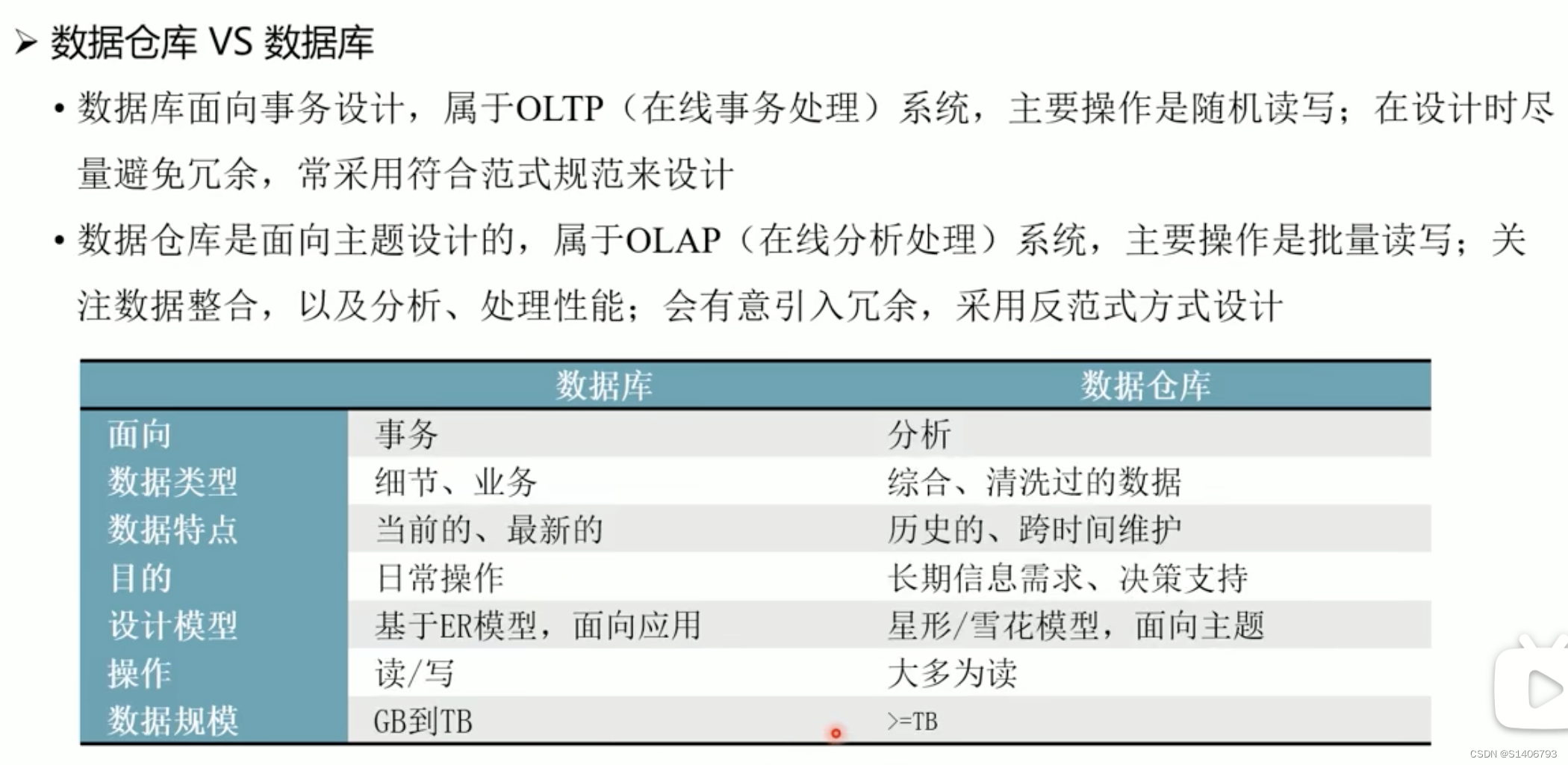
一、数据仓库概述
1. 数据仓库诞生原因
(1)历史数据积存(存放在线上业务数据库中,当数据积压到一定程度会导致性能下降,所以需要将实用频率低的冷数据转移到数据仓库中)
(2)企业数据分析的需要(业务数据库中的数据实时更新,企业各个部门自己建立独立的数据抽取系统,导致数据不一致;数仓面向数据分析,业务数据库面向业务系统)
2. 数据仓库概述
(1)数据仓库是一个面向主题的、集成的、非易失的且随时间变化的数据集合。
(2)主要用于组织积累的历史数据,并使用分析方法(OLAP、数据分析)进行分析整理,进而
辅助決策,为管理者、企业系统提供数据支持,构建商业智能
面向主题:为数据分析提供服务,根据主题将原始数据集合在一起
集成:原始数据来源于不同数据源,要整合成最终数据,需要经过抽取、清洗、转换的过程
非易失:保存的数据是一系列历史快照,不允许被修改,只允许通过工进行查询、分析
时变性:数仓会定期接收、集成新的数据,从而反映出数据的最新变化
3. 数据仓库建设方案
(1)传统数据仓库(扩展性有限,热点问题)
由关系型数据库组成MPP(大规模并行处理)集群;hash算法;分库分表
(2)大数据数据仓库
利用大数据天然的扩展性(分布式存储,包括分布式计算,并添加了SQL的支持),完成海量数据的存放,但是在数据量较少的时候后计算速度较慢。解决了传统数据仓库扩展性和热点问题。
4. MMP架构

