作业头
| 这个作业属于哪个课程 | 自然语言处理 |
|---|---|
| 这个作业要求在哪里 | NLP作业02:课程设计报告 |
| 我在这个课程的目标 | 实现基于Seq2Seq注意力机制的聊天机器人 |
| 这个作业在哪个具体方面帮助我实现目标 | 问题的提出,资料的查找 |
| 参考文献 | 1.简说Seq2Seq原理以及实现 2.序列到序列学习(seq2seq) 20分钟掌握RNN与LSTM原理及其结构应用(Seq2Seq & Attention) |
文章目录
- 1. 设计目的
- 2.设计要求
- 2.1 实验仪器及设备
- 2.2 设计要求
- 3.设计内容
- 4.设计过程
- 4.1 提出总体设计方案
- 4.2 具体实现过程
- 4.2.1 数据收集和预处理
- 4.2.2 模型搭建
- 4.2.3 模型训练与保存
- 4.2.4 聊天机器人
- 4.2.5 登录界面
- 5.设计体会
1. 设计目的
通过课程设计的练习,加深学生对所学自然语言处理的理论知识与操作技能的理解和掌握,使得学生能综合运用所学理论知识和操作技能进行实际工程项目的设计开发,让学生真正体会到自然语言处理算法在实际工程项目中的具体应用方法,为今后能够独立或协助工程师进行人工智能产品的开发设计工作奠定基础。通过综合应用项目的实施,培养学生团队协作沟通能力,培养学生运用现代工具分析和解决复杂工程问题的能力;引导学生深刻理解并自觉实践职业精神和职业规范;培养学生遵纪守法、爱岗敬业、诚实守信、开拓创新的职业品格和行为习惯。
2.设计要求
2.1 实验仪器及设备
(1) 使用64位Windows操作系统的电脑。
(2) 使用3.8.16版本的Python。
(3) 使用6.4.12版本的jupyter notebook编辑器。
(4) 使用 numpy,pandas,tensorflow,pyttsx3……
2.2 设计要求
课程设计的主要环节包括课程设计作品和课程设计报告的撰写。课程设计作品的完成主要包含方案设计、计算机编程实现、作品测试几个方面。课程设计报告主要是将课程设计的理论设计内容、实现的过程及测试结果进行全面的总结,把实践内容上升到理论高度。
3.设计内容
本项目针对传统的聊天机器人对话生成机制识别率低的情况,设计一种基于 seq2seq和Attention模型的聊天机器人对话生成机制,一定程度提高了识别率,项目设计内容为:
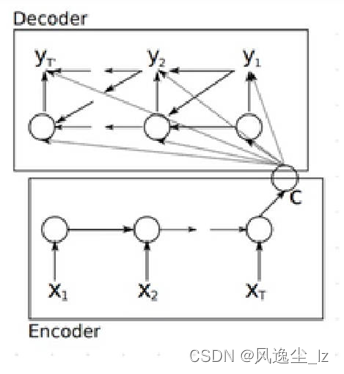
(1)编码器和解码器
这两个模型本质上都⽤到了两个循环神经⽹络,分别叫做编码器和解码器。 编码器⽤来分析输⼊序列,解码器⽤来⽣成输出序列。
(2)LSTM
长短期记忆(Long short-term memory)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
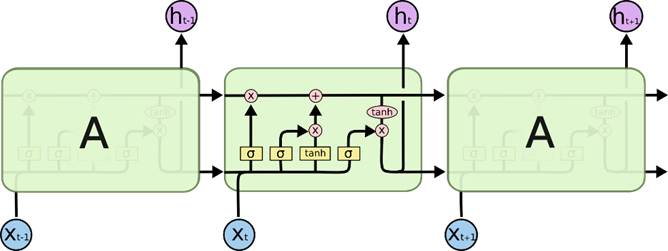
本项目采用LSTM作为编码器和解码器。
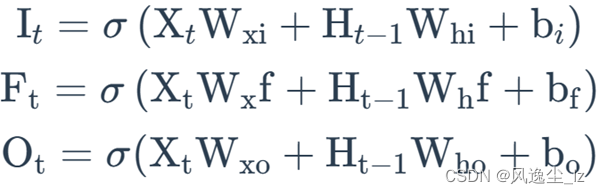
(3)注意力机制
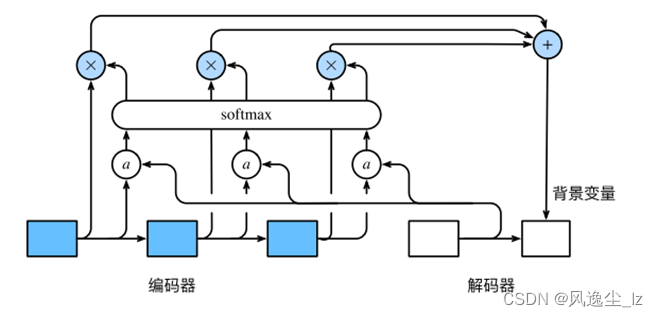
编码器在时间步t的隐藏状态为ht,且总时间步数为T。那么解码器在时间步t ′的背景变量为所有编码器隐藏状态的加权平均:
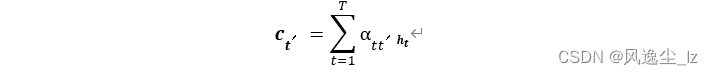
其中给定t ′时,权重αt ′t在t = 1, . . . , T的值是⼀个概率分布。为了得到概率分布,我们可以使⽤softmax运算:
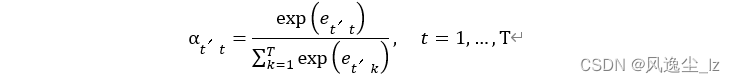
计算softmax运算的输⼊et ′t。由于et ′t同时取决于解码器的时间步t ′和编码器的时间步t,不妨以解码器在时间步t ′ − 1的隐藏状态st ′−1与编码器在时间步t的隐藏状态ht为输⼊,并通过函数a计算et ′t:
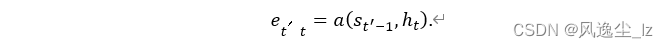
4.设计过程
4.1 提出总体设计方案
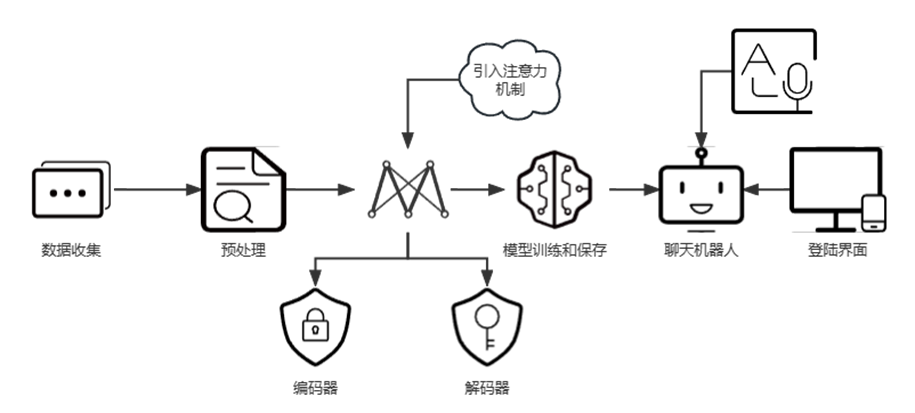
为了设计基于Seq2Seq注意力机制的聊天机器人系统,需要以下几个步骤:
