文章目录
- 前言
- 泛读
- 储备知识
- 提示学习
- 提示工程Promt Engineering
- 答案工程
- 背景介绍
- 研究SELF-INSTRUCT的动机
- 研究意义&贡献
- 精读
- Overview
- 种子任务
- 步骤1:定义指令数据
- 步骤2:自动指令数据生成
- 步骤2.1指令生成
- 步骤2.2指令分类
- 步骤2.3实例生成
- 步骤2.4筛选和后处理
- 实验分析和讨论
- 多样性分析
- 生成质量
- 应用结果
- ALpaca
- LoRA
- LoRA的优点
- 实操
- 注意事项
- 训练(微调)
- 预测
- 核心代码
前言
首发公众号:学姐带你学AI
本课程来自深度之眼《大模型——前沿论文带读训练营》公开课,部分截图来自课程视频。
文章标题:SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions
自指导:将语言模型与自生成的指令相结合
作者:Yizhong Wang等
单位:华盛顿大学
发表时间:ACL 2023
泛读
储备知识
提示学习
第一篇大模型LLaMA里面就有提到过这个概念,这里再详细讲解一下。这个技术是用在大模型上的,因为大模型参数比较多,因此调整参数非常困难,经研究发现调整输入亦可以达到提高模型表现的目的,因此提示学习孕育而生。
白话:大模型相当于:
y
=
f
(
x
)
y=f(x)
y=f(x)中的
f
f
f函数包含非常复杂,难以调整以使得
y
y
y得到更好的表现,但修改输入
x
x
x同样能影响
y
y
y,且修改
x
x
x非常简单,无需修改模型的参数。
因此,为了更好的发掘预训练语言模型的潜力,利用其不同的能力,研究趋势如下:
| 预训练模型 | 提示学习 | |
|---|---|---|
| 预训练+微调 | → \rightarrow → | 预训练+提示+预测 |
具体来说,提示学习是研究者们为了下游任务设计出来的一种输入形式或模板(或者说一种表现形式),它的目的是能够帮助预训练模型“回忆”起自己在预训练时“学习”到的东西,它是一种激活预训练模型知识的技术手段。例如:
输入为:我喜欢这部电影。
输出模板为:我喜欢这部电影,总的来说,它是一部_______的电影。
那么模型可能会在下划线处填上:很棒、不错、值得一看…
目前prompt的一般方法:pre-train, prompt, and predict,新的范式
上面的例子就是预训练任务属于Masked Language Model,可让预训练语言模型 (下面简称为PLM) 用表示情感的答案填空。