架构方式有三种:share everything; share disk; share nothing
>>MMP架构缺点
(1)由于这种非共享架构,存储位置不透明,通过Hash确定数据所在的物理节点,查询任务在所有节点均会执行;
(2)并行计算时(在整个协同运算的过程中),单节点瓶颈(单个节点运行缓慢的时候)会成为整个系统短板,容错性差;随着节点总数的增加,集群规模的增大,节点故障的数量也会增加,瓶颈将会越发明显,这也是MMP数据库扩展性较差的根本原因;
(3)MMP数据库致力于实现分布式事务(为了保证数据的一致性),但是在分布式事务中,实现这种事务之后,一定会影响它的扩展性。
5. 分布式架构
(1)分布式架构大数据中常见的技术架构,也称为Hadoop架构/批处理架构;
(2)各节点实现场地自治(可以单独运行局部应用,MMP不可单独运行局部应用,只能作为整体对外提供服务),数据在集群中全局透明;
(3)每台节点通过局域网或广域网相连,节点问的通信开销较大,在运算时致力减少数据(移动计算而非移动数据);
(4)优先考虑的是P(分区容错性,数据存储到集群会被拆分成多个分片,每个分片又会保存多个副本,解决了单点故障问题),然后是A(可用性),最后再考虑C(一致性)。

数据量低的时候用MMP数据库,数据量一但达到某个量级,推荐使用分布式架构,其吞吐量大的优势就会显示出来。
6. MPP +分布式架构
(1)数据存储采用分布式架构中的公共存储,提高分区容错性
(2)上层架构采用MPP,减少运算延迟;
(3)相较于其他大数据产品来说,延迟较低,运行速度较快。在实时的流数据处理中,经常被采用;相较于传统的MMP架构数据库,扩展性有了进一步提升。
总结:MMP数据库适用于中等规模的数据,延迟较低,SQL支持率高;分布式批处理这种架构更适合处理海量数据的批处理计算,其吞吐较高,运算速度快,扩展性强。
二、架构
1. 架构图
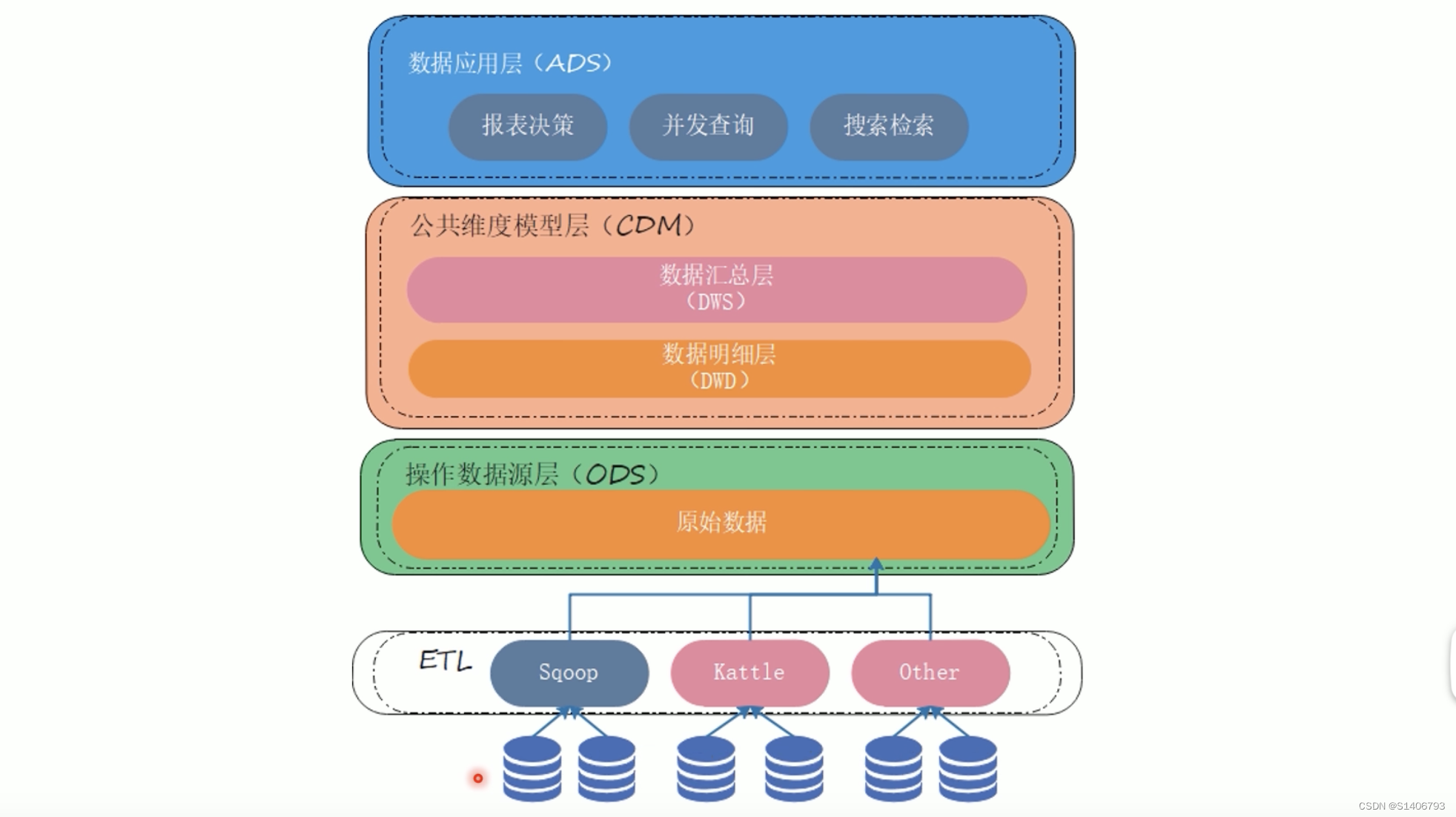
2. ETL流程(extract+transform+load)
(1)数据抽取 (Extraction)
抽取的数据源可以分为结构化数据、非结构化数据、半结构化数据。结枸化数据一般采用JDBC、数据库日志方式(推荐方式),非半结构化数据会监听文件
(2)抽取方式
数据抽取方式有全量同步、增量同步两种方式:
- 全量同步会将全部数据进行抽取,一般用于初始化数据装载
- 增量同步方式会检测数据的变动,抽取发生变动的数据,一般用于数据
(3)数据转换 (Transformation)
数据转换要经历数据清洗和转换两个阶段:
- 数据清洗:主要是对出现的重复、二义性、不完整、违反业务或逻辑规则等问题的数据进行统一的处理
- 数据转换:主要是对数据进行标准化处理,进行字段、数据类型、数据定义的转换
结构化数据在转换过程中的逻辑较为简单,非|半结构化数据的转换会较为复杂。
(4)数据加载(Loading)
将最后处理完的数据导入到对应的目标
3. 数据积存
(1)操作数据层 (ODS)
数据与原业务数据保持一致,可以增加字段用来进行数据管理(实际上属于原数据的扩充集)。存储的历史数据是只读的,提供业务系统查询使用。

