文章目录
- 1. get_id
- this_thread
- 2. 锁
- 1. 为什么要使用锁?
- 2. 锁的使用
- 并行 与 串行
- 递归锁 recursive_mutex
- timed_mutex
- lock_guard 与 unique_lock
- 3. atomic
- 4. 条件变量
- 线程等待
- 线程唤醒
- 条件变量的应用
- 问题1:如何保证 v1先运行,v2阻塞?
- 问题2:如何防止 一个线程不断运行?
- 整体代码
- 线程等待中仿函数的使用
1. get_id

linux下的 pthread 是一个整形,而 id 是一个自定义类型,
get_id 即打印线程id

期望使用get_id 展开对应线程的id,但是get_id需要线程对象去调用,而此时正在构造线程对象
this_thread
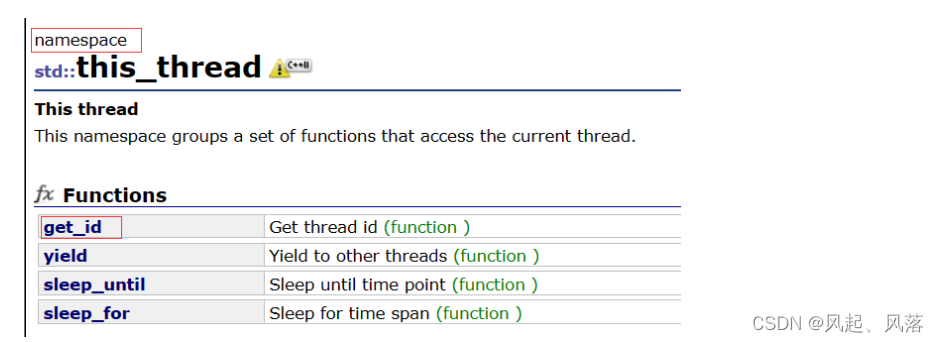
thread中 单独提供一个类 this_thread, 该类中存在 get_id()
属于全局的,由于可能存在冲突问题,所以使用命名空间封装起来

此时即可查看对应线程id
2. 锁
C++11中锁的使用规则 与 Linux的锁基本一致,所以例如 lock /unlock 等接口说明不是很详细
点击查看:Linux中的锁
1. 为什么要使用锁?
对变量进行++
传统写法:

定义一个全局变量,对其++ n次,分别使用线程v1和线程v2去调用
每个线程都有自己独立的栈,而n作为局部变量,线程都有各个的n存在 即 各线程之间访问的是不同的n
x作为全局变量,被多线程共享, 即多个线程之间访问的是同一个x
多个线程去访问同一个全局变量,就会引发并发访问的问题,进而导致 数据不一致
如:线程a和线程b同时访问 fun函数,进行x++,
刚开始 x为0,线程a进行++操作时,被终止,而同时进行线程b的++操作被执行 ,
就导致 x为 1 ,而进行线程 a 和 b 分别进行一次操作
为了避免并发访问的问题,需要加锁,即 只有一个线程可以调用全局变量
2. 锁的使用

支持无参构造 与拷贝构造

lock 加锁
unlock 解锁
trylock 是一种申请锁的非阻塞版本(死锁部分有提到)
native_handle (基本不使用,所以就不简介了)
并行 与 串行

若将锁的定义设置在fun函数内部
每个线程都有独立的栈,就会导致 线程 v1 和线程v2 都有不同的锁,两者的加锁和解锁操作 不是对同一个锁
就无法解决并发访问的问题
所以将锁定义为全局的,才可以保证两者使用的同一把锁
在以上场景下,串行所需时间更少

并行 除了有 频繁调用 加锁 和 解锁
还有切换上下文的消耗
若存在线程A和线程B,当线程A进行加锁操作,线程B需要进入休眠,导致切出去,
可线程B还没有切完,线程A就进行解锁,此时需要线程B进行加锁
(线程B还没等切出去,又要切回来)
当线程A完成加锁 解锁 ,等到线程B 也完成 加锁 解锁 ,才会打印x ,从而进行两者交替
(看起来就像是 两者一起打印x)

