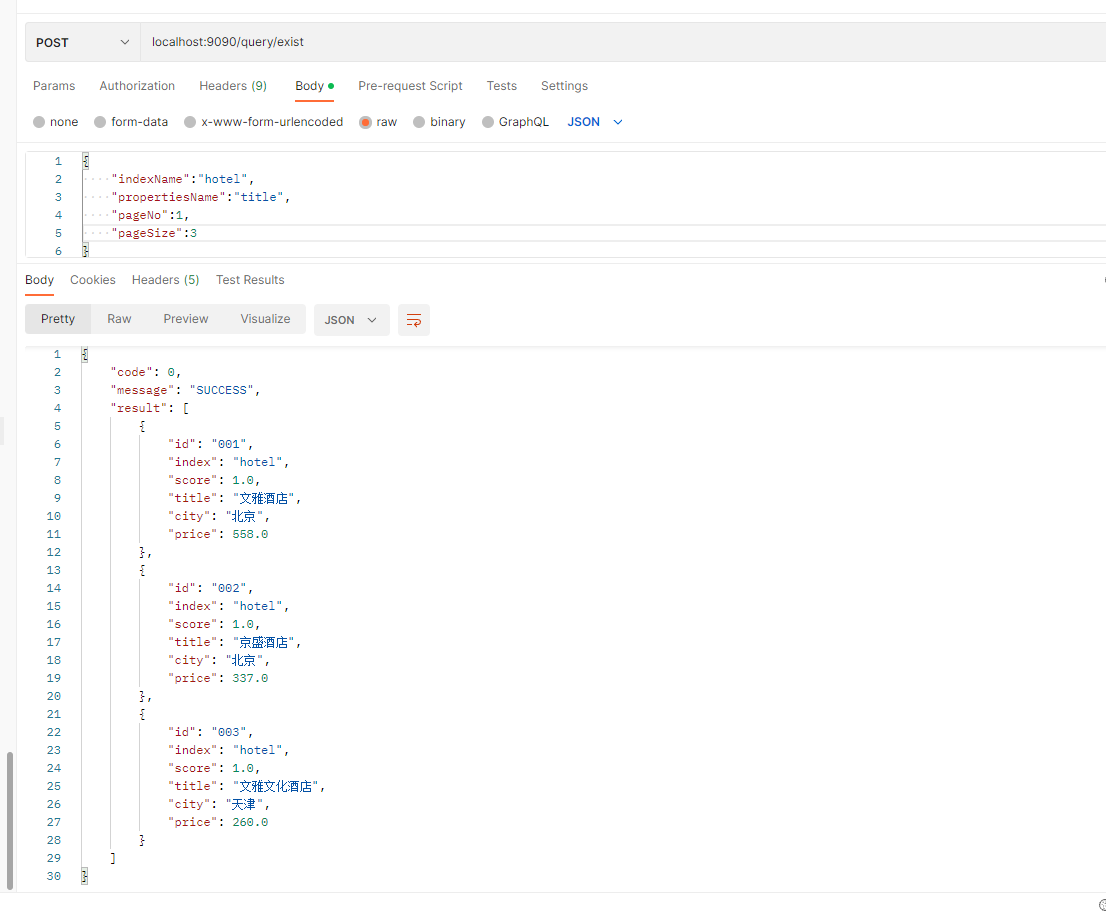
转子:https://tech.meituan.com/2022/03/10/exploration-and-practice-of-heterogeneous-ad-mixed-ranking-in-meituan-ads.html
1 背景与简介
1.1 背景
美团到店广告负责美团搜索流量的商业变现,服务于到店餐饮、休娱亲子、丽人医美、酒店旅游等众多本地生活服务商家。质量预估团队负责广告系统中CTR/CVR以及客单价/交易额等质量分预估,在过去几年中,我们通过位次上下文建模[1]、时空超长序列建模[2]等创新技术,在CTR预估问题中的用户、上下文等方向都取得了一些突破[3],并整理成论文发表在SIGIR、ICDE、CIKM等国际会议上。
不过以上论文重在模型精度,而模型精度与广告候选共同决定着排序系统的质量。但在广告候选角度,相比于传统电商的候选集合,美团搜索广告因LBS(Location Based Services, 基于位置的服务)的限制,所以在某些类目上门店候选较少,而候选较少又严重制约了整个排序系统的潜力空间。当用传统方式来增加候选数量的方法无法取得收益时,我们考虑将广告候选进行扩展与优化,以期提升本地生活场景排序系统的潜能上限。
1.2 场景介绍
单一的门店广告不足以满足用户找商品、找服务的细粒度意图诉求。部分场景将商品广告作为门店广告的候选补充,两者以竞争方式来确定展示广告样式;此外,还有部分场景商品广告以下挂形式同门店广告进行组合展示。多种形式的异构广告展示样式,给到店广告技术团队带来了机遇与挑战,我们根据业务场景特点,针对性地对异构广告进行了混排优化。下文以美团结婚频道页和美团首页搜索为例,分别介绍两类典型异构混排广告:竞争关系异构广告和组合关系异构广告。
-
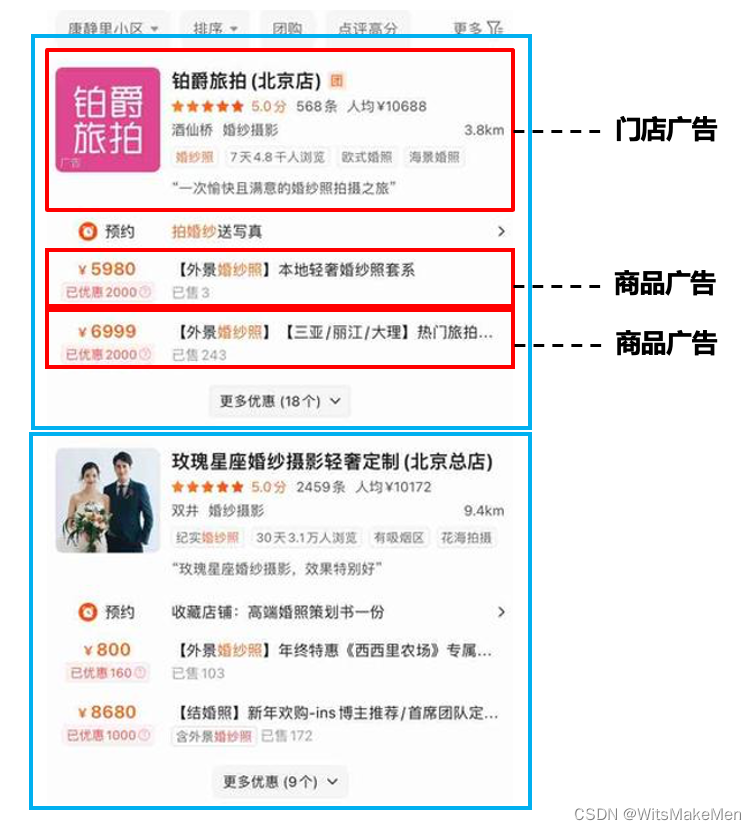