4. 数据分析
(1)数据明细层(DWD)

在ODS层下有多张表,将其汇总成一个表,得到标准数据,分析运算效率变高,接下来进行分析运算。
(2)数据汇总层(DWS)
数据汇总层的数据对数据明细层的数据,按照分析主题进行计算汇总,存放便于分析的宽表模型。脱离了三范式(存储模型并非3NF),而是注重数据聚合,复杂查询、处理性能更优的数仓模型,如维度模型。
在大数据的数仓中,主要以大宽表为主;在传统数仓中会对汇总表建立一些模型,如维度模型。对DWS这一层的设计,是数据仓库的核心,因为数据仓库的面向主题,包括模型设计都是在DWS层中进行。目的是为了数据分析提供一个更优异的性能。

(3)数据应用层(ADS层)
对DWS层数据进行分析完成之后得到的结果表就存在ADS层数据中,ADS层保存的数据要提供给外部系统进行使用。
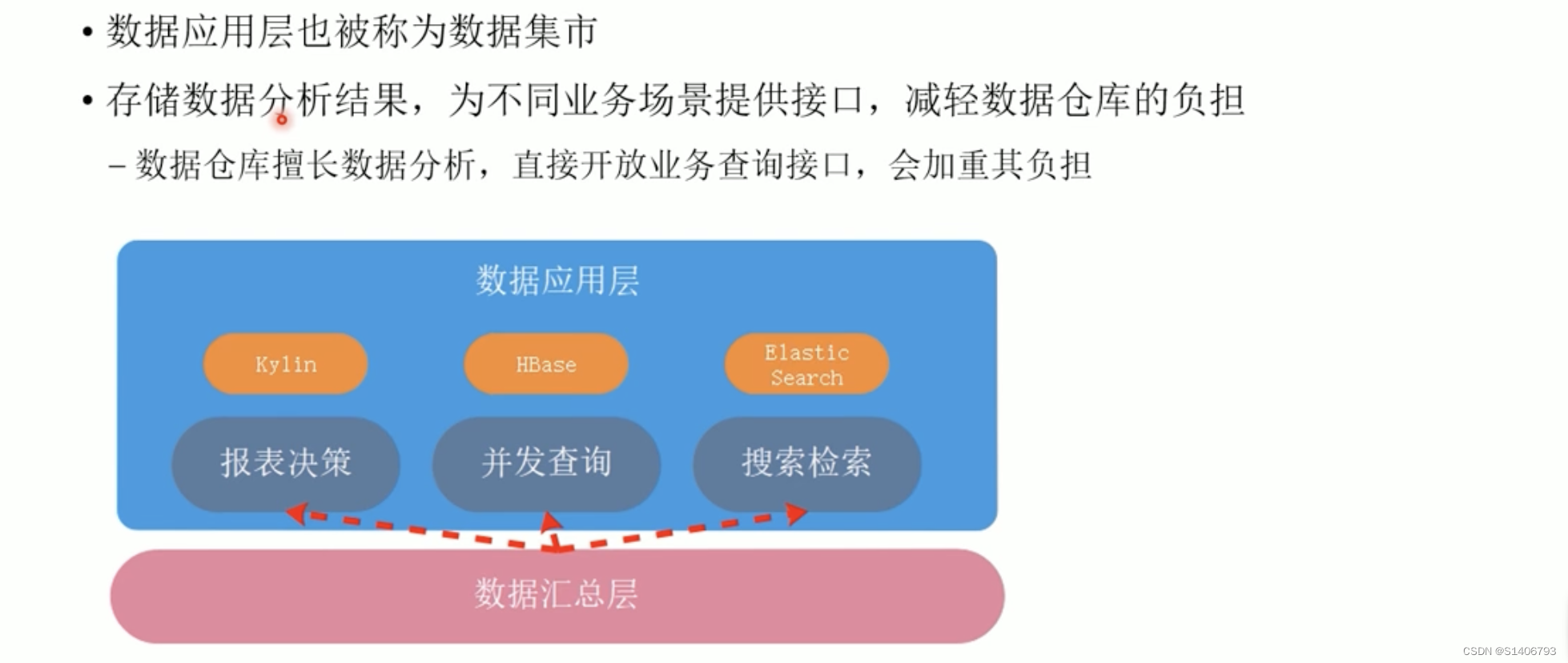
由于数据仓库更注重分析和计算,与外部系统的查询和交互效率低,如果让外部系统直接对接数据仓库的话,大量的查询落进来,全部转换成批处理任务,这种频繁的查询会给数仓带来压力。所以使用ADS层来专们存储数据结果,为外部系统提供访问接口,提供更快的查询和交互速度。
三、建模方法
1. 基本概念(OLTP和OLAP)

ROLAP依赖于模型设计;MOLAP和HOLPAP主要依赖于数仓产品的选型,更依赖于产品的底层设计。MOLAP主要存数据结果,一般不存明细数据(表数据);HOLAP底层是关系型的,所以可以存储明细数据、表的原数据,将预计算结果保存在上层,如果SQL在上层中查不到结果,也可以在底层中查询。
2. ROLAP