(1)数据收集和预处理:搜集对话记录数据集,并进行文本清洗、处理,如去除标点符号、转换为小写字母等。将文本序列转换为相应的整数序列,并对数据进行填充,对话记录数据集应包含问题和答案的对应关系。
(2)创建Seq2Seq模型:使用TensorFlow框架创建Seq2Seq模型,其中编码器采用 LSTM,解码器采用 LSTM + 注意力机制。Seq2Seq 模型将问题作为输入,输出答案。
(3)训练模型和保存:将预处理的数据集训练Seq2Seq模型,调整超参数和网络结构优化模型性能。
(4)设计主函数:加载预训练模型的权重参数,通过循环处理输入的文本序列 encoder_input_data,进行机器人对话交互。
(5)构建UI界面,使用 PyQt5设计登录界面,实现正确输入账号密码登录使用基于Seq2Seq注意力模型的聊天机器人系统。
4.2 具体实现过程
4.2.1 数据收集和预处理
(1)数据收集
通过在网上搜集资料,寻找合适的语料库,本项目采用的语料库为Source_segment11.txt
(2)导入相关库
导入实验所需库,用于后续数据的处理和模型的构建,其中主要使用Tensorflow中的Keras模块,Keras 是一个高级神经网络API,它可以帮助构建和训练深度学习模型,而无需手动编写大量的代码,避免重复造轮子。
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers , activations , models , preprocessing , utils
import pandas as pd
import pyttsx3
import sys
(3)数据预处理
使用中文分词工具jieba,将原来的语料库进行中文分词处理,在自动问答系统中,对于用户输入的问题,我们需要通过自然语言处理技术将其转换成机器能够理解和处理的形式,以便能够正确匹配并返回相应的答案。而中文分词是这个过程中的一环,其主要作用是将中文句子切分为一系列有意义的词汇单位,以便后续的处理。
import jieba
with open('Source_segment11.txt', 'r', encoding='utf-8') as f:
text = f.read()
seg_list = jieba.cut(text, cut_all=False)
with open('Source_segment12.txt', 'w', encoding='utf-8') as f:
f.write(' '.join(seg_list))
(4)读取预处理数据
读取预处理数据,移除换行,对文本库数据进行检查,并查看对话内容总数,对数据展示,初步查看数据预处理情况。
text_Segment = open('./Source_segment11.txt','r', encoding='utf-8')
text_Segment_list = text_Segment.readlines()
text_Segment.close()
text_Segment_list = [n.rstrip() for n in text_Segment_list]
if len(text_Segment_list)%2!=0:
print("文本库数据有误 对话不对称 请检查!")
else:
print('对话内容总数:', len(text_Segment_list))
X = text_Segment_list[0:][::2]
Y = text_Segment_list[1:][::2]
lines = pd.DataFrame({"input":X,"output":Y})
lines.head()
(5)数据填充
使用预处理模块中的 Tokenizer() 方法对其进行处理,将文本数据转换为相应的整数序列。然后,统计所有序列的长度,并找到其中的最大长度作为填充后的标准长度,再使用 pad_sequences() 函数对序列进行填充。
#encoder
input_lines = list()
for line in lines.input:
input_lines.append(line)
print(input_lines[:4])
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(input_lines)
tokenized_input_lines = tokenizer.texts_to_sequences(input_lines)