竞争关系异构广告:门店和商品两种类型广告竞争混排,通过比较混排模型中pCTR确定广告展示类型。如下图1所示,左列首位为门店类型广告胜出,展示内容为门店图片、门店标题和门店星级评论数;右列首位为商品类型广告胜出,展示内容为商品图片、商品标题和对应门店。广告系统决定广告的排列顺序和展示类型,当商品类型广告获胜时,系统确定展示的具体商品。

-
组合关系异构广告:门店广告和其商品广告组合为一个展示单元(蓝色框体)进行列表排序,商品从属于门店,两种类型异构广告组合混排展示。如下图2所示,门店广告展示门店的头图、标题价格等信息;两个商品广告展示商品价格、标题和销量等信息。广告系统确定展示单元的排列顺序,并在门店的商品集合中确定展示的Top2商品。
1.3 挑战与做法简介
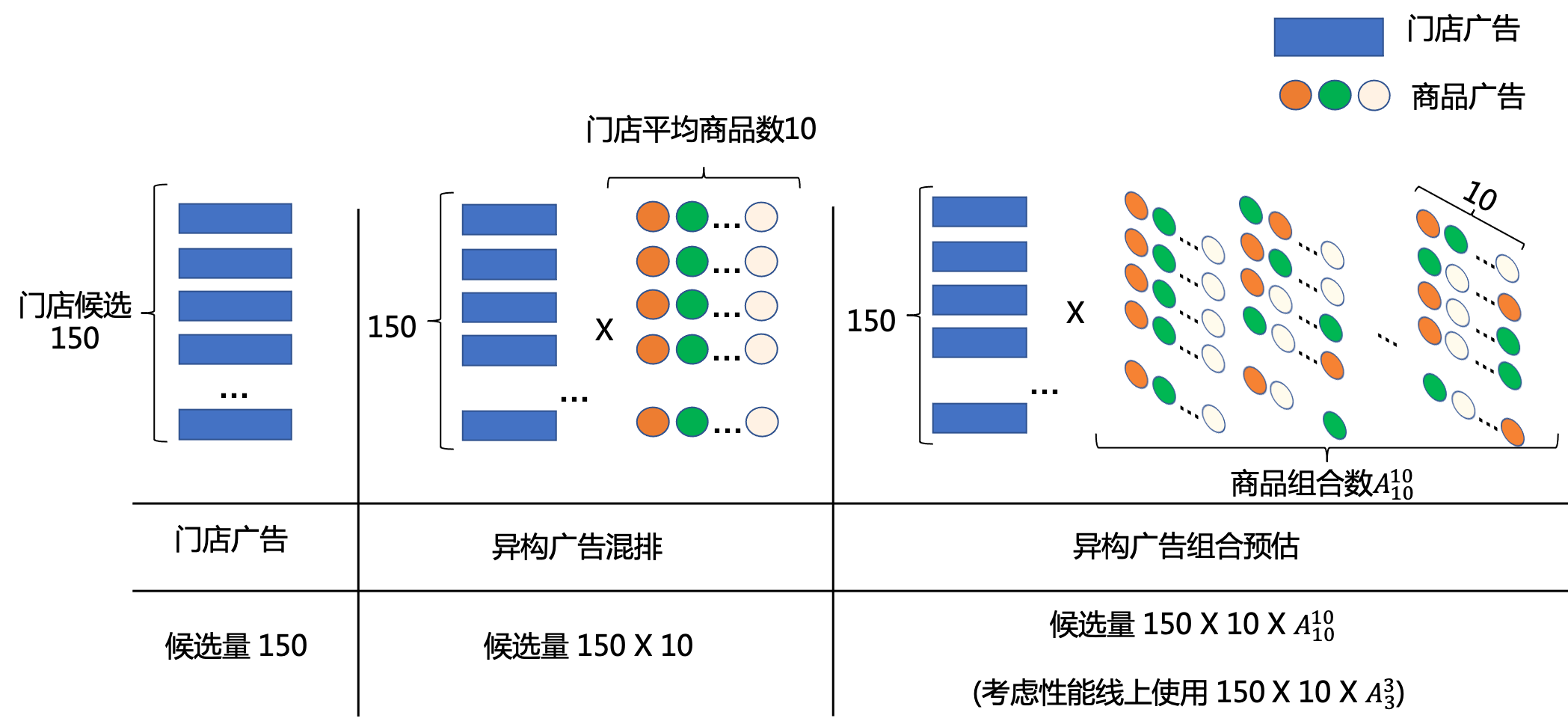
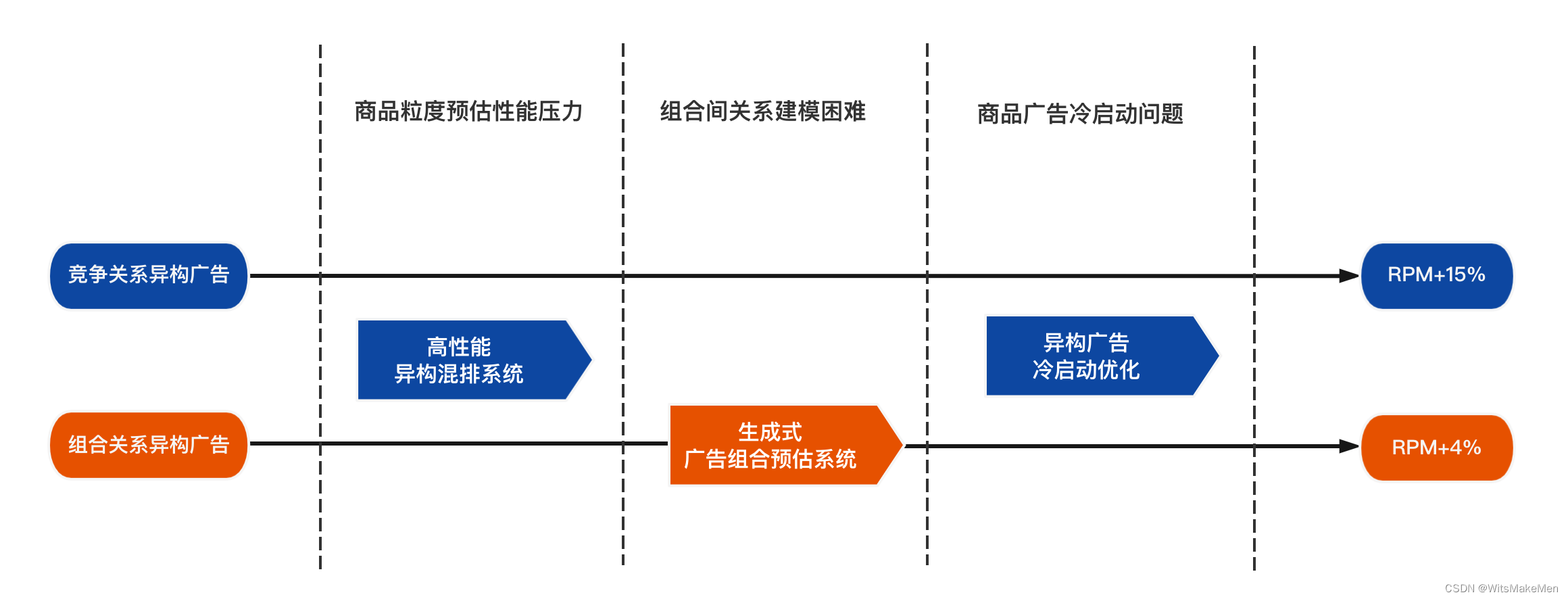
目前,搜索广告模型线上为基于DNN(深度神经网络)[4-6]的门店粒度排序模型,门店候选数量受限(约150)且缺失商品等更直接且重要的决策信息。因此,我们将商品广告作为门店的候选补充,通过门店与门店下多商品的混排打开候选空间,候选量可以达到1500+。此外,考虑广告上下文影响,同时进一步扩展打分候选以提升排序上限,我们将门店粒度升级为异构广告组合粒度的排序,基于此构建生成式广告组合预估系统,候选极限达到了1500X(考虑线上性能我们最终选择1500X)。而在探索过程中,我们遇到了以下三大挑战:
-
商品粒度预估性能压力:下沉到商品粒度后增加至少10倍的候选量,造成线上预估服务无法承受的耗时增加。
-
组合间关系建模困难:门店同组合商品的上下文关系使用Pointwise-Loss建模难以刻画。
-
商品广告冷启动问题:仅使用经过模型选择后曝光的候选,容易形成马太效应。
针对上述挑战,技术团队经过思考与实践,分别进行如下针对性的优化: -
高性能异构混排系统:通过bias网络对门店信息迁移学习,从而实现高性能商品粒度预估。
-
生成式广告组合预估系统:将商品预估流程升级为列表组合预估,并提出上下文联合模型,建模商品上下文信息。
-
异构广告冷启动优化:基于汤姆森采样算法进行E&E(Exploit&Explore, 探索与利用)优化,深度探索用户的兴趣。