最常用的是维度模型,适合互联网这种业务变动比较频繁的数据。其他三种适合比较成熟的数据仓库,数据的表结构变动不大。
维度模型
(1)维度模型中,表被分为维度表、事实表,维度是对事实的一种组织;
(2)维度一般包含分类、时间、地域等
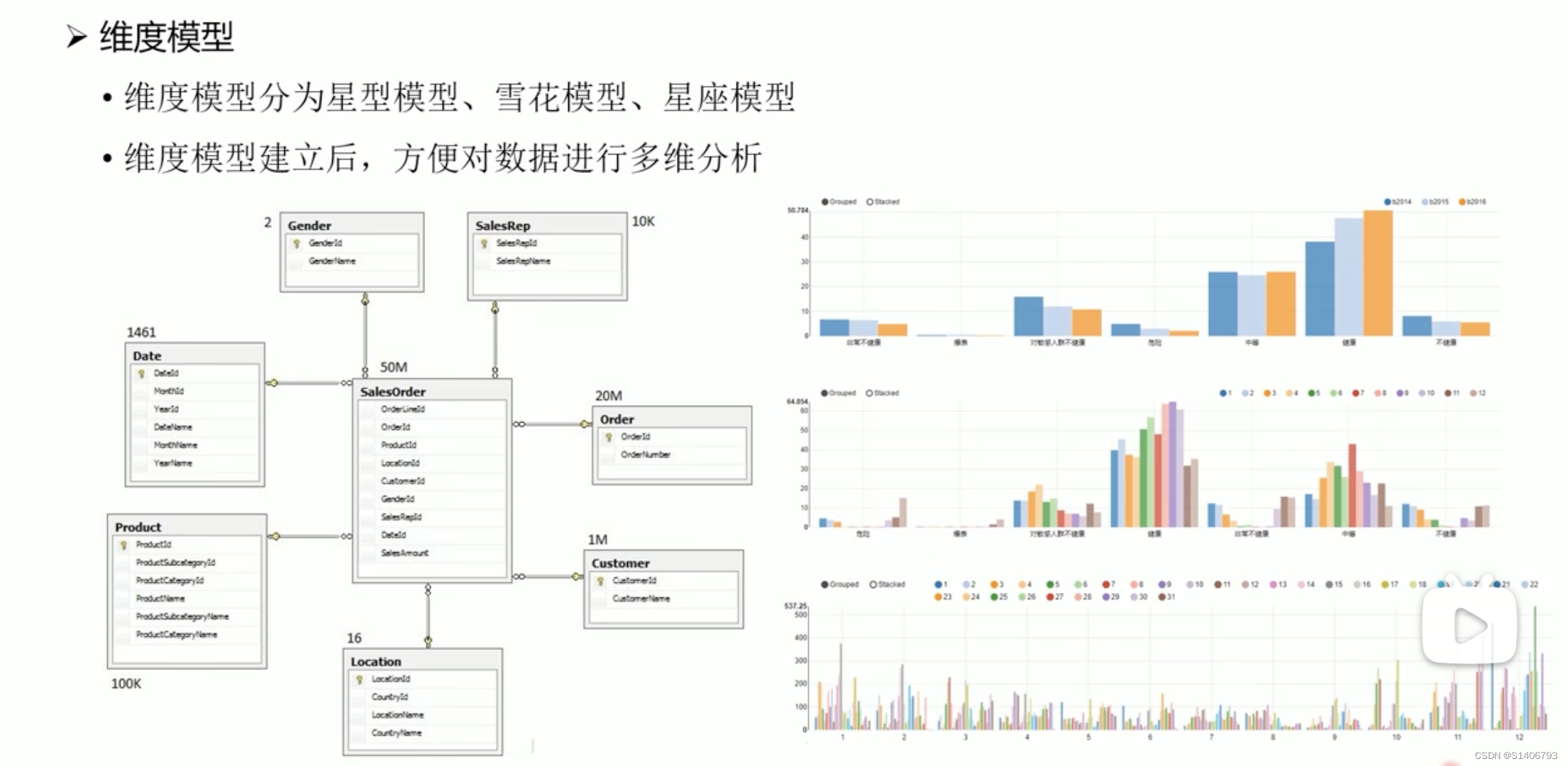

直接对事实表进行聚合即可。在企业中这种情况比较少,可能会有多层的维度,

