参考教程:
what is DDP
pytorch distributed overview
文章目录
- DDP介绍
- 什么是DDP
- DistributedSampler()
- DistributedDataParallel()
- 使用DDP
- 代码示例
- multiprocessing.spawn()
- save and load checkpoints
DDP介绍
什么是DDP
DDP的全称是DistributedDataParallel,它允许使用pytorch使用数据并行训练。
在非分布式训练中,你的模型被放在一个gpu上,你的模型接收来自一个dataloader的inputbatch,它对输入进行前向传播并且计算损失,然后进行反向传播并计算参数的梯度。优化器在这个过程中对模型的参数进行更新。
当我们现在多个gpu上进行训练时,DDP会在每个GPU上都启动一个进程,每个进程中都有一个模型的复制品replica(local copy),每一个模型和优化器的复制品都是相同的。模型的参数初始化相同,优化器也使用一样的随机种子。DDP在训练过程中维持了这种一致性。
现在,每个gpu的模型都是一样的。我们仍然从dataloader中获取inputbatch,但是这个时候我们使用的是DistributedSampler。这个sampler保证了每个模型接收到的inputbatch是不同的,这就是“data parallel” in DDP。
在每个进程中,模型接收到一个不同的输入,并且locally的进行前向传播和后向传播。因为输入是不同的,所以梯度的累积也是不同的。使用optimizer.step()会产生不同的结果。比如说我们现在有4个gpu,在4个gpu上有4个模型的local copy,那么这四个模型就是不同的模型,而不是我们想要的一个分布式的模型。
DDP中的同步机制,会把来自四个replicas的梯度累加起来,其中使用了一个算法,在replicas间进行通信,它不会等待所有的梯度都计算完成,而是在计算过程中就保持着通信,这保证了你的gpu总是在工作的。
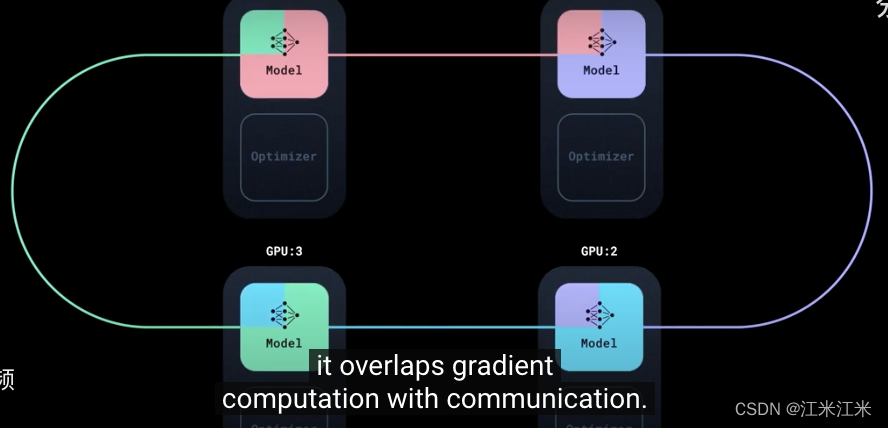
综合来说,就是在n个gpu上的训练相当于同时进行n个模型的训练,这些模型是完全一样的,实时同步的,只不过传入的数据不一样。
DistributedSampler()
在之前介绍数据集构建的时候曾经提到过sampler的概念。假如dataloader中的shuffle = True,你使用的就是一个randomsampler;假如dataloader中的shuffle = False,你使用的就是一个sequentialsampler。
torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)
DistributedSampler传入的第一个参数是dataset,它要求这个Dataset有一个constant的大小。iterable dataset也可以使用DDP,参考https://github.com/Lightning-AI/lightning/issues/15734。我先不看了,用的时候再说。
第二个参数是num_replicas,你想要复制的个数。第三个参数是rank,是当前的process的index。shuffle和seed主要是控制你的dataset是否要shuffle和随机种子。
DistributedSampler()一般和torch.nn.parallel.DistributedDataParallel组合使用。在这种情况下,每一个进程都会传递一个DistributedSampler实例,并且加载原始数据中彼此完全不同的子集。
在构造函数初始化阶段,会计算每个replica中分配到的samples数。
if self.drop_last and len(self.dataset) % self.num_replicas != 0: # type: ignore[arg-type]
# Split to nearest available length that is evenly divisible.
# This is to ensure each rank receives the same amount of data when
# using this Sampler.
self.num_samples = math.ceil(
(len(self.dataset) - self.num_replicas) / self.num_replicas # type: ignore[arg-type]
)
else:
self.num_samples = math.ceil(len(self.dataset) / self.num_replicas) # type: ignore[arg-type]
最终获得的dataset中数据的总数就是
self.total_size = self.num_samples * self.num_replicas
在取数据的时候,会把不同的数据分配给不同的replicas。
indices = indices[self.rank:self.total_size:self.num_replicas]
在使用DistributedSampler时,在每个epoch都需要调用set_epoch(epoch)函数,这样每个epoch里数据都会按照不同的顺序获取,如果不调用的话,获取的顺序将始终保持一致。因为它随机种子的生成也和当前的epoch有关系。
g.manual_seed(self.seed + self.epoch)
下面给出了一个使用的例子。
sampler = DistributedSampler(dataset) if is_distributed else None
loader = DataLoader(dataset, shuffle=(sampler is None),
sampler=sampler)
for epoch in range(start_epoch, n_epochs):
if is_distributed:
sampler.set_epoch(epoch)
train(loader)
DistributedDataParallel()
torch.nn.parallel.DistributedDataParallel(module, device_ids=None, output_device=None, dim=0, broadcast_buffers=True, process_group=None, bucket_cap_mb=25, find_unused_parameters=False, check_reduction=False, gradient_as_bucket_view=False, static_graph=False)
DDP为了保证不同gpu上的模型能完成同步,需要进行较为繁琐的设置。
使用这个类要求你先对torch.distributed进行初始化,通过调用方法。
torch.distributed.init_process_group(backend=None, init_method=None, timeout=datetime.timedelta(seconds=1800), world_size=- 1, rank=- 1, store=None, group_name='', pg_options=None)
在DistributedDataParallel()中,第一个参数module是你想要并行话的module,在训练中也就是你的模型。
参数device_id和output_device代表你的moudle的CUDAdevice和你的output的CUDAdevice。
process_group如果为None,会默认使用你的torch.distributed.init_process_group。
给出一个简单的示例
torch.distributed.init_process_group(backend='nccl', world_size=4, init_method='...')