对于其他任务,prompt的方法也可以通过设计不同的模板,通过选取合适的prompt,控制模型预测输出。适用于下游各种任务。不需要修改PLMs的结构,能够充分利用PLMs所学习到的知识。大量研究表明,prompt的微小差别,可能会造成效果的巨大差异。这也就引发可后续如何自动构造prompt一系列工作,因此就有了提示工程(autoGPT就是类似工具)。
提示工程Promt Engineering
Prompt 工程是创建 prompting 函数 f p r o m p t ( x ) f_{prompt}(x) fprompt(x),根据需要填充的文字[Z]的位置,可以分成两种Prompt 工程:
| 前缀Prompt | 完形填空Prompt | |
|---|---|---|
| 应用场景 | 延续字符串前缀 | 填充文本中空白的字符串 |
| 对应任务 | 主要针对关生成的任务或使用标准自回归 LM 解决的任务 | 使用掩码 (Mask) LM 解决的任务(如:BERT) |
| 原因 | 生成方式与模型从左到右的性质刚好吻合 | 生成方式与预训练任务的形式非常匹配 |
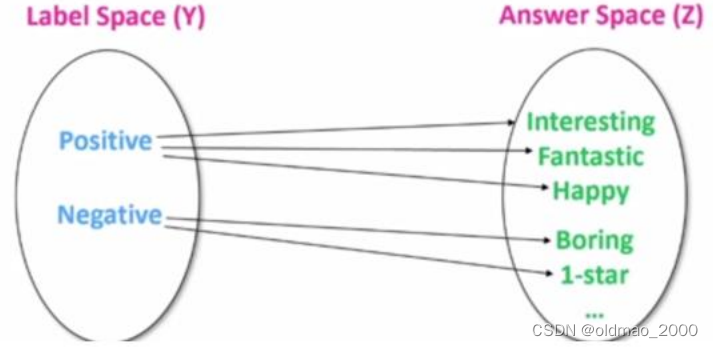
答案工程
答案工程的目的是搜索一个 answer 空间 Z 和一个到原始输出 Y 的映射,从而得到一个有效的预测模型。
背景介绍
研究SELF-INSTRUCT的动机
以上介绍的prompt称之为:指令。
各种研究表明:对大模型进行指令微调,可使的模型对于新任务具有0-shot的卓越能力(摘要第一句)。但指令微调很大程度上依赖于人类(专家)编写的指令数据,这些些数据在数量、多样性和创造性方面都是有限的,阻碍了调整后的模型的通用性。(摘要第二句)
因此,有研究开始尝试建立能够遵循自然语言指令的模型。工作主要有两个:大预训练语言模型和人类编写的Instruction。(Introduction第二句)
这里原文提到两篇文献,涉及到两个数据集,它们使用了大量的人工注释来收集指令:
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
SUPER-NATURAL INSTRUCTIONS: Generalization via Declarative Instructions on 1600+ NLP Tasks
使用人工注释使得成本很高,而且很倾向于主流的NLP任务,没有涵盖真正的各种任务和描述它们的不同方式。鉴于这些限制,就需要继续提高指令调整模型的质量,来实现更好的LLMS。(Introduction最后一部分)
这篇文章的Alpaca指令微调模型,展现出了较强指令遵循能力,有类似于chatGPT的能力展现。其指令微调数据集都是通过本篇文章提出的SELF-INSTRUCT方法,并通过Open AI的API进行提取的。
问题:为什么要使用Open AI的API?