目前,高性能异构混排和生成式广告组合预估已经在多个广告场景落地,视场景业务不同,在衡量广告营收的千次广告展示收益(RPM,Revenue Per Mille)指标上提升了4%~15%。异构广告冷启动优化在各业务生效,在精度不下降的前提下给予流量10%随机性。下文将会对我们的具体做法进行详细的介绍。
2 技术探索与实践
2.1 高性能异构混排系统
打分粒度从门店下沉为商品后,排序候选量从150增加到1500+,带来排序潜力提升的同时,如果使用门店模型直接进行商品预估,则会给线上带来无法承担的耗时增加。通过分析,我们发现门店下所有商品共享门店基础特征,占用了80%以上的网络计算,但对于多个商品只需要计算一次,而商品独有的、需要独立计算的商品特征只占用20%的网络计算。所以基于这个特性,我们参照组合预估[7]的做法,来实现异构混排网络。主网络的高复杂性门店表征通过共有表达的迁移学习,实现对门店网络输出层的复用,从而避免在进行商品预估时对门店网络的重复计算。
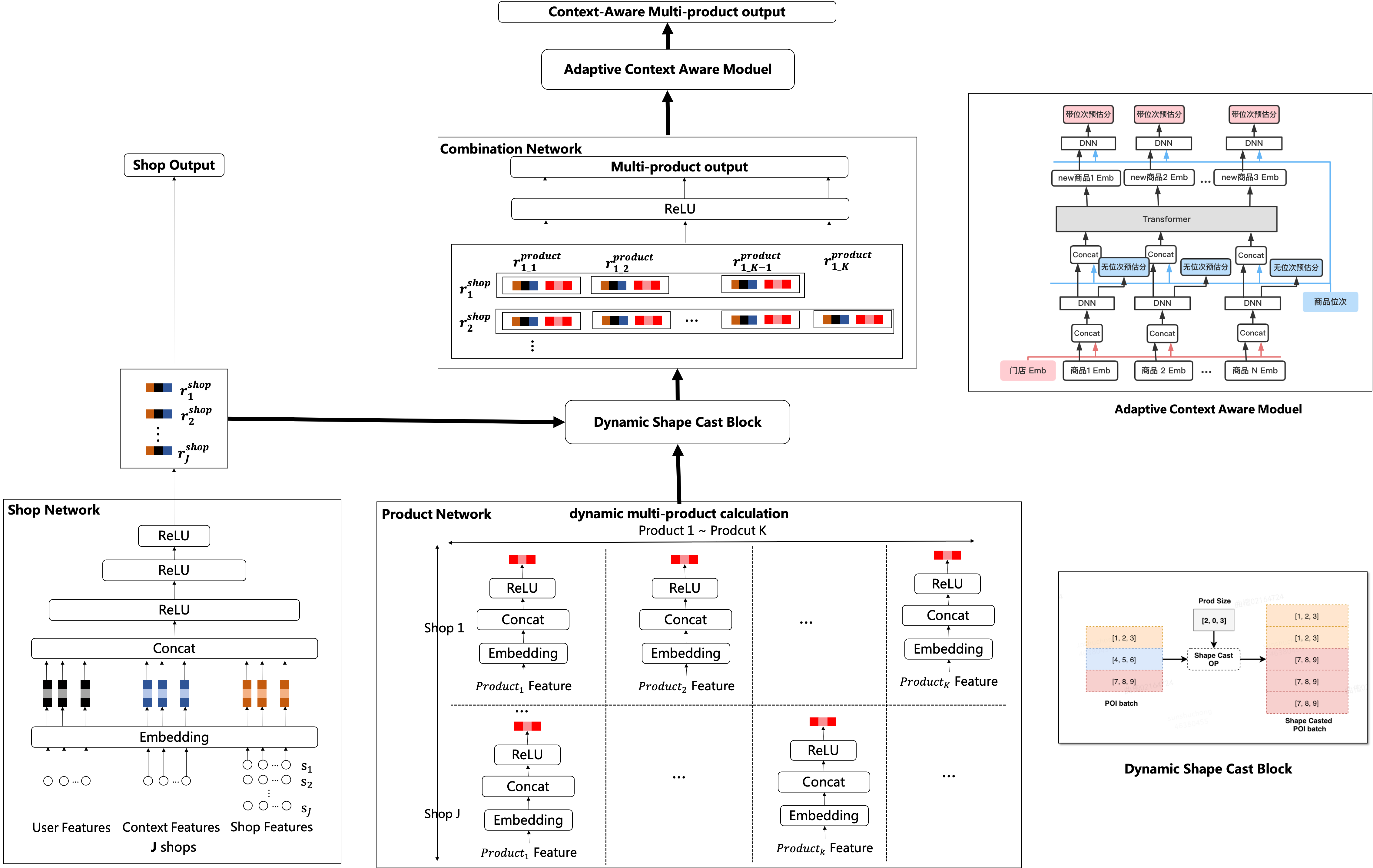
如下图4所示,整个网络分为门店网络和商品网络。在离线训练阶段,门店网络(主网络)以门店特征作为输入,得到门店的输出层,计算门店Loss,更新门店网络;商品网络(bias网络)以商品特征为输入,得到商品输出层,与门店网络的输出层门店向量作CONCAT操作,然后计算最终的商品Loss,并同时更新门店网络和商品网络。
为了实现线上预估时对门店网络输出层的复用,我们将商品以List的方式喂入模型,实现请求一次打分服务,获得1(门店)+n(商品)个预估值。另外,对于门店的商品数不固定这一问题,我们通过维度动态转换的方式保证维度对齐。实现保持网络规模情况下扩大了10倍打分量,同时请求耗时仅增加了1%。
通过异构混排网络,我们在性能约束下得到了门店和各个商品的预估值,但是由于广告出口仍然以门店作为单元进行计费排序,所以我们需要根据不同业务场景特点进行预估值应用。为了描述方便,下文中用“P门店”代表门店的预估值,“P商品_i”代表第i个商品的预估值。