当为串行时,若存在线程A和线程B,只有当线程A跑完后, 线程B才能再跑

C++11中使用lambda表达式 也可替换函数指针的位置,内部通过函数体 来实现 x++
在进行for循环之前使用 lock 加锁,在循环结束 使用 unlock 解锁
递归锁 recursive_mutex
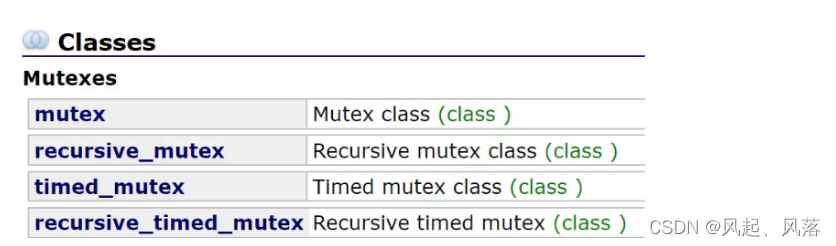
锁分为以上几种,
mutex为普通的互斥锁
recursive_mutex 为递归 的互斥锁(解决递归的问题)
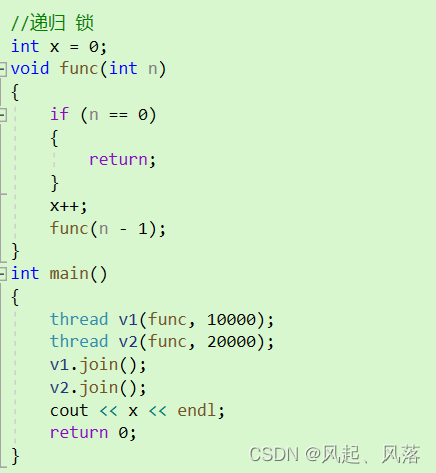
运行程序会挂掉,因为每个线程对应的栈空间不大,导致栈溢出了
若存在线程安全问题,则需要加锁

线程v1 先加锁,还没等解锁,递归再次调用func函数 进行加锁 ,导致死锁问题 ,使程序挂掉了
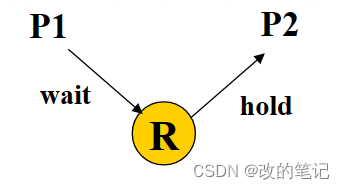
(死锁: 两个线程各自持有自己的锁,并向对方申请锁,从而导致互相申请锁不成功,进而导致双执行流互相被挂起访问临界资源的临界区代码,无法得以推进)
点击查看:Linux 下的死锁
使用递归互斥锁, recursive_mutex 即可解决这个问题
线程v1加锁后,若再次递归调用func函数,若发现再次对线程v1加锁,就不会执行该动作
timed_mutex