答:指令微调实际上是调整模型的输入
X
X
X,要想提高模型效果必须要获得输入对应的输出
Y
Y
Y才能进行对应调整,获取输出就必须调用Open AI的API。
研究意义&贡献
它提出了一种框架:Self-Instruct,可以利用语言模型自己的生成能力,来提高其遵循指令的能力,而不需要大量的人工标注数据。这种方法可以降低指令微调的成本和难度,同时提高模型的泛化性和创造性。(摘要第三句)
贡献:(Introduction最后一段)
它提出了一种自动生成指令、输入和输出样本的流程,然后对它们进行筛选和后处理,再用它们来微调原始的语言模型。
它在vanilla GPT3上应用了该方法,并在Super-NaturalInstructions数据集上取得了与InstructGPT_001(人工标注结果)相当的性能,后者是使用私有的用户数据和人工标注来训练的。
它提供了一种几乎无需标注的方法,来使预训练的语言模型与指令对齐,并且发布了它生成的大规模合成数据集,以促进未来对指令微调的研究。
发布了一个包含52k条指令的大型合成数据集和一组手工编写的新任务,用于建立和评估未来的指令模型
精读
Overview
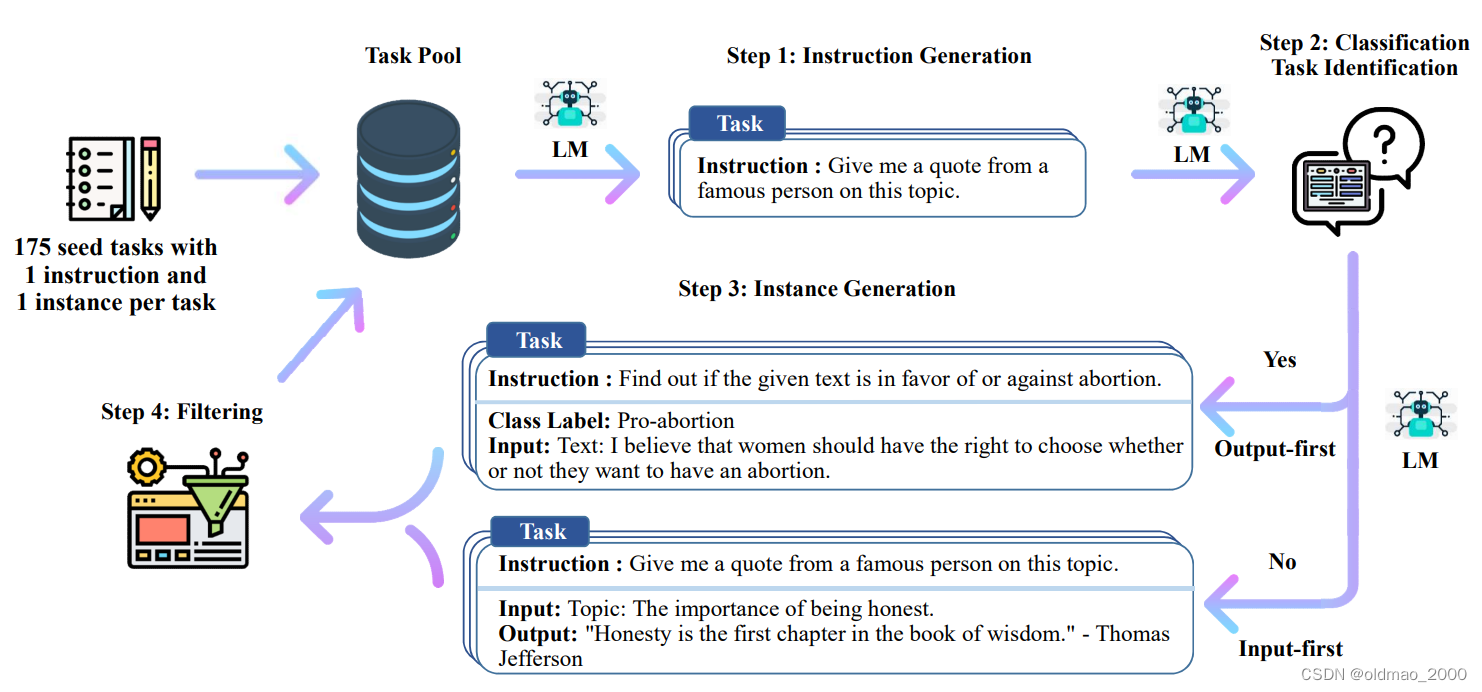
原文:A high-level overview of SELF-INSTRUCT. The process starts with a small seed set of tasks (one instruction and one input-output instance for each task) as the task pool. Random tasks are sampled from the task pool, and used to prompt an off-the-shelf LM to generate both new instructions and corresponding instances, followed by filtering low-quality or similar generations, and then added back to the initial repository of tasks. The resulting data can be used for the instruction tuning of the language model itself later to follow instructions better. Tasks shown in the figure are generated by GPT3. See Table 10 for more creative examples.
