Alex-Net 由加拿大多伦多大学的 Alex Krizhevsky、Ilya Sutskever(G. E. Hinton 的两位博士生)和 Geoffrey E. Hinton 提出,网络名“Alex-Net”即 取自第一作者名。
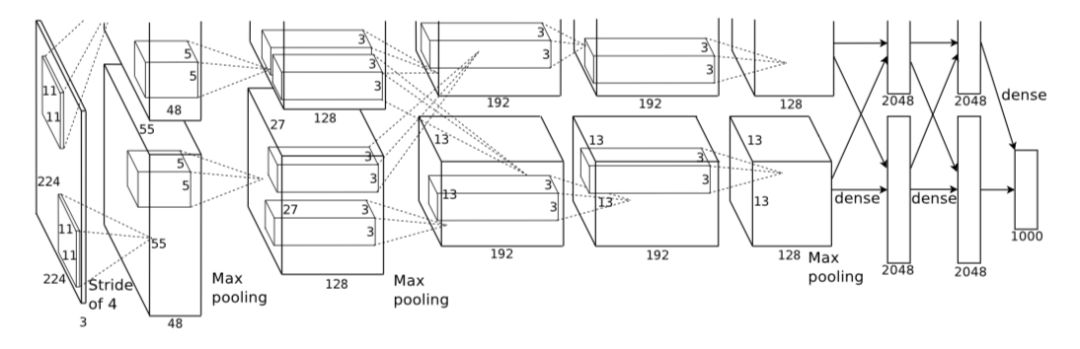
下图所示是 Alex-Net 的网络结构,共含五层卷积层和三层全连接层。其中,Alex-Net 的上下两支是为方便同时使用两片 GPU 并行训练,不过在第三层卷积和全连接层处上、下两支信息可交互。
由于两支网络完全一致, 在此仅对其中一支进行分析。下表列出了 Alex-Net 网络的架构及具体参数。
单在网络结构或基本操作模块方面,Alex-Net 的改进非常微小,构建网络的基本思路变化不大,仅在网络深度、复杂度上有较大优势。
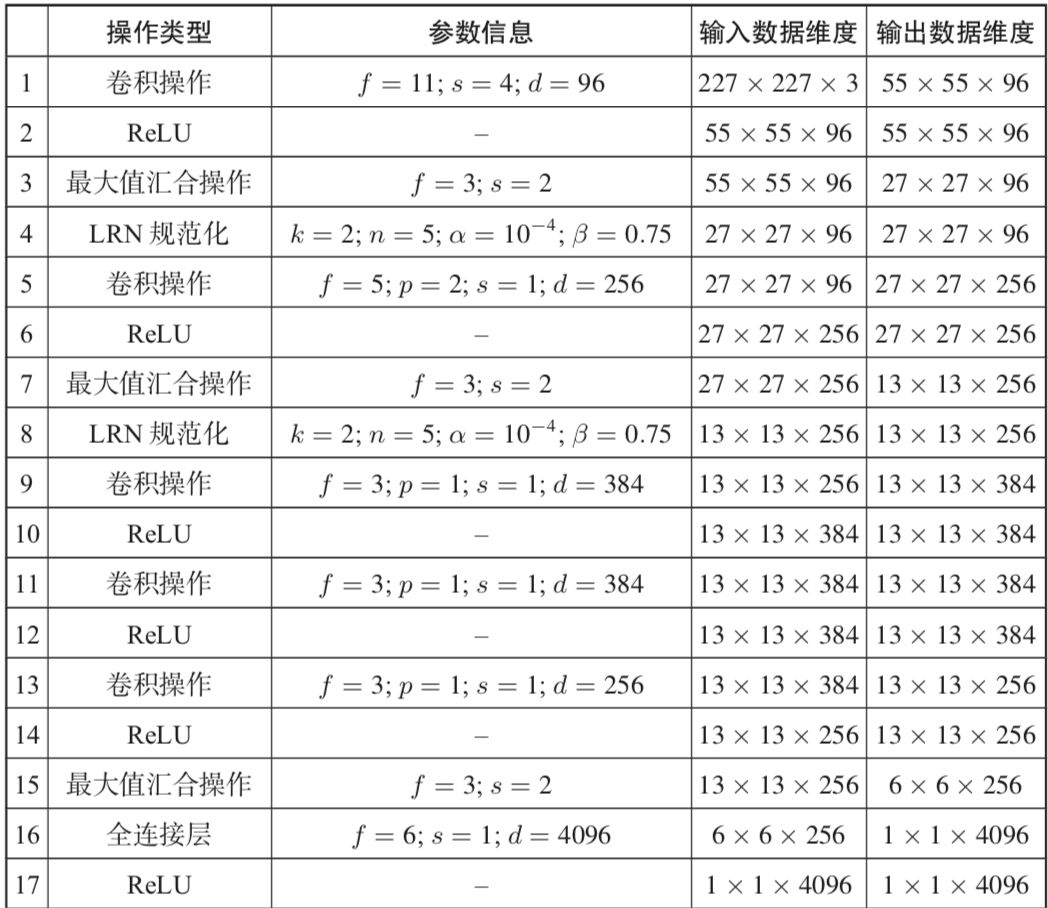
Alex-Net 网络架构及参数:
VGG,又叫VGG-16,顾名思义就是有16层,包括13个卷积层和3个全连接层,是由Visual Geometry Group组的Simonyan和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,该模型主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。其年参加了ImageNet图像分类与定位挑战赛,取得了在分类任务上排名第二,在定位任务上排名第一的优异成绩。
结构:根据卷积核大小与卷积层数目不同,VGG可以分为6种子模型,分别是A、A-LRN、B、C、D、E,我们常看到的基本是D、E这两种模型,让我们看下面官方给出的6种结构图:
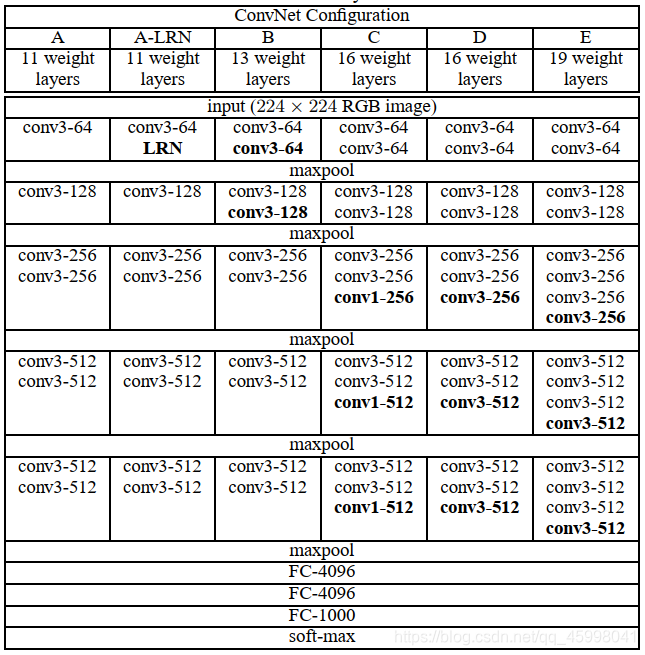
以配置D为例,在卷积层1(conv3-64),卷积层2(conv3-128),卷积层3(conv3-256),卷积层4(conv3-512)分别有64个,128个,256个,512个3X3卷积核,在每两层之间有池化层为移动步长为2的2X2池化矩阵(maxpool)。在卷积层5(conv3-512)后有全连接层,再之后是soft-max预测层。