timed_mutex 相对于 mutex
新增加了 try_lock_for 与 try_lock_until 的功能
try_lock_for:
加锁后,给一段时间,若超过这段时间还没解锁,就会自动解锁
try_lock_until:
加锁后,到一个绝对时间
如:加锁后,设置到11点,若到11点还没解锁就自动解锁
lock_guard 与 unique_lock
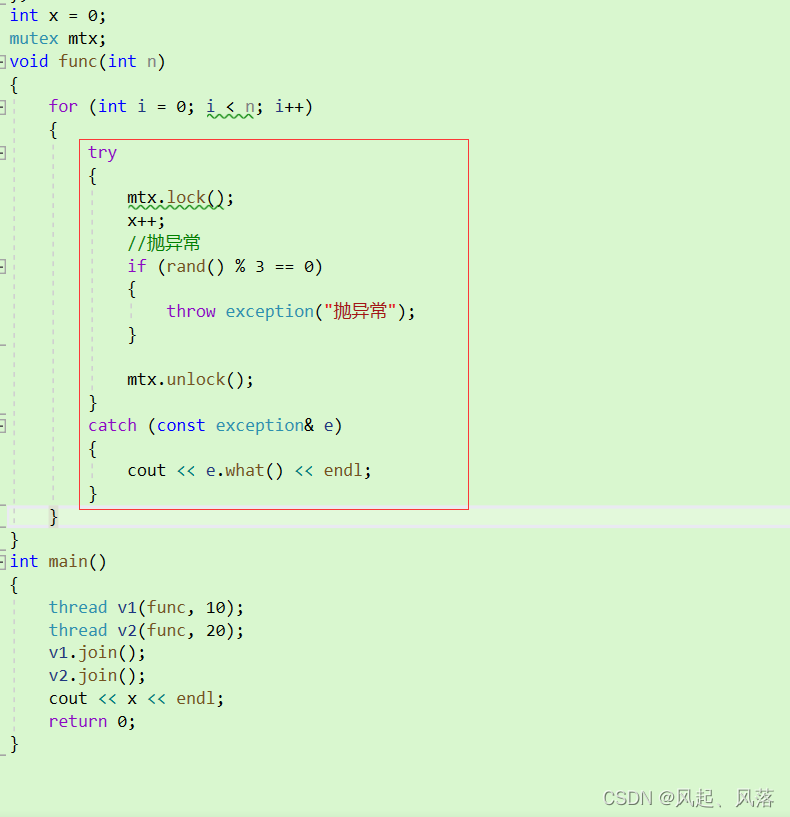
先进入try 进行加锁,由于抛异常 ,进入catch ,跳过了解锁操作 ,再次循环进入try 对其进行加锁,存在 死锁 问题
抛异常后,会直接跳到捕获的地方

借助LockGuard这个类
构造时,进行加锁
析构时,进行解锁
但是在构造时,是有锁对象的,所以可以去调用lock 进行加锁
而 析构时,是没有锁对象的,所以借助私有成员变量 调用unlock 进行解锁
由于锁是没有移动构造的,只有拷贝构造
所以将私有成员变量设置为 引用 ,(必须在初始化列表进行初始化)
将其设置为 锁对象的别名
为了解决上述的死锁问题,调用LockGurad类 的构造和析构

在构造时,就会进行加锁,
当出了作用域 ,就会调用析构,进行解锁

实际上这个类不需要自己写,库里面有两个
lock_guard:
与上述自己实现的 LockGuard 类效果相同 ,构造时,进行加锁,析构时,进行解锁

unique_lock 除了支持 构造加锁 析构解锁外 ,还支持 手动解锁
3. atomic
C++11 将 atomic 分装成一套库,支持 CAS相关的操作

一般直接使用atomic 这个类,支持为原子的

之前为了防止多线程出现 并发访问的问题,使用加锁
把 ++本身 改为原子的 ,也是可以解决这个问题的


三种写法分别对应 三种构造
4. 条件变量
在C++11中条件变量 的使用 与 linux中的条件变量 差不多
点击查看:Linux下的条件变量
线程等待
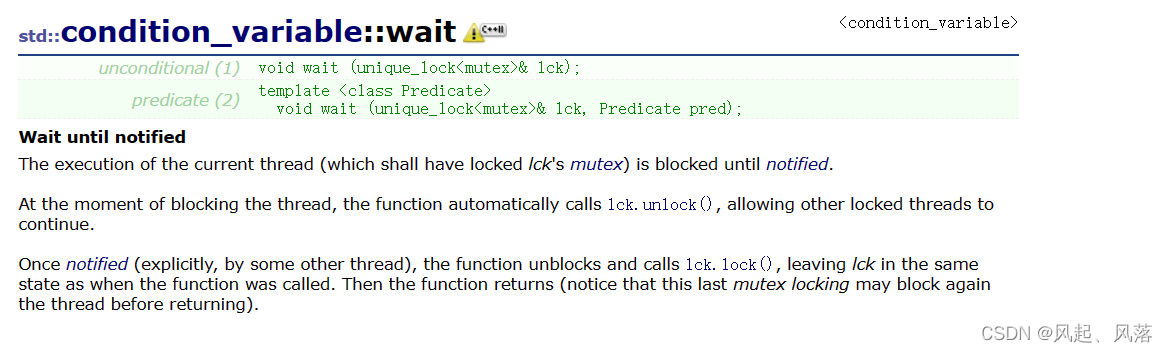
C++11推荐把锁对象 给 unique_lock
对线程进行阻塞,直到被唤醒
在阻塞前的一瞬间,会进行解锁 (unique_lock 支持 手动解锁),允许其他线程进行加锁
被唤醒后,会先加锁
线程唤醒

