1.作者
Rushmian Annoy Wadud、Wei Sun
2.时间
2022
3.整体架构
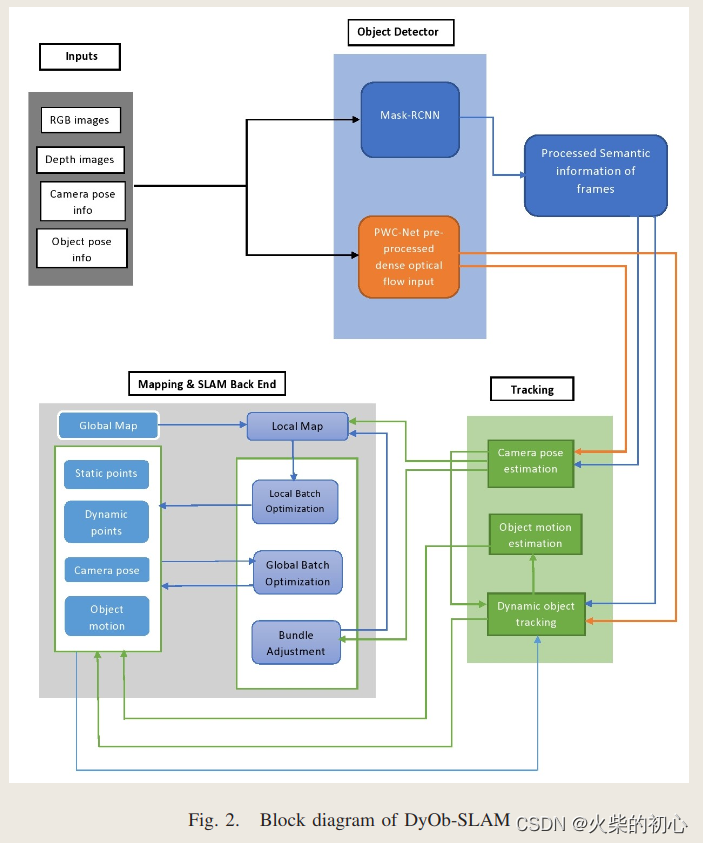
DyOb-SLAM是DynaSLAM和VDO-SLAM的结合:
- 基于
先验信息使用Mask RCNN分割出动态目标 - 通过基于
光流和场景流的算法对运动目标进行跟踪 - 对静态点进行BA优化
输出:
- 当前帧显示ORB特征以及Masj信息和对象标签
- 基于静态特征的稀疏地图
- 包含动态目标及其随时间更新的运动的全局地图
4.中心思想
1.目标检测
- Mask-RCNN被用来分割出当前帧的潜在运动目标
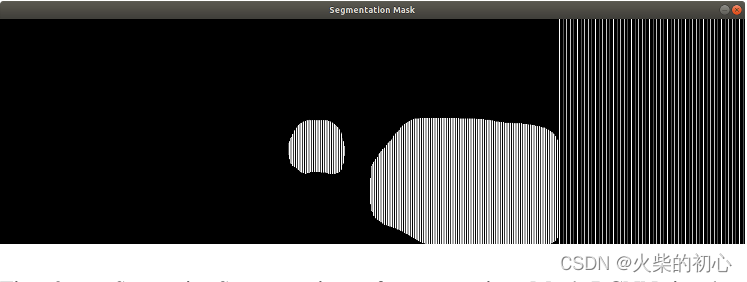
- 稠密光流:使用
PWC-Net,有助于最大化跟踪点的数量,然后用于跟踪多个对象
2.跟踪
跟踪的输入是RGB图像、每帧的深度信息、分割Mask和光流信息,其分为 3 个模块:
-
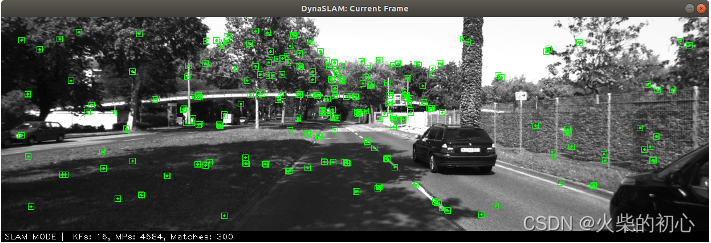
ORB特征提取:采用ORB_SLAM2中提出的
-
相机位姿估计:使用
静态的点最小化重投影误差进行相机位姿估计
e ( X k ) = C k − π ( X k − 1 P k − 1 ) e\left(X_{k}\right)=C_{k}-\pi\left(X_{k}^{-1} P_{k-1}\right) e(Xk)=Ck−π(Xk−1Pk−1)
- 目标运动跟踪:使用场景流更新动态目标的分割信息,对于场景流的话,静态目标的场景流理论上为0,因此可以用一个阈值来判断目标是运动的还是静止的