当业务规模逐渐增长的情况下,出现的维度共用,形成了星座模型。
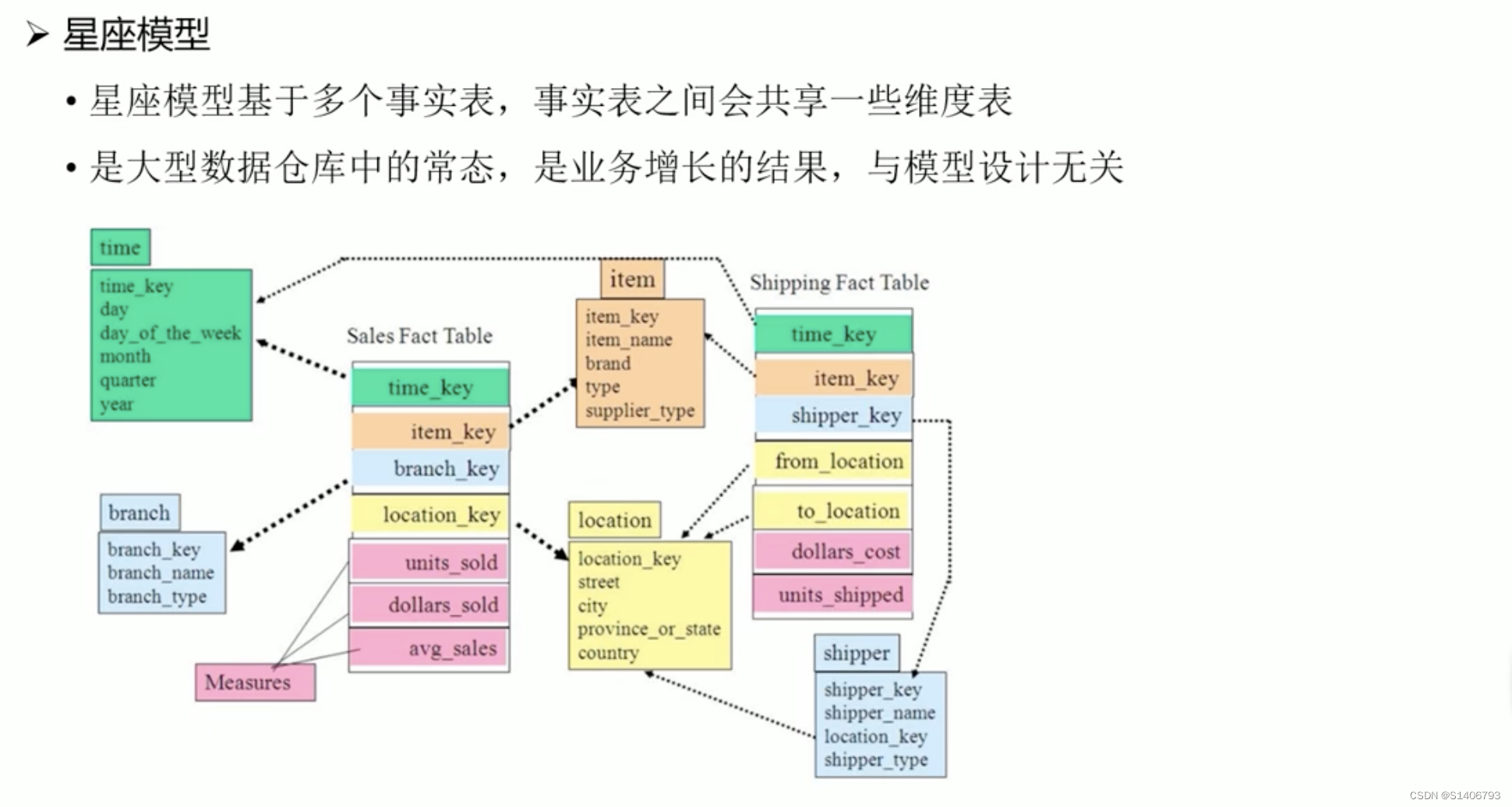
宽表模型
宽表模型是维度模型的行生,适合join性能不佳的数据仓库产品——大数据数据仓库,是维度模型的衍生,在大数据产品这块的妥协。宽表模型将维度元余到事实表中,形成宽表,以此减少join操作。