这张图可能会更好地理解
数据与训练
1、输入处理
如果要使用224x224的图作为训练的输入,用S表示图片最小边的值,当S=224时这个图就直接使用,直接将多余的部分减掉;对于S远大于224的,模型将对图像进行单尺度和多尺度的剪裁,通过剪切这个图片中包含object的子图作为训练数据。
2、训练方式
采用带动量的小批量梯度下降法,来优化目标函数,并且当学习效果较为满意时,最初加入的学习率权重衰减系数会起作用,会减小学习率,缓慢达到最优解。
3、初始化
若为浅层,则先随机初始化后训练,深层采用浅层训练后的数据作为初始化数据,中间层则随机初始化。
特色
1、卷积层均采用相同的卷积核参数,这样就能够使得每一个卷积层(张量)与前一层(张量)保持相同的宽和高;
2、池化层均采用相同的池化核参数,池化层采用尺寸为2X2,stride=2,max的池化方式,使得池化后的层尺寸长宽为未池化前的1/2;
3、利用小尺寸卷积核等效大尺寸卷积核,2个3X3卷积核的感受野与1个5X5卷积核相当,3个3X3卷积核与1个7X7卷积核相当,故在特征提取效果相当时,多个小卷核与大卷积核相比,学习参数更少计算量较小,训练更加快速,还能增加网络的深度,提升模型性能。
下面用计算说明为什么2个3X3卷积核能代替1个5X5卷积核: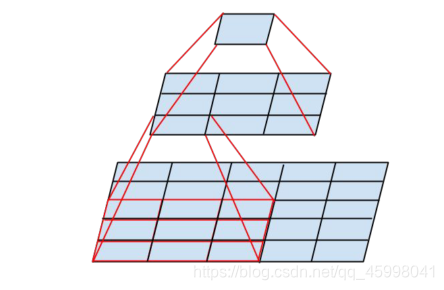
假设feature map是28×28的,假设卷记的步长step=1,padding=0:
使用一层5X5卷积核
由(28−5)/1+1=24可得,输出的feature map为24X24
使用两层3X3卷积核
第一层,由(28−3)/1+1=26可得,输出的feature map为26X26
第二层,由(26−3)/1+1=24可得,输出的feature map为24X24
故最终尺寸结果相等,用3X3卷积核代替7X7卷积核同理。