- 目标位姿估计:
P
k
=
k
−
1
O
k
P
k
−
1
P_{k} =^{k-1}O_{k}P_{k-1}
Pk=k−1OkPk−1
- 目标的运动: k − 1 O k ^{k-1}O_{k} k−1Ok
- P k P_{k} Pk:第K帧静止的点
- P k − 1 P_{k-1} Pk−1:第K-1帧静止的点
- 在全局参考帧中的目标点和图像帧中的静止点的重投影误差: e ( k − 1 O k ) = C k − π ( X k − 1 [ k − 1 O k ] P k − 1 ) e\left({ }^{k-1} O_{k}\right)=C_{k}-\pi\left(X_{k}{ }^{-1}\left[{ }^{k-1} O_{k}\right] P_{k-1}\right) e(k−1Ok)=Ck−π(Xk−1[k−1Ok]Pk−1)
- 速度的差: E = v g − v e E =v_{g}-v_{e} E=vg−ve
3.建图
- 稀疏地图:由静止背景上的特征点三角化生成的稀疏点云
- 全局地图:相机的位姿信息与目标的运动

4.后端
- BA:关键帧和稀疏的地图点(局部+全局)
- 局部的batch优化:对于局部地图,最小化重投影误差优化相机的位姿
- 全局的batch优化:对于全局地图,最小化位姿误差优化相机和运动目标的位姿
5.云计算
将耗费计算资源的模块放到云端,比如语义分割
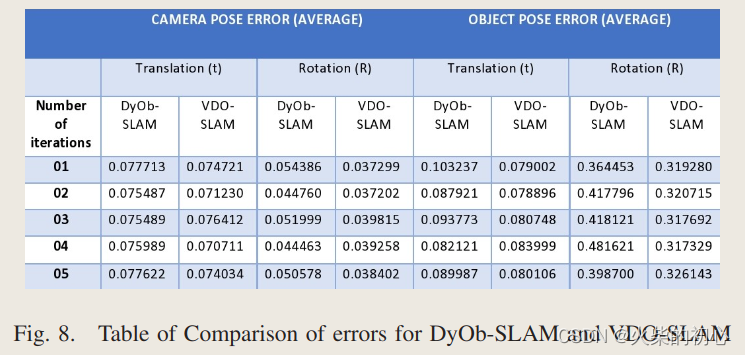
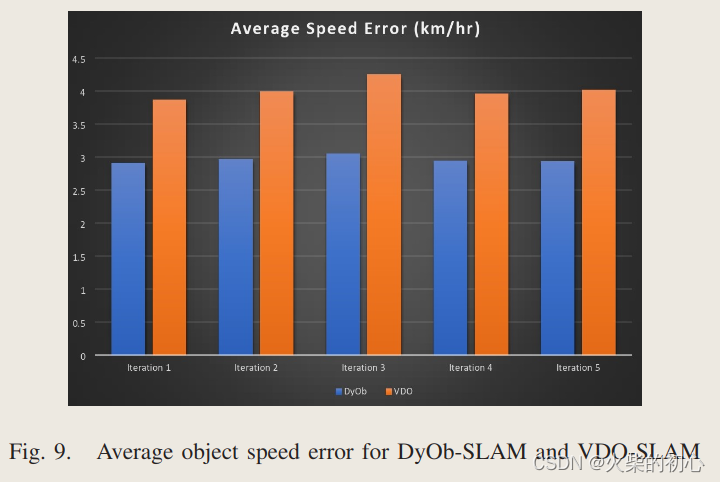
5.结果