notify_one : 当前线程 进行解锁后,唤醒 一个线程 进行加锁 操作
notify_all :当前线程 进行解锁后,通知 所有线程 ,唤醒其中一个线程进行加锁 操作

唤醒等待条件的 其中一个线程
如果没有人等待,就什么都不做
若等待的线程超过一个,就随机选择一个线程进行唤醒
条件变量的应用
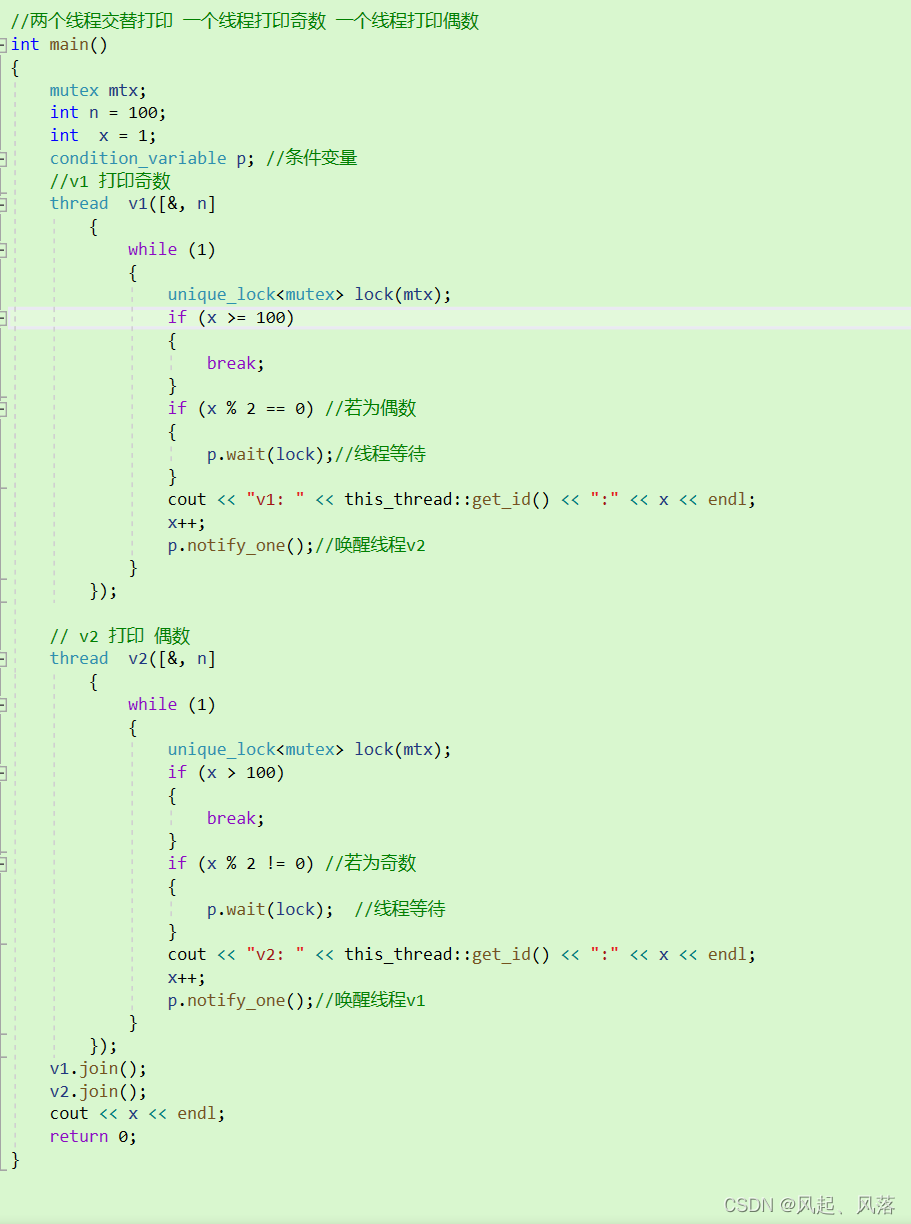
使两个线程 v1 和v2,使之交替打印,线程v1 打印偶数 线程v2打印奇数
因为要使用 条件变量的wait 接口,需要使用 unique_lock
所以 使用 unique_lock 先创建一个锁对象
问题1:如何保证 v1先运行,v2阻塞?