3. MOLAP
MOLAP系统建模方法
- MOLAP将数据进行预结算,并将聚合结果存储到CUBE模型中;
- CUBE模型以多维数组的形式,物化到存储系统中,加快后续的查询,以空间换时间,需要大量的存储空间;灵活性较差,只存储预计算结果,不存储原始数据;
- 生成CUBE需要大量的时间、空间,维度预处理可能会导致数据膨胀

MOLAP是面向ADS层的,加快查询速度;ROLPAP是面向DWS层的。
4. 多维分析
OLAP多维分析
- OLAP主要操作是复杂查询,可以多表关联,使用COUNT、SUM、AVG等聚合函数
- OLAP对复杂查询操作做了直观的定义,包括钻取、切片、切块、旋

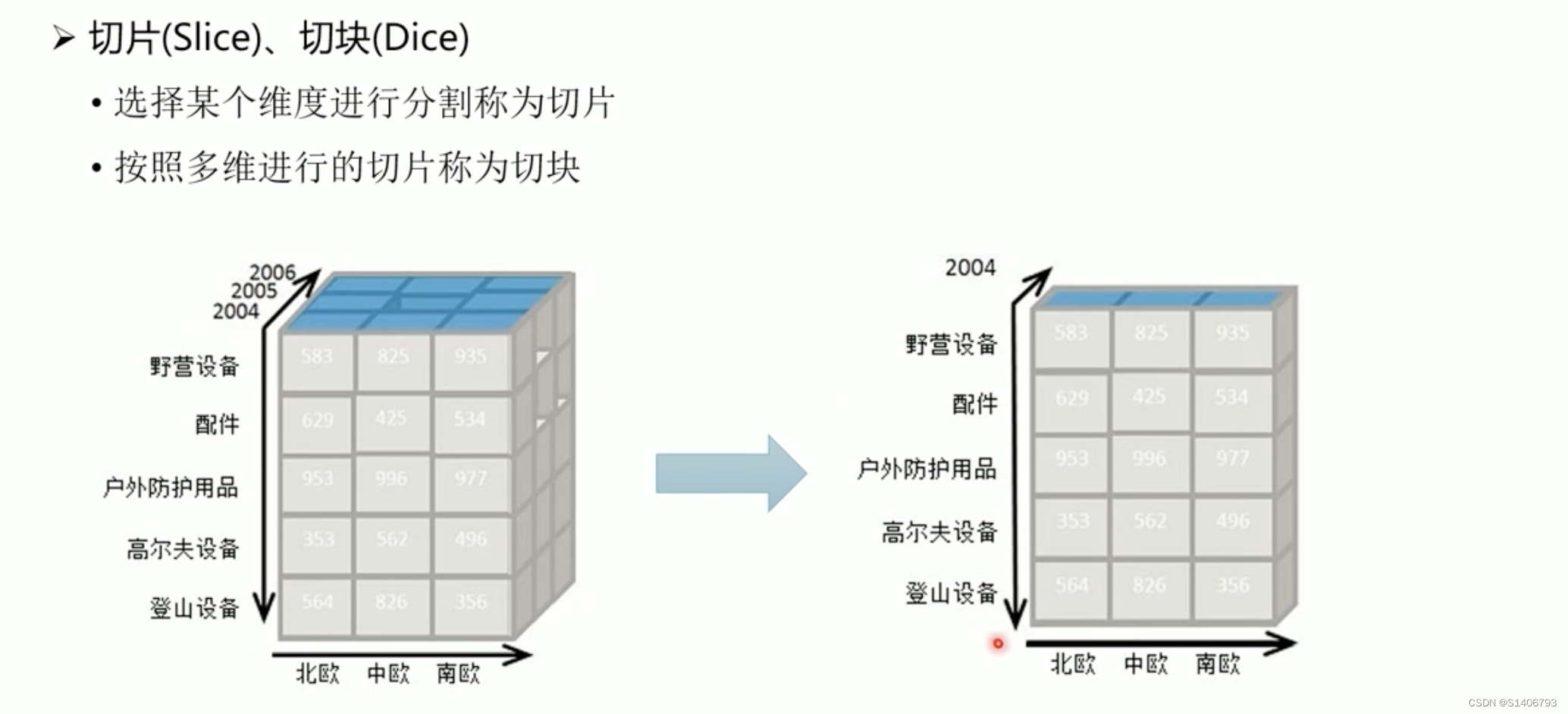

四. 最佳实践
1. 表的分类
- 事实表
- 维度表
- 事务事实表
- 周期快照事实表
- 累积快照事实 累计快照事实的三种实现方式
2. ETL技巧/策略
(1)全量同步:
•数据初始化装载一定使用全量同步的方式