筛选频道页的竞争关系异构广告
- 筛选频道页内有门店和商品两种展示类型进行竞争,获胜的广告类型将最终得到展示。训练阶段,每一次曝光为一条样本,一条样本为商品和门店其中一种类型。门店样本只更新门店网络,商品样本同时更新门店网络和商品网络。
- 预估阶段,门店和商品发生点击概率互斥,我们使用Max算子:通过Max(P门店 ,P商品_1 ,…,P商品_n ),如果门店获胜,则展示门店信息,门店的预估值用于下游计费排序;如果任一商品获胜,则展示该商品信息,该商品的预估值用于下游。
首页搜索的组合关系异构广告
- 首页搜索的排序列表页中每个展示单元由门店和两个商品组成,机制模块对这一个展示单元进行计费排序。训练阶段,每一次曝光为多条样本:一条门店样本和多条商品样本。门店样本只更新门店网络,商品样本同时更新门店网络和商品网络。
- 预估阶段,由于用户点击【更多优惠】前,默认展示Top2商品,所以可以选择商品预估值最高的Top2作为展示商品,其余商品按预估值排序。我们需要预估pCTR(门店|商品1|商品2) 。从数学角度分析,我们在预估门店或商品1或商品2被点击的概率,因此我们使用概率加法法则算子:pCTR(门店|商品1|商品2) = 1 - (1-P门店 ) * (1-P商品_1 ) * (1-P商品_2)。所以在得到门店和商品预估值之后,首先要对商品按预估值进行排序,得到商品商品的展示顺序,并选择Top2的商品预估值和门店预估值进行概率加法法则计算,得到展示单元的预估值用于门店排序计费。
虽然系统整体架构相似,但是因使用场景不同,样本生成方式也不同,模型最终输出的P商品有着不同的物理含义。在竞争关系广告中,P商品作为和门店并列的另一种展示类型;组合关系广告中,P商品则为门店广告展示信息的补充,因此也有着不同预估值的应用方式。最终高性能异构混排系统在多个广告场景落地,视场景业务不同,RPM提升范围在2%~15%之间。
2.2 生成式广告组合预估系统
