目录
前言
1、基础
2、操作步骤
2.1、启动主节点
2.2、启动从节点
2.2.1、启动自己电脑的从节点
2.2.2、启动同事电脑的从节点
2.3、开始并发
3、无web界面,定时运行,数据存储在csv中、等待4个节点连接后自动开始
4、有web界面,定时运行,数据存储在csv及html中、等待4个节点连接后自动开始
🎁更多干货
前言
一句话总结:在自己电脑上分布式执行、在同事电脑上分布式执行、在docker中分布式执行
1、基础
- 当运行 Locust 分布式时,master 和 worker 机器都必须有 locustfile 的副本
- 运行 Locust 的单个进程可以模拟相当高的吞吐量。对于一个简单的测试计划,它应该能够每秒发出数百个请求,如果使用FastHttpUser则可以发出数千个请求。要运行更多负载,则需要扩展到多个进程(你自己电脑上开多核),如果还不满足,需要去同事电脑上开多核处理。所以,用该--master标志以主模式启动 Locust 的一个实例。并使用该标志启动多个工作器实例--worker。如果 worker 与 master 不在同一台机器上,您可以--master-host将它们指向运行 master 的机器的 IP,如果在同一台机器则不需要。
- 主机运行 Locust 的 Web 界面,并告诉worker机何时产生/停止用户。worker机运行用户并将统计信息发送主机。主机本身不运行任何用户。每个工作人员可以运行的用户数量几乎没有限制。Locust/gevent 每个进程可以运行数千甚至数万个用户,只是它们的总请求率/RPS 不是太高,所以,为了每秒的请求数更高,应该开启多核。如果 Locust 即将耗尽 CPU 资源,它将记录警告。
- Python 不能充分利用每个进程的多个内核,通常应该在工作机器上为每个处理器内核运行一个工作实例,以利用它们的所有计算能力。如果你的电脑是12核,并发时候创建12个窗口,充分利用电脑的处理能力。
2、操作步骤
2.1、启动主节点
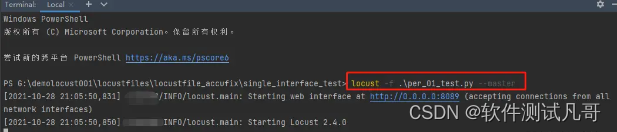
locust -f per_01_test.py --master ,预期:
2.2、启动从节点
2.2.1、启动自己电脑的从节点
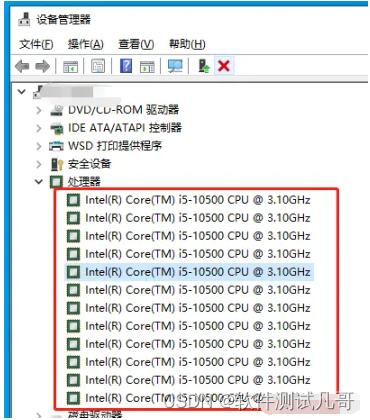
1、明确自己电脑是几核处理器,我是12核
2、进入脚本所在目录空白处执行: shift + 右键 > 在此处打开 PowerShell 窗口,我打开了12个窗口,充分利用了电脑每秒处理事务的能力。 3、在每个窗口执行:locust -f .\per_01_test.py --worker,两个预期:
2.2.2、启动同事电脑的从节点
- 同事电脑拉取代码,配置执行环境
- 进入脚本所在目录空白处执行: shift + 右键 > 在此处打开 PowerShell 窗口,打开12个窗口,
- 在打开的窗口依次执行:locust -f .\per_01_test.py --worker --master-host=192.168.0.14
2.3、开始并发
主节点界面打开网址,输入需要的并发数,只要从节点不主动断开,我们就可以一直多核处理并发数目。

3、无web界面,定时运行,数据存储在csv中、等待4个节点连接后自动开始
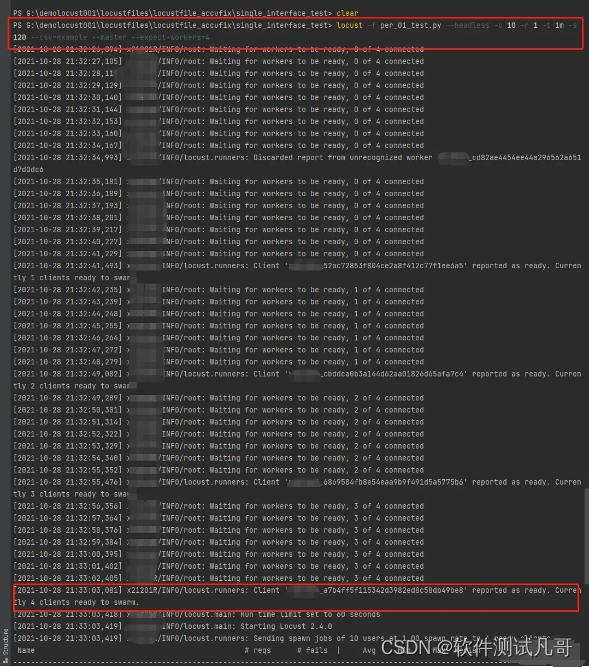
执行:locust -f per_01_test.py --headless -u 10 -r 1 -t 1m -s 120 --csv=example --master --expect-workers=4
- --master :将此机器设置为主节点
- --expect-workers=4 启动主节点时使用 --headless。在开始测试之前,主节点将等待4个工作节点连接后才开始执行脚本,如图:
4、有web界面,定时运行,数据存储在csv及html中、等待4个节点连接后自动开始
locust -f per_01_test.py --autostart -u 1 -r 1 -t 1m -s 120 --csv=example --autoquit 10 --html locust_report.html --master --expect-workers=4

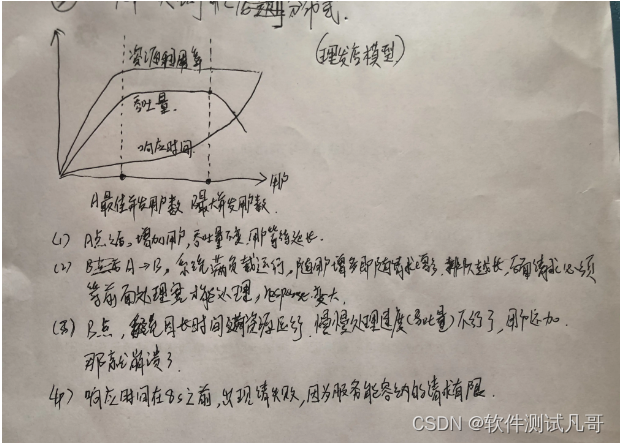
---------------------------------以下:理发店模型的一点总结---------------------------------
🎁更多干货
完整版文档下载方式:
这些资料,对于从事【软件测试】等相关工作的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享。
在评论区和我互动交流或者私❤我【软件测试学习】领取即可,拿走不谢。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “👍点赞” “✍️评论” “💙收藏” 一键三连哦!