简单解释:整个过程是半自动(需要初始化种子任务)的迭代引导算法,该算法利用模型本身的指令信号对预训练的LM进行指令调整。
seed task:种子任务
task pool:任务池
instruction generation:指令生成
Classification task identification:是否分类任务
种子任务
原始的、最早定义的一批数据(175个),实际上就是有固定字段格式的文本:
id,name,instruction,instances(包括可为空的input,output),is_classification
样式如下:
{"id":"seed_task_0", "name": "breakfast_suggestion","instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?","instances":[{"input": "", "output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal,60 grams whey protein powder,1/2 medium banana,1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."}],"is_classification":false}
步骤1:定义指令数据
从上面的例子可以看到,每条指令都用自然语言定义了一个任务task。每个任务都有一个或多个输入输出实例instance(X,Y)
模型的期望输出可以表示为:
Y
=
M
(
t
a
s
k
,
X
)
Y=M(task,X)
Y=M(task,X)
很多情况下,指令和实例输入并没有严格的边界。举个例子:
“写一篇关于人工智能的文章 ”可以是一个指令,希望模型能够直接响应,输出一篇文章。而它也可以被表述为 “写一篇关于XXXX的文章 ”作为任务指令,而 "人工智能"作为实例输入填入XXXX。
注意:X可以为空。
可以将输入看做指令的补充说明,以达到更具体的效果。
步骤2:自动指令数据生成
在这个步骤,模型被提示生成新的任务指令。这一步是利用现有的指令集来创造更广泛的指令任务,通常是新的任务。
生成指令数据的流程由四个步骤组成。
1)指令生成,
2)识别指令是否代表分类任务,
3)根据是否分类任务选择用输入优先或输出优先的方法生成实例,
4)过滤低质量数据。
步骤2.1指令生成
已有研究发现:大型预训练的语言模型在遇到上下文中的一些现有指令时,可以被提示生成新的指令。这个发现提供了一种从一小部分人类编写的指令种子中扩充指令数据的方法,也是本文SELF-INSTRUCT的思想。
利用人工编写的175个任务(1个指令+1个实例)作为任务池,用引导的方式产生多样化的指令集。具体方法是:先从种子池中随机抽取6个人工编写的指令,再随机抽取2个之前步骤中模型生成的指令,总共8个指令(就是让大模型进行few shots的生成)。输入给模型,让模型输出一个新的指令。