print(tokenized_input_lines[:4])
len_list = list()
for token_line in tokenized_input_lines:
len_list.append(len(token_line))
print(len_list[:4])
max_len = np.array(len_list).max()
print( '输入最大长度为{}'.format( max_len ))
padded_input_lines = preprocessing.sequence.pad_sequences(tokenized_input_lines, maxlen=max_len, padding='post')
print("进行填充之后:")
print(padded_input_lines[:4])
encoder_input_data = np.array(padded_input_lines)
print( '编码输入数据后的形状 -> {}'.format( encoder_input_data.shape ))
input_word_dict = tokenizer.word_index
# print(input_word_dict)
num_input_tokens = len(input_word_dict) + 1
print( '输入词元数量 = {}'.format( num_input_tokens))
output_lines = list()
for line in lines.output:
output_lines.append('<START> ' + line + ' <END>')
print(output_lines[:4])
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(output_lines)
tokenized_output_lines = tokenizer.texts_to_sequences(output_lines)
length_list = list()
for token_seq in tokenized_output_lines:
length_list.append( len( token_seq ))
max_output_length = np.array( length_list ).max()
print( '输出最大长度为 {}'.format( max_output_length ))
padded_output_lines = preprocessing.sequence.pad_sequences(tokenized_output_lines, maxlen=max_output_length, padding='post')
decoder_input_data = np.array(padded_output_lines)
print( '解码数据后的shape -> {}'.format( decoder_input_data.shape ))
output_word_dict = tokenizer.word_index
num_output_tokens = len(output_word_dict) + 1
print( '输出词元的数量 = {}'.format( num_output_tokens))
decoder_target_data = list()
for token in tokenized_output_lines:
decoder_target_data.append(token[1:])
padded_output_lines = preprocessing.sequence.pad_sequences(decoder_target_data, maxlen=max_output_length, padding='post')
onehot_output_lines = utils.to_categorical(padded_output_lines, num_output_tokens) #对答案进行 one-hot 编码
decoder_target_data = np.array(onehot_output_lines)