在商品列表中,商品的点击率除了受到其本身质量的影响外,还会受到其上下展示商品的影响。例如,当商品的上下文质量更高时,用户更倾向于点击商品的上下文,而当商品上下文质量较低时,用户则倾向于点击该商品,这种决策差异会累积到训练数据中,从而形成上下文偏置。而消除训练数据中存在的上下文偏置,有利于更好地定位用户意图以及维护广告系统的生态,因此我们参照列表排序的思路[8-9],构建生成式商品排序系统,建模商品上下文信息。
获取上下文信号可以通过预估商品列表的全排列,但是全排列的打分量极大(商品候选数10的全排列打分数为10!=21,772,800)。为了在耗时允许的情况下获取上下文信号,我们采用二次预估的方式对全排列结果进行剪枝。首次预估时采用Base模型打分,仅取Top N商品进行排列,二次预估时再利用上下文模型对排列的所有结果进行打分。将全排列的打分量从10!减少到N!(在线上,我们选择的N为3)。
但是二次预估会给服务带来无法承受的RPC耗时,为了在性能的约束下上线,我们在TensorFlow内部实现了二次预估模块。如下图5所示,我们最终实现了基于剪枝的高性能组合预估系统,整体耗时和基线持平。
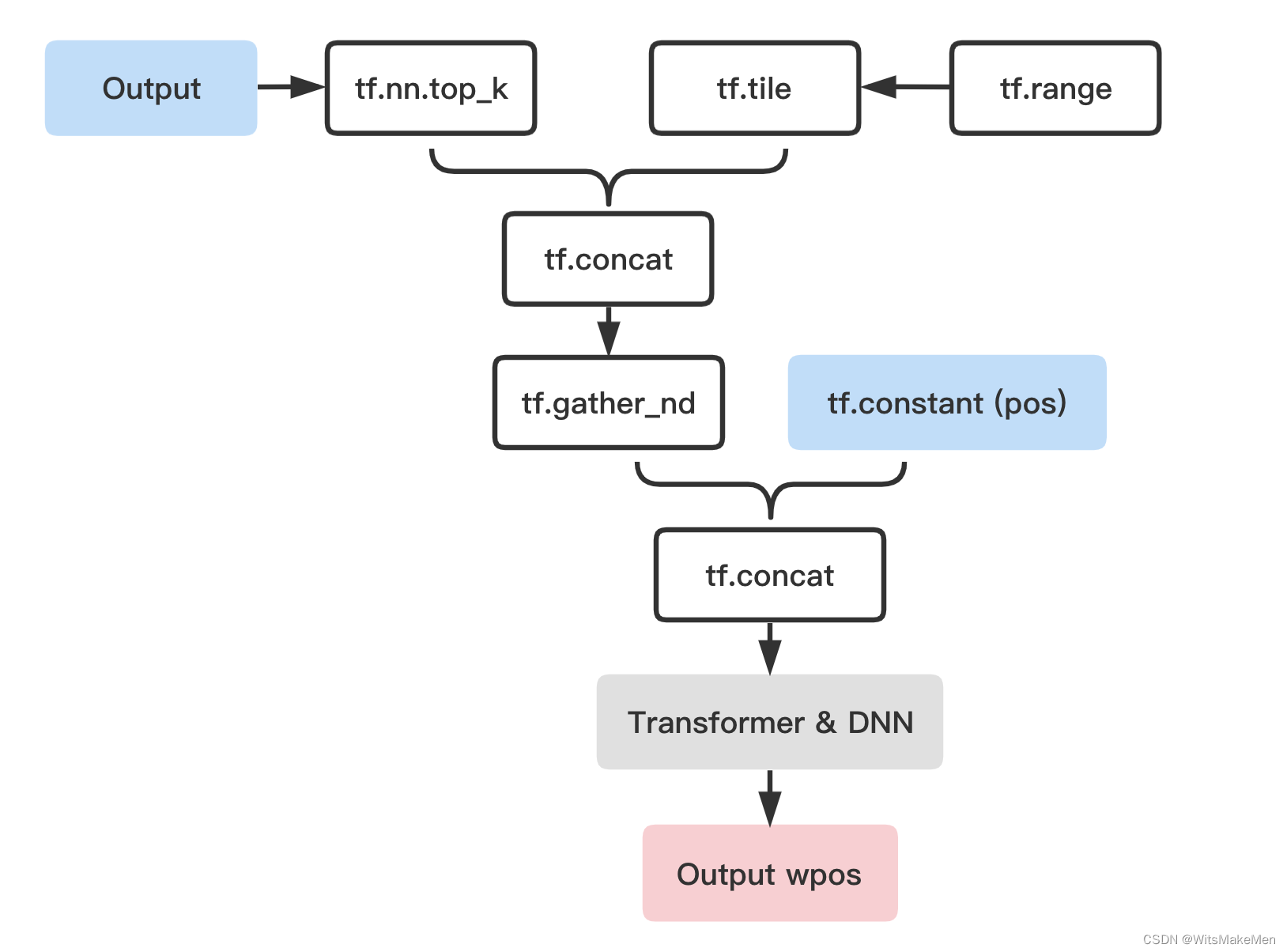
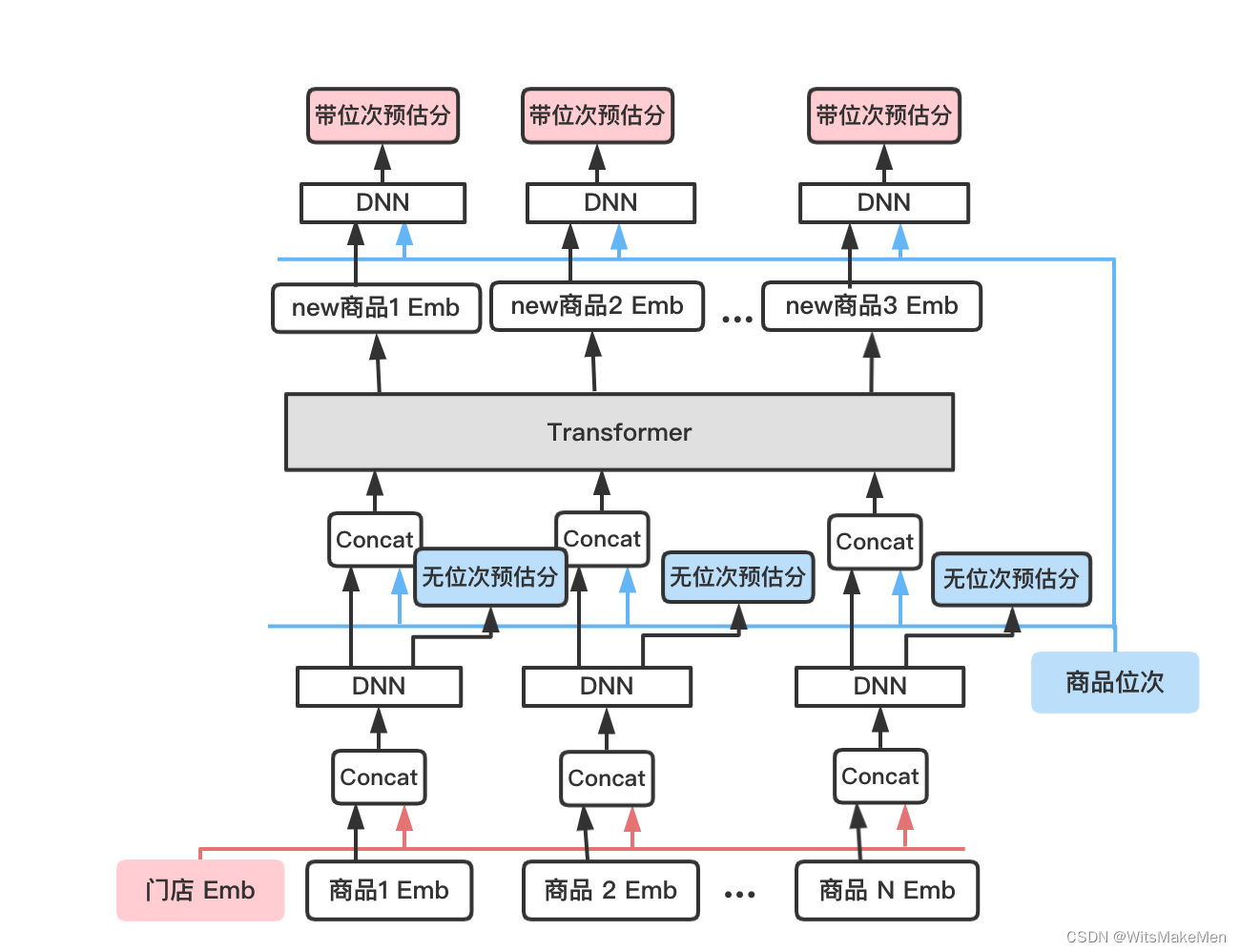
通过剪枝和TF算子,任一商品输入可以感知其上下文信号。为了建模上下文信息,我们提出基于Transformer的上下文自适应感知模型。模型结构如图6所示:
- 我们首先将门店特征及商品特征分别过Embedding层得到门店Emb及商品Emb,再通过全链接层得到无位次商品向量和无位次的预估值;
- 将无位次商品向量与商品位次信号进行拼接,通过Transformer建模商品的上下文信息,得到包含上下文信息的商品Emb;
- 将包含上下文信息的商品Emb与位次信号再次拼接,通过DNN非线性交叉,得到包含上下文信息及位次信息的最终输出商品预估值。通过强化商品间的交叉,达到建模商品上下文的目的,最终生成式广告组合预估在首页搜索取得了RPM+2%的效果提升。
2.3 异构广告冷启动优化