这里第一次迭代的时候没有生成指令,则直接选取8条人工指令,这里选用人工指令是保证模型的正确性;
这里加入生成指令目的是为了增强模型的泛化性和随机性
这里对应overview中的:

步骤2.2指令分类
使用GPT3 few-shot去识别生成的指令是否是分类任务。
处理分类和非分类任务,需要两种不同的方法。所以接下来要识别生成的指令是否代表分类任务。 文中使用种子任务中的12条分类指令和19条非分类指令,提示预训模型进行区分,提示模板如下图所示:

步骤2.3实例生成
针对分类和非分类任务,使用两种不同的Prompt构造方法:
■输入优先:主要针对生成类任务,优先生成实例中的X,在产生相应的Y。
■输出优先:主要针对分类任务,给定指令,先生成输出Y,再生成输入。避免先生成输入,再生成输出时结果单一。通俗的说就是正样本较多的情况下,避免模型把所有输入都标记(瞎蒙)为正样本(结果单一)。
步骤2.4筛选和后处理
筛选的标准:
新生成的指令只有与种子池中的指令的 ROUGE-L 小于0.7时才会添加进入种子池;
排除一些无法被语言模型处理的指令,比如涉及图像、图片、图形的指令;
在给指令生成实例时,过滤掉那些完全相同的实例。
附录C中给出了生成得比较好的指令示例:

也给出了一些生成失败的实例:
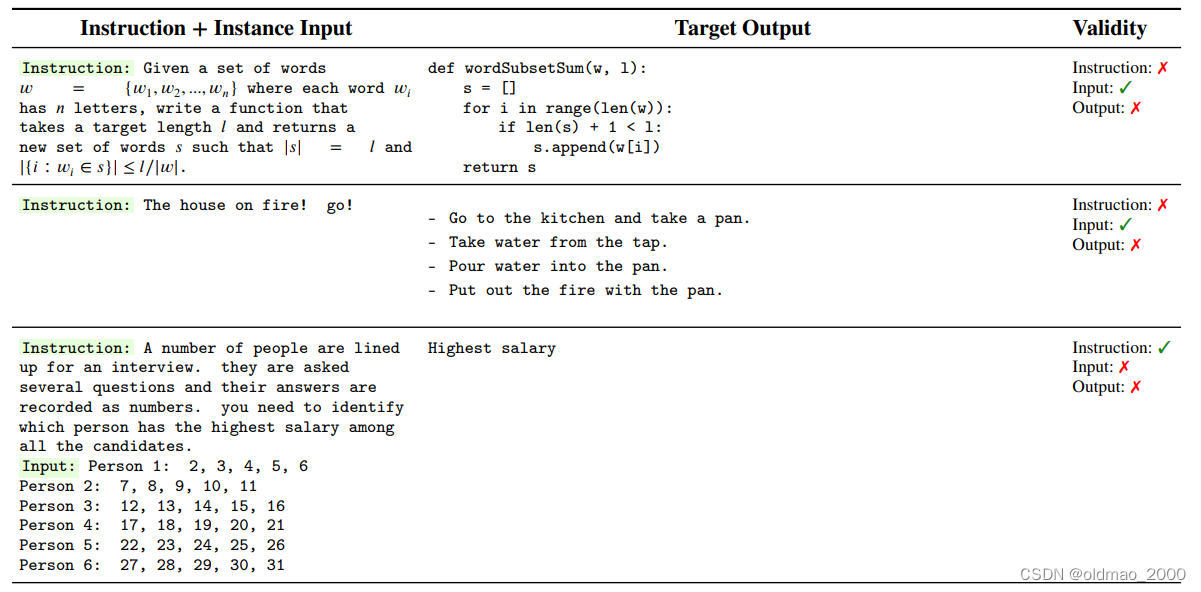

将合格的指令加入指令池,并反复迭代。
实验分析和讨论
生成的指针统计数据如下表所示:

由于一个指令可以对应多个实例,所以指令数量52K,对应实例数量为82K,比例约为1:1.5。
多样性分析
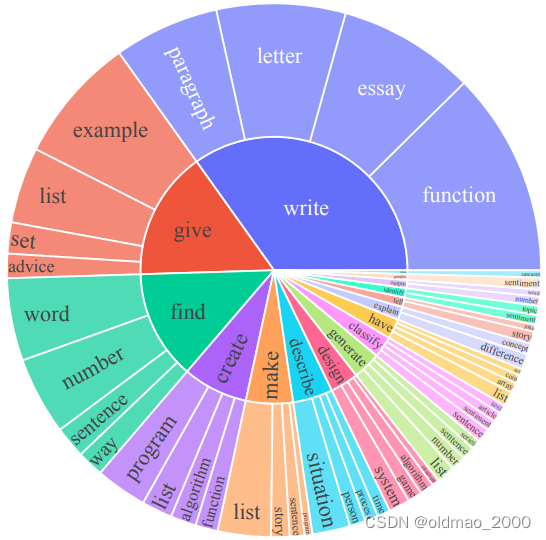
这个漂亮的图就是多层环形饼图,相当于两个系列,分两层显示。
图中内圈是动词,外圈是动词对应的名词。图中绘制了前20个最常见的根动词和它们的前4个直接名词对象,这占了整个集合的14%。例如,write后面常接letter、essay、paragraph以及function。
计算生成指令与种子指令的ROUGE-L重叠度(这个指标用来评价摘要的共现度的):

生成质量
文章随机抽取了200条指令,并在每个结构中随机选择一个实例。请一位专家标注(文章的共同作者)从指令、实例输入和实例输出的角度来标注每个实例是否正确,结果如表2所示:
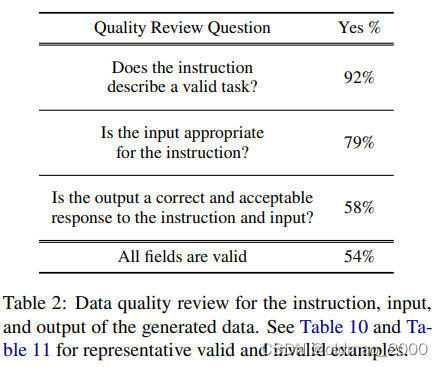
结论:大多数生成的指令是有意义的,而生成的实例可能包含更多的噪音(在合理的范围内)
应用结果
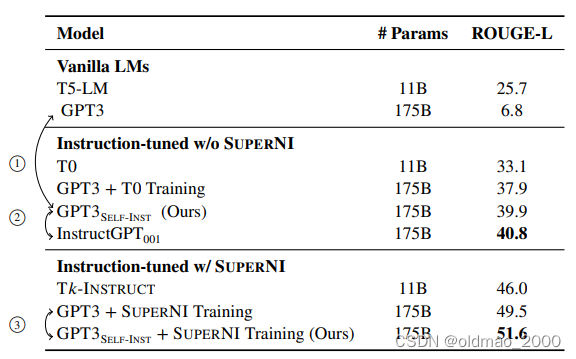
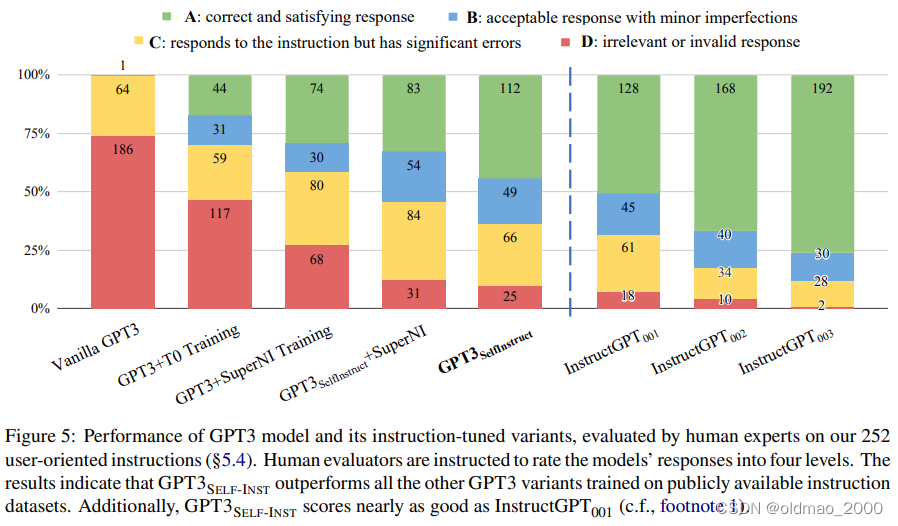
①箭头表示 SELF-INSTRUCT加持后GPT3性能暴涨33.1%
②箭头表示SELF-INSTRUCT加持后基本与InstructGPT001持平