print( 'Decoder target data shape -> {}'.format( decoder_target_data.shape ))
4.2.2 模型搭建
模型搭建包含编码器和解码器两个部分。
(1)编码器的输入
是一个形状为(None,)的张量,表示输入序列的长度是可变的;嵌入层将输入序列中的每个单词转换为一个256维的向量;LSTM层将嵌入层的输出作为输入,返回最后一个时间步的输出和状态向量。这些状态向量将作为解码器的初始状态。
图 4- 11 编码器输入
(2)解码器的输入
也是一个形状为(None,)的张量,表示输出序列的长度是可变的;嵌入层将输出序列中的每个单词转换为一个256维的向量;LSTM层将嵌入层的输出作为输入,同时也接收编码器的状态向量作为初始状态,返回一个形状为(None,256)的张量作为输出序列。
encoder_inputs = tf.keras.layers.Input(shape=( None , ))
#嵌入层将输出序列中的每个单词转换为一个256维的向量
encoder_embedding = tf.keras.layers.Embedding( num_input_tokens, 256 , mask_zero=True ) (encoder_inputs) #编码器的嵌入层
#LSTM层将嵌入层的输出作为输入,同时也接收编码器的状态向量作为初始状态,返回一个形状为(None,256)的张量作为输出序列
encoder_lstm = tf.keras.layers.LSTM( 256 , return_state=True , recurrent_activation = 'sigmoid',dropout=0.2)
encoder_outputs , state_h , state_c = encoder_lstm( encoder_embedding )
encoder_states = [ state_h , state_c ]
decoder_inputs = tf.keras.layers.Input(shape=( None , ))
decoder_embedding = tf.keras.layers.Embedding( num_output_tokens, 256 , mask_zero=True) (decoder_inputs)
decoder_lstm = tf.keras.layers.LSTM( 256 , return_state=True , recurrent_activation = 'sigmoid',return_sequences=True,dropout=0.2)
decoder_outputs , _ , _ = decoder_lstm ( decoder_embedding , initial_state=encoder_states)
(3)注意力机制,
通过计算解码器的输出序列和编码器的输出序列之间的相似度,得到一个权重向量,表示解码器在生成当前单词时应该关注编码器输出序列的哪些部分。这个权重向量会被用来加权编码器的输出序列,得到一个加权向量,作为解码器的输入。
#注意力机制
attention = tf.keras.layers.Attention(name='attention_layer')
attention_output = attention([decoder_outputs,encoder_outputs])
(4)Concatenate和全连接层
将解码器的输出向量映射到一个形状为(num_output_tokens)的张量,表示输出序列中每个单词的概率分布。
#定义 Concatenate 层,并将解码器 LSTM 层的输出 decoder_outputs 与 attention_output 进行连接。
decoder_concat = tf.keras.layers.Concatenate(axis=-1, name='concat_layer')
decoder_concat_input = decoder_concat([decoder_outputs, attention_output])
#全连接层
decoder_dense = tf.keras.layers.Dense( num_output_tokens , activation=tf.keras.activations.softmax )