net = torch.nn.parallel.DistributedDataParallel(model)
为了让你的DDP能够在N个GPU上使用,你需要产生N个进程,并且保证每个进程独立的工作在一个GPU上。有两个方法可以完成这个设置。
第一个方法是:
torch.cuda.set_device(i)
在每个进程中,你需要进行以下的设置。
torch.distributed.init_process_group(
backend='nccl', world_size=N, init_method='...'
)
model = DistributedDataParallel(model, device_ids=[i], output_device=i)
使用DDP
建议直接参考https://github.com/pytorch/examples/blob/main/distributed/ddp-tutorial-series/multigpu.py。给出了一个完整的模版,可以直接套用。
代码示例
教程中给出了一个比较简单但完整的DDP示例。
在这个例子中,init_process_group被封装到一个setup函数里。
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
然后定义一个作为例子的小模型。使用torch.multiprocess产生多个进程,rank表示当前的进程数,或者说CUDA id。world_size代表了gpu的个数。在每个进程中,将你的model放到对应的device上。
这个例子中没有加入dataset的部分。只有DDP中模型的使用。
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
multiprocessing.spawn()
torch.multiprocessing.spawn(fn, args=(), nprocs=1, join=True, daemon=False, start_method='spawn')
torch.multiprocessing基本上就是在python的multiprocessing上进行了一些改动。具体的不讲了【因为我也没有看】,我们只说一下spawn。
spawn的输入包括 fn:目标函数, args:函数的参数,nprocs:需要的进程数。
在使用这个方法后,multiprocessing会以‘spawn’的方法来创建新的进程。创建的数量由nprocs决定。
for i in range(nprocs):
error_queue = mp.SimpleQueue()
process = mp.Process(
target=_wrap,
args=(fn, i, args, error_queue),
daemon=daemon,
)
process.start()
error_queues.append(error_queue)
processes.append(process)
可以看到在下方代码的mp.Process中使用的target是一个名为_wrap的函数。这个函数把当前process对应的index和args组合在一起,作为输入传入到fn中去。所以理论上来讲,你定义的fn的传入参数数量至少为1个,也就是当前进程的index。而在使用torch中的mp.spawn()时,args里面你不能把这个参数写出来,而只需要写第二个以及以后的参数。
def _wrap(fn, i, args, error_queue):
# prctl(2) is a Linux specific system call.
# On other systems the following function call has no effect.
# This is set to ensure that non-daemonic child processes can
# terminate if their parent terminates before they do.
_prctl_pr_set_pdeathsig(signal.SIGINT)
try:
fn(i, *args) # index和args一起作为args传给了fn
except KeyboardInterrupt:
pass # SIGINT; Killed by parent, do nothing
except Exception:
# Propagate exception to parent process, keeping original traceback
import traceback
error_queue.put(traceback.format_exc())
sys.exit(1)
save and load checkpoints
模型的保存和加载方法和之前的使用上区别不大。只是加了一点限制。
在下方的示例代码中,在DDP中保存state_dict()时用的是model.module.state_dict()。确认了一下发现在ddp(model)的示例化时,model会被赋值给self.module。
但是有的例子中并没有使用module.state_dict()来完成保存。
这里为了防止重复保存model,限制了只在gpu_id == 0 时才进行模型的保存。
- ckp = self.model.state_dict()
+ ckp = self.model.module.state_dict()
...
...
- if epoch % self.save_every == 0:
+ if self.gpu_id == 0 and epoch % self.save_every == 0:
self._save_checkpoint(epoch)
一个优化方法是将模型的每次更新都保存在一个进程上然后被加载到所有进程中,这样可以防止多次写入。因为所有的进程都是从一样的参数开始的,并且bp中的梯度计算总是同步的,因此不同gpu上的optimizer也要保持同步。
** make sure no process starts loading before the saving is finished。**
在下面的例子中,在rank == 0的情况下才会进行model的保存。使用dist.barrier()限制了save期间的别的process对模型的加载。
def demo_checkpoint(rank, world_size):
print(f"Running DDP checkpoint example on rank {rank}.")
setup(rank, world_size)
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"
if rank == 0:
# All processes should see same parameters as they all start from same
# random parameters and gradients are synchronized in backward passes.
# Therefore, saving it in one process is sufficient.
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# Use a barrier() to make sure that process 1 loads the model after process
# 0 saves it.
dist.barrier()
# configure map_location properly
map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}
ddp_model.load_state_dict(
torch.load(CHECKPOINT_PATH, map_location=map_location))
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
# Not necessary to use a dist.barrier() to guard the file deletion below
# as the AllReduce ops in the backward pass of DDP already served as
# a synchronization.
if rank == 0:
os.remove(CHECKPOINT_PATH)
cleanup()