•因为业务、技术原因,使用全量同步的方式做周期数据更新,直接覆盖原有数据即可
(2)增量同步
针对结构化数据:对数据库日志进行抽取,Ogg或者CDC;或者JDBC方式,用SQL对时间字段进行筛选数据;
针对非|半结构化数据:一般的抽取工具自带实时监控。
- 传统数据整合方案中,大多采用merge方式 (updatetinsert)
- 主流大数据平台不支持update操作,可采用全外连接+数据全量覆盖方式
一如果担心数据更新出错,可以采用分区方式,每天保存最新的全量版本,保留较短

3. 任务调度
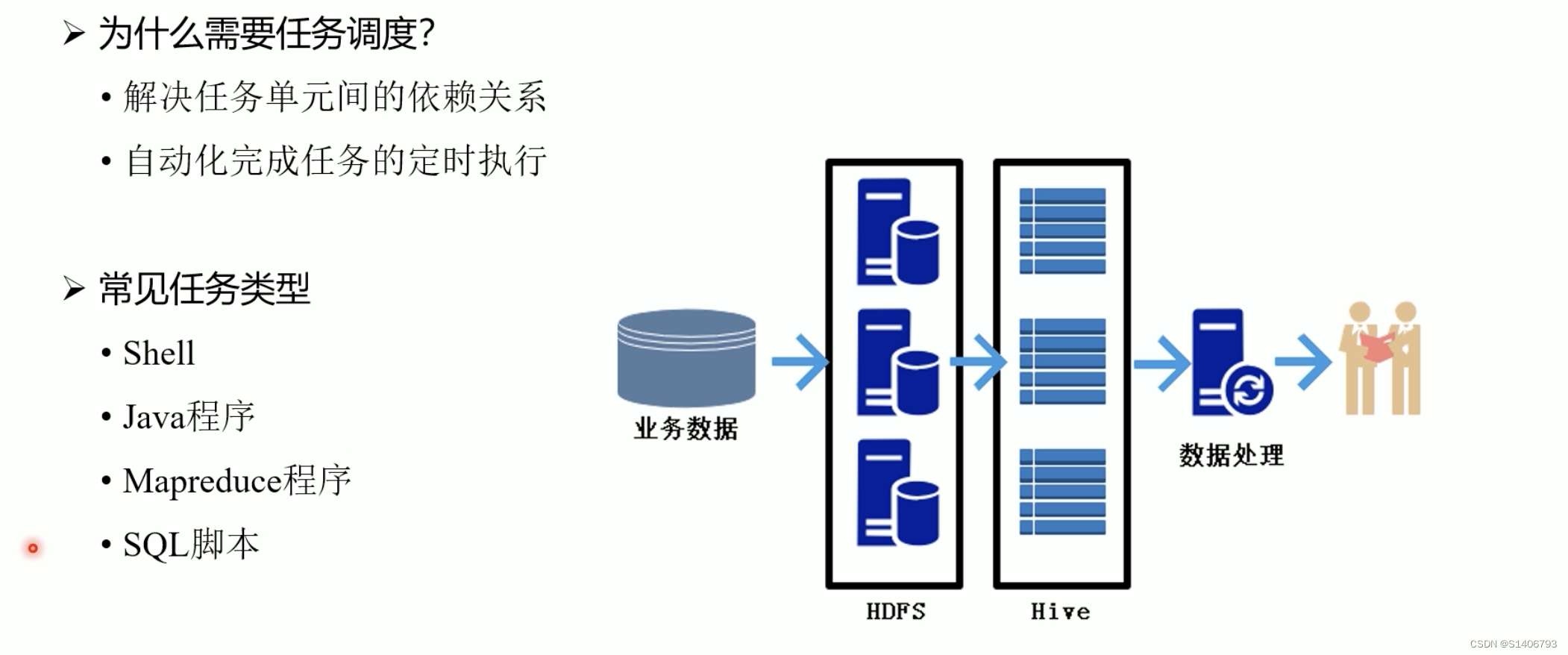
常见调度工具: Azkaban和Oozie
五、 项目实战
>> 项目背景
- 某电商企业,因数据积存、分析需要,筹划搭建数据仓库,提供数据分析访问接口
- 项目一期需要完成数仓建设,并完成用户复购率的分析计算,支持业务查询需求
>> 复购率计算
- 复购率是指在一段附间问隔内,多次重复购买产品的用户,占全部人数的比率
- 统计各个一级品类下,品牌月单次复购率,和多次复购率