③箭头表示它与标记指令集结合能进一步提升性能3
ALpaca
使用方法见:https://github.com/pengwei-iie/alpaca-lora
LoRA
LoRA(Low-Rank Adaptation of Large Language Models)中文含义是大语言模型的低阶适应,是一种PEFT(Parameter-Efficient Fine-Tuning)参数高效微调技术,是微软提出用来解决大语言模型参数微调的技术。其基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅finetune的成本显著下降,还能获得和全模型微调类似的效果。
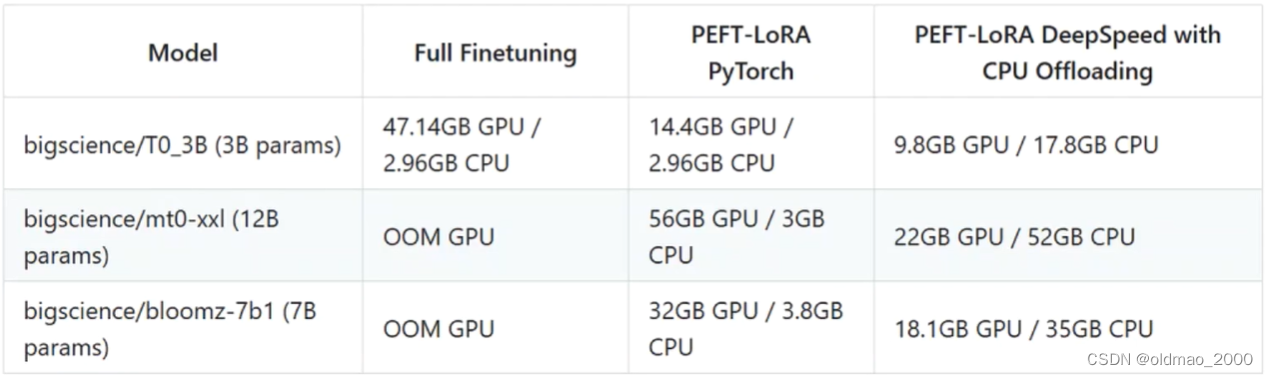
原来的输出可表示为:
h
′
=
W
0
x
h' = W_0x
h′=W0x
为了微调模型,给他加上额外的网络层,训练时
W
0
W_0
W0不变只训练
Δ
W
\Delta W
ΔW,则变成:
h
=
W
0
x
+
Δ
W
x
h= W_0x+\Delta Wx
h=W0x+ΔWx
Δ
W
\Delta W
ΔW可以进一步用矩阵分解的方式来表示:
h
=
W
0
x
+
Δ
W
x
=
W
0
x
+
B
A
x
B
∈
R
d
×
r
,
A
∈
R
r
×
k
,
rank
r
<
<
min
(
d
,
k
)
h=W_0x+\Delta Wx=W_0x+BAx\\ B\in \R^{d\times r},A\in \R^{r\times k},\text{rank }r<<\min (d,k)
h=W0x+ΔWx=W0x+BAxB∈Rd×r,A∈Rr×k,rank r<<min(d,k)
分解后参数量变少(从
d
×
k
d\times k
d×k个变成
d
×
r
+
r
×
k
d\times r+r\times k
d×r+r×k个),具体实作上可以看为:
原来的模型是(忽略图中参数的维度和上面不一样):

现在给他加上额外的网络层,则变成:
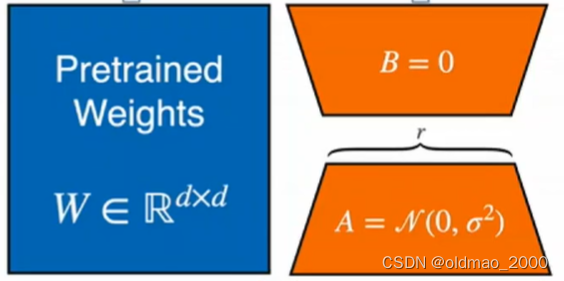
将输入
x
x
x复制一份,分别丢进两边,左边参数不变,右边参数调整:
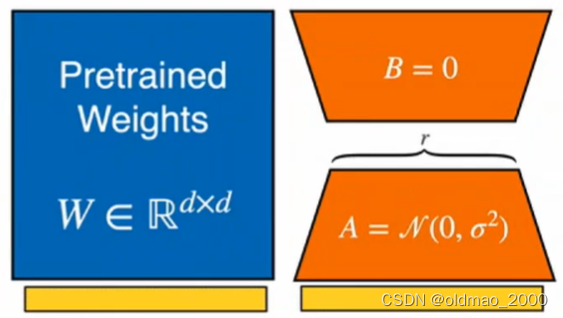
将得到结果相加:
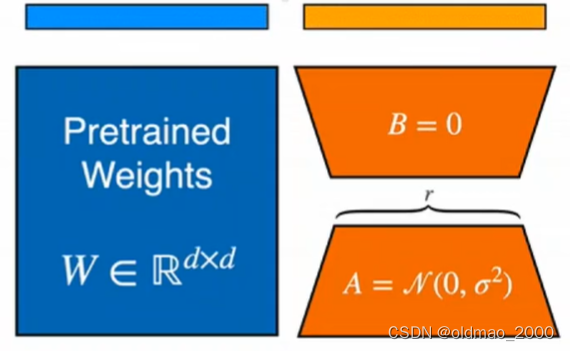
原理:预训练语言模型具有较低的“本征维度“,尽管随机投影到一个较小的子空间,仍然可以有效地学习。
LoRA的优点
1.从LoRA的原理可以看到,LoRA可以使得大模型更方便的共享了,我们把大模型看做多用螺丝刀的底座,然后把多个A和B矩阵看做不同的批头,只要我们训练好多个A和B矩阵,就可以使用一个底座完成不同任务,从而大大减少存储需求和任务切换开学。