unique_lock lock(mtx);
调用unique_lock 使mtx锁 在 构造时,可以进行加锁操作,析构时,进行解锁操作
分为两种情况
情况1:
若v1先抢到锁,v2后抢到锁
v1先运行,v2阻塞到锁上
情况2:
若v1先抢到锁,v2后抢到锁
v2先运行,v1阻塞到锁上,但是v2会被下一步的wait进行阻塞(在阻塞前的一瞬间,会进行解锁)
保证v1先运行
问题2:如何防止 一个线程不断运行?
线程 v1 :
当线程v1打印后,理应让线程v2打印,所以使用 notify_one 唤醒 wait 但是没有wait 存在,所以什么都不做 ,出了作用域 使线程v1解锁
此时 线程v1并没有停下来,有可能继续循环 与线程v2 竞争 锁 的使用权
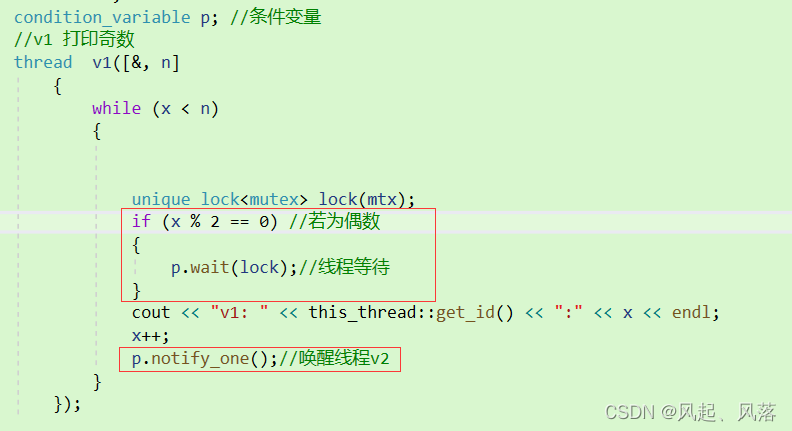
所以需要避免这种 竞争锁的事情 发生,在线程v1中 设置 if 判断 ,
若为偶数 进入 if 判断中,进行线程等待,若为奇数,则正常打印
线程v2 :

当线程v1打印后,理应让线程v2打印,所以使用 notify_one 唤醒 wait 但是没有wait 存在,所以什么都不做 ,出了作用域 使线程v1解锁
若线程v1竞争到了 锁, 由于x作为偶数,所以线程v2会阻塞到 条件变量中(这个过程中会解锁)
此时 线程v2被唤醒,x作为偶数 进行打印, 同时 会继续运行,再次进行 wait ,使 线程v2也 阻塞 到条件变量中
所以 在线程v2运行一次后,需要唤醒线程v1

有可能继续循环 与线程v1 竞争 锁 的使用权
所以需要避免这种 竞争锁的事情 发生,在线程v2中 设置 if 判断 ,
若为奇数 进入 if 判断中,进行线程等待,若为偶数,则正常打印
整体代码
线程等待中仿函数的使用

给一个前置条件的仿函数 /可调用对象 (lambda表达式对象) pred
若 返回 false,就wait阻塞
若返回 true ,就不wait

lambda对象 即可调用对象
在函数体内 ,因为线程v1要打印奇数,所以当x为偶数时,就会发生阻塞