}.pth'
discriminator_name = f'discriminator_{epoch+1}.pth'
torch.save(generator, generator_name)
torch.save(discriminator, discriminator_name)
# 将输出打印到终端并保存到log文件中
log_str = f'Epoch [{epoch+1}/{num_epochs}] Loss_D: {errD.item():.4f} Loss_G: {errG.item():.4f} Time: {time.time()-start_time:.2f}s\n'
print(log_str)
log_file.write(log_str)
log_file.flush() # 刷新缓冲区
log_file.close()
代码开始运行

5. 生成新图像
训练完成后,我们可以使用生成器来生成新的图像。
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 64 * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(64 * 8),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 8, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 4, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 2, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, x):
x = self.main(x)
return x
# generator = Generator()
# 加载保存的模型文件,'model/generator_82.pth'填写自己的生成模型文件路径
generator = torch.load('model/generator_82.pth', map_location=device)
generator.to(device)
with torch.no_grad():
noise = torch.randn(1, 100, 1, 1, device=device)
generated_image = generator(noise)
def imshow(img):
img = img / 2 + 0.5 # unnormalize
np_img = img.cpu().numpy()
plt.imshow(np.transpose(np_img, (1, 2, 0)))
plt.show()
imshow(torchvision.utils.make_grid(generated_image.cpu()))
通过上述代码通过加载生成器模型,可以生成图片,这个模型训练的次数一般越多越好,我训练的82次,也就图一乐,虽说图片啥也不是,但是勉强有图片轮廓。
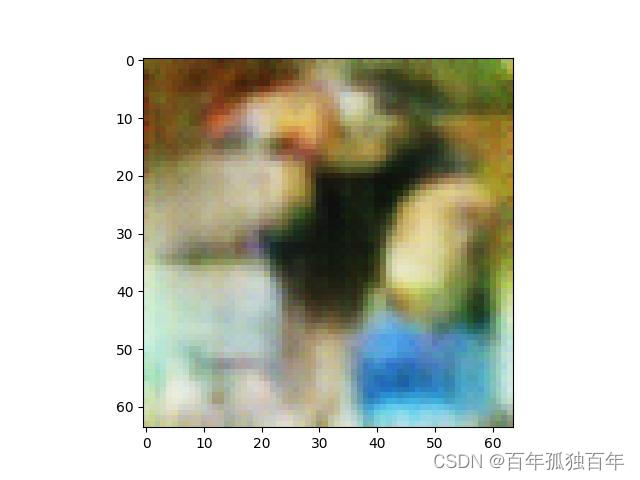
如果不调用生成模型,将上述代码修改为如下
generator = Generator()
# 加载保存的模型文件,'model/generator_82.pth'填写自己的生成模型文件路径
# generator = torch.load('model/generator_82.pth', map_location=device)
generator.to(device)
重新运行代码,可得到下面随机噪声的图片,说明我们生成器模型是有点作用的,刚才的图片并不是随机噪声,随机噪声是下面这种图片。
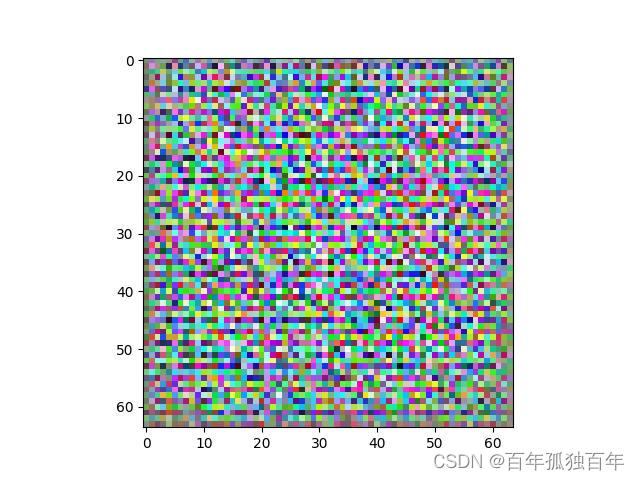
6. 总结
在本教程中,我们介绍了如何使用生成对抗网络(GANs)生成图像。我们以 CIFAR-10 数据集为例,构建了生成器和判别器网络,并进行了训练。最后,我们使用训练好的生成器生成了新的图像。
GANs 是一种非常强大的图像生成技术,但训练过程可能具有挑战性。为了获得高质量的生成图像,可能需要调整网络结构、损失函数和训练参数。此外,还有许多 GANs 的变体可供尝试,如 Deep Convolutional GANs(DCGANs)、Wasserstein GANs(WGANs)等。