output = decoder_dense ( decoder_concat_input )
#预训练的神经网络模型
model = tf.keras.models.Model([encoder_inputs, decoder_inputs], output )
#编译模型,使用 Adam 优化器以及交叉熵损失函数进行训练,同时使用 accuracy 指标查询准确率
model.compile(optimizer=tf.keras.optimizers.Adam(), loss='categorical_crossentropy',metrics=['accuracy'])
(5)模型预训练和编译
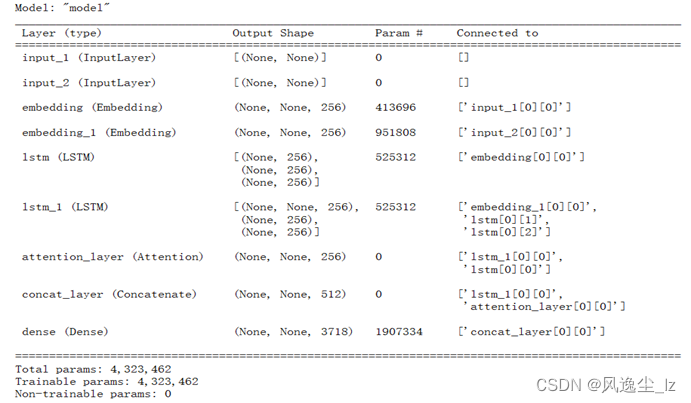
模型的损失函数为交叉熵,优化器为Adam,评价指标为准确率。模型的输入是编码器和解码器的输入张量,输出是全连接层的输出张量。模型结构的具体信息可以通过调用summary()方法进行查看。
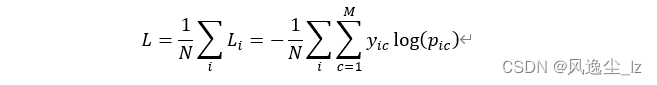
其中:
| 符号 | 解释 |
|---|---|
| M | 类别的数量 |
| yic | 符号函数( 0 或 1 ) |
| pic | 观测样本 i 属于类别 c 的预测概率 |
model.summary() #查看模型结构的具体信息
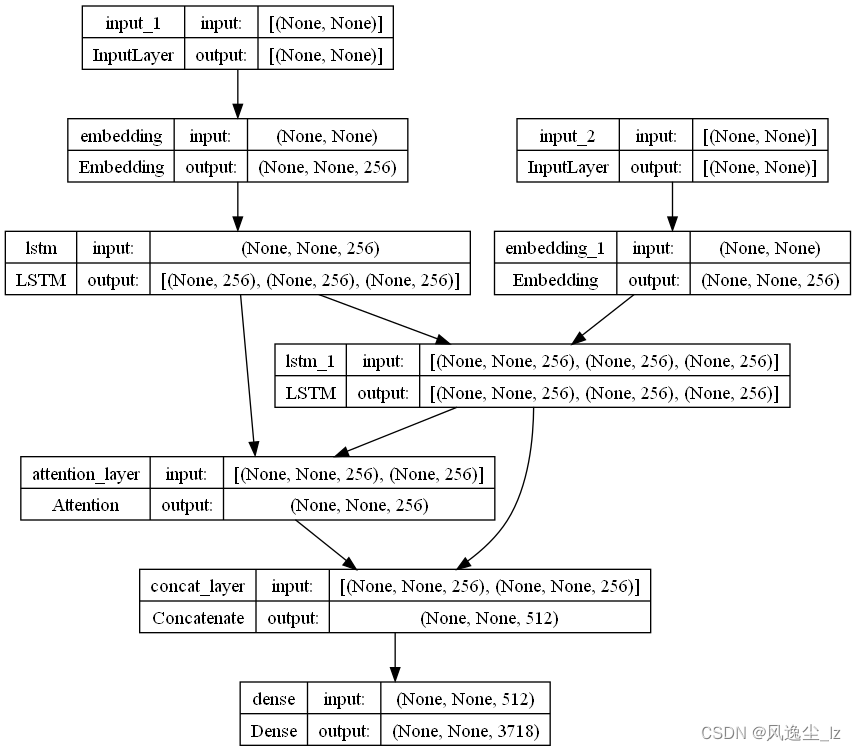
#导入下面的库
from tensorflow.keras.utils import plot_model
import pydotplus
#参数 :模型名称,结构图保存位置,是否展示shape
plot_model(model,to_file='model.png',show_shapes=True)
4.2.3 模型训练与保存
(1)代码定义了一个生成随机 batch 数据的函数 generate_batch_data_random,用于逐步提取数据并降低对显存的占用。
DEFAULT_BATCH_SIZE = 32
DEFAULT_EPOCH = 200
import random
def generate_batch_data_random(x1,x2, y, batch_size):
"""逐步提取batch数据到显存,降低对显存的占用"""
ylen = len(y)
loopcount = ylen // batch_size
while (True):
i = random.randint(0,loopcount)
yield [x1[i * batch_size:(i + 1) * batch_size],x2[i * batch_size:(i + 1) * batch_size]], y[i * batch_size:(i + 1) * batch_size]
(2)计算训练集的批次数,以便在训练过程中使用。然后,使用generate_batch_data_random函数生成随机批次的训练数据,并使用fit函数进行训练。其中,steps_per_epoch参数设置为train_num_batches,表示在一个epoch中训练的批次数。batch_size参数设置为DEFAULT_BATCH_SIZE,表示每个批次的大小。epochs参数设置为DEFAULT_EPOCH,表示训练的轮数。最后,使用save函数将训练好的模型保存为’h5’格式的文件。
train_num_batches = len(encoder_input_data) // DEFAULT_BATCH_SIZE #
model.fit(generate_batch_data_random(encoder_input_data,decoder_input_data,decoder_target_data,DEFAULT_BATCH_SIZE)
,steps_per_epoch=train_num_batches, batch_size=DEFAULT_BATCH_SIZE, epochs=DEFAULT_EPOCH)
model.save( 'model.h5' )
(3)将训练好的编码器和解码器模型组合成一个完整的推理模型。在推理阶段,该模型可以一步一步地生成目标序列,直到完成整个序列的生成,并且可以对每一步的输出进行调整和优化。