为了避免马太效应,我们也会主动试探用户新的兴趣点,主动推荐新的商品来发掘有潜力的优质商品。我们在模型上线前,通过随机展示的方式来挖掘用户感兴趣的商品。但是给用户展示的机会是有限的,展示用户历史喜欢的商品,以及探索用户新兴趣都会占用宝贵的展示机会,此外,完全的随机展示从CTR/PRS等效果上看会有较为明显的下降,所以我们考虑通过更合理的方式来解决“探索与利用”问题。
相对于传统随机展示的E&E算法,我们采用基于汤普森采样的Exploration算法[10],这样可以合理地控制精度损失,避免因部分流量进行Exploration分桶的bias问题。汤普森采样是一种经典启发式E&E算法,核心思路可以概况为,给历史曝光数(HI,Historical Impressions)较多的商品较低的随机性,历史曝光较少的商品给予较高的随机性。具体的做法是我们使商品的预估值(pCTR)服从一个beta(a,b)分布,其中:
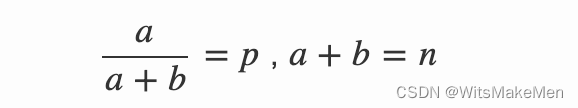
其中p是以pCTR为自变量的函数,n是以EI为自变量的函数。根据经验,我们最终使用的函数为:
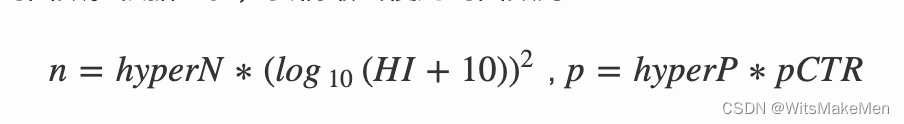
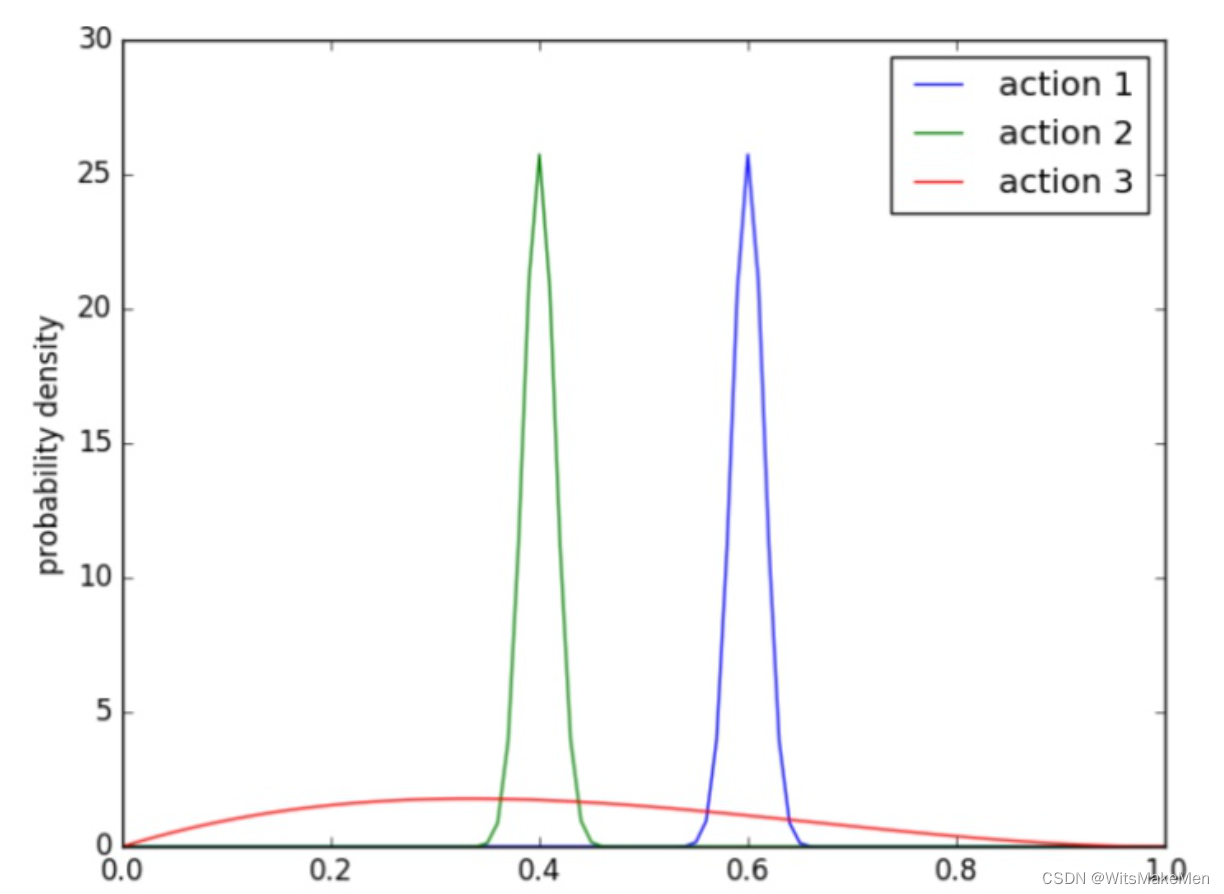
我们通过调节hyperP和hyperN两个参数来控制最终呈现结果的随机性。如下图7所示,action1相比action2分布的均值更高,action3相比另外两个分布的随机性更强。较高的随机性可能会带来准确性的下降,我们通过参数离线模拟,确定全量版本的超参数。最终上线的模型在精度和效果没有下降的前提下,展示的商品有10%的随机性。
2.4 业务实践
异构混排和广告组合预估有效地解决了LBS限制下门店候选较少的问题。对于前文介绍的两类典型异构广告:竞争关系异构广告和组合关系异构广告,我们根据其展示样式和业务特点,将相应的技术探索均进行了落地,并取得了一定的效果。如下图8所示:
3 总结