2.LoRA使训练更加有效(即使是与prefix的方法相比也是一样),在在使用自适应优化器时,硬件门槛降低了3倍,因为我们不需要计算梯度或维护参数优化器的状态。相反,我们只优化注入的、小得多的低秩矩。
3.LoRA与许多先前的方法是不相关的,并且可以与许多方法相结合,例如前缀微调。
实操
注意事项
1.安装环境
pip install -r requirements.txt
需要注意的是peft安装对网速要求比较高,比较容易安装失败,如提示克隆超时,可将zip格式的peft项目下载到本地后再安装。此时需要修改requirement.txt的内容,将peft修改为本地路径即可,就是下面代码中加井号那里。
accelerate
appdirs
loralib
bitsandbytes
black
black[jupyter]
datasets
fire
git+https://github.com/huggingface/peft.git # /hy-tmp/peft
transformers>=4.28.0
sentencepiece
gradio
2.跑到200 steps就出现OOM (out of memory)错误,解决方法:
upgrading transformers to the dev version pip install git+https://github.com/huggingface/transformers seems to have resolved it. bitsandbytes==0.37.2 also work
训练(微调)
启动服务器,打开终端,新建一个目录
git clone https://github.com/pengwei-iie/alpaca-lora.git
把llama7b模型down下来进行(下载地址在这里,大约26G)。
下载llama的代码如下:
git lfs install
git clone https://huggingface.co/decapoda-research/llama-7b-hf
然后用SELF-INSTRUCT微调
在finetune.py文件中有几行代码是设置训练的几个路径参数的,第一个设置基础大模型,这里选用huggingface集成了的llama(对应上面精读LoRA原理中蓝色部分,也就是多功能螺丝刀的底座,所以最好是下载到本地,便于匹配不同的批头),然后设置SELF-INSTRUCT的指令集,最后设置输出的目录。
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca'
这里需要自己手工修改为本地存放对应文件的路径。
当然,还有两个size:
# training hyperparams
batch_size: int = 128,
micro_batch_size: int = 4,
第一个batch_size是保存梯度累积的大小(这里实际值为:128÷4=32),第二个才是在GPU中训练的batch_size大小,这个直接会影响GPU内存的占用,如果显存不够就把它改成2(对应16G显存)。