>> 数据表



5.1 架构设计 
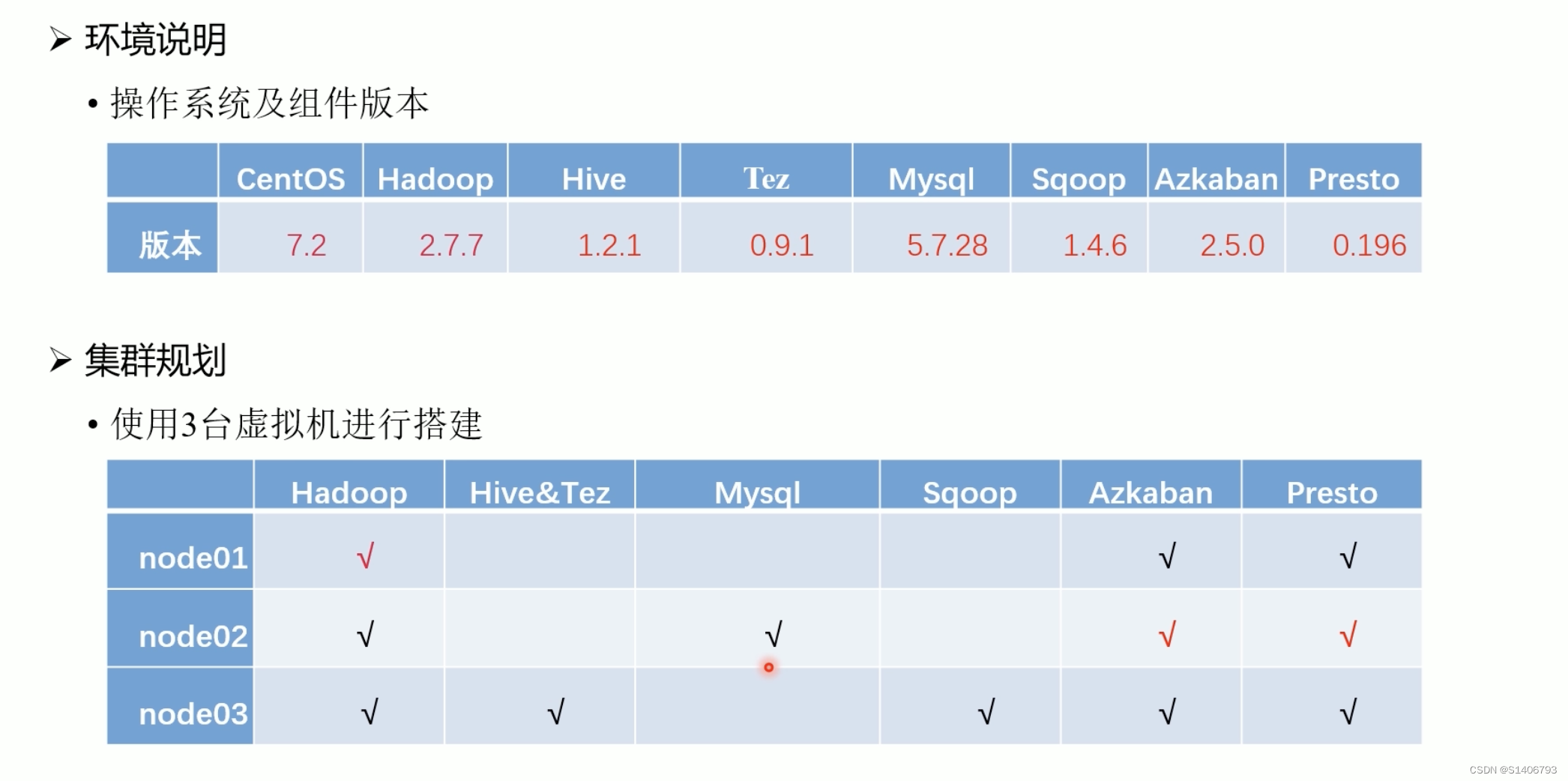
1. 虚拟机环境搭建
2. Xshell下载并与虚拟机连接
3. 脚本准备
4. 大数据集群的一键安装