def make_inference_model():
encoder_outputs , state_h , state_c = encoder_lstm( encoder_embedding )
encoder_model = tf.keras.models.Model(encoder_inputs, [encoder_outputs,encoder_states])
decoder_state_input_h = tf.keras.layers.Input(shape=(256,))
decoder_state_input_c = tf.keras.layers.Input(shape=(256,))
decoder_state_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_embedding, decoder_state_inputs)
decoder_states = [state_h, state_c]
attention_output = attention([decoder_outputs,encoder_outputs])
decoder_concat_input = decoder_concat([decoder_outputs, attention_output])
decoder_outputs = decoder_dense(decoder_concat_input)
decoder_model = tf.keras.models.Model([decoder_inputs,encoder_outputs] + decoder_state_inputs, [decoder_outputs] + decoder_states)
return encoder_model, decoder_model
enc_model , dec_model = make_inference_model()
4.2.4 聊天机器人
(1)定义str_to_token函数,将一个输入的句子转换为一个数字序列。
import jieba
def str_to_token (sentence: str):
words = sentence.lower().strip()
words = jieba.cut(words)
token_list = list()
for word in words:
token_list.append(input_word_dict[word])
return preprocessing.sequence.pad_sequences([token_list], maxlen=max_len, padding='post')
(2)定义聊天机器人函数,实现一个简单的基于预训练模型的聊天机器人,它可以接收用户的文本输入,使用预训练模型生成合适的响应,并通过语音输出等方式进行回复。
4.2.5 登录界面
设计一个登录界面,用户,输入正确的账号密码,方可登录聊天机器人系统,若输入错误,会有错误提示。
# 导入所需的库
import sys
import numpy as np
import pyttsx3
from PyQt5.QtWidgets import QApplication, QWidget, QTextEdit, QLineEdit, QVBoxLayout
from PyQt5.QtCore import Qt
# 加载模型和词典
model = ... # 省略模型加载的代码
output_word_dict = ... # 省略词典加载的代码
# 定义一个将字符串转换为token的函数
def str_to_token(sentence):
# 省略转换逻辑的代码
return token
# 创建一个聊天机器人类
class Chatbot:
def __init__(self):
# 初始化语音引擎对象
self.engine = pyttsx3.init()
# 加载编码器和解码器模型
self.enc_model = ... # 省略模型加载的代码
self.dec_model = ... # 省略模型加载的代码
# 定义一个回答用户输入的方法
def reply(self, user_input):
# 初始化一个空的翻译结果
decoded_translation = ''