本文介绍了美团到店搜索广告业务中异构广告混排的探索与实践,我们通过高性能的异构混排网络来应对性能挑战,并根据业务特点对异构预估进行了应用。为了建模广告的上下文信息,我们将商品预估流程由单点预估升级为组合预估模式,并提出上下文组合预估模型,建模商品位次及上下文信息,然后,通过基于汤普森算法的E&E策略对商品冷启动问题进行了优化,在多个场景均取得了一定的成果。近期,已经有越来越多业务场景开始了展示样式的升级,例如美食类目由门店调整为菜品广告,酒店类目由门店调整为房型展示,本文提到的方案与技术也在逐步的推广落地过程中。
值得一提的是,相比于美团以门店作为广告主体,业界的广告主体以商品和内容为主,本文提到的共有表达迁移和生成式组合预估的技巧,可以应用在商品和创意的组合问题上,更进一步拓展候选规模。
广告异构混排项目也是从业务视角出发,勇于打破原来迭代框架下的一次重要尝试。我们希望该项目能够通过技术手段来解决业务问题,然后再通过业务理解反推技术的进步。此外,我们也将在广告候选问题上进行更多的探索,寻找新的突破点,从而进一步设计更完善的网络结构,不断释放排序系统的潜力空间。
4 参考资料
[1] Huang, Jianqiang, et al. “Deep Position-wise Interaction Network for CTR Prediction.” Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021.
[2] Qi, Yi, et al. “Trilateral Spatiotemporal Attention Network for User Behavior Modeling in Location-based Search.” Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021.
[3] 胡可,坚强等. 广告深度预估技术在美团到店场景下的突破与畅想
[4] Cheng, Heng-Tze, et al. “Wide & deep learning for recommender systems.” Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
[5] Zhou, Guorui, et al. “Deep interest network for click-through rate prediction.” Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018.
[6] Ma, Jiaqi, et al. “Modeling task relationships in multi-task learning with multi-gate mixture-of-experts.” Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
[7] Gong, Yu, et al. “Exact-k recommendation via maximal clique optimization.” Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019.
[8] Guo, Huifeng, et al. “PAL: a position-bias aware learning framework for CTR prediction in live recommender systems.” Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[9] Feng, Yufei, et al. “Revisit Recommender System in the Permutation Prospective.” arXiv preprint arXiv:2102.12057 (2021).
[10] Ikonomovska, Elena, Sina Jafarpour, and Ali Dasdan. “Real-time bid prediction using thompson sampling-based expert selection.” Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2015.