然后可以运行run.py开始训练,并显示运行参数及过程
bash run.sh
tail train_fine.out -f
这里需要对run.sh进行编辑,路径、size含义和上面一样,这里nohup可以使得系统后台不挂断地运行这个命令,毕竟炼丹时间需要12h以上。
nohup python finetune.py \
--base_model './path_to_llama-7b-hf' \
--data_path './alpaca_data_cleaned_archive.json' \
--batch_size '32' \
--micro_batch_size '2' \
--output_dir './lora-alpaca' > train_fine.out 2>&1 &
预测
一种是等炼丹完毕进行预测,也可以将别人微调好的lora下载(不大10多M)下来进行预测,这里主要讲后者。
编辑一个down.py文件
from huggingface_hub import snapshot_download
snapshot_download(repo_id="tloen/alpaca-lora-7b",cache_dir="./lora")
具体的repo_id可以看老师网站的说明,后面的cache_dir表示将模型参数下载到哪个路径。

运行down.py就会得到alpaca-lora这个文件夹。
然后编辑generate.py文件,这里面也有几个参数需要注意:
python generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'tloen/alpaca-lora-7b'
base_model 是指定大模型底座,lora_weights 是指定批头,这里要把下载下来的snapshots的jason文件指定进来。
运行generate.py后会得到一个url,放到浏览器打开就可以进行预测了:
核心代码
主要看finetune.py
这里导入huggingface的peft,它集成了许多参数微调的方法,里面当然包含LoRA
from peft import (
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
prepare_model_for_int8_training,
set_peft_model_state_dict,
)
train函数中定义了许多参数,
lora_r: int = 8这个表示精讲中提到的矩阵分解后的秩
实例化了prompt,原来是jason格式,这里转化为文本格式:
prompter = Prompter(prompt_template)
generate_and_tokenize_prompt函数对指令进行处理
model = get_peft_model(model, config)表示将大模型和微调部分网络层合并