try:
# 用编码器模型预测用户输入的状态值和输出值
encoder_outputs, states_values = self.enc_model.predict(str_to_token(user_input))
# 创建一个空的目标序列
empty_target_seq = np.zeros((1, 1))
# 将目标序列的第一个元素设为"start"对应的索引值
empty_target_seq[0, 0] = output_word_dict['start']
# 初始化一个停止条件为False
stop_condition = False
# 循环直到停止条件为True
while not stop_condition:
# 用解码器模型预测目标序列,状态值和输出值
dec_outputs, h, c = self.dec_model.predict([empty_target_seq, encoder_outputs] + states_values)
# 获取输出值中最大概率对应的索引值
sampled_word_index = np.argmax(dec_outputs[0, -1, :])
# 初始化一个采样的单词为None
sampled_word = None
# 遍历输出词典,找到索引值对应的单词
for word, index in output_word_dict.items():
if sampled_word_index == index:
# 将单词添加到翻译结果中,并加上空格
decoded_translation += ' {}'.format(word)
# 更新采样的单词为找到的单词
sampled_word = word
# 如果采样的单词是"end"或者翻译结果超过最大长度,更新停止条件为True
if sampled_word == 'end' or len(decoded_translation.split()) > max_output_length:
stop_condition = True
# 创建一个新的空目标序列
empty_target_seq = np.zeros((1, 1))
# 将目标序列的第一个元素设为采样单词对应的索引值
empty_target_seq[0, 0] = sampled_word_index
# 更新状态值为当前状态值
states_values = [h, c]
except:
# 如果出现异常,将翻译结果设为一个默认回答
decoded_translation = '对不起,我没有听懂。'
# 返回去掉"end"和空格后的翻译结果
return decoded_translation.replace(' end', '').replace(' ', '')
# 创建一个图形用户界面类
class GUI(QWidget):
def __init__(self):
super().__init__()
# 初始化一个聊天机器人对象
self.chatbot = Chatbot()
# 初始化图形用户界面
self.initUI()
def initUI(self):
# 设置窗口标题
self.setWindowTitle('聊天界面')
# 设置窗口大小
self.resize(400, 400)
# 设置窗口背景颜色
self.setStyleSheet('background-color: lightblue')
# 创建一个文本框,用于显示聊天记录,设置为只读模式
self.text_box = QTextEdit(self)
self.text_box.setReadOnly(True)
# 创建一个输入框,用于输入用户信息,设置为单行模式
self.entry_box = QLineEdit(self)
self.entry_box.setPlaceholderText('请输入一些内容')
# 绑定回车键事件,调用send方法
self.entry_box.returnPressed.connect(self.send)
# 创建一个垂直布局,将文本框和输入框添加到布局中
layout = QVBoxLayout(self)
layout.addWidget(self.text_box)
layout.addWidget(self.entry_box)
# 定义一个发送用户输入并接收机器人回答的方法
def send(self):
# 获取用户输入的内容
user_input = self.entry_box.text()
# 清空输入框
self.entry_box.clear()
# 在文本框中显示用户输入的内容,并换行
self.text_box.append('user:👨🏻🎓' + user_input)
# 调用聊天机器人的回答方法,获取机器人回答的内容
bot_output = self.chatbot.reply(user_input)
# 在文本框中显示机器人回答的内容,并换行
self.text_box.append('chatbot🤖:' + bot_output)
# 调用语音引擎说出机器人回答的内容
self.chatbot.engine.say(bot_output)
self.chatbot.engine.runAndWait()
# 创建一个应用对象
app = QApplication(sys.argv)
# 创建一个图形用户界面对象
gui = GUI()
# 显示图形用户界面
gui.show()
# 进入主循环,等待用户交互
sys.exit(app.exec_())
5.设计体会
历时七天的自然语言处理实训,是在写代码中度过的,我想这也是我们大都数同学,第一次这么长时间的坐在一起去认真搞一个项目;这对我来说,是一段特殊的回忆,并且我想,通过认真做项目,这在很大程度上提高了我们的动手能力,就比如说,在本次项目的开发过程中,我通过查找资料,看视频课学到了很多的关于自然语言处理和神经网络与深度学习方面的知识,我还拓展了该项目,为我的聊天机器人设计了一个登录界面,进而,我也学会了一些PyQt5界面设计技巧,我相信通过后续的进一步学习思考,我的聊天机器人将变得更加完善。
我选择了大都数人认为难实现的实验三作为我本次自然语言的课程设计,原因有很多,更多的是因为兴趣使然,随着ChatGPT的爆红,聊天机器人作为一种智能化的交互方式受到了越来越多人的欢迎。尤其是在各种社交软件和智能家居中,聊天机器人已经成为人们生活和工作中不可缺少的一部分。而基于 Seq2Seq 注意力机制的聊天机器人,则是目前比较常见和有效的一种技术方案,这让我忍不住想动手去试一试,实现一个自己的简单聊天机器人。
Seq2Seq 作为一种经典的神经网络模型,由编码器和解码器两个部分组成。编码器将输入序列压缩成一个定长向量,并将其传递给解码器,解码器再根据该向量生成输出序列。
然而,当输入或输出序列很长时,编码器和解码器无法保留所有信息,从而导致信息冗余和模型性能下降。为了解决这个问题,注意力机制被引入并得到成功应用。它通过学习每个输入位置与输出位置之间的相似度,使解码器能够关注输入序列中与当前输出位置最相关的部分,从而提高模型的效果。
在聊天机器人的实现中,我们可以使用 Seq2Seq 注意力机制来判断用户的输入并生成相应的回复。
首先,我们需要对聊天记录进行预处理,将原始数据转化为模型可以理解并处理的格式。这个过程通常涉及到文本清洗、分词、词向量化等一系列步骤。然后,我们可以将用户的输入作为编码器的输入,并将生成的定长向量传递给解码器。解码器通过注意力机制来生成相应的回复,并将其返回给用户。
除了技术方案,聊天机器人的交互设计也是十分重要的。为了增强用户体验,我考虑如何让用户尽可能地简便地使用聊天机器人。为此,我采用了 GUI 开发工具,如 PyQt5 等,来实现友好、直观、便捷的用户界面,从而提高用户的操作体验和满意度。例如,可以设计一个具有登录功能的界面,以便用户可以通过输入用户名和密码来进入聊天室。
在完成聊天机器人项目的过程中,我遇到了很多困难,比如说,对注意力机制和编码器解码器模型的不够理解,对PyQt5的使用,知之甚少,但是这些问题大都得到了解决,同时我增加了一些融合创新,使得整个界面看起来与众不同,这让我感受到了快速学习和创新思维的重要性。在技术和设计之间进行融合时,需要全面地考虑各种情况,并及时解决遇到的问题。同时,需要有创新思维和创造力,能够不断地推陈出新,做出更好的应用体验。此外,我还需要定期更新和优化模型,在不断学习新技术、新算法的基础上,提高聊天机器人的表现。
总的来说,基于 Seq2Seq 注意力机制的聊天机器人是一个相对较为复杂的应用,需要综合运用多种技术和工具并考虑到许多复杂因素。在实际开发中,需要我们不断地学习、思考和实践,以达到更好的应用效果和用户使用体验。